実行時間制限: 2 sec / メモリ制限: 256 MiB
第1章について
第1章では、プログラムの基本的な文法について説明します。
第1章をマスターすれば、理論上は全ての「計算処理」を行うプログラムを書ける程の知識が身につきます。
APG4bの取り組み方
プログラミングの勉強では手を動かすことが重要です。練習問題はできるだけ解くようにしましょう。
ただし、「説明文中のプログラムを何も考えずに写す」というのは時間の無駄にしかならないことが多いです。
用意されているプログラムを動かすときはコピー&ペーストを使いましょう。
プログラミング言語
プログラミングはプログラミング言語を使って行います。プログラミング言語にも様々なものがありますが、 APG4bではその中でもC++という名前のプログラミング言語を使います。
C++はプログラミング言語のなかでも主流の文法を使っているので、C++が書ければ他の多くの言語もすぐに書けるようになります。
もしかしたら「C++は難しいので初心者向けでない」という話を聞いたことがあるかもしれません。確かにC++には複雑な面があります。
しかし、C++も全てが複雑なわけではありません。初めの部分はむしろ簡単です。そして、この教材では複雑な部分はほとんど扱いません。
この教材の目的は「プログラミングの基礎」を学ぶことであって、C++に詳しくなることではないからです。
プログラムの実行方法
プログラムを実行する方法については次の練習問題を解く直前で説明します。それまで環境構築(パソコンの設定)をする必要はありません。
APG4bでは後で説明する「コードテスト」の利用を推奨しているので、難しい環境構築は不要です。環境構築をしてでも手元のパソコンでプログラムを動かしたい人は、付録1の「手元のコンピュータでプログラムを書きたい場合」を参照してください。
問題
提出練習
プログラミングの文法の説明に入る前に、自動採点システム(ジャッジ)の使い方を確認しましょう。
このページの一番下の「ソースコード」と書かれた場所の隣にテキストを入力できるところがあると思います。
そこに次のプログラムをコピー&ペーストしてみましょう。
コピー&ペーストの仕方:
↓の右上にある「Copy」ボタンをクリック→「ソースコード」のテキストを入力する場所で右クリック→「貼り付け」をクリック
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "Hello, world!" << endl;
}
コピー&ペーストができたら、「言語」と書かれた場所の隣に「C++23 (gcc 12.2)」と表示されていることを確認し、「提出」ボタンを押してください。
ページが切り替わり、 と表示されているところが に変われば提出成功です。
- と表示されてしまった場合、正しくコピー&ペーストできているか確認し、再提出してください。
- と表示されてしまった場合、「言語」として「C++23 (gcc 12.2)」が選択されているか確認してください。「C++23 (gcc 12.2)」以外のものが表示されている場合は、「C++23 (gcc 12.2)」を選択し、再提出してください。
補足: 以前の環境では「C++ (GCC 9.2.1)」が使用されていましたが、現在のAtCoderのジャッジ環境では「C++23 (gcc 12.2)」を選択する必要があります。本ページの情報は最新のジャッジ環境に合わせて更新しました。(2025年3月18日)
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
#include <bits/stdc++.h>とusing namespace std;は毎回最初に書く- C++のプログラムはmain関数から始まる
cout << "文字列" << endl;で文字列を出力できる//や/* */でコメントを書ける
| 書き方 | コメントになる場所 |
|---|---|
// |
同じ行の//を書いた場所より後 |
/* */ |
/*と*/の間 |
- プログラムは基本半角文字で書く
プログラムの基本形
まずはプログラムの基本形について学びましょう。次のプログラムは何もしないプログラムです。
この形式は今後解説するプログラムのほぼ全てに登場しますが、暗記する必要はありません。
#include <bits/stdc++.h>
using namespace std;
int main() {
}
このプログラムについて知っておくべきことは、次で説明する「main関数」についてのみです。
main関数
C++のプログラムはmain関数から始まります。上のプログラムでは4行目から5行目までがmain関数です。
int main() {
}
C++のプログラムを起動すると、main関数の{の次の行から実行され、それに対応する}に辿り着くとプログラムを終了します。
このプログラムではmain関数の{ }の中に何も書いていないので、何もせずにプログラムは終了します。
今後のプログラムでは基本的にmain関数の中だけを考えれば良いです。自分でプログラムを書く場合、main関数の外の部分はコピー&ペーストしましょう。
main関数の外の部分についての詳細は第4章で説明しますが、このページの末尾の「細かい話」で簡単に説明しています。気になる人は読んでみてください。
読むのが面倒な人は「プログラムの最初にとりあえず書く必要があるもの」くらいの認識で良いです。
出力
最初に提出したプログラムの詳細を見てみましょう。
このプログラムは「Hello, world!」という文字列を出力する(画面に表示する)プログラムです。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "Hello, world!" << endl;
}
実行結果
Hello, world!
先程述べた通り、main関数の中だけに注目しましょう。このプログラムのmain関数の中には次の1行のプログラムが書かれています。
cout << "Hello, world!" << endl;
この行が出力を行うプログラムです。この行について以下で詳しく説明します。
cout
C++で文字列を出力するには cout(しーあうと) を使います。
出力する文字列を指定している部分は"Hello, world!"の部分です。
C++プログラムの中で文字列を扱う場合、" "で囲う必要があります。endlは改行を表しています。
"Hello, world!"とendlというデータを、<<でcoutに送っていくイメージと覚えると良いでしょう。
endlはの4文字目は「数字の1」ではなく「アルファベットのl(小文字のL)」です。
文字列 という言葉は聞き馴染みが無いかもしれませんが、単に文字のことだと思っておけば良いです。詳しくは「1.12.文字列と文字」で扱います。
セミコロン
行の一番最後には;(セミコロン)が必要です。C++では、大抵の行の一番最後にはセミコロンが必要になります。どの行にセミコロンが必要でどの行に不要なのかは新しい文法を学んだ際に適宜見ていって下さい。
セミコロンが必要なところで書き忘れるとエラーになるので、注意しましょう。
別の文字列の出力
別の文字列を出力したい場合、次のように" "の中身を変えます。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "こんにちは世界" << endl;
}
実行結果
こんにちは世界
複数の出力
出力を複数回行うこともできます。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "a";
cout << "b" << endl;
cout << "c" << "d" << endl;
}
実行結果
ab cd
このプログラムのポイントは2点です。
まず、5行目で改行を表すendlを出力していないため、aの後に改行がされずにabと出力されます。
次に、7行目でcout << "c" << "d"と書くことで、cdと出力することができます。この書き方を知っているとプログラムを短く書けることがあるので覚えておきましょう。
数値の出力
数値を出力するときは、" "を使わずに、直接書くことでも出力できます。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << 2525 << endl;
}
実行結果
2525
コメント
コメントは人間が「プログラムがどういう動作をしているか」等のメモ書きをプログラム中に残しておくための機能です。
プログラムとしての意味はないので、書いても動作に影響はありません。
例を見てみてみましょう。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "Hello, world!" << endl; //Hello, worldと表示
/*ここも
コメント*/
}
実行結果
Hello, world!
コメントには二種類の書き方があります。
| 書き方 | コメントになる場所 |
|---|---|
// |
同じ行の//を書いた場所より後 |
/* */ |
/*と*/の間 |
コメントを使わなくてもプログラムは書けますが、今後プログラム例の中で使うことがあるため、覚えておいて下さい。
コメントアウト
一時的に実行させたくない部分をコメントにしてしまうことで、その部分のプログラムを無効化するというテクニックがあります。このテクニックは コメントアウト と呼ばれ、よく使われています。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "Hello" << endl;
// cout << "World" << endl;
}
実行結果
Hello
6行目の処理はコメント扱いされるので、"World"は出力されません。
// cout << "World" << endl;
"World"と出力させたくなった場合もコメントを解除する(//を消す)だけなので、書き直す手間が省けます。
注意点
半角文字と全角文字
基本的にC++プログラムの中に「全角文字」(あいう12 等)が入り込むとエラー(AtCoderではCE)になってしまいます。
プログラムを書くときは必ず「半角文字」(abc12 等)で書くようにしましょう。
特に全角スペース「 」が入り込んでしまった場合、発見が難しくなってしまうので気をつけましょう。
ただし、" "の中とコメント内では全角文字を使うことができます。
コメントで全角文字を使った後、半角入力に戻し忘れて全角文字を紛れ込ませてしまう、というミスに気をつけましょう。
細かい話
細かい話なので、飛ばして問題を解いても良いです。
#include <bits/stdc++.h>
#include <bits/stdc++.h>はC++の機能を「全て」読み込むための命令です。例えばすでに紹介したcoutやendlは#include <bits/stdc++.h>によって読み込まれた機能です。
今後の解説で出てくるC++の機能の多くは#include <bits/stdc++.h>と書くことで利用できるようになります。これを書かずに読み込みが必要な機能を使った場合、エラーが発生します。
機能は個別に読み込むこともできます。このページで用いたcoutとendlだけであれば、#include <iostream>と書くことによって読み込めます。
ただし、はじめのうちは機能の読み込み忘れによるエラーで詰まってしまうことがよくあるので、#include <bits/stdc++.h>を使って一括で読み込むことをおすすめします。
なお、#include <bits/stdc++.h>は業務におけるプログラミングでは推奨されないことがありますが、競技プログラミングやAPG4bで利用する場合は全く問題ありません。
bits/stdc++.hに関して詳しくは4.01.includeディレクティブおよびトップページの「bits/stdc++.hに関するQ&A」を読んでください。
using namespace std;
using namespace std;はプログラムを短く書くための機能です。#includeで読み込んだC++の機能を利用するためには、通常はstd::coutやstd::endlのようにstd::をはじめに付ける必要があります。
using namespace std;を利用すると、このstd::を省略して書くことができます。
なお、using namespace std;も業務におけるプログラミングでは推奨されないことがありますが、競技プログラミングやAPG4bで利用する場合は全く問題ありません。
これについて詳しくは4.02.名前空間を読んでください。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- スペース・改行・インデントを使ってプログラムを見やすくする
- プログラムは「書く→実行→正しく動作することを確認」で初めて完成と言える
- コンパイルエラーは文法のエラーで、プログラムは実行されない
- 実行時エラーは内容のエラーで、プログラムは強制終了される
- 論理エラーは内容のエラーで、プログラムは正しく動いているように見えてしまう
- エラーは「実行して動作を確認する」「Webで検索する」等して修正する
- エラーの大まかな発生箇所は
./Main.cpp:行:文字目: errorからわかる - エラーメッセージが複数表示された場合は最初のエラーから直す
プログラムの書き方
プログラム中のスペースと改行、およびインデントについて説明します。
これらを使ってプログラムを読みやすくしておくと、エラーが発生した時に修正しやすくなります。
スペースと改行
C++では、基本的にスペースと改行は同じ意味になります。
また、どちらも省略できることが多いです。
以下の2つプログラムは全く同じ意味になります。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "a";
cout << "b" << endl;
cout << "c" << "d" << endl;
}
#include <bits/stdc++.h>
using namespace std;int main(){cout<<"a";cout<<"b"<<endl;cout<<"c"<<"d"<<endl;}
実行結果
ab cd
詰め込んであるプログラムは読みづらいので、スペースと改行を多く使って読みやすく書くのが一般的です。
スペースと改行の使い方に決まったルールはありません。一例としてサンプルプログラムを参考にしてください。
インデント
行のはじめにある連続したスペースのことをインデントと言います。
スペースとインデントでプログラムの動作が変わることはありません。プログラムを見やすくするために行います。
インデントはキーボードのTabキーを押して行います。TabキーはQキーの隣にあります。
#include <bits/stdc++.h>
using namespace std;
int main() {
//←インデント
cout << "こんにちは世界" << endl;
}
基本的に{が出てきたら一段インデントし、}が出てきたら一段戻します。
また、元々一行に書いていたプログラムが長くなった場合は、改行してインデントすることがあります。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
<< "abcdefghijklmnopqrstuvwxyz" // 長いので改行してインデント
<< endl;
}
インデントの幅はプログラムを書いている環境により異なり、スペース2個から8個分であることが多いです。
どの程度の幅を使うかは基本的に自由ですが、プログラムを読みやすくするにはインデントの幅が統一されていることが重要です。
この教材では、AtCoderのコードテストページの設定に合わせて、インデントの幅をスペース2個分にしています。
今後複雑なプログラムを書くようになった場合、インデントをしているかどうかで大きく読みやすさが変わってきます。
サンプルプログラムを参考にしっかりインデントをするようにしましょう。
プログラムのエラー
プログラムは書き終わったら完成ではありません。動かしてみてその動作が正しいことを確認して、はじめて完成と言えます。
しかし書き終えたばかりのプログラムを実行しようとすると、たいてい何らかのエラーが発生します。そのときにエラーの原因を理解して修正できることもプログラマーの重要なスキルです。
プログラムには主に3つのエラーがあります。
- コンパイルエラー
- 実行時エラー
- 論理エラー
それぞれについて説明します。
コンパイルエラー
コンパイルエラーとは、書いたプログラムの文法にミスがあるときに発生するエラーです。
全角文字がプログラム中に入り込んだり、文末の;を忘れたときなどにはコンパイルエラーになります。
プログラミング言語では「文法」が厳密に決められています。
日本語などの人間が使う言語では、文法的に少し崩れた文でも意図が通じますが、プログラミング言語ではそうはいきません。
コンパイルエラーが起きた場合、プログラムは一切動作しません。
実行時エラー
「プログラムを動かす」ことを「プログラムを実行する」といいます。
実行時エラーとは、プログラムの文法に間違いはなかったが、内容に致命的な間違いがあったときに発生するエラーです。
具体的には3÷0のように、0で割り算を行ってしまった場合などに発生します。
スマホアプリやゲーム等が強制終了してしまったとき、多くの場合実行時エラーが発生しています。
実行時エラーが起きた場合、実行時エラーが起きる直前までプログラムは動作しますが、エラー以降は動かなくなってしまいます。
論理エラー
論理エラーとは、プログラムは一見正しく動作しているが、その動作が実は正しくないときに発生するエラーです。
例えば、「300円のクッキーと100円のアメを買ったときに払うお金」を計算するプログラムでは300 + 100と計算するべきですが、間違って300 - 100としてしまった場合などは論理エラーに当たります。
論理エラーは勘違いで生まれたり、タイピングのミスで発生したりと様々です。
論理エラーは一見問題なくプログラムが動作してしまうため、発見することが難しくなりやすいです。
エラーの直し方
実行してエラーや出力を確認→プログラムを修正→実行してエラーや出力を確認→... を繰り返すことが基本的な流れです。
エラーメッセージが表示される場合は、そのメッセージをコピー&ペーストしてWeb検索してみるのも手です。
特にコンパイルエラーに関しては、エラーメッセージで検索すると分かることが多々あります。
調べてみてもよくわからない場合は、わかりそうな人に質問するのも良いでしょう。
コンパイルエラーの例
コンパイルエラーのうち、よくある3つの例を紹介します。
コンパイルエラーの内容は英語で表示されますが、英語が読める必要はありません。
エラーメッセージのパターンからなんとなく原因が推測できれば十分です。
全角スペース
全角スペースを紛れ込ませてしまうケースです。
次のプログラムでは、coutの前に全角スペースが紛れ込んでいます。
#include <bits/stdc++.h>
using namespace std;
int main() {
//↓に全角スペース
cout << "Hello, world!" << endl;
}
コンパイルエラー
./Main.cpp:6:1: error: stray ‘\343’ in program cout << "Hello, world!" << endl; ^ ./Main.cpp:6:1: error: stray ‘\200’ in program ./Main.cpp:6:1: error: stray ‘\200’ in program
error: stray ‘\343’ in program(エラー: ‘\343’がプログラム中に紛れ込んでいます)というエラーメッセージが表示されています。
全角スペースのコンパイルエラーでは、stray ‘\343’ in programやstray ‘\200’ in programと表示されるのが特徴です。
多くの場合、エラーメッセージがどこに全角スペースが入っているのかも教えてくれます。
上記のケースでは./Main.cpp:6:1:と書いてあり、6行目の1文字目にエラーがあることがわかります。
このように、エラーの発生箇所は./Main.cpp:行:文字目: errorを読めば特定できます。
また、エラーメッセージの2行目に
cout << "Hello, world!" << endl; ^
と書いてあり、coutの前に全角スペースがあることが視覚的にもわかります。
ただし、エラーメッセージが示す位置は少しずれることもあるので注意してください。
セミコロン忘れ
セミコロン;が必要な行の末尾にセミコロンを付け忘れるケースです。
次のプログラムでは、endlの後にセミコロンを付けるのを忘れてしまっています。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "Hello, world!" << endl
}
コンパイルエラー
./Main.cpp: In function ‘int main()’: ./Main.cpp:6:1: error: expected ‘;’ before ‘}’ token } ^
error: expected ‘;’ before ‘}’ token(エラー: ‘}’トークンの前に‘;’が予期されます)というエラーメッセージが表示されています。
セミコロン忘れのコンパイルエラーでは、expected ‘;’ before ...というメッセージが表示されるのが特徴です。
少しわかりにくいですが、このエラーメッセージは「エラーが発生した次の行」を指し示しています。
上記のケースでは./Main.cpp:6:1: error:とあり、セミコロンを忘れた次の行である6行1文字目}の位置を指し示しています。
大量のエラー・謎のエラー
一つのミスで大量のエラーメッセージが出てくることもあります。また、エラーメッセージが直接的な原因を示していないことがあります。
その場合は一番最初のエラーが指し示している場所を見て、原因を推測しましょう。
次のプログラムではendlの直前の<<を<と書いてしまっただけのミスにより、大量に謎のエラーメッセージが表示されています。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "hello" < endl;
}
コンパイルエラー
./Main.cpp: In function ‘int main()’:
./Main.cpp:5:19: error: no match for ‘operator<’ (operand types are ‘std::basic_ostream<char>’ and ‘<unresolved overloaded function type>’)
cout << "hello" < endl;
^
In file included from /usr/include/c++/5/regex:61:0,
from /usr/include/x86_64-linux-gnu/c++/5/bits/stdc++.h:108,
from ./Main.cpp:1:
/usr/include/c++/5/bits/regex.h:1426:5: note: candidate: template<class _Bi_iter> bool std::operator<(const std::sub_match<_BiIter>&, const typename std::iterator_traits<_Iter>::value_type&)
operator<(const sub_match<_Bi_iter>& __lhs,
^
/usr/include/c++/5/bits/regex.h:1426:5: note: template argument deduction/substitution failed:
./Main.cpp:5:21: note: ‘std::basic_ostream<char>’ is not derived from ‘const std::sub_match<_BiIter>’
cout << "hello" < endl;
^
In file included from /usr/include/c++/5/regex:61:0,
from /usr/include/x86_64-linux-gnu/c++/5/bits/stdc++.h:108,
...
大量のエラーメッセージが表示された場合、とりあえず一番最初のエラーメッセージだけを見ると良いです。
一番最初のエラーメッセージだけを抜き出すと次のように表示されています。
./Main.cpp: In function ‘int main()’:
./Main.cpp:5:19: error: no match for ‘operator<’ (operand types are ‘std::basic_ostream<char>’ and ‘<unresolved overloaded function type>’)
cout << "hello" < endl;
^
error: no match for ‘operator<’...と書いてありますが、このエラーメッセージはあまり参考になりません。
このように、エラーメッセージが直接的な原因を示していないこともあります。
エラーメッセージの内容がよくわからない場合でも、エラーの発生箇所は参考になることが多いです。
この場合は./Main.cpp:5:19: error:と書いてあるので、5行目19文字目である次の部分でエラーが発生していることがわかります。
cout << "hello" < endl;
^
エラーの発生箇所をよく見ると、<<を<と書き間違えていることがわかります。
コンパイルエラーを直す際は、エラーの発生箇所から原因を推測することも大切です。
コンパイルエラー集
付録3.コンパイルエラー集にその他のよくあるエラーについてまとめました。
コンパイルエラーの原因がわからない時に見てみてください。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
| 演算子 | 計算内容 |
|---|---|
+ |
足し算 |
- |
引き算 |
* |
掛け算 |
/ |
割り算 |
% |
割った余り |
- 整数同士の割り算は小数点以下切り捨て
四則演算
C++プログラムで簡単な計算をする方法を見ていきましょう。
次のプログラムは上から順に、「足し算」「引き算」「掛け算」「割り算」を行っています。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << 1 + 1 << endl; // 2
cout << 3 - 4 << endl; // -1
cout << 2 * 3 << endl; // 6
cout << 7 / 3 << endl; // 2
}
実行結果
2 -1 6 2
これらの記号+, -, *, /のことを算術演算子といいます。
3 - 4が-1になっている通り、負の値も計算できます。
*が「掛け算」で、/が「割り算」です。
7 / 3が2になっていることに注意して下さい。C++では、整数同士で割り算した場合、結果は小数点以下を切り捨てした値になります。(7 ÷ 3 = 2.33... → 2, -7 ÷ 3 = -2.33... → -2)
小数点以下を切り捨てないで計算してほしい場合、7.0 / 3.0のように.0をつけます。同様に7.0 / 3.5のような計算も行えます。
剰余演算
もう一つ重要な算術演算子として % があります。この演算子は「割ったときの余り」を計算します。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << 7 % 3 << endl; // 1
cout << 4 % 5 << endl; // 4
}
実行結果
1 4
7 ÷ 3 = 2 あまり 1
4 ÷ 5 = 0 あまり 4
となるため、このプログラムの出力は1と4になります。
演算子の優先順位
演算子には優先順位があります。
例えば1 + 2 * 3のような式を計算する場合、先に2 * 3が計算された後、1が足され、計算結果は7になります。
1 + 2 * 3 → 1 + 6 → 7
*は+よりも優先順位が高いというわけです。
C++の算術演算子の優先順位は、一般的な数学の優先順位と同じです。%は*や/と同じ優先順位になります。
| 優先順位 | 高い | 低い |
|---|---|---|
| 演算子 | * / % |
+ - |
( )を使って優先順位を変えることもできます。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << (1 + 2) * 3 << endl; // 9
}
実行結果
9
( )の中が先に計算され、(1 + 2) * 3 → 3 * 3となり結果は9になります。
なお、5 / 2 * 3のように同じ優先順位の演算子が並んでいる式は、基本的に左の演算子から順に計算されます。
注意点
除算の順序
割り算/のある整数同士の計算では、切り捨てが行われるタイミングの違いで結果が異なることがあります。
例えば3÷2×4を計算する場合、書き方によって2つの計算結果が考えられます。
3 / 2 * 4→1 * 4→43 * 4 / 2→12 / 2→6
多くの場合、割り算はできるだけ後の方で行うようにしたほうが正しい結果になります。
ゼロ除算
0で割ると実行時エラーが発生します。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << 3 / 0 << endl;
}
終了コード
136
3 % 0のように0で剰余演算%をした場合も同様に実行時エラーになります。
コードテスト上で表示される終了コードは136になります。
コードテスト以外の環境で実行した場合、Floating point exceptionと表示されることもあります。
なお、0 / 3や0 % 3のように、割られる数が0の場合は問題なく計算できることに注意してください。どちらも結果は0になります。
細かい話
細かい話なので、飛ばして問題を解いても良いです。
負の数の剰余
剰余演算A % Bを行う時にAまたはBが負の数の場合、計算結果は以下のようになります。|A|, |B|はそれぞれの絶対値を表すとします。
- Aが正のとき:|A|%|B|
- Aが負のとき:-(|A|%|B|)
つまりBの正負に関わらず、計算結果はAの正負と一致します。
より正確に言うと、C++の剰余演算子は
(A / B) * B + (A % B)とAが等しくなるように定義されており、結果的にAの正負と一致します。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 変数は「メモ」
=は代入- 「データの種類」のことを型という
| 型 | 書き込むデータの種類 |
|---|---|
| int | 整数 |
| double | 小数 |
| string | 文字列 |
変数
変数という機能について見ていきましょう。変数は「メモ」だと考えて下さい。
一度使ったデータをまた後で使いたいときのために、名前を付けてメモをして覚えておくというものです。

例を見てみましょう。
#include <bits/stdc++.h>
using namespace std;
int main() {
int name;
name = 10;
cout << name << endl; // 10
cout << name + 2 << endl; // 10 + 2 → 12
cout << name * 3 << endl; // 10 * 3 → 30
}
実行結果
10 12 30
宣言
変数を使うには、最初に宣言を行う必要があります。
変数を宣言するときは、「データの種類」と「変数の名前」を指定します。
int name;
「整数」のデータを書き込む変数を「name」という名前で宣言しています。
intの部分がデータの種類が整数だと指定している部分です。
「データの種類」のことを型(かた)と言い、「変数の名前」のことを変数名と言います。型についての詳しい説明はこの節の後半で行います。
また、「データ」のことを値(あたい)と言うこともあります。今後この表現を使うこともあるので覚えておきましょう。
代入
宣言した変数にデータをメモするには、以下のように=を使って代入をします。
name = 10;
これでnameという名前の変数に10が書き込まれます。
C++の =は代入 であって、「等しい」という意味ではないということに注意して下さい。
読み込み
main関数の最後の3行で変数にメモした値を読み込んで出力しています。
cout << name << endl; // 10 cout << name + 2 << endl; // 10 + 2 → 12 cout << name * 3 << endl; // 10 * 3 → 30
変数の値を読み書きすることを「変数にアクセスする」ということもあります。
変数の初期化
変数の宣言と代入は同時に行うこともできます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int name = 10;
cout << name << endl;
}
実行結果
10
変数を宣言した後の最初の代入を初期化といいます。上のプログラムで変数nameは10に初期化されています。
変数はコピーされる
変数1 = 変数2と書いた場合、変数の値そのものがコピーされます。
その後にどちらかの変数の値が変更されても、もう片方の変数は影響を受けません。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 10;
int b;
b = a; // aの値がコピーされ、bに10が代入される
a = 5; // aの値は5に書き換わるが、bは10のまま
cout << a << endl; // 5
cout << b << endl; // 10
}
実行結果
5 10
変数bが10のままであることに注意してください。
7行目から9行目の処理を図で説明すると以下のようになります。

変数を同時に宣言
変数の宣言時に,を間に入れることで複数の変数を同時に宣言することもできます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 10, b = 5;
cout << a << endl;
cout << b << endl;
}
実行結果
10 5
上のプログラムは次のように書いた場合と同じ意味になります。
int a = 10; int b = 5;
変数名のルール
変数名は基本的に自由につけることができますが、一部の名前を変数名にしようとするとコンパイルエラーになります。
利用できない変数名
以下の条件に該当する名前は変数名にできません。
- 数字で始まる名前
_以外の記号が使われている名前- キーワード(C++が使っている一部の単語)
以下は変数名にできない名前の例です。
int 100hello; // 数字で始まる名前にはできない int na+me; // 変数名に+を使うことはできない int int; // intはキーワードなので変数名にできない
以下のような名前は変数名にできます。
int hello10; // 2文字目以降は数字にできる int hello_world; // _ は変数名に使える
無意識にキーワードを変数名にしてしまうことはあまり無いので、キーワードに関してはあまり気にしなくても良いです。気になる人は「C++ キーワード」等でWebで検索してみてください。
同じ名前の変数は宣言できない
同じ名前の変数を複数宣言することはできません。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 0;
int a = 5; // この行でコンパイルエラーになる
cout << a << endl;
}
コンパイルエラー
./Main.cpp: In function ‘int main()’:
./Main.cpp:7:9: error: redeclaration of ‘int a’
int a = 5; // この行でコンパイルエラーになる
^
./Main.cpp:5:9: note: ‘int a’ previously declared here
int a = 0;
^
error: redeclaration of ‘int a’(エラー: ‘int a’の再宣言)というエラーメッセージが表示されています。
例外的に同じ名前の変数を宣言する方法もありますが、それについては「1.08.変数のスコープ」で説明します。
型
int以外にもC++には様々な型があります。ここでは重要な3つの型だけを紹介します。
| 型 | 書き込むデータの種類 |
|---|---|
| int | 整数 |
| double | 小数(実数) |
| string | 文字列 |
#include <bits/stdc++.h>
using namespace std;
int main() {
int i = 10;
double d = 0.5;
string s = "Hello";
cout << i << endl;
cout << d << endl;
cout << s << endl;
}
実行結果
10 0.5 Hello
異なる型同士の計算
異なる型同士の計算では型変換が行われます。
例えば、int型とdouble型の計算結果はdouble型になります。
ただし、変換できない型同士は計算はコンパイルエラーになります。
#include <bits/stdc++.h>
using namespace std;
int main() {
int i = 30;
double d = 1.5;
string s = "Hello";
cout << i + d << endl; // 31.5
cout << i * d << endl; // 45
cout << 45 / 2 << endl; // 22 小数点以下切り捨て
cout << i * d / 2 << endl; // 22.5 小数点以下も残る
/*
以下の処理はコンパイルエラー
cout << s + i << endl; // string型とint型
cout << s * i << endl; // string型とint型
cout << s + d << endl; // string型とdouble型
*/
}
実行結果
31.5 45 22 22.5
計算の途中にdouble型のデータが入ってくるかどうかで、小数点以下を切り捨てるかどうかが変わってきます。
string型とint型、string型とdouble型は変換できない型の組み合わせなのでコンパイルエラーになります。
異なる型同士の代入
異なる型同士の代入でも型変換は行われます。
計算と同様、変換できない型同士の代入はコンパイルエラーになります。
#include <bits/stdc++.h>
using namespace std;
int main() {
int i = 10;
double d = i; // doubleとintは互いに代入できる(小数点以下切り捨て)
string s = "Hello";
i = s; // int型とstring型は互いに代入できない
cout << i << endl;
}
コンパイルエラー
./Main.cpp: In function ‘int main()’:
./Main.cpp:9:5: error: cannot convert ‘std::string {aka std::basic_string<char>}’ to ‘int’ in assignment
i = s; // int型とstring型は互いに代入できない
^
「エラー:代入時に‘string’を‘int’に変換できません」というような内容のエラーメッセージが表示されています。
double型とint型は変換できる型同士なので互いに代入できます。double型をint型に変換したときは小数点以下切り捨てになります。
int型やdouble型の型変換については3.01.数値型で詳しく説明します。
細かい話
細かい話なので、飛ばして問題を解いても良いです。
初期化する前の変数の値
初期化する前のint型やdouble型の変数の値を読み込んだ場合、どのような値になっているか分かりません。
次のプログラムは初期化する前の変数の値を読み込む例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
int name;
cout << name << endl; //なにが出力されるかわからない
}
変数の初期化をし忘れてしまい、このプログラムのような状況になることがしばしばあります。
変数の初期化し忘れによるバグ(プログラムのミス)を防ぎたい場合、すべての変数を宣言時に適当な値で初期化しておくのも一つの手です。
より厳密には、初期化する前の変数の値は基本的に宣言するより前の処理内容で決まります。
その関係で、単純なプログラムでは初期化しなくても変数の値は0になっていることが多いです。
なお、string型の変数は初期化を行わなかった場合は自動的に""で初期化されます。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- プログラムは上から下へ順番に実行される
cin >> 変数で入力を受け取ることができる- スペースと改行で区切られて入力される
プログラムの実行順序
基本的にプログラムは上から下へ順番に実行されます。
次のプログラムを見てみて下さい。
#include <bits/stdc++.h>
using namespace std;
int main() {
int name;
// nameに10を代入
name = 10;
cout << name << endl; // 10
// nameに5を代入
name = 5;
cout << name << endl; // 5
}
実行結果
10 5
このプログラムが実行される様子を表したのが次のスライドです。
1回目の出力の時点ではnameに10が書かれていますが、その後name = 5;でnameのデータを5に上書きしているため、2回目の出力では5が出力されます。
「プログラムが実行される順序」を意識してプログラムを読み書きしましょう。
入力
プログラムの実行時にデータの入力を受け取る方法を見ていきましょう。
「入力機能」を使うことにより、プログラムを書き換えなくても様々な計算を行えるようになります。
入力を受け取るには cinと>> を使います。
次のプログラムは、入力として受け取った数値を10倍にして出力するプログラムです。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a;
// 変数aで入力を受け取る
cin >> a;
cout << a * 10 << endl;
}
入力
5
実行結果
50
ここではint型の変数aで入力を受け取っています。
実際に入力を受け取っているのは次の部分です。
cin >> a;
coutとは>>の向きが逆になっていることに注意して下さい。
cout << 10; cin >> a;
- 出力は
coutに<<でデータを送っている - 入力は
cinから変数に>>でデータを送っている
というようなイメージだと覚えておくと良いでしょう。
整数以外のデータの入力
整数以外のデータを受け取りたいときは、そのデータの種類に合わせた型の変数を使います。
#include <bits/stdc++.h>
using namespace std;
int main() {
string text;
double d;
cin >> text;
cin >> d;
cout << text << ", " << d << endl;
}
入力
Hello 1.5
実行結果
Hello, 1.5
このプログラムが実行される様子を表したのが次のスライドです。
繋げて入力
coutと同じように、cinも>>を繋げて入力を受け取ることができます。
入力が複数ある場合は、スペースか改行で区切られていれば分解して入力してくれます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a, b, c;
cin >> a >> b >> c;
cout << a * b * c << endl;
}
入力
2 3 4
実行結果
24
aに2、bに3、cに4が入力されています。
問題
リンク先の問題を解いてください。
AtCoder Beginner Contestの問題
AtCoderではAtCoder Beginner Contest (ABC)というコンテストを定期的に開催しています。
そのコンテストで出題される問題の中には、ここまでで学んだ知識だけで解けるものもあります。
ここではその中からいくつか紹介します。練習問題では物足りない人は解いてみてください。
易しめ
難しめ
「難しめ」の問題はもっとプログラムの知識がつくと簡単になりますが、ここまでで学んだ知識のみで解こうとすると少し工夫が必要になります。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- if文を使うと「ある条件が正しい時だけ処理をする」というプログラムが書ける
- else句を使うと「条件式が正しくなかった時」の処理を書ける
if (条件式1) {
処理1
}
else if (条件式2) {
処理2
}
else {
処理3
}
- 比較演算子
| 演算子 | 意味 |
|---|---|
x == y |
xとyは等しい |
x != y |
xとyは等しくない |
x > y |
xはyより大きい |
x < y |
xはyより小さい |
x >= y |
xはy以上 |
x <= y |
xはy以下 |
- 論理演算子
| 演算子 | 意味 | 真になる時 |
|---|---|---|
!(条件式) |
条件式の結果の反転 | 条件式が偽 |
条件式1 && 条件式2 |
条件式1が真 かつ 条件式2が真 | 条件式1と条件式2のどちらも真 |
条件式1 || 条件式2 |
条件式1が真 または 条件式2が真 | 条件式1と条件式2の少なくとも片方が真 |
if文
if文を使うと、ある条件が正しい時だけ処理をするというプログラムが書けるようになります。
書き方は次のようになります。
if (条件式) {
処理
}
条件式が正しい時、{ から } の間の処理が実行され、条件式が正しくないとき、処理は飛ばされます。
次の例では、入力の値が10より小さければ「xは10より小さい」と出力した後「終了」と出力します。また、入力の値が10より小さくなければ「終了」とだけ出力します。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x;
cin >> x;
if (x < 10) {
cout << "xは10より小さい" << endl;
}
cout << "終了" << endl;
}
入力1
5
実行結果1
xは10より小さい 終了
入力2
15
実行結果2
終了
この例では、まず変数xに整数のデータを入力しています。
int x; cin >> x;
重要なのはその後です。
if (x < 10) {
cout << "xは10より小さい" << endl;
}
この部分は、「もしx < 10(xが10より小さい)なら、xは10より小さいと出力する」という意味になります。
最後にcout << "終了" << endl;を実行して終了と出力し、プログラムは終了します。
xが10より小さく無い場合、次の処理は飛ばされます。
{
cout << "xは10より小さい" << endl;
}
そのため、2つ目の実行例では終了とだけ出力されています。
if文のように、何かの条件で処理が別れることを条件分岐といいます。
また、「条件式が正しい」ことを条件式が真、「条件式が正しくない」ことを条件式が偽といいます。以降からこの表現を使います。
比較演算子
条件式のところには、多くの場合、比較演算子を使って条件を書きます。
比較演算子は以下の6つです。
| 演算子 | 意味 |
|---|---|
x == y |
xとyは等しい |
x != y |
xとyは等しくない |
x > y |
xはyより大きい |
x < y |
xはyより小さい |
x >= y |
xはy以上 |
x <= y |
xはy以下 |
「より大きい」「より小さい」を表す記号は数学と同じです。
「等しい」は=を2つ繋げたものになり、「等しくない」は!が=の前につきます。
「以上」「以下」は、数学では「≧」「≦」のように=を下につけますが、C++では>=,<=のように右に=をつけます。
次のプログラムは、入力された整数値がどんな条件を満たしているかを出力するプログラムです。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x;
cin >> x;
if (x < 10) {
cout << "xは10より小さい" << endl;
}
if (x >= 20) {
cout << "xは20以上" << endl;
}
if (x == 5) {
cout << "xは5" << endl;
}
if (x != 100) {
cout << "xは100ではない" << endl;
}
cout << "終了" << endl;
}
入力1
5
実行結果1
xは10より小さい xは5 xは100ではない 終了
入力2
100
実行結果2
xは20以上 終了
論理演算子
条件式の中にはもっと複雑な条件を書くこともできます。そのためには論理演算子を使います。
| 演算子 | 意味 | 真になる時 |
|---|---|---|
!(条件式) |
条件式の結果の反転 | 条件式が偽 |
条件式1 && 条件式2 |
条件式1が真 かつ 条件式2が真 | 条件式1と条件式2のどちらも真 |
条件式1 || 条件式2 |
条件式1が真 または 条件式2が真 | 条件式1と条件式2の少なくとも片方が真 |
#include <bits/stdc++.h>
using namespace std;
int main() {
int x, y;
cin >> x >> y;
if (!(x == y)) {
cout << "xとyは等しくない" << endl;
}
if (x == 10 && y == 10) {
cout << "xとyは10" << endl;
}
if (x == 0 || y == 0) {
cout << "xかyは0" << endl;
}
cout << "終了" << endl;
}
入力1
2 3
実行結果1
xとyは等しくない 終了
入力2
10 10
実行結果2
xとyは10 終了
入力3
0 8
実行結果3
xとyは等しくない xかyは0 終了
「前の条件が真でないとき」の処理
else句
else句は、if文の後に書くことで「if文の条件が偽の時」に処理を行えるようになります。
書き方は次のようになります。
if (条件式1) {
処理1
}
else {
処理2
}
次のプログラムは入力の値が10より小さければ「xは10より小さい」と出力し、そうでなければ「xは10より小さくない」と出力します。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x;
cin >> x;
if (x < 10) {
cout << "xは10より小さい" << endl;
}
else {
cout << "xは10より小さくない" << endl;
}
}
入力1
5
実行結果1
xは10より小さい
入力2
15
実行結果2
xは10より小さくない
else if
else ifは「『前のif文の条件が偽』かつ『else ifの条件が真』」の時に処理が行われます。
書き方は次のようになります。
if (条件式1) {
処理1
}
else if (条件式2) {
処理2
}
処理2が実行されるのは「条件式1が偽 かつ 条件式2が真」のときになります。
else ifの後に続けてelse ifやelseを書くこともできます。次のプログラムはその例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x;
cin >> x;
if (x < 10) {
cout << "xは10より小さい" << endl;
}
else if (x > 20) {
cout << "xは10より小さくなくて、20より大きい" << endl;
}
else if (x == 15) {
cout << "xは10より小さくなくて、20より大きくなくて、15である" << endl;
}
else {
cout << "xは10より小さくなくて、20より大きくもなくて、15でもない" << endl;
}
}
入力1
5
実行結果1
xは10より小さい
入力2
30
実行結果2
xは10より小さくなくて、20より大きい
入力3
15
実行結果3
xは10より小さくなくて、20より大きくなくて、15である
入力4
13
実行結果4
xは10より小さくなくて、20より大きくもなくて、15でもない
注意点
よくあるミス
==のつもりで=とだけ書いてしまわないように注意しましょう。
次のプログラムは「xが10と等しいか」を判定するプログラムの典型的なミスです。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x = 5;
if (x = 10) {
cout << "xは10" << endl;
}
}
実行結果
xは10
if (x = 10)のif文はxがどんな数値でも真だと判定されます。ハマりどころなので覚えておきましょう。なぜそうなるかは次の節で説明します。
細かい話
細かい話なので、飛ばして問題を解いても良いです。
{ } の省略
処理の部分が1文しか無い場合は、{ }を省略することができます。
if (x < 10) cout << "xは10より小さい" << endl;
「1文」とは、「セミコロンが1つだけで十分な処理」だと思えば良いです。
つまり、以下のような書き方は思った通りには動きません。
if (x < 10) cout << "xは10より小さい" << endl; cout << "Hello!" << endl;
これは次のように書いたのと同じ意味になります。
if (x < 10) {
cout << "xは10より小さい" << endl;
}
cout << "Hello!" << endl;
if文のネスト
if文の中にif文を入れることをif文のネストと言います。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x, y;
cin >> x >> y;
if (x == 10) {
cout << "xは10" << endl;
if (y == 10) {
cout << "yも10" << endl;
}
}
cout << "終了" << endl;
}
入力
10 10
実行結果
xは10 yも10 終了
入力
5 10
実行結果
終了
問題
リンク先の問題を解いてください。
ABCの問題
ここまでの知識だけで解ける問題をAtCoder Beginner Contestから再び紹介します。練習問題だけでは物足りない人は解いてみてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 条件式の結果は真のとき
1に、偽のとき0になる 1をtrueで、0をfalseで表す- bool型は
trueとfalseだけが入る型
| int型の表現 | bool型の表現 | |
|---|---|---|
| 真 | 1 | true |
| 偽 | 0 | false |
条件式の結果
C++では、真のことを数値の1で表現し、偽のことを数値の0で表現します。
条件式の「計算結果」も真のときは1、偽のときは0になります。
次のプログラムは条件式の結果をそのまま出力し、真のときと偽のときでどのような値を取るかを確認しています。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << (5 < 10) << endl; // 真
cout << (5 > 10) << endl; // 偽
}
実行結果
1 0
演算子の優先順位の関係で、条件式を( )で囲まないといけないので注意して下さい。
出力を見てみると、条件が真のときは1、偽のときは0になっていることがわかります。
1 + 1の計算結果が2という数値になること同じように、条件式5 < 10の計算結果は1という数値になるということです。
trueとfalse
条件式の部分に直接1や0を書くこともできます。次のプログラムはその例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
// 1は真を表すのでhelloと出力される
if (1) {
cout << "hello" << endl;
}
// 0は偽を表すのでこのifの中は実行されない
if (0) {
cout << "world" << endl;
}
}
実行結果
hello
先述したとおり、C++では「1と真」「0と偽」はほとんど同じ意味になります。
しかし、「数値としての1と0」なのか、「真偽を表すための1と0」なのかが分かりにくいことがあります。
そのため、真のことを true 、偽のことを false で表すことができるようになっています。
次のプログラムは上のプログラムと同じ動作をします。
#include <bits/stdc++.h>
using namespace std;
int main() {
// 1と書くよりも真だということがわかりやすい
if (true) {
cout << "hello" << endl;
}
// 0と書くよりも偽だということがわかりやすい
if (false) {
cout << "world" << endl;
}
}
bool型
bool型というデータ型があります。この型の変数にはtrueまたはfalseだけが入ります。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x;
cin >> x;
bool a = true;
bool b = x < 10; // xが10未満のときtrue そうでないときfalseになる
bool c = false;
if (a && b) {
cout << "hello" << endl;
}
if (c) {
cout << "world" << endl;
}
}
入力
3
実行結果
hello
このように、条件式の結果など、真偽のデータを変数で扱いたい場合はbool型を使います。
いままでif (条件式)と書いていましたが、基本的にはif (bool型の値)ということになります。
ここまでの話をまとめたのが次の表です。
| int型の表現 | bool型の表現 | |
|---|---|---|
| 真 | 1 | true |
| 偽 | 0 | false |
bool型を使う場面
今まで学んできたものと違い、「bool型がないと書けないプログラム(計算)」はありません。
bool型は基本的に「条件式の結果」や「状態が2つしか無いもの」を扱っていることを明示するために使います。
これができることによる恩恵は今はわかりにくいかもしれませんが、1.15.関数で紹介する機能を使う場合など、bool型を使うことでプログラムがわかりやすくなることがあります。
なお、今後は「真」や「偽」という言葉の代わりにtrueやfalseという言葉を使って説明することがあるので、これらの意味はしっかりと覚えておいてください。
細かい話
細かい話なので、飛ばして問題を解いても良いです。
bool型と数値
実は、0と1以外の数値もbool型の値のように扱うことができます。
その場合、0のときだけfalse、それ以外の数値はすべてtrueになります。
#include <bits/stdc++.h>
using namespace std;
int main() {
bool a = 10; // 10はtrue
bool b = 0; // 0はfalse
cout << a << endl; // 1
cout << b << endl; // 0
// 100はtrue
if (100) {
cout << "hello" << endl;
}
}
実行結果
1 0 hello
if文の節で紹介した==と=を書き間違える典型的なミスは、この「trueとfalse以外の値もbool型のように受け入れてしまう」という性質によって引き起こされています。
a = bという式の「計算結果」はbになります。そのため、if (a = b)はif (b != 0)とほとんど同じ意味になってしまいます。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
{ }で囲われた部分のところをブロックという- 変数が使える範囲のことをスコープという
- 変数のスコープは「変数が宣言されてからそのブロックが終わるまで」
- スコープが重なっている場合は最も内側のブロックで宣言された変数が選ばれる
変数のスコープ
今までmain関数やif文の後には{ }を書いてきました。この{ }で囲った部分のところをブロックといいます。
あるブロックの中で宣言した変数は、それより内側のブロックでしか使えないというルールがあります。そして、その変数が使える範囲のことをスコープといいます。
具体例を見てみましょう。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x = 5; // xのスコープはこの行からmain関数のブロックの終わりまで
if (x == 5) {
int y = 10; // yのスコープはこの行からif文のブロックの終わりまで
cout << x + y << endl;
}
cout << x << endl;
cout << y << endl;
}
コンパイルエラー
In function ‘int main()’:
14:13: error: ‘y’ was not declared in this scope
cout << y << endl;
^
「14:13: error: ‘y’ was not declared in this scope(14行13文字目 エラー: 'y'はこのスコープでは宣言されていません)」というコンパイルエラーが出ています。
変数yは7行目からはじめるif文のブロックで宣言されています。
if (x == 5) {
int y = 10; // yのスコープはこの行からif文のブロックの終わりまで
cout << x + y << endl;
}
しかし、13行目の
cout << y << endl;
はyを宣言したブロックよりも外側にあるので、yを使うことができません。
なお、変数yのスコープ、つまり変数yが使える場所は、「変数が宣言されてからそのブロックが終わるまで」なので、8行目から10行目の間ということになります。
int y = 10; // yのスコープはこの行からif文のブロックの終わりまで
cout << x + y << endl;
}
同じ名前の変数
変数を宣言するブロックが異なれば、同じ名前の変数を宣言することができます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x = 10;
if (x == 5) {
int y = 10;
cout << x + y << endl;
// string y = "hello" 同じブロックに変数yがあるので宣言できない
}
if (x == 10) {
string y = "hello"; // ブロックが違うので変数yを宣言できる
cout << x << y << endl;
}
}
実行結果
10hello
スコープがある理由
スコープがある理由はいくつかありますが、その中から一つ説明します。
スコープがない場合、一度宣言した変数等の名前は別の場所で使えなくなってしまいます。
プログラムの規模が大きくなってくると、その分多くの変数が用いられます。そのため、新しく変数を宣言しようとしたとき、まだ使われていない名前を考えることに手間がかかってしまいます。
スコープがあることで、プログラムの別の部分でどのような名前が使われているかをあまり考えること無く、変数等の名前を決められるようになります。
細かい話
細かい話なので、飛ばして問題を解いても良いです。
スコープが重なっている場合
変数を使える条件は次の2つです。
- 変数を使っている場所より前で宣言されている
- 変数を使っている場所と同じか、より外側のブロックで宣言されている
同じ名前の変数のスコープが重なっていて、候補が複数考えられる場合は次の条件で使う変数が決められます。
- 候補の変数のうち最も内側で宣言されている
例を見てみましょう。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x = 5;
cout << x << endl; // 5
if (x == 5) {
cout << x << endl; // 5
string x = "hello"; // int x = 5;のスコープと重なっている
cout << x << endl; // hello
}
cout << x << endl; // 5
}
実行結果
5 5 hello 5
次の図はこのプログラムの動作を説明したものです。

上のプログラムの8行目のxにおいて、条件1.と条件2.に当てはまるxはint x = 5;だけなので、出力は5になります。
9行目のxにおいて、条件1.と条件2.に当てはまるxはint x = 5;だけなので、出力は5になります。
12行目のxにおいて、条件1.と条件2.に当てはまるのはint x = 5;とstring x = "hello";の2つがありますが、条件3.からstring x = "hello";が選ばれ、出力はhelloになります。
15行目のxにおいて、条件1.と条件2.に当てはまるのは再びint x = 5;だけになるなので、出力は5になります。
この挙動はしばしばバグの原因になります。注意してください。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
x = x + yはx += yのように短く書けるx += 1はx++と書ける(インクリメント)x -= 1はx--と書ける(デクリメント)
複合代入演算子
x = x + 1 のように、同じ変数名が2回現れる代入文では、複合代入演算子を使うとより短く書くことができます。
次のプログラムは、変数xに(1 + 2)を足して出力するだけのプログラムです。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x = 5;
x += 1 + 2;
cout << x << endl; // 8
}
実行結果
8
x += 1 + 2;
は
x = x + (1 + 2);
と同じ意味になります。
+=以外の複合代入演算子
他の算術演算子についても同様のことができます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 5;
a -= 2;
cout << a << endl; // 3
int b = 3;
b *= 1 + 2;
cout << b << endl; // 9
int c = 4;
c /= 2;
cout << c << endl; // 2
int d = 5;
d %= 2;
cout << d << endl; // 1
}
実行結果
3 9 2 1
インクリメントとデクリメント
x = x + 1はx++または++xと書くことができます。このような「1増やす操作」をインクリメントと言います。
x = x - 1はx--または--xと書くことができます。このような「1減らす操作」をデクリメントと言います。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x = 5;
x++;
cout << x << endl; // 6
int y = 5;
y--;
cout << y << endl; // 4
}
実行結果
6 4
このように、プログラムを短く書くための記法のことをシンタックスシュガーと言います。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
補足
この説明を読む前に付録4.ループの裏技repマクロを読んだほうが理解しやすいです。ただし、必須の知識では無いので読まなくても問題ありません。
キーポイント
- while文を使うと繰り返し処理ができる
- 条件式が真のとき処理を繰り返す
while (条件式) {
処理
}
- 「N回処理する」というプログラムを書く場合、「カウンタ変数を0からはじめ、カウンタ変数がNより小さいときにループ」という形式で書く
int i = 0; // カウンタ変数
while (i < N) {
処理
i++;
}
while文
while文を使うと、プログラムの機能の中でも非常に重要な「繰り返し処理」(ループ処理)を行うことができます。
無限ループ
次のプログラムは、「"Hello"と出力して改行した後、"AtCoder"と出力する処理」を無限に繰り返すプログラムです。
#include <bits/stdc++.h>
using namespace std;
int main() {
while (true) {
cout << "Hello" << endl;
cout << "AtCoder" << endl;
}
}
実行結果
Hello AtCoder Hello AtCoder Hello AtCoder Hello AtCoder Hello AtCoder ...(無限に続く)
while文は次のように書き、条件式が真のとき処理を繰り返し続けます。
while (条件式) {
処理
}

先のプログラムでは条件式の部分にtrueと書いているため、無限に処理を繰り返し続けます。
このように、無限に繰り返し続けることを無限ループと言います。
1ずつカウントする
次プログラムは、1から順に整数を出力し続けます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int i = 1;
while (true) {
cout << i << endl;
i++; //ループのたびに1増やす
}
}
実行結果
1 2 3 4 5 6 7 8 ...(無限に1ずつ増えていく)
途中で負の値になったかもしれませんが、なぜそうなるかは3.01.数値型で説明します。
ループ回数の指定
1ずつカウントするプログラムを「1から5までの数を出力するプログラム」に変える場合、次のようにします。
#include <bits/stdc++.h>
using namespace std;
int main() {
int i = 1;
// iが5以下の間だけループ
while (i <= 5) {
cout << i << endl;
i++;
}
}
実行結果
1 2 3 4 5
カウンタ変数は0からN未満まで
5回Helloと出力するプログラムを考えます。
まず一般的でない書き方(やめておいた方が良い書き方)を紹介し、次に一般的な書き方(推奨される書き方)を紹介します。
一般的でない書き方
#include <bits/stdc++.h>
using namespace std;
int main() {
// iを1からはじめる
int i = 1;
// iが5以下の間ループ
while (i <= 5) {
cout << "Hello" << endl;
i++;
}
}
実行結果
Hello Hello Hello Hello Hello
「N回処理をする」というプログラムをwhile文で書く場合、今までは「iを1からはじめ、N以下の間ループする」という形式で書いてきました。
int i = 1;
while (i <= N) {
処理
i++;
}
この形式は一見わかりやすいと感じるかもしれません。
しかし、この書き方はあまり一般的ではなく、次のように書いたほうが良いです。
一般的な書き方
#include <bits/stdc++.h>
using namespace std;
int main() {
// iを0からはじめる
int i = 0;
// iが5未満の間ループ
while (i < 5) {
cout << "Hello" << endl;
i++;
}
}
実行結果
Hello Hello Hello Hello Hello
「N回処理する」というプログラムを書く場合、次のように「iを0からはじめ、iがNより小さいときにループする」という形式で書くのが一般的です。
int i = 0;
while (i < N) {
処理
i++;
}
最初は分かりづらく感じるかもしれませんが、こう書いた方がプログラムをシンプルに書けることが後々増えてくるので、慣れるようにしましょう。
なお、このプログラムの変数iのように、「何度目のループか」を管理する変数のことをカウンタ変数と呼ぶことがあります。
カウンタ変数は基本的にiを使い、iが使えない場合はj, k, l...と名前をつけていくのが一般的です。
応用例
N人の合計点を求めるプログラムを作ってみましょう。
次のプログラムは「入力の個数N」と「点数を表すN個の整数」を入力で受け取り、点数の合計を出力します。
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
int sum = 0; // 合計点を表す変数
int x; // 入力を受け取る変数
int i = 0; // カウンタ変数
while (i < N) {
cin >> x;
sum += x;
i++;
}
cout << sum << endl;
}
入力
3 1 10 100
実行結果
111
合計点を表す変数sumを作っておき、ループするたびに入力を変数xに入れ、sumに足しています。
このプログラムが実行される様子を表したのが次のスライドです。
このように、繰り返し処理を使えば様々な処理が行えるようになります。
ループ構文を使って様々な処理を書く方法は2.01.ループの書き方や2.02.多重ループで詳しく説明します。
細かい話
細かい話なので、飛ばして問題を解いても良いです。
2ずつ増やす
今まではiを1ずつだけ増やしてきましたが、2ずつ増やすこともできます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int i = 0;
while (i < 10) {
cout << i << endl;
i += 2;
}
}
実行結果
0 2 4 6 8
次のように書くことで2ずつ増やしています。
i += 2;
同様にして、より多く飛ばしてループすることもできます。
逆順ループ
5から0までの数を出力したい場合は以下のようにします。
#include <bits/stdc++.h>
using namespace std;
int main() {
int i = 5;
while (i >= 0) {
cout << i << endl;
i--;
}
}
実行結果
5 4 3 2 1 0
こちらはデクリメントを使うことで1ずつ減らしています。
i--;
無限ループをコードテストで実行した場合
AtCoderのコードテストでは実行時間が長すぎるとプログラムが中断されます。また、出力が長すぎる場合も途中から省略されます。
そのため、はじめに紹介した「"Hello"と出力して改行した後、"AtCoder"と出力する処理」を無限に繰り返すプログラムをコードテストで実行しても無限には出力されず、次のように表示されます。
標準出力
Hello AtCoder (中略) Hello AtCoder He...
終了コード
9
無限ループが発生した場合、終了コードは実行時間が長すぎることを表す9となります。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
補足
この説明を読む前に付録4.ループの裏技repマクロを読んだほうが理解しやすいです。ただし、必須の知識では無いので読まなくても問題ありません。
キーポイント
- for文は繰り返し処理でよくあるパターンをwhile文より短く書くための構文
- 「初期化」→「条件式」→「処理」→「更新」→「条件式」→「処理」→...という順で実行され、条件式が真のとき繰り返し続ける
for (初期化; 条件式; 更新) {
処理
}
- N回の繰り返し処理は次のfor文で書くのが一般的
for (int i = 0; i < N; i++) {
処理
}
- breakを使うとループを途中で抜けられる
- continueを使うと後の処理を飛ばして次のループへ行ける
for文
for文は「N回処理する」というような繰り返し処理でよくあるパターンをwhile文より短く書くための構文です。
3回繰り返すプログラムをwhile文とfor文で書くと次のようになります。
#include <bits/stdc++.h>
using namespace std;
int main() {
int j = 0;
while (j < 3) {
cout << "Hello while: " << j << endl;
j++;
}
for (int i = 0; i < 3; i++) {
cout << "Hello for: " << i << endl;
}
}
実行結果
Hello while: 0 Hello while: 1 Hello while: 2 Hello for: 0 Hello for: 1 Hello for: 2
for文は次のように書き、条件式が真のとき処理を繰り返し続けます。
for (初期化; 条件式; 更新) {
処理
}
実行される順序は次のとおりです。

はじめのプログラムのfor文が実行される様子を表したのが次のスライドです。
forとwhileの対応関係
for文とwhile文の対応関係を見てみましょう。
int i = 0; // 初期化
while (i < 3 /* 条件式 */ ) {
cout << "Hello while: " << j << endl; // 処理
i++; //更新
}
for (int i = 0 /* 初期化 */ ; i < 3 /* 条件式 */ ; i++ /* 更新 */) {
cout << "Hello for: " << i << endl; // 処理
}
処理される順序はwhile文で書いたときと全く同じで、「初期化」→「条件式」→「処理」→「更新」→「条件式」→「処理」→...という順で実行されます。
while文とfor文は機能面ではほとんど差がありませんが、次の「N回の繰り返し処理」等、for文で簡潔に書ける処理はfor文で書くのが一般的です。
N回の繰り返し処理
for文を使うとき、ほとんどは「N回の繰り返し処理」のパターンです。
動作の細かい部分がわからない人は、とりあえずこのパターンを覚えるところから始めましょう。
for (int i = 0; i < N; i++) {
処理
}
for文を使うときのコツ
「N回の繰り返し処理」のfor文を使うときは、「初期化」「条件式」「更新」の細かい動作を考えないようにしましょう。
よりおおざっぱに、for文はiが1ずつ増えながらN回処理を繰り返す機能と考えた方が、for文を使うプログラムを書きやすくなります。
また、ループでどう書けばよいかわからなくなったときは、まずループを使わずにプログラムを書いてみて、その後ループで書き直すという方法が有効です。
以下の2つのプログラムはその例です。これに関しては2.01.ループの書き方でより詳しく説明します。
ループを使わないプログラム
cout << "hello for :" << 0 << endl; cout << "hello for :" << 1 << endl; cout << "hello for :" << 2 << endl;
ループで書き直したプログラム
for (int i = 0; i < 3; i++) {
cout << "hello for :" << i << endl;
}
breakとcontinue
while文とfor文を制御する命令として、breakとcontinueがあります。
break
breakはループを途中で抜けるための命令です。

breakを使ったプログラムの例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
// breakがなければこのループは i == 4 まで繰り返す
for (int i = 0; i < 5; i++) {
if (i == 3) {
cout << "ぬける" << endl;
break; // i == 3 の時点でループから抜ける
}
cout << i << endl;
}
cout << "終了" << endl;
}
実行結果
0 1 2 ぬける 終了
if文で i == 3 が真になったとき、break;の命令を実行することでforループを抜け、終了と出力しています。
continue
continueは後の処理をとばして次のループへ行くための命令です。

continueを使ったプログラムの例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
for (int i = 0; i < 5; i++) {
if (i == 3) {
cout << "とばす" << endl;
continue; // i == 3 のとき これより後の処理をとばす
}
cout << i << endl;
}
cout << "終了" << endl;
}
実行結果
0 1 2 とばす 4 終了
上のプログラムでは、if文で i == 3 が真になったとき、continue;の命令を実行することでcontinueより下の部分を飛ばし、次のループに入ります。
細かい話
細かい話なので、飛ばして問題を解いても良いです。
for文とwhile文の違い
for文とwhile文の違いは主に2点あります。「カウンタ変数のスコープ」と「continueをしたときの動作」です。
カウンタ変数のスコープ
for文のカウンタ変数はwhile文よりスコープが狭くなります。
次の例では、for文のカウンタ変数であるiがスコープの範囲外で使われているため、コンパイルエラーが発生しています。
#include <bits/stdc++.h>
using namespace std;
int main() {
int j = 0; // jのスコープはmain関数の終わりまで
while (j < 3) {
cout << "Hello while" << endl;
j++;
}
for (int i = 0; i < 3; i++) { // iのスコープはforの終わりまで
cout << "Hello for" << endl;
}
cout << j << endl;
cout << i << endl;
}
コンパイルエラー
In function ‘int main()’:
18:13: error: ‘i’ was not declared in this scope
cout << i << endl;
^
「変数のスコープ」で見たエラーと同じく、‘i’ was not declared in this scope('i'はこのスコープで宣言されていません)というエラーが出ています。
while文で使っている変数jのスコープは6行目からmain関数の終わりまでですが、
for文の「初期化」の場所で宣言している変数iのスコープは、for文の{ }中(12行目から14行目)だけになります。
continueをしたときの動作
while文でcontinueをすると更新処理を飛ばしてしまう事があるので、注意が必要です。
例を見てみましょう。
#include <bits/stdc++.h>
using namespace std;
int main() {
for (int i = 0; i < 5; i++) {
if (i == 3) {
cout << "forとばす" << endl;
continue;
}
cout << "for" << i << endl;
}
cout << "for終了" << endl;
int j = 0;
while(j < 5) {
if (j == 3) {
cout << "whileとばす" << endl;
continue;
}
cout << "while" << j << endl;
j++;
}
cout << "while終了" << endl;
}
実行結果
for0 for1 for2 forとばす for4 for終了 while0 while1 while2 whileとばす whileとばす whileとばす (無限に続く)
for文のcontinueは先に説明したとおりですが、while文では無限ループになってしまっています。
j == 3のとき、12行目のcontinue;より後を飛ばして次のループに行っていますが、よく見てみるとj++の処理も飛ばされてしまっています。
そのため、変数jの値は永遠に3のままとなり、無限ループになってしまいます。
省略したfor文
for文の「初期化」「条件式」「更新」の部分は、必要が無い場合省略できます。
次のように書いた場合、for文の動作はwhile文と完全に同じものになります。
int i = 0;
for (; i < n;) {
i++;
}
「条件式」の部分を省略した場合、trueと書いたときと同じ動作になります。
次のプログラムは無限ループになります。
for (int i = 0; ; i++) {
cout << i << endl;
}
{ } の省略
if文と同様に、for文やwhile文の処理が一文のみの場合も{ }を省略できます。
#include <bits/stdc++.h>
using namespace std;
int main() {
for (int i = 0; i < 3; i++)
cout << "Hello!" << endl;
}
for文のネスト
if文と同様、for文とwhile文もネストさせることができます。そのような書き方は多重ループと呼ばれます。
詳しくは2.02.多重ループで説明します。
#include <bits/stdc++.h>
using namespace std;
int main() {
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
cout << "i: " << i << ", j:" << j << endl;
}
}
}
実行結果
i:0, j:0 i:0, j:1 i:1, j:0 i:1, j:1
問題
リンク先の問題を解いてください。
ABCの問題
ここまでの知識だけで解ける問題をAtCoder Beginner Contestから再び紹介します。練習問題だけでは物足りない人は解いてみてください。
「易しめ」と書いてあるものも今までのABCの問題よりも難易度が高いことに注意してください。
解けない場合、2.01.ループの書き方や2.02.多重ループを読んでから再挑戦してみてください。
易しめ
- B - Hina Arare
- B - Theater
- B - Harshad Number
- B - Addition and Multiplication
- B - Collecting Balls (Easy Version)
難しめ
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 文字列を扱うにはstring型を使う
- 文字を扱うにはchar型を使う
文字列変数.size()で文字列の長さを取得できる文字列変数.at(i)でi文字目にアクセスできる文字列変数.at(i)のiを添え字という- 添字は0から始まる
- 添字の値が正しい範囲内に無いと実行時エラーになる
文字列(string型)
abcやhelloのように、文字が順番に並んでいるもののことを文字列といいます。
1.04.変数と型で説明したとおり、C++で文字列を扱うにはstring型を使います。
#include <bits/stdc++.h>
using namespace std;
int main() {
string str1, str2;
cin >> str1;
str2 = ", world!";
cout << str1 << str2 << endl;
}
入力
Hello
実行結果
Hello, world!
文字列の長さ
文字列の長さ(文字数)は文字列変数.size()で取得できます。
#include <bits/stdc++.h>
using namespace std;
int main() {
string str = "Hello";
cout << str.size() << endl;
}
実行結果
5
この書き方は「メンバ関数」という機能を使ったものですが、詳しくは後の章で扱います。ここではとりあえず文字列変数.size()とすると文字列の長さが取得できることを覚えておきましょう。
i番目の文字
次のように書くとi文字目が取得できます。
文字列.at(i)
このiのことを添字と言います。
添字は0から始まる
添字は0から始まることに注意しましょう。
#include <bits/stdc++.h>
using namespace std;
int main() {
string str = "hello";
cout << str.at(0) << endl; // h
cout << str.at(4) << endl; // o
}
実行結果
h o
str.at(0)で1文字目、str.at(4)で5文字目を取得しています。
"hello"という文字列の場合、添字の値と文字の対応は次の表のとおりです。
| 添字 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 文字 | h | e | l | l | o |
ループのカウンタ変数を0から始めるのと同じように、添字が0から始まることにも慣れていきましょう。
文字(char型)
string型は「文字列型」ですが、「文字型」というのもあります。それはchar型です。
string型と違い、char型は一文字のデータしか保持することができません。
string型を表すために" "で囲ったように、char型を表すためには' 'で囲います。
#include <bits/stdc++.h>
using namespace std;
int main() {
char c = 'a';
cout << c << endl; // a
}
実行結果
a
文字列変数.at(i)の型
文字列変数.at(i)で取得されるデータはchar型です。
#include <bits/stdc++.h>
using namespace std;
int main() {
string str = "Hello";
char c = str.at(0); // char型の値が得られる
cout << c << endl; // H
}
実行結果
H
文字列の書き換えと比較
文字列の一部を書き換えるときや比較をするときはchar型を使う必要があります。
#include <bits/stdc++.h>
using namespace std;
int main() {
string str = "Hello";
str.at(0) = 'M'; // char型の'M'
cout << str << endl; // Mello
if (str.at(1) == 'e') {
cout << "AtCoder" << endl;
}
}
実行結果
Mello AtCoder
応用
ループ構文との組み合わせ
文字列はループ構文を組み合わせることで様々な処理が記述できるようになります。
次のプログラムでは、入力された文字に何文字'O'が含まれているかを数えています。
#include <bits/stdc++.h>
using namespace std;
int main() {
string str;
cin >> str;
int count = 0;
for (int i = 0; i < str.size(); i++) {
if (str.at(i) == 'O') {
count++;
}
}
cout << count << endl;
}
入力
LOOOOL
実行結果
4
実行環境によっては次のような警告文が表示されることがありますが、動作には影響がないのでこれに関してはひとまず気にしなくて良いです。
warning: comparison of integer expressions of different signedness: 'int' and 'std::__cxx11::basic_string<char>::size_type' {aka 'long unsigned int'} [-Wsign-compare]
この警告が出る理由に関しては3.01.数値型の「符号なし整数のオーバーフロー」で説明します。
注意点
範囲外エラー
添字の値が正しい範囲内に無いと実行時エラーになります。
次のプログラムは"hello"という5文字の文字列(有効な添字の値は0~4)に対し、at(10)で存在しない文字数目にアクセスしようとしているため、実行時エラーが発生します。
#include <bits/stdc++.h>
using namespace std;
int main() {
string x = "hello";
cout << x.at(10) << endl;
}
実行時エラー
terminate called after throwing an instance of 'std::out_of_range' what(): basic_string::at: __n (which is 10) >= this->size() (which is 5)
終了コード
134
添字が範囲外のときのエラーでは、1行目の最後で'std::out_of_range'(範囲外)というエラーメッセージが表示されることが特徴です。
2行目の__n (which is 10) >= this->size() (which is 5)では、「添字の値(10) ≧ 文字列のサイズ(5)」であるためエラーが発生したということを伝えています。
全角文字の扱い
string型やchar型は全角文字を正しく扱えません。
#include <bits/stdc++.h>
using namespace std;
int main() {
string s = "こんにちは";
cout << s.at(0) << endl;
char c = 'あ';
cout << c << endl;
}
実行結果
� �
どちらの出力も文字化けしてしまっています。
C++で全角文字を扱う場合、string型ではない別の文字列型(u32string等)が用いられます。
しかし、それらの扱いはstring型より面倒な部分があり、この教材の目的はC++を使いこなすことではないので詳しくは説明しません。
文字列のメンバ関数や演算子を利用するとき
.size()や後述する==演算子等を利用する場合、一度変数に格納するか、"文字列"s.size()のように" "の末尾にsをつける必要があります。
単に"文字列".size()と書いた場合はコンパイルエラーになります。
#include <bits/stdc++.h>
using namespace std;
int main() {
string str = "Hello";
cout << str.size() << endl; // 5
cout << "Hello"s.size() << endl; // 5(sを末尾につける)
cout << "Hello".size() << endl; // できない
}
コンパイルエラー
./Main.cpp: In function ‘int main()’:
./Main.cpp:8:19: error: request for member ‘size’ in ‘"Hello"’, which is of non-class type ‘const char [6]’
cout << "Hello".size() << endl; // できない
^
細かい話
細かい話なので、飛ばして問題を解いても良いです。
文字列の比較
string型にも数値型のような比較演算子が定義されています。
#include <bits/stdc++.h>
using namespace std;
int main() {
string s1 = "ABC";
string s2 = "ABC";
string s3 = "XY";
if (s1 == s2) {
cout << "ABC == ABC" << endl;
}
if (s1 < s3) {
cout << "ABC < XY" << endl;
}
}
実行結果
ABC == ABC ABC < XY
string型に定義されている比較演算子は次の表の通りです。
| 演算子 | 意味 |
|---|---|
== |
2つの文字列が完全に一致している |
!= |
2つの文字列に違いがある |
<, <=, >, >= |
辞書順による比較 |
「辞書順」というのは簡単に言うと「辞書に載っている順番」のことです。
上の例ではs1 = "ABC"はs3 = "XY"よりも先に載っているので、s1 < s3 == trueとなります。
ただし、C++の順序では'0'~'9'→'A'~'Z'→'a'~'z'の順になっていることに注意しましょう。
つまり、"012"s < "ABC"s == trueであり"ABC"s < "xyz"s == trueです。
「辞書順」の定義について詳しく知りたい人はABC007 B - 辞書式順序の問題文を参照してください。
文字列の連結
+演算子を使うと文字列同士を連結できます。+=を使うこともできます。
#include <bits/stdc++.h>
using namespace std;
int main() {
string hello = "Hello";
// +演算子による連結
cout << hello + ", world!" << endl; // Hello, world!
// +=演算子による連結
hello += ", AtCoder!";
cout << hello << endl; // Hello, AtCoder!
}
実行結果
Hello, world! Hello, AtCoder!
ただし、数値型のように-,*,/,%はできないので注意しましょう。
stringとcharの比較
string型とchar型は==で比較できません。
#include <bits/stdc++.h>
using namespace std;
int main() {
string str = "a";
char c = 'a';
bool b = str == c; // できない
}
コンパイルエラー
./Main.cpp: In function ‘int main()’:
./Main.cpp:7:16: error: no match for ‘operator==’ (operand types are ‘std::string {aka std::basic_string<char>}’ and ‘char’)
bool b = str == c; // できない
^
この後延々とエラー文が続く...
文字列と文字の連結
string型とchar型を+すると、文字列同士と同様に連結できます。
#include <bits/stdc++.h>
using namespace std;
int main() {
string str = "Hello";
char c = str.at(0);
cout << str + c << endl; // HelloH
}
実行結果
HelloH
char型の変数への入力
char型の変数にcinで入力すると一文字ずつ取り出すことができます。
#include <bits/stdc++.h>
using namespace std;
int main() {
char a, b;
cin >> a >> b;
cout << a << endl;
cout << b << endl;
}
入力
OK
実行結果
O K
エスケープシーケンス
「改行」などの特殊な文字をプログラム中で表現する場合、エスケープシーケンスを利用します。
次のプログラムでは改行を表すエスケープシーケンスである\nを使い、こんにちはとAtCoderの間で改行して出力をしています。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "こんにちは\nAtCoder";
}
実行結果
こんにちは AtCoder
基本的には\nだけ覚えておけば良いですが、他にも代表的なエスケープシーケンスとして以下のものがあります。
| エスケープシーケンス | 説明 |
|---|---|
\" |
二重引用符 " |
\' |
引用符 ' |
\\ |
バックスラッシュ(または半角円記号) \ |
\t |
タブ(水平タブ) |
\r |
復帰(一部の実行環境では改行に用いる) |
行単位での入力
cinを使うと空白や改行区切りの入力を簡単に扱えますが、空白で区切らずに行単位で入力を受け取りたいこともあります。
その場合はgetlineを使います。
次のプログラムは2行の入力を行単位で受け取っています。
#include <bits/stdc++.h>
using namespace std;
int main() {
string s, t;
getline(cin, s); // 変数sで入力を一行受け取る
getline(cin, t); // 変数tで入力を一行受け取る
cout << "一行目 " << s << endl;
cout << "二行目 " << t << endl;
}
入力
I have a pen. I have an apple.
実行結果
一行目 I have a pen. 二行目 I have an apple.
getline関数は次の形式で利用します。
getline(cin, 文字列変数);
この書き方は「関数」という機能を使ったものです。詳しくは1.14.STLの関数で扱います。
問題
リンク先の問題を解いてください。
ABCの問題
ここまで学んだ内容だけで、おそらく全てのAtCoder Beginner ContestのA問題を解くことができます。
その中から文字列を扱う問題を一部紹介します。
- A - 居合を終え、青い絵を覆う / UOIAUAI
- A - AtCoder *** Contest
- A - Addition and Subtraction Easy
- A - 添字
- A - お茶
- A - 複数形
- A - 高橋くんの研修
- A - ハンドルネーム
文字列の知識があれば解けるB問題も紹介します。こちらは難易度が高めなので、 解けない場合は2.01.ループの書き方や2.02.多重ループを読んでから再挑戦してみてください。なお、この問題は1.13.配列の知識があると少し解きやすくなります。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 配列は様々なデータの列を扱うことができる機能
vector<型> 配列変数名;で配列変数を宣言できる配列変数名 = { 要素1, 要素2, ... };で配列変数に値を代入できる配列変数.at(i)でi番目の要素にアクセスできる配列変数.size()で配列の要素数を取得できるvector<型> 配列変数名(要素数)と書くと指定した要素数で配列を初期化できる- 配列でN個の入力を受け取るときは、N要素で初期化した後、for文の中で
atを使って1ずつ受け取る
vector<int> vec(N);
for (int i = 0; i < N; i++) {
cin >> vec.at(i);
}
- 配列とfor文を組み合わせると、大量のデータを扱うプログラムを簡潔に書ける
- 配列の添字のルールは文字列と同じ
配列と文字列
文字列は「文字の列」を扱うための機能でした。
配列は文字だけでなく、様々なデータの列を扱うことができる非常に重要な機能です。
文字列と配列は使い方もある程度同じです。
次のプログラムは、「'a', 'b', 'c', 'd'」という文字の列と、「25, 100, 64」という整数の列を扱っています。
#include <bits/stdc++.h>
using namespace std;
int main() {
// 文字列
string str; // 文字列変数を宣言
str = "abcd"; // 'a', 'b', 'c', 'd' という文字(char)の列を代入
cout << str.at(0) << endl; // 1つ目である'a'を出力
cout << str.size() << endl; // 文字列の長さである4を出力
// 配列
vector<int> vec; // int型の配列変数vecを宣言
vec = { 25, 100, 64 }; // 25, 100, 64 という整数(int)の列を代入
cout << vec.at(0) << endl; // 1つめである25を出力
cout << vec.size() << endl; // 配列の長さである3を出力
}
実行結果
a 4 25 3
配列変数の宣言
配列変数は次の形式で宣言します。
vector<型> 配列変数名;
vector<int> vec;と書いた場合、int型のデータ列を扱う配列変数vecが宣言されます。
配列変数への代入
配列変数に値を代入する方法はいくつかありますが、その一つが次の形式です。
配列変数 = { 要素1, 要素2, ... };
配列が持つデータの1つ1つのことを要素と呼びます。
vec = { 25, 100, 64 };と書いた場合、「25, 100, 64」というデータ列が配列変数vecに代入されています。
i番目の要素
文字列と同様に、配列も.at(i)を使ってi番目の要素へアクセスできます。
配列変数.at(i)
配列でも添字は0から始まります。
vector<int> vec = {25, 100, 64};という配列変数vecの場合、添字の値と文字の対応は次の表のとおりです。
| 添字 | 0 | 1 | 2 |
| 要素 | 25 | 100 | 64 |
配列の要素数
文字列と同様に、配列も.size()を使って要素数(長さ)を取得できます。
配列変数.size()
vector<int> vec = {25, 100, 64};という配列変数vecの場合、vec.size()の値は3になります。
配列と変数
配列は「複数の変数を一度に宣言する方法」のように使うことができます。
次のプログラムは、3つの整数を入力から受け取り、それらの合計を出力します。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a1, a2, a3;
cin >> a1 >> a2 >> a3;
cout << a1 + a2 + a3 << endl;
}
次のプログラムは上のプログラムとほとんど同じ意味です。
#include <bits/stdc++.h>
using namespace std;
int main() {
// 3個の入力を受け取れるように 3要素の配列 {0, 0, 0} で初期化
vector<int> vec(3);
// atを使って1つずつ入力
cin >> vec.at(0) >> vec.at(1) >> vec.at(2);
// 和を出力
cout << vec.at(0) + vec.at(1) + vec.at(2) << endl;
}
配列の初期化
次のように書くと、指定した要素数で配列を初期化できます。
vector<型> 配列名(要素数);
vector<int> vec(3);はvector<int> vec = {0, 0, 0}とほとんど同じ意味です。
vector<int>の場合は全ての要素が0で初期化されます。
どんな値で初期化されるかは型によって変わります。例えばvector<string> vec(3)と書いた場合、空の文字列の配列{"", "", ""}で初期化されます。
配列変数への入力
配列変数で入力を受け取るには、十分な大きさで配列を初期化した後、.at(i)を使って一つずつ受け取っていく必要があります。
// 3個の入力を受け取れるように 3要素の配列 {0, 0, 0} で初期化
vector<int> vec(3);
// atを使って1つずつ入力
cin >> vec.at(0) >> vec.at(1) >> vec.at(2);
for文を使った入力
入力を配列変数で受け取る場合、for文を使って入力処理を書くのが一般的です。
#include <bits/stdc++.h>
using namespace std;
int main() {
// 100要素の配列で初期化
vector<int> vec(100);
// 100個の入力を受け取る
for (int i = 0; i < 100; i++) {
cin >> vec.at(i);
}
}
入力の個数が多いときでも、for文を使えば簡潔に入力処理を書くことができます。
配列の使い所
配列とfor文を組み合わせると、大量のデータを扱うプログラムを書くことができます。
次の例題を見て下さい。
例題
N人の数学と英語のテストの点数が与えられます。
それぞれの人について、数学と英語の点数の合計点を計算してください。
制約
0≦N≦1000
入力
N 1人目の数学の点数 2人目の数学の点数 ... N人目の数学の点数 1人目の英語の点数 2人目の英語の点数 ... N人目の英語の点数
出力
1人目の数学と英語の合計点 2人目の数学と英語の合計点 \vdots N人目の数学と英語の合計点
入力例
3 20 100 30 100 5 40
出力例
120 105 70
解答例
Nが小さい場合、配列を使わずにint型の変数だけでこの問題を解くことも可能です。
しかし、Nが大きい場合は配列を使わずに書くのは非常に大変になります。
例えばN=1000だったとき、変数を1000個宣言しなければなりません。
配列とfor文を使えば、Nの大きさに関わらず簡潔に処理を書くことができます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
vector<int> math(N); // N個の数学の点数データ
vector<int> english(N); // N個の英語の点数データ
// 数学の点数データを受け取る
for (int i = 0; i < N; i++) {
cin >> math.at(i);
}
// 英語の点数データを受け取る
for (int i = 0; i < N; i++) {
cin >> english.at(i);
}
// 合計点を出力
for (int i = 0; i < N; i++) {
cout << math.at(i) + english.at(i) << endl;
}
}
その他の機能
初期値の指定
次のように書くと、配列の各要素の初期値を指定できます。
vector<型> 配列名(要素数, 初期値);
例えばvector<int> vec(3, 5);と書いた場合、配列変数vecは{5, 5, 5}で初期化されます。
要素の追加
配列は文字列のように+=で要素を追加することはできません。
代わりに配列変数.push_backを使えば、配列の末尾に要素を追加することができます。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> vec = { 1, 2, 3 };
vec.push_back(10); // 末尾に10を追加
// vecの全要素を出力
for (int i = 0; i < vec.size(); i++) {
cout << vec.at(i) << endl;
}
}
実行結果
1 2 3 10
push_backの後の配列変数vecは次の表の通りになっています。
| 添字 | 0 | 1 | 2 | 3 |
| 要素 | 1 | 2 | 3 | 10 |
注意点
範囲外エラー
文字列と同様に、配列も添字の値が正しい範囲内に無いと実行時エラーになります。
次のプログラムは{ 1, 2, 3 }という3要素の配列(有効な添字の値は0~2)に対し、vec.at(10)で存在しない要素にアクセスしようとしているため、実行時エラーが発生します。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> vec = { 1, 2, 3 };
cout << vec.at(10) << endl;
}
実行時エラー
terminate called after throwing an instance of 'std::out_of_range' what(): vector::_M_range_check: __n (which is 10) >= this->size() (which is 3)
終了コード
134
文字列と同様に、1行目の最後で'std::out_of_range'(範囲外)というエラーメッセージが表示されます。
2行目の__n (which is 10) >= this->size() (which is 3)では、「添字の値(10) ≧ 配列のサイズ(3)」であるためエラーが発生したということを伝えています。
細かい話
細かい話なので、飛ばして問題を解いても良いです。
vector以外の配列
C++にはvector以外にも配列の書き方があります。次の3つの配列の書き方はほとんど同じ意味です。
vector<int> data(3); // vectorによる配列 int data[3]; // Cの配列 array<int, 3> data; // arrayによる配列
他の人のソースコードを見ると、2つ目の書き方をよく見かけるかもしれません。
しかし、この書き方で宣言した配列は多くの落とし穴があります。基本的にはvectorによる配列を使った方が良いです。
APG4bではvectorによる配列の使用を推奨していますが、AtCoderのコンテストの模範解答ではCの配列が使われることもあります。コンテストに参加する人はどちらも読めるようにしておくと良いでしょう。
atを使わないi番目の要素へのアクセス
今まで配列の要素を指定するときは配列変数.at(添字)と書いてきましたが、配列変数[添字]でも同じことができます。
ただし、この書き方は範囲外の添字を指定してしまったときにエラーメッセージを表示してくれず、何が原因でプログラムが正しく動いていないのかがわかりにくいので、配列変数.at(添字)の書き方を使うようにしましょう。
次のプログラムは、配列{ 1, 2, 3 }の最初の要素に2つの方法でアクセスしています。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> vec = { 1, 2, 3 };
cout << vec.at(0) << endl;
cout << vec[0] << endl; // .at(0)と同じ
}
実行結果
1 1
安全に[]でi番目の要素へのアクセスする方法
ABC/ARCで他の人の提出を見ると[]を使っている人が多いです。これは[]のほうが短くて読み書きしやすい、または最初に[]を学んで慣れているという理由からです。
先に述べたとおり[]はエラーが発見しにくいですが、#define _GLIBCXX_DEBUGとコードの最初に書くことで.atと同程度に安全に使うことができるようになります。
2021/11/10追記 注意:_GLIBCXX_DEBUGを使用することで、後に登場するpriority_queueなど、一部の処理の実行速度が遅くなってしまうことが確認されています。使用の際はご注意ください。
次のプログラムは{ 1, 2, 3 }という3要素の配列(有効な添字の値は0~2)に対し、vec[10]で存在しない要素にアクセスしようとしているため、実行時エラーが発生します。
#define _GLIBCXX_DEBUG
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> vec = { 1, 2, 3 };
cout << vec[10] << endl; // 実行時エラーが起きる
}
実行時エラー
/usr/include/c++/5/debug/vector:409:
Error: attempt to subscript container with out-of-bounds index 10, but
container only holds 3 elements.
Objects involved in the operation:
sequence "this" @ 0x0x401350 {
type =
Error: attempt to subscript container with out-of-bounds index 10, but container only holds 3 elements.で3要素の配列に対して境界外の添字10でアクセスしようとしたことを表しています。
.at()を使うか#define _GLIBCXX_DEBUG+[]を使うかは好みですが、APG4bでは.at()を統一して使用します。
#define _GLIBCXX_DEBUGはGCC特有の機能です。Clang環境では代わりに#define _LIBCPP_DEBUG 0と書く必要があります。
要素の削除
配列変数.pop_backを使えば配列の末尾の要素を削除することもできます。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> vec = { 1, 2, 3 };
vec.pop_back(); // 末尾の要素を削除
// vecの全要素を出力
for (int i = 0; i < vec.size(); i++) {
cout << vec.at(i) << endl;
}
}
実行結果
1 2
pop_backの後の配列変数vecは次の表の通りになっています。
| 添字 | 0 | 1 |
| 要素 | 1 | 2 |
配列同士の比較
配列変数同士は==で比較することができます。
==では2つの配列の全要素が一致していたとき、条件式は真になります。
ただし、比較する際はどちらも「配列変数」である必要があり、vec == { 1, 2, 3 }のようには書けないことに注意しましょう。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> vec1 = { 1, 2, 3 };
vector<int> vec2 = { 1, 2, 3 };
if (vec1 == vec2) {
cout << "OK" << endl;
}
/*
↓これはコンパイルエラーになる
if (vec1 == { 1, 2, 3 }) {
cout << "NG" << endl;
}
*/
}
配列の初期化その2
配列の初期化は次のように書くこともできます。
vector<型> 配列変数 = vector<型>(要素数, 初期値);
この書き方はすでに宣言してある配列変数を上書きするときにも使えます。
次の例では{10, 10, 10}で初期化してある変数を100要素の配列{2, 2, ... , 2, 2}で上書きしています。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> vec(3, 10); // {10, 10, 10} で初期化
vec = vector<int>(100, 2); // 100要素の配列 {2, 2, ... , 2, 2} で上書き
cout << vec.at(99) << endl;
}
実行結果
2
大きすぎる配列
配列の要素数が多すぎると、実行時エラーになることがあります。
次の例は要素数が10億の配列を確保しようとして実行時エラーが発生しています。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> v(1000000000);
cout << v[0] << endl;
}
終了コード
134
どの程度までの大きさの配列が確保できるかは実行環境によります。
AtCoderの問題の回答として提出してこのエラーが出た場合、またはと表示されます。
問題
リンク先の問題を解いてください。
ABCの問題
ここまでの知識だけで解ける問題をAtCoder Beginner Contestから再び紹介します。練習問題だけでは物足りない人は解いてみてください。
「易しめ」と書いてあるものも今までのABCの問題よりも難易度が高いことに注意してください。
解けない場合、2.01.ループの書き方や2.02.多重ループを読んでから再挑戦してみてください。
易しめ
難しめ
配列とループ構文がわかっていれば、AtCoderのコンテストに参加するのに最低限の知識を持っていると言えます。
ぜひリアルタイムでコンテストに挑戦してみてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 関数を使うとプログラムのまとまった機能を簡単に使うことができる
- C++で用意されている、関数等がまとまっているもののことをSTLという
関数名(引数1, 引数2, ...)で関数を呼び出せる- 関数に
( )で渡す値のことを引数という - 関数の計算結果のことを返り値または戻り値という
- 引数と返り値は型のルールが決まっており、間違えるとコンパイルエラーになる
| 関数 | min(a, b) |
max(a, b) |
swap(a, b) |
|---|---|---|---|
| 機能 | aとbのうち小さい方の値を返す | aとbのうち大きい方の値を返す | 変数aと変数bの値を交換する |
| 関数 | sort(vec.begin(), vec.end()) |
reverse(vec.begin(), vec.end()) |
|---|---|---|
| 機能 | 配列変数vecをソートする(要素を小さい順に並び替える) | 配列変数vecの要素の並びを逆にする |
STLの関数
関数を使うとプログラムのまとまった機能を簡単に使うことができます。
「C++の関数」と「数学の関数」は似た部分もありますが、基本的には別物であることに注意してください。
関数の使い方
「2つの変数の値のうち小さい方を出力するプログラム」を例として見てみましょう。
関数を使わないで書く場合、次のようになります。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 10, b = 5;
int answer;
if (a < b) {
answer = a;
}
else {
answer = b;
}
cout << answer << endl;
}
実行結果
5
「min関数」を使えば次のように書くことができます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 10, b = 5;
int answer = min(a, b); // min関数
cout << answer << endl;
}
実行結果
5
プログラム中で出てくるminは2つの値のうち小さい方を求める関数です。
min(a, b)の「計算結果」としてaとbの小さい方の値が取得できるので、それを変数answerに代入しています。
STLとは
C++ではminの他にも様々な関数が用意されており、多くの機能を自分でプログラムを書くこと無く利用できます。
C++で用意されている、関数等がまとまっているもののことをSTL (Standard Template Library)といいます。
関数を自分で作る事もできます。それについては「1.15.関数」で説明します。
関数の呼び出し方
関数を使うことを関数呼び出しと言います。
関数呼び出しの記法は以下のとおりです。
関数名(引数1, 引数2, ...)
引数(ひきすう)とは、関数に渡す値のことです。min(a, b)では変数aと変数bがそれに当たります。
min関数では2つの引数がありましたが、引数の数は関数によって異なります。
関数の計算結果の値のことを返り値(かえりち)または戻り値(もどりち)と言います。
int answer = min(a, b);ではmin関数の返り値を変数answerに代入しています。
引数と返り値の型
引数と返り値は関数によって型のルールが決まっており、間違うとコンパイルエラーになります。
次のプログラムは、min関数の引数にint型とstring型を渡そうとして、コンパイルエラーが発生しています。
#include <bits/stdc++.h>
using namespace std;
int main() {
string s = "hello";
int a = min(10, s); // min関数にint型とstring型のペアは渡せない
cout << a << endl;
}
コンパイルエラー
./Main.cpp: In function ‘int main()’:
./Main.cpp:7:22: error: no matching function for call to ‘min(int, std::string&)’
int a = min(10, s); // min関数にint型とstring型のペアは渡せない
^
(この後長々とエラー文が続く)
STLの関数の使い方を間違えると、非常に長いコンパイルエラー文が出ることがあります。
関数の例
STLの関数の中から3つの関数を紹介します。
これらを暗記しておく必要はありませんが、「この処理はSTLの関数でできた気がする」と思い出して調べられることが大切です。
min関数
min関数は、2つの引数のうち小さい方の値を返します。
#include <bits/stdc++.h>
using namespace std;
int main() {
int answer = min(10, 5);
cout << answer << endl; // 5
}
実行結果
5
引数と返り値の型
引数と返り値の型はintやdoubleのような数値型(または大小比較が出きる型)ならなんでも良いです。
#include <bits/stdc++.h>
using namespace std;
int main() {
double answer = min(1.5, 3.1);
cout << answer << endl; // 1.5
}
実行結果
1.5
ただし、2つの引数の型は同じである必要があります。
#include <bits/stdc++.h>
using namespace std;
int main() {
double a = 1.5;
int b = 10;
int answer = min(a, b); // 引数の型がdouble型とint型なのでエラーになる
}
コンパイルエラー
./Main.cpp: In function ‘int main()’:
./Main.cpp:7:26: error: no matching function for call to ‘min(double&, int&)’
int answer = min(a, b); // 引数の型がdouble型とint型なのでエラーになる
^
(この後長々とエラー文が続く)
max関数
max関数は、2つの引数のうち大きい方の値を返します。
#include <bits/stdc++.h>
using namespace std;
int main() {
int answer = max(10, 5);
cout << answer << endl; // 10
}
実行結果
10
引数と返り値の型
引数と返り値の型についてはminと同様です。
swap関数
swap関数は、2つの引数の値を交換します。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 10, b = 5;
swap(a, b);
cout << a << endl; // 5
cout << b << endl; // 10
}
実行結果
5 10
引数と返り値の型
2つの引数の型は同じである必要があります。
また、swap関数に返り値はありません。このように、返り値が無い関数もあります。
配列を引数にする関数
STLの関数の中から、配列を引数に渡す2つの関数を紹介します。
STLの関数に配列を渡す場合、少し特殊な形式で書く必要があることに注意してください。
reverse関数
reverse関数を使うと、配列の要素の並びを逆にできます。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> vec = {1, 5, 3};
reverse(vec.begin(), vec.end()); // {3, 5, 1}
for (int i = 0; i < vec.size(); i++) {
cout << vec.at(i) << endl;
}
}
実行結果
3 5 1
reverse関数は次の形式で呼び出します。
reverse(配列変数.begin(), 配列変数.end());
reverse関数に返り値はありません。
sort関数
データ列を順番に並び替えることをソートといいます。
sort関数を使うと、配列の要素を小さい順に並び替えることができます。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> vec = {2, 5, 2, 1};
sort(vec.begin(), vec.end()); // {1, 2, 2, 5}
for (int i = 0; i < vec.size(); i++) {
cout << vec.at(i) << endl;
}
}
実行結果
1 2 2 5
sort関数は次の形式で呼び出します。
sort(配列変数.begin(), 配列変数.end());
sort関数に返り値はありません。
sort関数とreverse関数の組合せ
sort関数を使ってからreverse関数を使うと、大きい順にソートできます。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> vec = {2, 5, 2, 1};
sort(vec.begin(), vec.end()); // {1, 2, 2, 5}
reverse(vec.begin(), vec.end()); // {5, 2, 2, 1}
for (int i = 0; i < vec.size(); i++) {
cout << vec.at(i) << endl;
}
}
実行結果
5 2 2 1
ソートは様々な計算で使われる非常に重要な処理なので、使い方を覚えておきましょう。
配列を渡す形式
STLの関数に配列を渡す場合、次の形式で渡すことが多いです。
関数名(配列変数.begin(), 配列変数.end())
この記法について完全に理解するにはイテレータという機能の知識が必要ですが、それについては後の章で扱います。
とりあえず今の段階では、こう書けば関数の機能を利用できるということだけ理解しておきましょう。
細かい話
細かい話なので、飛ばして問題を解いても良いです。
引数で関数を呼び出した場合
次のプログラムのように、引数で関数を呼び出した場合は内側の関数から実行されます。
min(max(1, 2), 3) ↓ min(2, 3) ↓ 2
引数の実行順序
引数の実行順序は環境によって異なります。APG4bの推奨環境である「GCC, C++」では、次のように最後の引数の式から順に実行されます。
min(1 + 1, 2 + 2) ↓ min(1 + 1, 4) ↓ min(2, 4) ↓ 2
その他の環境(Clang等)では、次のように最初の引数の式から順に実行されることがあります。
min(1 + 1, 2 + 2) ↓ min(2, 2 + 2) ↓ min(2, 4) ↓ 2
このことを気にする必要がある場面は少ないですが、次の節のように自分で関数を定義する場合はハマりどころになりうるので、頭の片隅においておきましょう。
問題
リンク先の問題を解いてください。
ABCの問題
AtCoder Beginner Contestからソートを活用できる問題を紹介します。
次の2問は「1.13.配列」で「難しめ」として紹介したものですが、ソートを使えばもっと簡単に解くことができます。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 関数を作成することを関数を定義すると言う
返り値の型 関数名(引数1の型 引数1の名前, 引数2の型 引数2の名前, ...) {
処理
}
- 関数の返り値はreturn文を使って
return 返り値;で指定する - 関数の返り値が無い場合は返り値の型にvoidを指定し、return文は
return;と書く - 関数の引数が不要な場合は定義と呼び出しで
()だけを書く - 処理がreturn文の行に到達した時点で関数の処理は終了する
- 返り値がある関数で返り値の指定を忘れた場合、どんな値が返ってくるかは決まっていない
- 引数に渡された値は基本的にコピーされる
関数
関数を作成することを関数を定義すると言います。
次の例では、STLのmin関数と同じ機能を持つ関数をmy_minを定義しています。
#include <bits/stdc++.h>
using namespace std;
// 関数定義
int my_min(int x, int y) {
if (x < y) {
return x;
}
else {
return y;
}
}
int main() {
int answer = my_min(10, 5);
cout << answer << endl; // 5
}
実行結果
5
関数の動作
次のスライドは上のプログラム全体の動作を説明したものです。
関数の定義
関数の定義はmain関数より前で行います。
関数定義の記法は次のとおりです。
返り値の型 関数名(引数1の型 引数1の名前, 引数2の型 引数2の名前, ...) {
処理
}
前の節で見たとおり、引数は「関数に渡す値」、返り値は「関数の結果の値」のことです。
my_min関数はint型の引数を2つ受け取り、計算結果としてint型の値を返すので、定義は次のようになります。
int my_min(int x, int y) {
}
呼び出し方はSTLの関数と同様です。
次のように呼び出した場合、引数xに10が代入され、引数yに5が代入されます。
my_min(10, 5);
返り値の指定
関数の返り値は、return文で指定します。
return 返り値;
my_min関数では2つの引数x,yのうち小さい方を返すので、次のように書きます。
if (x < y) {
return x;
}
else {
return y;
}
返り値が無い関数
関数の返り値は無いこともあります。その場合は返り値の型にvoidを指定します。
次のプログラムのhello関数は、引数の文字列の始めに"Hello, "をつけて出力します。
返り値は必要ないのでvoid型を指定しています。
#include <bits/stdc++.h>
using namespace std;
// 返り値が無いのでvoidを指定
void hello(string text) {
cout << "Hello, " << text << endl;
return;
}
int main() {
hello("Tom");
hello("C++");
}
実行結果
Hello, Tom Hello, C++
返り値がvoid型である関数のreturn文は次のように書きます。
return;
引数が無い関数
関数の引数が不要な場合は、定義と呼び出しでは()だけを書きます。
#include <bits/stdc++.h>
using namespace std;
// 整数の入力を受け取って返す関数
// 引数なし
int input() {
int x;
cin >> x;
return x;
}
int main() {
int num = input(); // 引数なし
cout << num + 5 << endl;
}
入力
10
実行結果
15
関数を自分で定義する理由
関数を自分で定義する理由はいくつかありますが、その中から3つを紹介します。
- プログラムの重複が避けられる
- 処理のかたまりに名前をつけられる
- 再帰関数が書ける
大規模なプログラムを書く際は1.と2.による恩恵が大きいです。
APG4bでは主に3.のために関数の紹介をしています。詳しくは「2.04.再帰」で説明します。
注意点
return文の動作
処理がreturn文の行に到達した時点で関数の処理は終了します。
一つの関数の中にreturn文が複数あっても問題ありませんが、return文より後に書いた処理は実行されないことに注意しましょう。
次のプログラムでは、"Hello, "を出力した次の行でreturn;と書いているため、その後の処理は実行されません。
#include <bits/stdc++.h>
using namespace std;
void hello() {
cout << "Hello, ";
return; // この行までしか実行されない
cout << "world!" << endl;
return;
}
int main() {
hello();
}
実行結果
Hello,
返り値の指定忘れ
返り値がある関数でreturn文を忘れると、どんな値が返ってくるかは決まっていません。
次のプログラムのmy_min関数は、if文の中が実行されない場合に返り値を指定していないので、0が返ってきています。
#include <bits/stdc++.h>
using namespace std;
int my_min(int x, int y) {
if (x < y) {
return x;
}
// x >= y のときのreturn忘れ
}
int main() {
int answer = my_min(10, 5);
cout << answer << endl;
}
実行結果
0
このプログラムでは0が返ってきますが、0でない値が返ってくることもあります。
返り値がある関数では、どのような引数のパターンでも必ずreturnするように注意しましょう。
引数はコピーされる
他の変数に値を代入したとき同様に、基本的に引数に渡した値はコピーされます。
次のプログラムのadd5関数は関数内で引数に5を足していますが、呼び出し元の変数numの値は変化しません。
#include <bits/stdc++.h>
using namespace std;
// 引数の値に5を足して出力する関数
void add5(int x) {
x += 5;
cout << x << endl;
return;
}
int main() {
int num = 10;
add5(num); // numの値は引数xにコピーされる
cout << num << endl; // numは10のまま
}
実行結果
15 10
関数add5を呼び出す処理は次のプログラムと同じだと考えれば良いです。よくわからない人は1.04.変数と型の「変数はコピーされる」を読んでください。
int x = num; // xにnumの値10をコピー x += 5; // xとnumは別の変数なのでnumの値は変わらない cout << x << endl;
なお、vectorやstringを引数にした場合も同様にコピーされます。
関数が呼び出せる範囲
関数は宣言した行より後でしか呼び出せません。
次のプログラムでは、hello関数を定義した行より前でhello関数を呼び出しているため、コンパイルエラーが発生しています。
#include <bits/stdc++.h>
using namespace std;
int main() {
hello();
}
void hello() {
cout << "hello!" << endl;
return;
}
コンパイルエラー
./Main.cpp: In function ‘int main()’:
./Main.cpp:5:9: error: ‘hello’ was not declared in this scope
hello();
^
「5:11: error: ‘hello’ was not declared in this scope(5行11文字目 エラー: 'hello'はこのスコープでは宣言されていません)」というエラー文が表示されています。
このエラーが発生した場合、コンパイルエラーが起きない順番に関数の定義を並び替えるか、後述する「プロトタイプ宣言」を利用しましょう。
細かい話
細かい話なので、飛ばして問題を解いても良いです。
プロトタイプ宣言
プロトタイプ宣言をすれば関数を定義する前に呼び出すことができます。
プロトタイプ宣言とは、「関数の名前」と「引数と返り値の型」だけを先に宣言することです。
#include <bits/stdc++.h>
using namespace std;
// プロトタイプ宣言
void hello();
int main() {
// プロトタイプ宣言をしたので呼び出せる
hello();
}
void hello() {
cout << "hello!" << endl;
return;
}
実行結果
hello!
プロトタイプ宣言の記法は次のようになります。
返り値の型 関数名(引数1の型 引数1の名前, 引数2の型 引数2の名前, ...);
引数名の省略
引数の名前は省略することもできます。
例えば、my_min関数のプロトタイプ宣言は次のように書くこともできます。
int my_min(int, int);
returnの省略
返り値がない場合、関数の末尾ではreturnを省略できます。
void hello(string text) {
cout << "Hello, " << text << "!" << endl;
}
main関数
はじめのプログラムから出てきていたmain関数も関数の一つです。
ただし、main関数は特別扱いされていて、returnを省略した場合は必ず0が返るようになっています。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "Hello, world!" << endl;
// return 0; と書くのと同じ
}
実行結果
Hello, world!
関数のオーバーロード
「引数の型」または「引数の数」が異なる場合は、同じ名前の関数を定義することができます。これを関数のオーバーロードと言います。
次のプログラムでは「2つの引数を取るmy_min関数」と「3つの引数を取るmy_min関数」を定義しています。
#include <bits/stdc++.h>
using namespace std;
// 2つの引数のうち最も小さい値を返す
int my_min(int x, int y) {
if (x < y) {
return x;
}
else {
return y;
}
}
// 3つの引数のうち最も小さい値を返す
int my_min(int x, int y, int z) {
if (x <= y && x <= z) {
return x;
}
else if (y <= x && y <= z) {
return y;
}
else {
return z;
}
}
int main() {
int answer = my_min(10, 5); // 2つの引数
cout << answer << endl; // 5
answer = my_min(3, 2, 5); // 3つの引数
cout << answer << endl; // 2
}
ただし、返り値の型が異なるだけではオーバーロードできないことに注意してください。
複雑な引数の条件の指定
STLのmin関数は、引数としてint型でもdouble型でも指定できます。
これと似た挙動は関数のオーバーロードでも再現できますが、STLのmin関数は関数のオーバーロードではなく後の章で説明するテンプレートという機能を使って実装されています。
テンプレートを用いると、引数の条件として「大小比較ができる型なら何でも良い」などの複雑なものを指定できます。
変数のスコープ
関数内の変数のスコープは、呼び出し元とは完全に分けられています。
次のプログラムでは、test関数とmain関数の両方でnumという名前の変数を定義していますが、その2つは完全に別の変数として扱われます。
#include <bits/stdc++.h>
using namespace std;
void test() {
// test関数のスコープで変数numを宣言
int num = 5;
cout << num << endl; // 5
return;
}
int main() {
// main関数のスコープで変数numを宣言
int num = 10;
test();
cout << num << endl; // 10
}
実行結果
5 10
2章の内容の紹介
2章で扱う内容で、関数と関わりが深いものについて2つだけ簡単に紹介します。
飛ばして問題を解いても良いです。読む場合も、今はしっかりと理解する必要はありません。
参照
引数の値をコピーさせないようにすることもできます。
その場合は参照という機能を引数で利用します。これについては2.04.参照で詳しく説明します。
#include <bits/stdc++.h>
using namespace std;
// 型に&をつけると参照になる
void change(int &n, vector<int> &vec) {
n = 1;
vec.at(0) = 1;
return;
}
int main() {
int x = 5;
vector<int> v = {10, 10, 10};
change(x, v);
cout << x << endl;
cout << v.at(0) << endl;
}
実行結果
1 1
再帰関数
関数の中で同じ関数を呼び出すこともできます。
このような関数を再帰関数と言います。これについては2.05.再帰で詳しく説明します。
#include <bits/stdc++.h>
using namespace std;
// 0からnまでの和を求める関数sum
int sum(int n) {
if (n == 0) {
return 0;
}
return n + sum(n - 1);
}
int main() {
cout << sum(3) << endl;
}
実行結果
6
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
第1章修了

第1章お疲れ様でした。
1.00から1.15までの問題を全てACしたあなたは、理論上は全ての「計算処理」を行うプログラムを書ける程の知識を身に着けました。
APG4bでは第1章に関するアンケートを実施しています。回答していただけると嬉しいです。
なお、1章の内容は今後も加筆修正されることがあります。気になる人は公式twitterアカウントをフォローしてください。
第2章について
十分なプログラムの知識があったとしても、実際に複雑な計算をするプログラムを書くのは簡単ではありません。
第2章では「複雑な計算処理の書き方」について、例題を用いながら説明します。
そして、複雑な計算処理をコンピュータが行うのにかかる時間を見積もるための「計算量」という概念について説明します。
第2章をマスターすれば、実際に全ての「計算処理」を行うプログラムを書ける程の知識が身につきます。
AtCoder Beginners Selection の紹介
AtCoder Beginners Selection(ABS)では、AtCoderで競技プログラミングを始める際に解くと良い問題を10問紹介しています。
第1章で「ABCの問題」として紹介したものと一部重複がありますが、競技プログラミングに興味がある人は解いてみると良いでしょう。
解説はQiitaの元記事で見ることができます。
問題8・問題9・問題10は「3.05.計算量」で説明している内容の理解が求められますが、ABSで必要になる範囲であれば上記の解説にも書いてあります。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- ループ処理を書くときの3ステップ
- 1.ループを使わずに書く
- 2.パターンを見つける
- 3.ループで書き直す
- 配列の要素を取り出しながらループする範囲for文
for (配列の要素の型 変数名 : 配列変数) {
// 各要素に対する処理
}
ループの書き方
1.10, 1.11ではwhile、forといったループ構文を紹介しました。
whileやforなどのループ構文は非常に重要です。しかし、文法を理解しても「ループで処理を書く」ということは慣れないと難しいかもしれません。
うまくループ処理が書けない時は、以下の手順でプログラムを書くのが良いでしょう。
- ループを使わないで書く
- パターンを見つける
- ループで書き直す
これを使って次の問題を解いてみます。
例題
整数aと5個の整数x_1, x_2, x_3, x_4, x_5が与えられます。
5個の整数のうちaと等しいものの個数をfor文を使って求めてください。
入力
a x_1 x_2 x_3 x_4 x_5
出力
aと等しいものの個数
入力例
3 1 3 2 5 3
出力例
2
次のプログラムを元に説明していきます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a;
cin >> a;
vector<int> data(5);
for (int i = 0; i < 5; i++) {
cin >> data.at(i);
}
// ここにプログラムを追記
}
解答例
まずはループを使わないでプログラムを書きます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a;
cin >> a;
vector<int> data(5);
for (int i = 0; i < 5; i++) {
cin >> data.at(i);
}
// 答えを保持する変数
int answer = 0;
if (data.at(0) == a) {
answer++;
}
if (data.at(1) == a) {
answer++;
}
if (data.at(2) == a) {
answer++;
}
if (data.at(3) == a) {
answer++;
}
if (data.at(4) == a) {
answer++;
}
cout << answer << endl;
}
ループで書けそうなパターンが見つからないか探してみると、次のパターンが続いていることがわかります。
if (data.at(数値) == a) {
answer++;
}
これを元に、ループを使って書き直してみましょう。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a;
cin >> a;
vector<int> data(5);
for (int i = 0; i < 5; i++) {
cin >> data.at(i);
}
// 答えを保持する変数
int answer = 0;
for (int i = 0; i < 5; i++) {
if (data.at(i) == a) {
answer++;
}
}
cout << answer << endl;
}
入力
3 1 3 2 5 3
実行結果
2
範囲for文
配列の全ての要素に対して何かしらの処理を行ないたいとき、for文を用いて書くことができました。
例えば「配列の全ての要素を出力する」処理は次のように書くことができます。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> a = {1, 3, 2, 5};
for (int i = 0; i < a.size(); i++) {
cout << a.at(i) << endl;
}
}
実行結果
1 3 2 5
C++には配列の要素に対する処理を簡潔に書くことができる範囲for文という構文が用意されています。
範囲for文を用いると上のプログラムは次のように書き直せます。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> a = {1, 3, 2, 5};
for (int x : a) {
cout << x << endl;
}
}
実行結果
1 3 2 5
この例では、「配列変数aから要素を1つ取り出してxという変数にコピー→xの値を出力→次の要素をxにコピー→xの値を出力→…」 のように動作します。すべての要素を取り出し終わるとループを抜けます。
範囲for文は基本的に次の構文です。
for (配列の要素の型 変数名 : 配列変数) {
// 各要素に対する処理
}
全ての要素を取り出し終わるとループを抜けます。
範囲for文でも、for文・while文と同様にbreakやcontinueを使うことができます。
いずれもfor文・while文のときと同じ動作(breakでループを抜け、continueで次のループまで処理をスキップ)をします。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> a = {1, 3, 1, 2, 5, 10};
for (int x : a) {
if (x == 1) {
continue;
}
if (x == 5) {
break;
}
cout << x << endl;
}
}
実行結果
3 2
範囲for文はコンテナと呼ばれるデータ型に対して使うことができます。
配列はコンテナの一種です。
その他にも文字列型(string型)はコンテナの一種なので、範囲for文を用いることができます。
string型の変数に対して、1文字ずつ処理したい場合に便利です。
#include <bits/stdc++.h>
using namespace std;
int main() {
string str = "hello";
for (char c : str) {
if (c == 'l') {
c = 'L';
}
cout << c;
}
cout << endl;
}
実行結果
heLLo
細かい話
ループ構文の使い分け
ループ構文には1.10で扱ったwhile文、1.11で扱ったfor文、今回紹介した範囲for文がありますが、どのように使い分ければ良いのでしょうか。
for文は1.11で見たように「N回処理する」というようなパターンをwhile文より短く書くための構文でした。 今回紹介した範囲for文は配列に対する処理をfor文よりも簡潔に書くための構文でした。 よって、以下のように使い分けると良いでしょう。
- 配列の全ての要素に対する処理を行なう場合 → 範囲for文
- それ以外で一定回数繰り返し処理する場合 → for文
- それ以外の場合 → while文
ただし、例えば配列の要素に対する処理でも、範囲for文を用いるよりもfor文やwhile文を用いた方が簡潔に書ける場合もあるので、 必ずしも上のように使い分ける必要はありません。
while文が適しているケース
「整数Nがあるとき、Nが2で最大で何回割り切れるかを求める」という処理を考えます。 この処理は配列の要素に対する処理ではありませんし、具体的に何回処理を繰り返せば良いのかということも分かりません。 この処理にはwhile文が適しているでしょう。
次のサンプルプログラムは、入力で与えられた整数Nが2で割り切れる回数を出力するプログラムです。
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
int count = 0;
while (N > 0) {
// 2で割り切れなければループを抜ける
if (N % 2 > 0) {
break;
}
N = N / 2;
count++;
}
cout << count << endl;
}
入力1
8
実行結果1
3
入力2
5
実行結果1
0
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- ループ構文の中にさらにループ構文があるものを多重ループと呼ぶ
- 多重ループを一度に抜けたい場合は、フラグ変数を用意してそれぞれのループを抜けるようにする必要がある
多重ループ
ループの中でループすることもできます。
int main() {
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
cout << "i:" << i << ", j:" << j << endl;
}
}
}
実行結果
i:0, j:0 i:0, j:1 i:0, j:2 i:1, j:0 i:1, j:1 i:1, j:2 i:2, j:0 i:2, j:1 i:2, j:2
このように、ループの内側にループがある物のことを二重ループと言います。
当然三重ループや四重ループもあります。それらをまとめて多重ループと呼びます。
#include <bits/stdc++.h>
using namespace std;
int main() {
for (int i = 0; i < 2; i++) {
for (int j = 0; j < 2; j++) {
for (int k = 0; k < 2; k++) {
cout << "i:" << i << ", j:" << j << ", k:" << k << endl;
}
}
}
}
実行結果
i:0, j:0, k:0 i:0, j:0, k:1 i:0, j:1, k:0 i:0, j:1, k:1 i:1, j:0, k:0 i:1, j:0, k:1 i:1, j:1, k:0 i:1, j:1, k:1
二重ループを使って次の問題を問いてみましょう。
例題「3要素の2つの配列A, Bに同じ要素が含まれているかどうか判定する」
次のプログラムをベースに説明していきます。
今回は「存在するかどうか」のYES/NOを判定する問題なので、答えはbool型の変数に入れます。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> A(3), B(3);
for (int i = 0; i < 3; i++) {
cin >> A.at(i);
}
for (int i = 0; i < 3; i++) {
cin >> B.at(i);
}
// 答えを保持する変数
bool answer = false;
// ここにプログラムを追記
if (answer) {
cout << "YES" << endl;
}
else {
cout << "NO" << endl;
}
}
「全てのAとBの要素の組み合わせを見て、一致しているものがあるかを調べる」という方針で解くことにしましょう。
入力
1 3 2 4 5 3
実行結果
YES
まず、ループを使わないで書いてみます。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> A(3), B(3);
for (int i = 0; i < 3; i++) {
cin >> A.at(i);
}
for (int i = 0; i < 3; i++) {
cin >> B.at(i);
}
// 答えを保持する変数
bool answer = false;
if (A.at(0) == B.at(0) || A.at(0) == B.at(1) || A.at(0) == B.at(2) ||
A.at(1) == B.at(0) || A.at(1) == B.at(1) || A.at(1) == B.at(2) ||
A.at(2) == B.at(0) || A.at(2) == B.at(1) || A.at(2) == B.at(2)) {
answer = true;
}
if (answer) {
cout << "YES" << endl;
}
else {
cout << "NO" << endl;
}
}
Aに着目してパターン化すると次のような形式になっていることがわかります。
A.at(i) == B.at(0) || A.at(i) == B.at(1) || A.at(i) == B.at(2)
これをループ化してみます。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> A(3), B(3);
for (int i = 0; i < 3; i++) {
cin >> A.at(i);
}
for (int i = 0; i < 3; i++) {
cin >> B.at(i);
}
// 答えを保持する変数
bool answer = false;
for (int i = 0; i < 3; i++) {
if (A.at(i) == B.at(0) || A.at(i) == B.at(1) || A.at(i) == B.at(2)) {
answer = true;
}
}
if (answer) {
cout << "YES" << endl;
}
else {
cout << "NO" << endl;
}
}
次はBに着目してパターン化します。
A.at(i) == B.at(j)
最終的なプログラムは次のようになります。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> A(3), B(3);
for (int i = 0; i < 3; i++) {
cin >> A.at(i);
}
for (int i = 0; i < 3; i++) {
cin >> B.at(i);
}
// 答えを保持する変数
bool answer = false;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
if (A.at(i) == B.at(j)) {
answer = true;
}
}
}
if (answer) {
cout << "YES" << endl;
}
else {
cout << "NO" << endl;
}
}
このプログラムの添字の動きを追ってみましょう。
慣れてきたらループ処理を一つ一つ追っていくことはほとんど無くなりますが、慣れないうちは添字がどのように動くのかをイメージすることが大切です。
多重ループのbreak/continue
for文やwhile文にはbreak/continueという命令がありました。多重ループはループ文の中にループ文を入れた物なので、
通常のfor文と同様にbreak/continue命令を使うことができます。
多重ループでbreak命令を使うと1段階ループを抜けることができます。
内側のループの中でbreakすると内側のループを抜けることができますが、このbreakによって外側のループを抜けることはできません。
for (int i = 0; i < ... ; i++) { // ループ1
for (int j = 0; j < ... ; j++) { // ループ2
if (/* 条件 */) {
break; // (*)
}
}
// (*)のbreakでループ2を抜けてここに来る
}
// (*)のbreakでループ1を抜けてここに来ることはできない
多重ループを抜けるときは、ループを抜けるかどうかを持つ変数(フラグ変数)を用意して、フラグ変数の値に応じてループを抜けるように書きます。
処理の大まかな流れは次の通りです。
bool finished = false; // 外側のループを抜ける条件を満たしているかどうか(フラグ変数)
for (int i = 0; i < ... ; i++) {
for (int j = 0; j < ... ; j++) {
/* 処理 */
if (/* 2重ループを抜ける条件 */) {
finished = true;
break; // (*)
// finishをtrueにしてからbreakすることで、
// 内側のループを抜けたすぐ後に外側のループも抜けることができる
}
}
// (*)のbreakでここに来る
if (finished) {
break; // (**)
}
}
// (**)のbreakでここに来る
例
クリックしてサンプルプログラムを開く
#include <bits/stdc++.h>
using namespace std;
int main() {
int sum = 0;
bool finished = false;
for (int i = 0; i < 10 ; i++) {
for (int j = 0; j < 10 ; j++) {
sum += i * j;
if (sum > 1000) {
cout << i << ", " << j << endl;
finished = true;
break;
}
}
if (finished) {
break;
}
}
cout << sum << endl;
}
実行結果
7, 4 1015
他の方法
多重ループの部分を関数化し、関数の内部で使えるreturnを使って一気に抜けるという方法もあります。
void func( /* 処理に必要な変数 */ ) {
for (int i = 0; i < ... ; i++) {
for (int j = 0; j < ... ; j++) {
/* 処理 */
if (/* 2重ループを抜ける条件 */) {
return; // 関数のreturnはループに関係なく抜けることができる
}
}
}
}
int main() {
func();
}
この方法ではループ内の処理を行なうために必要な変数を引数で渡す必要があり、 余計な処理が必要になることがあるので、基本的にはフラグ変数を用意する方針で処理するようにしましょう。
例
クリックしてサンプルプログラムを開く
#include <bits/stdc++.h>
using namespace std;
void func() {
int sum = 0;
for (int i = 0; i < 10 ; i++) {
for (int j = 0; j < 10 ; j++) {
sum += i * j;
if (sum > 1000) {
cout << i << ", " << j << endl;
cout << sum << endl;
return;
}
}
}
}
int main() {
func();
}
実行結果
7, 4 1015
注意点
添え字のミス
多重ループを書いているときによくあるミスにforの中の添字ミスがあります。
次のプログラムのどこにミスがあるか考えてみてください。
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; i++) {
cout << "i: " << i << ", j: " << j << endl;
}
}
正解は内側のループの更新処理の部分です。j++とするべきところをi++としてしまっています。
for (int j = 0; j < 3; i++) {
正しくは
for (int j = 0; j < 3; j++) {
添字のミスは発生しやすく、ミスをした時も発見しにくい(コンパイルエラーにならない)ので、気をつけましょう。
多重ループ中のカウンタ変数の名前はi, j, k, l...としていくのが一般的なのでここでもそうしています。しかし、「iとjは形が似ていて間違えやすい」「名前から意図が伝わりにくい」という意見もあります。
もしカウンタ変数に明確な意味がある場合は、i, j, k, l...にこだわらず、自由に名前を付けるのも良いでしょう。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 2次元配列は2次元の表を扱うときに便利
vector<vector<要素の型>> 変数名(要素数1, vector<要素の型>(要素数2, 初期値))で宣言できる- 初期値は省略可能
変数名.at(i).at(j)でi行目j列目へアクセスできる変数名.size()で縦の大きさを取得できる変数名.at(0).size()で横の大きさを取得できる- 要素を指定して初期化する例
vector<vector<int>> data = {
{7, 4, 0, 8},
{2, 0, 3, 5},
{6, 1, 7, 0},
};
- 2次元以上の配列を多次元配列という
- vectorをN個入れ子にしたものをN次元配列という
配列は「データの列」を扱うための機能でした。
このページでは「データの表」を扱うときに便利な 2次元配列、さらに高次元の 多次元配列 と呼ばれる配列を紹介します。
2次元配列
次の問題を見てみましょう。
例題
縦3行、横4列の整数が書かれた表があります。この表に何個の0が含まれているかを求めてください。
表の例を次に示します。
| 7 | 4 | 0 | 8 |
| 2 | 0 | 3 | 5 |
| 6 | 1 | 7 | 0 |
入力
7 4 0 8 2 0 3 5 6 1 7 0
実行結果
3
このようなデータの表を2次元配列で扱うときは次のように書けます。
#include <bits/stdc++.h>
using namespace std;
int main() {
// int型の2次元配列(3×4要素の)の宣言
vector<vector<int>> data(3, vector<int>(4));
// 入力 (2重ループを用いる)
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++) {
cin >> data.at(i).at(j);
}
}
// 0の個数を数える
int count = 0;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 4; j++) {
// 上からi番目、左からj番目の画素が0かを判定
if (data.at(i).at(j) == 0) {
count++;
}
}
}
cout << count << endl;
}
宣言
2次元配列の宣言は次の形式になります。
vector<vector<要素の型>> 変数名(要素数1, vector<要素の型>(要素数2, 初期値)); vector<vector<要素の型>> 変数名(要素数1, vector<要素の型>(要素数2)); // 初期値を省略
初期値は省略することができます。省略した場合は「要素の型」に対応するゼロ値で初期化されます。
例えば要素の型がintなら、初期値は0で、stringなら空文字列("")です。
表のようなデータを扱う場合、一般的には次のようにします。
vector<vector<要素の型>> 変数名(縦の要素数, vector<要素の型>(横の要素数));
例題で扱ったデータは、
- 要素が整数
- 縦に3行
- 横に4列
の表であるため、次のように宣言しています。
vector<vector<int>> data(3, vector<int>(4));
アクセス
2次元配列の要素にアクセスする場合は次のように書きます。
変数名.at(添字1).at(添字2)
宣言時にvector<vector<要素の型>> 変数名(縦の要素数, vector<型>(横の要素数))としている場合、より具体的には次のようになります。
変数名.at(上から何番目か).at(左から何番目か)
例題では、入力の部分で「上からi番目、左からj番目」の要素に入力するため、
cin >> data.at(i).at(j)
と書いています。
また、上からi番目、左からj番目のマスが0かどうかを判定するため、
if (data.at(i).at(j) == 0)
と書いています。
大きさの取得
vector<vector<int>> data(3, vector<int>(4)); data.size(); // 3 (縦の要素数) (12ではないことに注意!) data.at(0).size(); // 4 (横の要素数)
縦の要素数を取得するには変数名.size()として、横の要素数を取得するには変数名.at(0).size()とします。
変数名.size()とした時に、すべての要素の個数ではなく縦の要素数が返ってくることに注意してください。
すべての要素数が必要なときは縦の要素数 * 横の要素数で求める必要があります。
2次元配列の考え方
説明のために、これまで扱ってきた通常の配列を"1次元配列"と呼ぶことにします。
ここで、1次元配列の復習をします。"要素数"個の"初期値"からなる配列は次のように宣言しました。(1.13 配列の細かい話を参照)
vector<要素の型> 変数名(要素数, 初期値);
2次元配列は「"1次元配列"の配列」と考えると分かりやすいと思います。

2次元配列の宣言の考え方

1次元配列を表す型はvector<要素の型>でした。
2次元配列を表す型は、「"1次元配列"の配列」なのでvector<vector<要素の型>>となります。("外側の配列の要素の型"が1次元配列を表す型になっています。)
また、2次元配列の"初期値"は"1次元配列"なのでvector<vector<要素の型>> 変数名(要素数1, 初期値)の"初期値"の部分にはvector<要素の型>(要素数2))を指定します。("要素数2"個の要素から成る1次元配列です。)

要素へのアクセスは次のように考えられます。
変数名.at(i) // i番目の1次元配列 変数名.at(i).at(j) // i番目の1次元配列 のj番目の要素

2次元配列の添字を「上から何番目か」と「左から何番目か」で表すことが直感的に感じられない人もいると思いますが、慣れましょう。たて×よこ と覚えると良いです。
例題の入力と配列の添字は次の表のように対応しています
| i\j | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| 0 | 7 | 4 | 0 | 8 |
| 1 | 2 | 0 | 3 | 5 |
| 2 | 6 | 1 | 7 | 0 |
このデータが入力されたとき、以下の要素が何になっているかを考えてみてください。
data.at(0).at(1)data.at(1).at(3)data.at(2).at(2)
答え
-
data.at(0).at(1)→4(0番目の1次元配列 の1番目の要素)
0番目の1次元配列は{7, 4, 0, 8}です。 -
data.at(1).at(3)→5(1番目の1次元配列 の3番目の要素)
1番目の1次元配列は{2, 0, 3, 5}です。 -
data.at(2).at(2)→7(2番目の1次元配列 の2番目の要素)
2番目の1次元配列は{6, 1, 7, 0}です。
N×0の二次元配列
後から配列に要素を追加して使う場合などに、N×0の配列を宣言することがあります。
以下のように書くと、N×0の二次元配列になります。
vector<vector<型>> 変数名(N); // 「要素数0の配列」の配列
外側のvectorの初期値を省略することで、N個の配列の要素数はそれぞれ0になります。
長方形にならない二次元配列(ジャグ配列)
N×0の二次元配列に後から要素を追加していく場合などに「行毎に要素数の違う二次元配列」ができることがあります。
このような配列はジャグ配列と呼ばれることがあります。
具体例
以下のdataはジャグ配列の例です。
vector<vector<int>> data(3); // 3×0の配列 data.at(0).push_back(1); data.at(0).push_back(2); data.at(0).push_back(3); // data.at(0)は3要素の配列 data.at(1).push_back(4); data.at(1).push_back(5); data.at(1).push_back(6); data.at(1).push_back(7); // data.at(1)は4要素の配列 data.at(2).push_back(8); data.at(2).push_back(9); // data.at(2)は2要素の配列
dataのイメージを以下に示します。

多次元配列
2次元配列をさらに拡張して、3次元配列や4次元配列といったより高次元の配列を作ることもできます。
1次元より次元の大きい配列をまとめて多次元配列と呼びます。
3次元配列を使った例を見てみましょう。
例題
まるばつゲームの状態がN個与えられます。マルは'o'、バツは'x'、空白は'-'で表されます。すべての状態の'o'の個数の和を求めてください。
1つ目の状態
| - | - | - |
| - | x | - |
| - | o | - |
2つ目の状態
| x | o | - |
| - | o | - |
| x | - | - |
入力
2 - - - - x - - o - x o - - o - x - -
実行結果
3
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
// N × (3 × 3)要素の配列を宣言
vector<vector<vector<char>>> data(N, vector<vector<char>>(3, vector<char>(3)));
// 入力
for (int i = 0; i < N; i++) {
// i番目の状態を読む
for (int j = 0; j < 3; j++) {
for (int k = 0; k < 3; k++) {
cin >> data.at(i).at(j).at(k);
}
}
}
// 'o'の数を数える
int count = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < 3; j++) {
for (int k = 0; k < 3; k++) {
// 「i番目の状態」「上からj番目」「左からk番目」の要素が'o'か判定
if (data.at(i).at(j).at(k) == 'o') {
count++;
}
}
}
}
cout << count << endl;
}
3次元以上の配列も2次元配列とほとんど変わりません。
宣言
3次元配列の場合の宣言方法を次に示します。
vector<vector<vector<要素の型>>> 変数名(要素数1, vector<vector<要素の型>>(要素数2, vector<要素の型>(要素数3, 初期値))); vector<vector<vector<要素の型>>> 変数名(要素数1, vector<vector<要素の型>>(要素数2, vector<要素の型>(要素数3))); // 初期値を省略
ギョッとしてしまうかもしれませんが、基本的な考え方は2次元配列のときと同じです。
3次元配列を「"2次元配列"の配列」つまり「"1次元配列の配列"の配列」と考えます。分かりやすくするために改行を入れてみます。
vector< vector<vector<要素の型>> /* 2次元配列の型 */ > 変数名(要素数1, vector<vector<要素の型>>(要素数2, vector<要素の型>(要素数3, 初期値)) /* 2次元配列の値 */ );

4次元以上の場合も同様に宣言します。N次元配列を「"N-1次元配列"の配列」と考えましょう。
アクセス
N次元配列の要素にアクセスするには次のように書きます。
変数名.at(添字1).at(添字2).at(添字3) ... .at(添字N)
.at(添字)をN回繰り返します。

注意点
多次元配列を扱う際の基本的な注意点は1次元配列と同様です。
多次元配列ではさらに、添字の順番に注意しましょう。
また、変数名.size()では1次元目の要素数が取得できますが、すべての要素の個数が取得できる訳ではないという点に注意しましょう。
vector<vector<vector<int>>> data = {
{
{1, 2, 3, 4},
{5, 6, 7, 8},
{9, 10, 11, 12},
},
{
{13, 14, 15, 16},
{17, 18, 19, 20},
{21, 22, 23, 24},
},
};
int size1 = data.size();
cout << size1 << endl; // 2
int size2 = data.at(0).size();
cout << size2 << endl; // 3
int size3 = data.at(0).at(0).size();
cout << size3 << endl; // 4
cout << size1 * size2 * size3 << endl; // 24
細かい話
要素を指定して初期化する
// 2次元配列の初期化
vector<vector<int>> data1 = {
{7, 4, 0, 8},
{2, 0, 3, 5},
{6, 1, 7, 0}
};
// 3次元配列の初期化
vector<vector<vector<char>>> data2 = {
{
{'-', '-', '-'},
{'-', 'x', '-'},
{'-', 'o', '-'}
},
{
{'x', 'o', '-'},
{'-', 'o', '-'},
{'x', '-', '-'}
}
};
あらかじめ要素の値とサイズが決まっている場合に、要素を指定して初期化することができます。
1次元の配列を多次元配列として使う
「データの表」を扱いたいときは多次元配列が適していることを紹介しました。しかし「データの表」は一列に"ならす"ことで「データの列」として見ることができるので、1次元の配列で扱うこともできます。
2次元の表を1次元に変換する方法はいろいろ考えられますが、表を行ごとに分割して「1列目のデータ→2列目のデータ→3列目のデータ→...」という1次元の列に変換するのがシンプルです。
例えば縦H行、横W列の表を扱いたい時、データの個数はH×W個なので、vector<型> 変数名(H * W);と表現することができます。この場合、上からy個目、左からx個目の要素にアクセスするときは変数名.at(y * W + x)とします。
y * Wの部分は、目的要素のある行の先頭の位置を表しています。一行のデータは並んでいるので、x列目のデータを得るには、行の先頭からxだけ進んだ位置にあるというわけです。
| (0, 0) | (0, 1) | (0, 2) |
| (1, 0) | (1, 1) | (1, 2) |
| (2, 0) | (2, 1) | (2, 2) |
vector以外を用いた多次元配列
「1.13配列」の細かい話でも紹介しましたが、C++にはvector以外にも配列を表現する方法があります。
vector<int> data(3); // vectorによる要素数3の配列 int data[3]; // Cの要素数3の配列 array<int, 3> data; // arrayによる要素数3の配列
このページではvectorを使った多次元配列を紹介しましたが、vector以外の配列で多次元配列を表現することもできます。
// vector を用いた2次元配列
vector<vector<int>> data(3, vector<int>(4)); // 縦3 x 横4 の2次元配列
data.at(1).at(2) // 上から2番目、左から3番目の要素へのアクセス (1番目から数えていることに注意)
// array を用いた2次元配列
array<array<int, 4>, 3> data = {}; // 縦3 × 横4 の2次元配列
data.at(1).at(2) // 上から2番目、左から3番目の要素へのアクセス
// Cの配列を用いた2次元配列
int data[3][4] = {}; // 縦3 × 横4 の2次元配列
data[1][2] // 上から2番目、左から3番目の要素へのアクセス
arrayやCの配列は要素数に変数を用いることができなかったり、Cの配列では範囲外アクセスをしてもエラーにならずにバグを埋め込んでしまうという点に注意する必要があります。慣れるまではvectorの多次元配列を使うようにしましょう。
問題
リンク先の問題を解いてください。
ABCの問題
ここまでの知識で解ける問題をAtCoder Beginner Contestの過去問題から紹介します。練習問題だけでは物足りない人は挑戦してみてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
参照先の型 &参照の名前 = 参照先;で参照を宣言できる- 通常の変数のように参照を宣言するときは参照先を指定する必要がある
- 関数の引数に参照を用いる場合は、その関数を呼び出す時に渡した変数が参照先になる
- 参照先を後から変更することはできない
- 引数が参照になっている関数を呼び出すことを参照渡しという
- 参照渡しは、無駄なコピーを避けたり複数の結果を返したいときに便利
参照
参照の機能を使うと、ある変数に別名を付けるようなことができます。
ある変数への参照を作ったとき、参照からその変数へアクセスすることができます。
次の例を見てください。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 3;
int &b = a; // bは変数aの参照
cout << "a: " << a << endl; // aの値を出力
cout << "b: " << b << endl; // bの参照先の値を出力(aの値である3が出力される)
b = 4; // 参照先の値を変更(aが4になる)
cout << "a: " << a << endl; // aの値を出力
cout << "b: " << b << endl; // bの参照先の値を出力(aの値である4が出力される)
}
実行結果
a: 3 b: 3 a: 4 b: 4
この例では、変数aを参照するbという参照を用意して、b = 4;と書き換えています。
その結果、aの値が4に変更されています。
参照bは変数aと同じように(aであるかのように)振る舞っています。
変数の宣言方法と似ていますが、通常の変数とは違い参照変数自体の値にアクセスすることはできません。 参照変数に対してアクセスを行うように書くと、そのアクセスが参照先についてなされるイメージです。
参照の宣言
参照は次のように宣言します。
参照先の型 &参照の名前 = 参照先;
基本的には宣言時に参照先を指定して初期化する必要がある点に注意してください。
また、あとから参照先を変更することはできません。
例:
int a = 123;
int &b = a; // int型変数aへの参照
string s = "apg4b";
string &t = s; // string型変数sへの参照
vector<int> v = {1, 2, 3, 4, 5};
vector<int> &w = v; // vector<int>型変数vへの参照
int &c; // 参照先が指定されていないためコンパイルエラーになる
参照のアクセス
参照に対して行った操作が、参照先に対して行ったように扱われます。
例1: 整数の場合
int a = 0; int &b = a; b = b + 1; // a = a + 1; と同じ結果になる cout << a << endl; // "1"が出力される

例2: 文字列の場合
string s = "apg4b"; string &t = s; // 以下の操作で参照先のsが書き換わる t.at(0) = 'A'; t.at(1) = 'P'; t.at(2) = 'G'; cout << s << endl; // "APG4b"が出力される cout << t << endl; // 参照先のsの値"APG4b"が出力される
参照の複製
既にある参照と同じ参照先をもつ参照を作ることもできます。
int a = 123; int &b = a; // 変数aへの参照 int &c = b; // 変数aへの参照
「参照への参照」のようにならない点に注意してください。

関数の引数での参照
関数の引数を参照にすることもできます。
関数の引数を参照にすると、関数の中で呼び出す側の変数を書き変えることができます。
通常の関数(値渡し)
まずは参照を用いない関数の例です。
#include <bits/stdc++.h>
using namespace std;
int f(int x) {
x = x * 2; // 2. xを2倍
return x; // 3. xの値を返す
}
int main() {
int a = 3; // "呼び出す側の変数"
int b = f(a); // 1. aの値をfに渡し、4. 結果をbに代入
cout << "a: " << a << endl;
cout << "b: " << b << endl;
}
実行結果
a: 3 b: 6
順を追ってプログラムの動きを確認します。
f(a)でfにaを渡します。このとき、fの引数のxにint x = a;のようにaの値がコピーされます。つまり、x= 3です。fの内部ではxを2倍します。- 変更後の値を返します。
x= 3なので、2倍されてx= 6となり、6が返されます。 int b = f(a);で結果をbにコピーします。a= 3,b= 6となります。
int b = f(a);の呼び出しを展開してみると次のプログラムのようになります。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 3; // "呼び出す側の変数"
int b;
// int b = f(a); を展開
{
int x = a; // aの値がxにコピーされる(引数)
x *= 2; // xが2倍される
b = x; // xの値がbに代入される(返り値)
}
cout << "a: " << a << endl; // "a: 3"
cout << "b: " << b << endl; // "b: 6"
}
このように、渡した変数の値がコピーされるような渡し方を値渡しといいます。
引数が参照になっている関数(参照渡し)
次に、引数を参照にした関数の例です。
#include <bits/stdc++.h>
using namespace std;
int g(int &x) {
x = x * 2; // xを2倍 (参照によって"呼び出す側の変数"が変更される)
return x;
}
int main() {
int a = 3; // 関数を呼び出す側の変数
int b = g(a); // xの参照先がaになる
cout << "a: " << a << endl;
cout << "b: " << b << endl;
}
実行結果
a: 6 b: 6
gの呼び出しの前後で、変数aの値が変わっていることが分かります。
「参照の宣言」では宣言時に参照先を指定して初期化する必要があると書きましたが、引数を参照にした場合は、
呼び出し時に渡した変数が参照先となります。
上のプログラムでは引数のxが参照であり、参照先が呼び出す側のaになるので、関数内でxを書き換えるとaの値が変更されます。
int b = g(a);の呼び出しを展開してみると次のプログラムのようになります。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 3; // "呼び出す側の変数"
int b;
// int b = g(a); を展開
{
int &x = a; // xの参照先がaになる
x *= 2; // xが2倍される(つまりaが2倍される)
b = x; // xの値(aの値)がbに代入される
}
cout << "a: " << a << endl; // "a: 6"
cout << "b: " << b << endl; // "b: 6"
}
このように、渡した変数が参照引数の参照先になるような呼び出し方を参照渡しといいます。
参照渡しの利点
参照渡しが便利な例を紹介します。
関数の結果を複数返したい
通常は関数の結果を返り値を使って呼び出し元に返します。
返り値は1つしか返すことができませんが、関数によっては結果を複数返したい場合があります。
このような場合の1つの実現方法として配列に結果を入れて返すという方法があります。
別の方法として、参照の引数を用いて結果を返す方法があります。
#include <bits/stdc++.h>
using namespace std;
// a,b,cの最大値、最小値をそれぞれminimumの参照先、maximumの参照先に代入する
void min_and_max(int a, int b, int c, int &minimum, int &maximum) {
minimum = min(a, min(b, c)); // 最小値をminimumの参照先に代入
maximum = max(a, max(b, c)); // 最大値をmaximumの参照先に代入
}
int main() {
int minimum, maximum;
min_and_max(3, 1, 5, minimum, maximum); // minimum, maximumを参照渡し
cout << "minimum: " << minimum << endl; // 最小値
cout << "maximum: " << maximum << endl; // 最大値
}
実行結果
minimum: 1 maximum: 5
無駄なコピーを減らす
関数に引数を渡す場合、無駄なコピーが発生することがあります。
#include <bits/stdc++.h>
using namespace std;
// 配列の先頭100要素の値の合計を計算する
int sum100(vector<int> a) {
int result = 0;
for (int i = 0; i < 100; i++) {
result += a.at(i);
}
return result;
}
int main() {
vector<int> vec(10000000, 1); // すべての要素が1の配列
// sum100 を500回呼び出す
for (int i = 0; i < 500; i++) {
cout << sum100(vec) << endl; // 配列のコピーが生じる
}
}
実行結果
100 100 100 100 100 (省略) ...
実行時間
7813 ms
※一例なので異なる結果になることがあります。
上のプログラムでは関数sum100を呼び出すたびに配列の要素がコピーされるので、1000万要素の配列のコピーが500回生じています。
この実行結果では全体で7秒以上の時間がかかっていて、配列を1回コピーするのに約15ミリ秒(0.015秒)程かかっていることになります。
ここで、引数のvector<int> aをvector<int> &aとして参照渡しするように変更します。
#include <bits/stdc++.h>
using namespace std;
// 配列の先頭100要素の値の合計を計算する (参照渡し)
int sum100(vector<int> &a) {
int result = 0;
for (int i = 0; i < 100; i++) {
result += a.at(i);
}
return result;
}
int main() {
vector<int> vec(10000000, 1); // すべての要素が1の配列
// sum100 を500回呼び出す
for (int i = 0; i < 500; i++) {
cout << sum100(vec) << endl; // 参照渡しなので配列のコピーは生じない
}
}
実行結果
100 100 100 100 100 (省略) ...
実行時間
15 ms
※一例なので異なる結果になることがあります。
こちらのプログラムでは、配列を参照渡ししているので呼び出し時に配列の要素がコピーされず、
実行時間が約15ミリ秒に収まっています。
値渡しを用いたsum100では1回あたりの呼び出しに約15ミリ秒かかっていたことを踏まえれば、
約500倍程高速に動作するようになったことになります。
これらのサンプルプログラムはあまりない意味の無い極端な例ですが、現実的なプログラムでも、
複数回呼び出される関数で配列の値渡しを行うと上の例のように実行時間が遅くなってしまうことがあります。
詳しくは2.06.計算量で扱いますが、プログラムを高速化したい場合には配列のコピーについて特に気をつける必要があります。
コピーが必要のない場合は参照渡しを用いるのが良いでしょう。
注意点
参照先の指定が必要
参照を宣言するときは基本的に参照先を指定して初期化する必要があります。
参照先が定まっていない参照を作ることはできないということに注意しましょう。
関数の引数に用いる参照は呼び出し時に自動的に参照先が決まります。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 0;
int &b; // コンパイルエラー
}
エラー出力
./Main.cpp: In function ‘int main()’:
./Main.cpp:6:8: error: ‘b’ declared as reference but not initialized
int &b;
^
「bが参照として宣言されているのに初期化されていない」というエラーです。
参照先を変更することはできない
一度宣言した参照の参照先を後から変更することもできません。
細かい話
&の位置
参照の宣言を以下のように紹介しました。
参照先の型 &参照の名前 = 参照先;
実は、&の位置は参照の名前の直前である必要はなく、次のようにすることもできます。
参照先の型& 参照の名前 = 参照先; // 型の直後 参照先の型 & 参照の名前 = 参照先; // 中間
しかし、複数の参照を同時に宣言しようとした場合には注意が必要です。
int a = 123; int& b = a, c = a;
例えば、上のようにした場合に、bとcはどちらもaへの参照になるように見えてしまいますが、
実際にはcは参照ではなく、「aの値で初期化されたint型の変数」になります。(bはaの参照になります。)
cを参照にするには、cの前にも&をつける必要があります。
&の位置は参照の名前の直前でも型名の直後でもいいのですが、このような問題があるため、名前の直前に書くのが良いでしょう。
int a = 123; int &b = a, &c = a; // bとcはどちらもaへの参照
範囲for文での参照
2.02 ループの書き方では、範囲for文を用いて配列の要素の値を読み取る場合についてのみ紹介しました。
vector<int> a = {1, 3, 2, 5};
for (int x : a) {
x = x * 2;
}
// aは{1, 3, 2, 5}のまま
例えば上のように書いても、x自体は2倍になるものの、対応する配列の要素は変更されません。
参照は範囲for文でも用いることができ、これによって配列の要素を書き換える処理を簡潔に書くことができます。
vector<int> a = {1, 3, 2, 5};
for (int &x : a) {
x = x * 2;
}
// aは{2, 6, 4, 10}となる
参照を用いた範囲for文の書き方
for (配列の要素の型 &変数名 : 配列変数) {
// 変数名 を使う(変数を経由して配列の要素を書き換え可能)
}
変数以外の参照
参照先を変数以外にすることもできます。
vector<int> v = {1, 2, 3};
// 以下の操作で参照先のvの要素が書き換わる
int &e = v.at(1);
e = -2;
cout << v.at(0) << ", " << v.at(1) << ", " << v.at(2) << endl; // "1, -2, 3"が出力される
この例では、配列の2番目の要素を参照先とする参照を宣言しています。
ただし、この例のようにvectorの要素に対する参照を作る場合には注意が必要です。
vectorの要素への参照を作った後に、vectorに対して要素を追加したり要素を削除するような操作を行うと、参照先が無効になり、意図しない動作をすることがあります。
vectorの要素への参照を生成した後は元のvectorの要素数が変わるような操作を行わないように注意しましょう。
具体的には、要素への参照を生成した後に、たくさんの要素をpush_backで追加するようなケースです。
次のプログラムでは、たくさんの要素をpush_backした結果、参照が期待した動作をしていないことが分かります。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> v = {1, 2, 3};
int &e = v.at(1);
// 大量のpush_backで要素数を大幅に増やす
for (int i = 0; i < 1000; i++) {
v.push_back(i + 4);
}
cout << "e: " << e << endl; // "e: 2"とならないことがある
}
実行結果
e: 32734
※一例なので異なる結果になることがあります。
参照型の返り値
#include <bits/stdc++.h>
using namespace std;
// int型の参照を返す関数f
int &f() {
int x = 12345;
return x; // xを参照として返そうとする
}
int main() {
int &y = f();
cout << y << endl; // "12345"が出力される?
}
実行結果
(※何も出力されない)
終了コード: 139
※一例なので異なる結果になることがあります。
このようなプログラムは未定義動作(どのように動作するか決まっていない)であり、避けなければなりません。
1.08 変数のスコープでスコープについて説明したとおり、関数fの中の変数xは、関数fの中でのみ使用可能ですが、このプログラムでは変数xの参照を関数の外側に返しています。
参照を用いても、スコープの制約を超えて変数を使用することはできません。
3章で説明するグローバル変数への参照を返り値として返すことは可能です。
扱わなかった機能のリスト
このページで紹介しきれなかった機能のリストを次に示します。 より詳しく勉強したい人は調べてみてください。
- 右辺値参照
- など
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 「ある関数の中で同じ関数を呼び出す」ことを再帰呼び出しという
- 再帰を行うような関数を再帰関数という
- 再帰呼び出しを行わずに完了できる処理をベースケースという
- 再帰呼出しを行い、その結果を用いて行う処理のことを再帰ステップという
- 再帰関数の実装方法3ステップ
- 1.「引数」「返り値」「処理内容」を決める
- 2.再帰ステップの実装
- 3.ベースケースの実装
再帰関数
再帰関数を理解するためには関数を理解している必要があります。 1.15.関数の記憶が曖昧な人は復習しておきましょう。
再帰関数は難しいので、説明を読んでみて分からなかった場合はそのまま次に進んでもかまいません。
繰り返し処理を行う方法として、これまでforループやwhileループのようなループ構文を扱ってきました。
再帰も繰り返し処理を行う方法の一つです。
再帰とは「ある関数の中で同じ関数を呼び出す」ことです。また、このような関数のことを再帰関数といいます。
再帰はループ構文よりも強力な繰り返し手法で、ループ構文で書くのが難しいような処理を簡潔に行うことができます。
初めは分かりにくく感じるかもしれませんが、強力な手法なので使いこなせるようにしましょう。
例として、「0からnまでの総和を計算する関数」を考えます。
これは今まで扱ってきたforループやwhileループを用いて書くことができますが、再帰関数を用いて書くと次のようになります。
#include <bits/stdc++.h>
using namespace std;
int sum(int n) {
if (n == 0) {
return 0;
}
// sum関数の中でsum関数を呼び出している
int s = sum(n - 1);
return s + n;
}
int main() {
cout << sum(2) << endl; // 0 + 1 + 2 = 3
cout << sum(3) << endl; // 0 + 1 + 2 + 3 = 6
cout << sum(10) << endl; // 0 + 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 = 55
}
実行結果
3 6 55
sum関数の中でsum関数を呼び出しています。このような関数呼び出しのことを再帰呼び出しと言います。
再帰関数の動作
次のスライドは上のsum関数をsum(3)として呼び出したときの動作を説明したものです。
再帰関数は関数名が同じなので自分自身を呼び出しているように感じられて動作が分かりにくく思えるかもしれません。
その場合は「引数の異なる呼び出しでは別の関数を呼んでいる」と考えるといいです。
上の例でsum(3)を呼び出したときの動作を書き出してみます。
sum(3)ではsum(2)を呼び出してその結果に3を足して返します。sum(2)ではsum(1)を呼び出してその結果に2を足して返します。sum(1)ではsum(0)を呼び出してその結果に1を足して返します。sum(0)は0を返します。
ここで、呼び出されるsum(3), sum(2), sum(1), sum(0)をそれぞれ別々の関数に切り出して考えてみると次のようになります。
#include <bits/stdc++.h>
using namespace std;
// 0~0の総和を求める
int sum0() {
return 0;
}
// 0~1の総和を求める
int sum1() {
int s = sum0();
return s + 1; // (0~0の総和) + 1 = 1
}
// 0~2の総和を求める
int sum2() {
int s = sum1();
return s + 2; // (0~1の総和) + 2 = 3
}
// 0~3の総和を求める
int sum3() {
int s = sum2();
return s + 3; // (0~2の総和) + 3 = 6
}
int main() {
cout << sum3() << endl; // 6
}
実行結果
6
sum1, sum2, sum3は同じような処理をしていますが、sum0だけは異なる処理をしています。
繰り返しの処理をwhile文やfor文を用いてまとめられたように、
このような繰り返しの呼び出しを再帰呼出しでまとめることができます。
もう一度元の再帰関数を見てみましょう。
#include <bits/stdc++.h>
using namespace std;
// 0 ~ nの総和を求める
int sum(int n) {
if (n == 0) {
// sum0のケースを場合分け
return 0;
}
// それ以外のケース
int s = sum(n - 1); // 1~(n-1)の総和を計算
return s + n; // nを足して返す
}
int main() {
cout << sum(3) << endl; // 6
}
実行結果
6
再帰関数が正しく動作するのは再帰呼び出しの連鎖に終わりがあるからです。
この例ではnが初めに呼び出されたときの値から1ずつ減っていき、0になるとif文によって分岐され、それ以上再帰呼出しが起こらなくなり、
呼び出しの連鎖が終わるのでうまく動きます。
再帰関数の性質
実装法を紹介する前に再帰関数の性質をまとめておきます。
再帰関数の内容は大きく分けると以下の2つの処理に分類できます。
- ベースケース:再帰呼び出しを行わずに完了できる処理
- 再帰ステップ:再帰呼出しを行い、その結果を用いて行う処理
sum関数の例では、ベースケース・再帰ステップはそれぞれ次のようになります。
// n を受け取って、0~n の総和を計算して返す関数
int sum(int n) {
// ベースケース
if (n == 0) {
return 0;
}
// 再帰ステップ
int s = sum(n - 1);
return s + n;
}
また、再帰関数が正しく動作するためには次の条件を満たす必要があります。
- 再帰呼び出しの連鎖に終わりがある
これを言い換えると、「再帰ステップでの再帰呼び出しを繰り返すうちに必ずベースケースに到達する」ということになります。
この条件を満たさない場合、無限ループになってしまいます。
再帰関数の実装法
初めのうちは、そもそも再帰関数でどのような処理を行うことができるのかが分からず、 使いこなすのが難しいかもしれませんが、再帰関数の実装を追いかけたり、実際に実行してみるうちに分かってくるはずです。
ここでは、再帰関数の実装の方法をできるだけ丁寧に説明します。
1.「引数」「返り値」「処理内容」を決める
関数では、処理に必要な変数を引数として受け取り、関数の内部で処理を行い、結果を返すという流れで処理を行うので、 「引数」「返り値」「処理内容」を決める必要があります。
「処理内容」は「返り値」を計算するという内容になり、結局同じことを示すことも多いです。
sum関数での例
| 引数 | int n (0以上の整数) |
| 返り値 | 0 \sim nの総和 |
| 処理内容 | 0 \sim nの総和を計算する |
ここで関数の概形が決まります。sum関数の例を次に示します。
// 0 ~ n の総和を返す
int sum(int n) {
// 処理内容 : 0 ~ n の総和を計算する
}
2. 再帰ステップの実装
次に、「具体的にどのような再帰呼び出しを使って処理を実現できるのか」つまり、再帰ステップの内容を考えます。
「処理内容」を実装するために、「引数を変えて再帰呼び出しした結果」を利用できないかを考えましょう。 ここは実装したい処理によって異なるので慣れるまで難しいかもしれません。
sum関数での例
「0 \sim nの総和」は「0 \sim (n-1)の総和」にnを足すことで計算できます。
ここで「0 \sim (n-1)の総和」はsum(n - 1)という再帰呼出しによって得られます。
// 0 ~ n の総和を返す
int sum(int n) {
// 処理内容 : 0 ~ n の総和を計算する
// 再帰ステップ
int s = sum(n - 1); // 0 ~ (n-1) の総和
return s + n; // 0 ~ n の総和
}
3. ベースケースの実装 (再帰呼び出しを行わずに完了できる処理)
まず、どのような場合がベースケースなのか、つまり「再帰呼び出しを行わずに完了できる」かを考えます。
次に、ベースケースをif文で場合分けして、処理を実装します。
適当な引数を与えたときに、再帰ステップでの再帰呼び出しが最終的にベースケースに到達することを確認しておきましょう。今考えたベースケースに到達しない場合は再帰ステップもしくはベースケースが間違っています。もう一度考え直してみましょう。
ベースケースは複数あることもあるという点に注意してください。
sum関数での例
sum関数は「0 \sim nの総和」を計算する関数なので、n == 0の場合はすぐに結果が0だと分かります。従ってこのケースがベースケースに相当します。
また、2で実装した再帰ステップでの再帰呼出しsum(n - 1)は、最終的にn == 0のケースに到達するので、必ずベースケースに到達することが分かります。
// n を受け取って、0~n の総和を計算して返す関数
int sum(int n) {
// 処理内容 : 0 ~ n の総和を計算する
// ベースケース
if (n == 0) {
return 0; // 再帰呼び出しをせずとも 0 という結果が確定している
}
// 再帰ステップ
int s = sum(n - 1); // 0 ~ (n-1) の総和
return s + n; // 0 ~ n の総和
}
これで再帰関数sumは完成です。
もう一度再帰関数の書き方まとめます。
- 「引数」「返り値」「処理内容」を決める
- 再帰ステップの実装
- ベースケースの実装
はじめのうちは再帰関数の実装は難しく感じると思います。 しかし、何度も再帰関数を読んだり書いたりしているうちに、直感的に納得できるときが来るはずです。
なお、再帰ステップを考えてからベースケースを考える流れで説明しましたが、 必ずしも先に再帰ステップを考えるのがよいとは限りません。 場合によってはベースケースを先に考えた方が考えやすかったり、再帰ステップで使う関係式を考えているうちにベースケースを思いつくこともあるかもしれません。 「再帰呼び出しの連鎖に終わりがある」という条件さえ満していれば大丈夫ですので、自由な発想で書いてみてください。
再帰関数の実装例
再帰関数のいくつかのパターンを紹介します。 for文やwhile文を用いた方が簡潔に書けるようなものもありますが、再帰関数の例として挙げています。
AからBまでの総和を求める関数: sum_range
クリックで開く
2つの整数aとb (a ≤ b) について、a, a+1, …, b - 1, bの総和を計算する関数sum_rangeを再帰関数で実装します。
具体的な例を挙げると、sum_range(3, 7)なら、3+4+5+6+7=25なので、25を返します。
1. 「引数」「返り値」「処理内容」を決める
| 項目 | 内容 |
|---|---|
| 引数 | int a, int b |
| 返り値 | a ∼ bの総和 (int型) |
| 処理内容 | a ∼ bの総和を計算する |
// a ~ bの総和を計算する (a ≦ b)という前提
int sum_range(int a, int b) {
}
2. 再帰ステップの実装
「a ∼ bの総和」=「a ∼ (b - 1)の総和」+ bという関係式が成り立ちます。
「a ∼ (b - 1)の総和」の部分は、引数bを1減らしてsum_rangeを再帰呼出しした結果に対応するので、この関係式を実装したものが再帰ステップとなります。
// a ~ bの総和を計算する (a ≦ b)という前提
int sum_range(int a, int b) {
// 再帰ステップ
return sum_range(a, b - 1) + b; //「a~bの総和」=「a~(b-1)の総和」+ b
}
3. ベースケースの実装
再帰呼出しせずに結果が確定するようなケースを考えます。
a == bのとき「a ∼ bの総和」=「a ∼ aの総和」=「a」となるので、このケースがベースケースになります。
また、2で実装した再帰ステップでは、aは変化せずbは1ずつ減って再帰呼び出しの連鎖が起こります。a ≤ bという関係より、bは最終的にaと等しくなるので、再帰呼出しに終わりがあることが分かります。
// a ~ bの総和を計算する (a ≦ b)という前提
int sum_range(int a, int b) {
// ベースケース
if (a == b) {
return a;
}
// 再帰ステップ
return sum_range(a, b - 1) + b; //「a~bの総和」=「a~(b-1)の総和」+ b
}
これでsum_rangeは完成です。
#include <bits/stdc++.h>
using namespace std;
// a ~ bの総和を計算する (a ≦ b)という前提
int sum_range(int a, int b) {
// ベースケース
if (a == b) {
return a;
}
// 再帰ステップ
return sum_range(a, b - 1) + b; //「a~bの総和」=「a~(b-1)の総和」+ b
}
int main() {
cout << sum_range(0, 4) << endl; // 0 + 1 + 2 + 3 + 4 = 10
cout << sum_range(5, 8) << endl; // 5 + 6 + 7 + 8 = 26
}
実行結果
10 26
この実装例では「a ∼ bの総和」=「a ∼ (b - 1)の総和」+ bという関係式に着目して、sum_range(a, b - 1) + bとbを減らしていく方針で実装しましたが、 「a ∼ bの総和」=「(a + 1) ∼ bの総和」+ aという関係式も成り立つので、sum_range(a + 1, b) + aとaを増やしていく方針で実装することもできます。
// a ~ bの総和を計算する (a ≦ b)という前提
int sum_range(int a, int b) {
// ベースケース
if (a == b) {
return a;
}
// 再帰ステップ
return a + sum_range(a + 1, b); //「a~bの総和」= a +「(a+1)~bの総和」
}
配列の要素の総和: array_sum
クリックで開く
引数(参照)で与えられた`int`型の配列の全ての要素の総和を計算する関数`array_sum`を実装します。1. 「引数」「返り値」「処理内容」を決める
配列の総和を求める関数なので、引数は配列を参照で受け取ります。 (実はこれではうまく再帰関数として実装できないのですが、ステップ2で確認した後に修正します。)| 項目 | 内容 |
|---|---|
| 引数 | vector<int> &data |
| 返り値 | dataの要素の総和 (int型) |
| 処理内容 | dataの要素の総和 |
// dataの要素の総和を計算する
int array_sum(vector<int> &data) {
}
2. 再帰ステップの実装
次のような関係が成り立つことが分かります。「配列の要素の総和」=「配列の先頭の要素」+「配列の2番目以降の要素の総和」しかし、このままではうまく再帰呼出しで計算できません。 この関係式は少し言い換えると次のようになります。
「1番目以降の要素の総和」=「1番目の要素」+「2番目以降の要素の総和」さらに以下のような関係も成り立っています。
「2番目以降の要素の総和」=「2番目の要素」+「3番目以降の要素の総和」 「3番目以降の要素の総和」=「3番目の要素」+「4番目以降の要素の総和」 ...これらは、変数iを使うことで次のようにまとめることができます。
「i番目以降の要素の総和」=「i番目の要素」+「i+1番目以降の要素の総和」「i+1番目以降の要素の総和」の部分は再帰呼び出しで得られます。 ステップ1で決めた引数だけでは不十分で、変数iを引数に追加する必要が出てきました。ステップ1に戻って修正しましょう。
1.「引数」「返り値」「処理内容」を決める (やり直し)
引数に`int i`を追加して「与えられた配列のi番目以降の要素の総和を計算する関数」とすることで、再帰関数として実装できることが分かりました。 この関数の「引数」「返り値」「処理内容」は次のようになります。| 項目 | 内容 |
|---|---|
| 引数 | vector<int> &data, int i |
| 返り値 | dataのi番目以降の要素の総和 (int型) |
| 処理内容 | dataのi番目以降の要素の総和 |
この関数の関数名を`array_sum_from_i`とします。 すると、当初の目的の「与えられた配列の全ての要素の総和を計算する」関数`sum_array`は、`array_sum_from_i`の引数`i`を0として呼び出すという処理によって実現できます。 ある関数を実装するために、別の関数を追加したものを「補助関数」と呼びます。 この例の場合、`array_sum`を実装するために追加した`array_sum_from_i`が補助関数です。
// (補助関数)
// dataのi番目以降の要素の総和を計算する
int array_sum_from_i(vector<int> &data, int i) {
}
// dataの全ての要素の総和を計算する
int array_sum(vector<int> &data) {
return array_sum_from_i(data, 0);
}
これ以降は`array_sum_from_i`の実装について見ていきます。
2. 再帰ステップの実装 (再)
ここまでで、「i番目以降の要素の総和」=「i番目の要素」+「i+1番目以降の要素の総和」の関係式が成り立つことが分かりました。 「i+1番目以降の要素の総和」の部分は`array_sum_from_i(data, i + 1)`と再帰呼出しすることで求めることができます。// (補助関数)
// dataのi番目以降の要素の総和を計算する
int array_sum_from_i(vector<int> &data, int i) {
// 再帰ステップ
int s = array_sum_from_i(data, i + 1); // i+1番目以降の要素の総和
return data.at(i) + s; // 「i番目以降の要素の総和」=「i番目の要素」+ s
}
3. ベースケースの実装
「i番目以降の要素の総和」なので、対象の要素が無くなったとき、つまり`i == data.size()`のときは答えが0だと分かります。よって、このケースがベースケースとなります。 再帰ステップでは引数の`i`が1ずつ増えて再帰呼び出しの連鎖が起こるので、最終的に`i == data.size()`を満たすはずです。 これより再帰の連鎖に終わりがあることが分かります。// (補助関数)
// dataのi番目以降の要素の総和を計算する
int array_sum_from_i(vector<int> &data, int i) {
// ベースケース
if (i == data.size()) {
return 0; // 対象の要素がないので総和は0
}
// 再帰ステップ
int s = array_sum_from_i(data, i + 1); // i+1番目以降の要素の総和
return data.at(i) + s; // 「i番目以降の要素の総和」=「i番目の要素」+ s
}
これで`array_sum_from_i`は完成です。 `array_sum`を含めたプログラム全体は次のようになります。
#include <bits/stdc++.h>
using namespace std;
// (補助関数)
// dataのi番目以降の要素の総和を計算する
int array_sum_from_i(vector<int> &data, int i) {
// ベースケース
if (i == data.size()) {
return 0; // 対象の要素がないので総和は0
}
// 再帰ステップ
int s = array_sum_from_i(data, i + 1); // i+1番目以降の要素の総和
return data.at(i) + s; // 「i番目以降の要素の総和」=「i番目の要素」+ s
}
// dataの全ての要素の総和を計算する
int array_sum(vector<int> &data) {
return array_sum_from_i(data, 0);
}
int main() {
vector<int> a = {0, 3, 9, 1, 5};
cout << array_sum(a) << endl; // 0 + 3 + 9 + 1 + 5 = 18
}
実行結果
18
Nが素数であるかを判定する関数 is_prime
クリックで開く
正の整数Nが素数であるかを判定する関数`is_prime`を実装します。 Nだけを引数にとって「Nが素数か」を判定する処理を再帰関数で実装するのは難しいので、`array_sum`と同じように、補助関数を導入します。 「i \sim N - 1の範囲にNの約数が存在するか」を判定する補助関数`has_divisor`を再帰関数として実装します。 Nが3以上のとき、「Nが素数である」という条件は「2 \sim N-1の範囲にNの約数が存在しない」と言い換えることができ、1は素数ではなく、2は素数であるので、 「Nが素数か」を判定する関数`is_prime`は、`has_divisor`を用いて実装できます。1.「引数」「返り値」「処理内容」を決める
| 項目 | 内容 |
|---|---|
| 引数 | int N (N ≥ 3), int i |
| 返り値 | i ∼ N - 1の範囲にNの約数が存在するかをbool型で返す |
| 処理内容 | i ∼ N - 1の範囲にNの約数が存在するかを判定する |
// i ~ N-1の範囲にNの約数が存在するか
bool has_divisor(int N, int i) {
}
2. 再帰ステップの実装 / 3. ベースケースの実装
まず、iがNの約数ならば、trueであることが確定します。 そうでないケースでは、「i + 1 \sim N - 1の範囲にNの約数があるか」が結果になります。 「i + 1 \sim N - 1の範囲にNの約数があるか」は再帰呼び出しによって得られます。 iがN以上の場合は、対象となる整数が存在せず、falseであることが確定するので、これはベースケースです。 また、iがNの約数である場合は、trueであることが確定するので、これもベースケースの1つです。 従って、実装は次のようになります。// i ~ N-1の範囲にNの約数が存在するか
bool has_divisor(int N, int i) {
// ベースケース1
if (i == N) {
// そもそも対象となる整数が無いのでfalse
return false;
}
// ベースケース2
if (N % i == 0) {
// 実際にiはNの約数なので、i ~ N-1の範囲に約数が存在する
return true;
}
// 再帰ステップ
// i+1 ~ N-1の範囲の結果がi ~ N-1の範囲の結果となる
// (ベースケース2によって、iがNの約数の場合は取り除かれているので、あとはi+1 ~ N-1の範囲を調べればよい)
return has_divisor(N, i + 1);
}
これで`has_divisor`が実装できました。あとはこれを用いて`is_prime`を実装すれば完成です。
#include <bits/stdc++.h>
using namespace std;
// i ~ N-1の範囲にNの約数が存在するか
bool has_divisor(int N, int i) {
// ベースケース1
if (i == N) {
return false;
}
// ベースケース2
if (N % i == 0) {
// 実際にiはNの約数なので、i ~ N-1の範囲に約数が存在する
return true;
}
// 再帰ステップ
// i+1 ~ N-1の範囲の結果がi ~ N-1の範囲の結果となる
// (ベースケース2によって、iがNの約数の場合は取り除かれているので、あとはi+1 ~ N-1の範囲を調べればよい)
return has_divisor(N, i + 1);
}
bool is_prime(int N) {
if (N == 1) {
// 1は素数ではない
return false;
}
else if (N == 2) {
// 2は素数
return true;
}
else {
// 2~(N-1)の範囲に約数が無ければ、Nは素数
return !has_divisor(N, 2);
}
}
int main() {
cout << is_prime(1) << endl; // 0
cout << is_prime(2) << endl; // 1
cout << is_prime(12) << endl; // 0
cout << is_prime(13) << endl; // 1
cout << is_prime(57) << endl; // 0
}
実行結果
0 1 0 1 0素数判定を行う方法にはもっと効率の良いものがあるので、ここで紹介した素数判定関数は実用的ではないことに注意してください。
配列の操作 reverse_array
クリックで開く
この例は、実装例のみ示します。 各自プログラムの動きを追ってみたり、実際に実行してみたりしてください。 次のプログラムは、参照渡しで与えられた配列を逆順に並べ替えた結果を返す関数`reverse_array`の実装例です。#include <bits/stdc++.h>
using namespace std;
// dataのi番目以降の要素を逆順にした配列を返す
vector<int> reverse_array_from_i(vector<int> &data, int i) {
// ベースケース
if (i == data.size()) {
vector<int> empty_array(0); // 要素数0の配列
return empty_array;
}
// 再帰ステップ
vector<int> tmp = reverse_array_from_i(data, i + 1); // dataのi+1番目以降の要素を逆順にした配列を得る
tmp.push_back(data.at(i)); // 末尾にdataのi番目の要素を追加
return tmp;
}
// 配列を逆順にしたものを返す
vector<int> reverse_array(vector<int> &data) {
return reverse_array_from_i(data, 0);
}
int main() {
vector<int> a = {1, 2, 3, 4, 5};
vector<int> b = reverse_array(a);
for (int i = 0; i < b.size(); i++) {
cout << b.at(i) << endl;
}
}
実行結果
5 4 3 2 1
例題 報告書の伝達時間
次の問題はこれまで紹介した例と違い、再帰関数で実装しないと煩雑になるような例です。
難易度が高めなので、少し考えて分からなかったらヒントや解答例を見るようにしてください。
問題文
あなたはA社を経営する社長です。 A社はN個の組織からなり、それぞれに0番からN - 1番の番号が付いています。 0番の番号が付いた組織はトップの組織です。
組織間には親子関係があり、0番以外のN - 1個の組織には必ず1つの親組織があります。 子組織は複数になることがあります。 また、それぞれの組織は直接的または間接的にトップの組織と関係があるものとします。
あなたは全ての組織に報告書を提出するように求めました。
混雑を避けるために、「各組織は子組織の報告書がそろったら、自身の報告書を加えて親組織に送る」ことを繰り返します。
子組織が無いような組織は自身の報告書だけをすぐに親組織に送ります。
ある組織から報告書を送ってから、その親組織が受け取るときにかかる時間を1分とします。
あるタイミングで一斉に報告書の伝達を開始したときに、トップの組織の元に全ての組織の報告書が揃う時刻(伝達を始めてから何分後か)を求めてください。
なお、各組織の報告書は既に準備されているため、報告書の伝達以外の時間はかからないこととします。
制約
- 1 \leq N \leq 50
- 0 \leq p_i < i (1 \leq i \leq N - 1)
入力
N
p_1 p_2 \ldots p_{N - 1}
p_iはi番の組織の親組織がp_i番の組織であることを示します。 0番の組織はトップの組織であり、親組織が存在しないことに注意してください。
出力
T
一斉に報告書の伝達を開始したときに、トップの組織の元に全ての組織の報告書が揃う時刻T(開始からT分後)を1行に出力してください。
入力例1
6 0 0 1 1 4
実行結果
3
この入力例では、組織は次のような関係になっています。
- 1番の組織の親組織は0番
- 2番の組織の親組織は0番
- 3番の組織の親組織は1番
- 4番の組織の親組織は1番
- 5番の組織の親組織は4番
この関係は次のような図になります。(子組織から親組織の向きに矢印が向いています。)

次の図は、子組織からの報告書が揃った時刻(集まった報告書を親組織へ送った時刻)を青い文字で、各子組織から受け取った時刻を赤い文字で書き込んだものです。

この図から分かるように、トップの組織の元に全ての組織の報告書が揃う時刻は3となります。
この問題における組織のような構造を木構造といいます。 木構造に関する処理を行う際には再帰関数が有用なことが多いです。
サンプルプログラム
下記のサンプルプログラムを書き換え、次のスライドのような動作をするようにプログラムを完成させてください。
スライドは入力例1のイメージを示したものです。
#include <bits/stdc++.h>
using namespace std;
// x番の組織について、子組織からの報告書が揃った時刻を返す
// childrenは組織の関係を表す2次元配列(参照渡し)
int complete_time(vector<vector<int>> &children, int x) {
// (ここに追記して再帰関数を実装する)
}
// これ以降の行は変更しなくてよい
int main() {
int N;
cin >> N;
vector<int> p(N); // 各組織の親組織を示す配列
p.at(0) = -1; // 0番組織の親組織は存在しないので-1を入れておく
for (int i = 1; i < N; i++) {
cin >> p.at(i);
}
// 組織の関係から2次元配列を作る(理解しなくてもよい)
vector<vector<int>> children(N); // ある組織の子組織の番号一覧 // N×0の二次元配列
for (int i = 1; i < N; i++) {
int parent = p.at(i); // i番の親組織の番号
children.at(parent).push_back(i); // parentの子組織一覧にi番を追加
}
// 0番の組織の元に報告書が揃う時刻を求める
cout << complete_time(children, 0) << endl;
}
push_backは配列に要素を追加する操作です。これについては「1.13.配列」で扱っています。
関数complete_timeの引数childrenは二次元配列で、
x番の組織の子組織の番号一覧の配列はchildren.at(x)とすることで得ることができます。
入力例1の場合のchildrenの中身は以下の表のようになります。
| x | children.at(x) |
|---|---|
| 0 | {1, 2} |
| 1 | {3, 4} |
| 2 | {} |
| 3 | {} |
| 4 | {5} |
| 5 | {} |
次のようにすることでx番の組織の子組織についての処理が行えます。
for (int c : children.at(x)) {
// (cについての処理)
}
ヒント
クリックでヒントを開く
- 「組織xの子組織の報告書が揃う時刻」= 組織xの全ての子組織cについて「組織cからの報告書を受け取った時刻」の最大値 - 「組織cからの報告書を受け取った時刻」=「組織cの元に報告書が揃った時刻」+ 1 - 子組織が無いような組織について、報告書が揃う時刻は0解答例
自分で考えてみたあと、必ず確認してください。
クリックで解答例を開く
#include <bits/stdc++.h>
using namespace std;
// x番の組織について、子組織からの報告書が揃う時刻を返す
// childrenは組織の関係を表す2次元配列(参照渡し)
int complete_time(vector<vector<int>> &children, int x) {
// ベースケース
if (children.at(x).size() == 0) {
return 0; // 子組織が無いような組織について、報告書が揃う時刻は0
}
// 再帰ステップ
int max_receive_time = 0; // 受け取った時刻の最大値
// x番の組織の子組織についてループ
for (int c : children.at(x)) {
// (子組織 c のもとに揃った時刻 + 1) の時刻に c からの報告書を受け取る
int receive_time = complete_time(children, c) + 1;
// 受け取った時刻の最大値 = 揃った時刻 なので最大値を求める
max_receive_time = max(max_receive_time, receive_time);
}
return max_receive_time;
}
// これ以降の行は変更しなくてよい
int main() {
int N;
cin >> N;
vector<int> p(N); // 各組織の親組織を示す配列
p.at(0) = -1; // 0番組織の親組織は存在しないので-1を入れておく
for (int i = 1; i < N; i++) {
cin >> p.at(i);
}
// 組織の関係から2次元配列を作る
vector<vector<int>> children(N); // ある組織の子組織の番号一覧
for (int i = 1; i < N; i++) {
int parent = p.at(i); // i番の親組織の番号
children.at(parent).push_back(i); // parentの子組織一覧にi番を追加
}
// 0番の組織の元に報告書が揃う時刻を求める
cout << complete_time(children, 0) << endl;
}
入力例1
6 0 0 1 1 4
実行結果
3
入力例2
8 0 1 2 1 4 3 1
実行結果
4
入力例3
10 0 0 1 3 2 5 3 4 6
実行結果
4
注意点
スタックオーバーフロー
再帰呼び出しは複雑な処理を簡潔に書くことできる便利な機能ですが、 「再帰呼出しの連鎖があまりにも多く続くと実行時エラーが起こる」 という点に注意しなければなりません。
例えば、再帰関数の実装を間違えて、無限に再帰呼出しが起こってしまうようなケースでは実行時エラーが起こります。 また、再帰関数が正しく実装できていたとしても、数千万回ほどの大量の再帰呼出しを行うようなプログラムでは 実行時エラーが発生することがあります。
次のプログラムは、ベースケースを実装していないため正しく動作しない例です。
#include <bits/stdc++.h>
using namespace std;
// 0からnまでの総和を計算し、途中結果を出力する
int sum(int n) {
// ベースケースが実装されていないので止まらない!
// 再帰ステップ
int result = sum(n - 1) + n;
cout << "sum(" << n << ") = " << result << endl; // 途中結果を出力する
return result;
}
int main() {
// 無限に再帰呼び出しが起こる
cout << sum(100) << endl;
}
実行結果の例
| 終了コード | 139 |
| 実行時間 | 218 ms |
| メモリ | 263296 KB |
終了コードの139はプログラムが正しく終了しなかったことを意味しています。
高度な話になりますが、関数呼び出しを行うときにメモリを消費します。 プログラムを実行しているコンピュータのメモリには限りがあるので、再帰呼び出しが多すぎるとメモリが足りなくなってしまいます。 メモリが足りなくなるとそれ以上プログラムを実行できなくなり、実行時エラーが起こります。 この現象をスタックオーバーフローといいます。 コードテストで実行したときに終了コードが139となった場合は、スタックオーバーフローを疑いましょう。
再帰関数を実装するときは、再帰呼び出しをしすぎると実行時エラーが起こる可能性があることを頭の片隅に置いておくようにしましょう。 スタックオーバーフローを避けるために、ループ構文で繰り返し処理を書き直す必要がある場合もあります。
細かい話
相互再帰
2つ以上の関数が相互に呼び出しあって再帰の形になっているものを相互再帰といいます。
次のプログラムを見てください。
#include <bits/stdc++.h>
using namespace std;
// プロトタイプ宣言 (1.15.関数「細かい話」を参照)
bool is_even(int);
bool is_odd(int);
// nが偶数かを判定する
bool is_even(int n) {
// ベースケース
if (n == 0) {
return true;
}
// 再帰ステップ
return is_odd(n - 1); // n-1 が奇数なら、nは偶数
}
// nが奇数かを判定する
bool is_odd(int n) {
// ベースケース
if (n == 0) {
return false;
}
// 再帰ステップ
return is_even(n - 1); // n-1 が偶数なら、nは奇数
}
int main() {
cout << is_even(4) << endl; // 1
cout << is_odd(5) << endl; // 1
cout << is_even(3) << endl; // 0
}
実行結果
1 1 0
まず、is_evenを見てください。再帰ステップでis_oddを呼び出しています。
一方is_oddの再帰ステップではis_evenを呼び出しています。
相互再帰では、「その関数の後ろで定義される別の関数」を呼び出すことになるので、プロトタイプ宣言が必須です。 プロトタイプ宣言については、1.15.関数の「細かい話」を参照してください。
上のプログラムの場合はis_evenを先に定義しているので、is_oddのプロトタイプ宣言があれば十分ですが、分かりやすさのために両方のプロトタイプ宣言を書いています。
相互再帰はプログラムの動作が複雑になりますが、 通常の再帰関数と同様に「再帰呼出しの連鎖に終わりがある」という条件を満たしていれば動作します。
発展的な例
途中で出力する例
クリックで開く
次のプログラムは再帰関数`func`は、「引数のnを1減らして再帰呼出しをn=0になるまで行い、呼び出し履歴を出力する」関数です。 少し複雑ですが、どのように実行されるかを追ってみてください。#include <bits/stdc++.h>
using namespace std;
// num個分のスペースからなる文字列を返す (字下げに用いる)
string space(int num) {
string ret = "";
for (int i = 0; i < num; i++) {
ret += " ";
}
return ret;
}
// 呼び出しの深さに応じて字下げし、関数の開始時点であるというメッセージを出力
void print_in(int n, int depth) {
cout << space(depth * 4) << "func(" << n << ", " << depth << ") in" << endl;
}
// 呼び出しの深さに応じて字下げし、関数の終了時点であるというメッセージを出力
void print_out(int n, int depth) {
cout << space(depth * 4) << "func(" << n << ", " << depth << ") out" << endl;
}
// n: 何回の再帰呼出しを行うか
// depth: 呼び出しの深さ(何回目の再帰呼び出しか)
void func(int n, int depth) {
// ベースケース
if (n == 0) {
print_in(n, depth); // 開始
print_out(n, depth); // 終了
return;
}
// 再帰ステップ
print_in(n, depth); // 開始
func(n - 1, depth + 1); // 残り回数を1減らし、呼び出しの深さを1増やす
print_out(n, depth); // 終了
}
int main() {
func(3, 0); // 3回の再帰呼び出しを行う, 初めの深さを0とする
}
実行結果
func(3, 0) in
func(2, 1) in
func(1, 2) in
func(0, 3) in
func(0, 3) out
func(1, 2) out
func(2, 1) out
func(3, 0) out
引数の配列を変化させる例
クリックで開く
次のような問題を考えます。例題 グリッド上の迷路の探索
N \times Nマスのマス目があります。 上からi行目、左からj列目のマスを(i - 1, j - 1 )と表すことにします。 マス目を迷路に見立ててスタート地点から移動を始め、ゴールに到達することができるかを判定するプログラムを作成してください。 スタートは(0, 0)でゴールは(N - 1, N - 1)とします。 マス目には2種類あり、それぞれのマス目はどちらかの種類です。 - 壁マス:そのマスに移動することはできない - 通路マス:そのマスに移動することができる 初めプレイヤーは(0, 0)にいます。(0, 0)、(N - 1, N - 1)は必ず通路マスであるとします。 プレイヤーは今いるマスの上下左右の4方向に隣合うマスのうち、通路マスであるようなマスに移動することができます。 斜めに移動したり、壁マスの中に移動したりすることはできません。また、N \times Nマスの範囲外へ移動することもできません。 移動を繰り返すことでゴールマスである(N - 1, N - 1)に到達することができるなら`Yes`を、そうでないなら`No`を出力するプログラムを作成してください。 各マスがどちらの種類であるかは文字列の配列として入力され、`.`は通路マスを表し、`#`は壁マスを表すとします。 一行目に迷路の大きさNが入力され、2行目以降に迷路のマス目が入力されます。入力例1
3 .## ... ##.
出力例1
Yesこの迷路は、(0, 0)→(1, 0)→(1, 1)→(1, 2)→(2, 2)と移動することによってゴールすることができるので、`Yes`を出力します。
入力例2
4 .### .### .### #...
出力例2
Noまた、次の迷路はスタートからゴールまで移動する方法が存在しないので、`No`を出力します。
クリックで入出力例を開く
入力例3
3 ... ##. ##.
出力例3
Yes
入力例4
5 ....# ...#. ..#.. .#... #....
出力例4
No
入力例5
10 ..#.#..### .###.#.##. .##....#.. .##..#.... ....#.##.. #####..... ##.#.###.# #..#.##..# ...####.## #.#.###...
出力例5
Yes
解説
このようなマス目の上での移動を扱うときに、単純なループ構文では書くことが難しいです。 しかし、再帰関数を使うと比較的簡単に書くことができます。
解答例
#include <bits/stdc++.h>
using namespace std;
// 正しい移動かを調べる (y, x)が移動先
bool is_valid_move(vector<string> &board, vector<vector<bool>> &checked, int x, int y) {
int N = board.size();
// 移動先がマス目の外である場合
if (x <= -1 || x >= N || y <= -1 || y >= N) {
return false;
}
// 移動先が壁マス
if (board.at(y).at(x) == '#') {
return false;
}
// 既に調べているマスへの移動は調べないのでfalseを返す
if (checked.at(y).at(x)) {
return false;
}
// それ以外なら正しい移動
return true;
}
// (y, x)にいる状態からゴールに到達できるか
// board: マス目の種類
// checked: そのマスを既に調べたかを持つ二次元配列
bool reachable(vector<string> &board, vector<vector<bool>> &checked, int x, int y) {
int N = board.size();
// ベースケース
if (x == N - 1 && y == N - 1) {
// ゴールにいる状態
return true;
}
// 再帰ステップ
checked.at(y).at(x) = true; // 既に調べているという状態に変えておく
// 「上」「右」「下」「左」のいずれかの移動でゴールに到達できるか?
bool result = false;
// 上へ移動したマスからゴールに到達できるか?
if (is_valid_move(board, checked, x, y - 1) && reachable(board, checked, x, y - 1)) {
result = true;
}
// 右へ移動したマスからゴールに到達できるか?
if (is_valid_move(board, checked, x + 1, y) && reachable(board, checked, x + 1, y)) {
result = true;
}
// 下へ移動したマスからゴールに到達できるか?
if (is_valid_move(board, checked, x, y + 1) && reachable(board, checked, x, y + 1)) {
result = true;
}
// 左へ移動したマスからゴールに到達できるか?
if (is_valid_move(board, checked, x - 1, y) && reachable(board, checked, x - 1, y)) {
result = true;
}
return result;
}
int main() {
int N;
cin >> N;
// マス目の状態を受け取る
vector<string> board(N);
for (int i = 0; i < N; i++) {
cin >> board.at(i);
}
// 既にそのマスを調べたかを保持する二次元配列
vector<vector<bool>> checked(N, vector<bool>(N, false)); // false(まだ調べていない)で初期化しておく
// (0, 0) からゴールまで到達できるか?
if (reachable(board, checked, 0, 0)) {
cout << "Yes" << endl;
}
else {
cout << "No" << endl;
}
}
is_valid_move関数は、あるマスへ移動することができるかを判定する関数です。
範囲外へ出るような移動や、壁マスへの移動をチェックしています。
reachable関数は再帰関数になっていて、あるマスからゴールまで到達可能かを調べる関数です。
ベースケースは次のようになっています。
if (x == N - 1 && y == N - 1) {
// ゴールにいる状態
return true;
}
既にゴールしているのでtrueを返しています。
再帰ステップは次のようになっています。
checked.at(y).at(x) = true; // 既に調べているという状態に変えておく
// 「上」「右」「下」「左」のいずれかの移動でゴールに到達できるか?
bool result = false;
// 上へ移動したマスからゴールに到達できるか?
if (is_valid_move(board, checked, x, y - 1) && reachable(board, checked, x, y - 1)) {
result = true;
}
// 右へ移動したマスからゴールに到達できるか?
if (is_valid_move(board, checked, x + 1, y) && reachable(board, checked, x + 1, y)) {
result = true;
}
// 下へ移動したマスからゴールに到達できるか?
if (is_valid_move(board, checked, x, y + 1) && reachable(board, checked, x, y + 1)) {
result = true;
}
// 左へ移動したマスからゴールに到達できるか?
if (is_valid_move(board, checked, x - 1, y) && reachable(board, checked, x - 1, y)) {
result = true;
}
return result;
上下左右への移動を行えるかを確認して移動できるなら、「移動した先からゴールまで到達できるか」を調べています。
無限ループを防ぐために、一度調べたマス目を再び調べることがないようにする必要があります。
あるマスaから、隣接するマスbへ移動できるということは、bからaへも移動できることになります。 もし既に調べたマスを調べることができてしまうと、 「aからゴール可能か」を調べるために「bからゴール可能か」を調べ、そのためにまた「aからゴール可能か」を調べる…… というように無限ループが起こってしまいます。
vector<vector<bool>> checkedは、既に調べられているかを表すN \times Nの二次元配列です。
これによって既に調べられているマスは調べないようにしています。
このように、引数の配列を変化させながら再帰呼び出しをすることもあります。
演習問題
リンク先の問題を解いてください。
ABC/ARCの問題
ここまでの知識で解ける問題をAtCoder Beginner Contest / AtCoder Regular Contestの過去問題から紹介します。 練習問題だけでは物足りない人は是非挑戦してみてください。
ヒントと解答例を用意しました。参考にしてください。
クリックでヒントを開く
まずは、「すべての陸地マスが繋がっている」かを調べる関数を作ります。 「すべての陸地マスが繋がっている」を言い換えると「ある1つの陸地マスから上下左右に移動することを繰り返して、すべての陸地マスに到達できる」となります。 これを調べるのは、発展的な例の「グリッド上の迷路の探索」を応用することで実装できます。vector<vector<bool>> checked(10, vector<bool>(10, false));
// 陸地マスを1つ探す
int y, x;
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
if (board.at(i).at(j) == 'o') {
y = i;
x = j;
break;
}
}
}
/* 引数: 盤面, チェック二次元配列, y座標, x座標*/
fill_island(board, checked, y, x); // (y, x)から到達できるすべての陸地マスのcheckedをtrueにする
bool ok = true;
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
if (board.at(i).at(j) == 'o') {
if (!check.at(i).at(j)) {
// 到達できていない陸地マスがある
ok = false;
}
}
}
}
// ok == true なら全ての陸地マスは繋がっている
クリックで解答例を開く
#include <bits/stdc++.h>
using namespace std;
// (y, x)から到達できるすべての陸地マスのcheckedをtrueにする
void fill_island(vector<vector<char>> &board, vector<vector<bool>> &checked, int y, int x) {
if (y < 0 || x < 0 || y >= 10 || x >= 10) return;
if (board.at(y).at(x) == 'x') return;
if (checked.at(y).at(x)) return;
checked.at(y).at(x) = true; // 既に調べているという状態に変えておく
fill_island(board, checked, y - 1, x ); // 上
fill_island(board, checked, y , x + 1); // 右
fill_island(board, checked, y + 1, x ); // 下
fill_island(board, checked, y , x - 1); // 左
}
bool check_connected(vector<vector<char>> &board) {
vector<vector<bool>> checked(10, vector<bool>(10, false));
// 陸地マスを1つ探す
int y, x;
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
if (board.at(i).at(j) == 'o') {
y = i;
x = j;
break;
}
}
}
/* 引数: 盤面, チェック二次元配列, y座標, x座標*/
fill_island(board, checked, y, x); // (y, x)から到達できるすべての陸地マスのcheckedをtrueにする
bool ok = true;
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
if (board.at(i).at(j) == 'o') {
if (!checked.at(i).at(j)) {
// 到達できていない陸地マスがある
ok = false;
}
}
}
}
// ok == true なら全ての陸地マスは繋がっている
return ok;
}
int main() {
vector<vector<char>> board(10, vector<char>(10));
for (int i = 0; i < 10; i++) {
for (int j = 0; j < 10; j++) {
cin >> board.at(i).at(j);
}
}
for (int y = 0; y < 10; y++) {
for (int x = 0; x < 10; x++) {
if (board.at(y).at(x) == 'o') continue;
// (y, x)は海のマス
// ここを埋め立てたと仮定して、島が1つになるかを判定
board.at(y).at(x) = 'o'; // 埋め立てたと仮定する
if (check_connected(board)) {
cout << "YES" << endl;
return 0;
}
board.at(y).at(x) = 'x'; // 戻す
}
}
cout << "NO" << endl;
}
「グリッド上の迷路の探索」とほとんど同じ問題です。
これ以降の問題は例題で扱った問題とは少し異なっています。 3.05.ビット演算で説明しているビット全探索を用いることで、再帰関数無しで解くこともできます。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- プログラムを実行するときには処理内容に応じた実行時間がかかる
- コンピュータの記憶領域(メモリ)は有限であり、プログラムで変数を使用した分だけメモリを消費する
- プログラムの実行時間・メモリ使用量が入力に応じてどのように変化するかを見積もったものを、それぞれ時間計算量・空間計算量という
- 計算量の表記にはオーダー記法を用いることが多い
アルゴリズム
ある処理を行うプログラムを作成するときに、どのような計算を行っていくかという計算手順のことをアルゴリズムといいます。
例えば、1から100までの総和を計算するプログラムを考えます。
1+2+3+...+99+100と順番に足していくというのは1つのアルゴリズムです。これをアルゴリズムAとします。
一方、\frac{100 \cdot (1 + 100)}{2}という式を用いて計算するというのもアルゴリズムです。これをアルゴリズムBとします。
この例のように、プログラムを作成するにあたって複数のアルゴリズムが考えられることがあります。 そのような場合には、どちらのアルゴリズムを用いるのかを選ぶことになります。
コンピュータの一回の計算には僅かに時間が掛かるので、計算回数が多くなるほど実行時間が長くなります。 より計算回数が少ないアルゴリズムを選択することによって、高速に動作するプログラムを作成できます。
上の例でのアルゴリズムAは99回の足し算が必要ですが、アルゴリズムBでは足し算・掛け算・割り算の計3回の計算で結果を求めることができます。 99回の計算が必要なアルゴリズムAと、3回の計算が必要なアルゴリズムB、というように必要な計算の回数で大まかな性能を見積もることができます。
アルゴリズムの性能を比較する方法は色々ありますが、1つの指標として計算量という考え方があります。
計算時間と記憶領域
既に説明しましたが、コンピュータがプログラムを実行するときには、処理内容に応じた時間が掛かります。
コンピュータの記憶領域のことをメモリといいます。メモリは有限であり、変数を使用した分だけメモリを消費します。 文字列や配列の変数は内部の要素数に応じてメモリを消費します。 例えば、int型のN要素の配列はN個のint型の変数を使用したのと同じくらいのメモリを消費します。 同様に長さNの文字列はN個のchar型の変数を使用したのと同じくらいのメモリを消費します。
計算量
プログラムは入力に対して必要な計算を行い、結果を出力します。 このときに必要な計算時間や必要な記憶領域の量が、入力に対してどれくらい変化するかを示す指標を計算量といいます。
計算量には時間計算量と空間計算量があります。単に計算量という場合、時間計算量を指すことが多いです。
時間計算量
「プログラムの実行に必要な計算のステップ数が入力に対してどのように変化するか」という指標を時間計算量といいます。 計算ステップ数とは、四則演算や数値の比較などの回数です。
空間計算量
「プログラムの実行に必要なメモリの量が入力に対してどのように変化するか」という指標を空間計算量といいます。
計算量の例
次のプログラムは1からNまでの総和(1+2+3+ \cdots +N)を計算するものです。
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
int sum = 0;
for (int i = 1; i <= N; i++) {
sum += i;
}
cout << sum << endl;
}
このプログラムではfor文でN回の繰り返し処理を行っているので、計算ステップ数は入力のNに応じて変わります。 N回の繰り返しを行うので、計算ステップ数はおおよそN回になります。 このときの時間計算量は次で紹介するオーダー記法を用いてO(N)と表します。
このプログラムで使用している変数は入力のNに関わらずint Nとint sumとint iの3つです。
このときの空間計算量はオーダー記法を用いてO(1)と表します。
オーダー記法
厳密な計算ステップ数や必要な記憶領域の量は実装に用いるプログラミング言語や実装方法などによって変わるので、 計算量を厳密に見積もるのは大変です。
そこで時間計算量や空間計算量の表現として、オーダー記法 O(\cdot)が用いられることが多いです。
例えば、3 N^2 + 7N + 4という式はオーダー記法ではO(N ^ 2)と表されます。
以下の手順によってオーダー記法による表記を得ることができます。
- ステップ1:係数を省略する。ただし定数については1とする。
- ステップ2:Nを大きくしたときに一番影響が大きい項を取り出し、O(項)と書く。
補足:N^2 + N + 1という式の場合「N^2」「N」「1」それぞれを項といいます。
「一番影響が大きい項」というのは、Nを大きくしていったときに「大きくなるスピードが最も速い項」と考えてください。 例えばNとN^2を比較すると、以下の表のようになるので3N^2の方が影響が大きいといえます。
| N | N^2 | |
|---|---|---|
| N=1 | 1 | 1 |
| N=10 | 10 | 100 |
| N=100 | 100 | 10,000 |
| N=1,000 | 1,000 | 1,000,000 |
3 N^2 + 7N + 4という式をオーダー記法で表す場合の手順以下の通りです。
- ステップ1:係数を省略してN^2 + N + 1とします。
- ステップ2:N^2 + N + 1で一番影響が大きい項はN^2なのでO(N^2)とします。
同じように2N + 10ならO(N)となります。
例題
次の式をそれぞれオーダー記法で表してください。
- N + 100
- 10N + N^3
- 3 + 5
- 2^N + N^2
補足:2^N = \underbrace{2 \times 2 \times \cdots \times 2}_{N個}
答え
クリックで答えを開く
- O(N)
- O(N^3)
- O(1)
- O(2^N)
2^NとN^2の比較は次の表の通りです。
| 2^N | N^2 | |
|---|---|---|
| N=1 | 2 | 1 |
| N=10 | 1,024 | 100 |
| N=30 | 1,073,741,824 = 約10億 | 900 |
計算量(オーダー記法)の求め方
計算量を求めるには計算ステップ数がどうなるかを式で表す必要があります。
次のプログラムは意味の無いものですが、計算量がどうなるかを考えてみましょう。
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
int sum = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
sum += i * j;
}
}
for (int i = 0; i < N; i++) {
sum += i;
}
for (int i = 0; i < N; i++) {
sum *= i;
}
cout << sum << endl;
}
1つの2重ループと2つの1重ループがあるので計算ステップ数はN^2 + 2Nくらいになります。 これをオーダー記法で表すとO(N^2)となります。 よってこのプログラムの時間計算量はO(N^2)です。
このように、 簡単なアルゴリズムであれば厳密な式を求めなくても 「N回の繰り返し処理があるからO(N)」や「0からNまで回す2重ループがあるからO(N^2)」 などと見積もることができます。
例
いくつかの計算量オーダーについて、具体的なプログラムの例を挙げます。
O(1)
次のプログラムは、1からNまでの総和を公式を使って計算するものです。 このプログラムの計算量はO(1)です。
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
int sum = N * (N + 1) / 2;
cout << sum << endl;
}
入力
10
実行結果
55
O(N)
次のプログラムは要素数Nの配列の中に含まれる偶数の個数を数えるものです。 このプログラムの計算量はO(N)です。
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
vector<int> a(N);
for (int i = 0; i < N; i++) {
cin >> a.at(i);
}
int cnt = 0;
for (int i = 0; i < N; i++) {
if (a.at(i) % 2 == 0) {
cnt++;
}
}
cout << cnt << endl;
}
入力
5 1 4 2 5 9
実行結果
2
O(N ^ 2)
次のプログラムは九九の要領でN×Nマスを埋めるものです。 このプログラムの計算量はO(N^2)です。
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
vector<vector<int>> table(N, vector<int>(N));
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
table.at(i).at(j) = (i + 1) * (j + 1); // N×N回実行される
}
}
// 出力
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
cout << table.at(i).at(j);
if (j != N - 1) {
cout << " ";
}
else {
cout << endl;
}
}
}
}
入力
9
実行結果
1 2 3 4 5 6 7 8 9 2 4 6 8 10 12 14 16 18 3 6 9 12 15 18 21 24 27 4 8 12 16 20 24 28 32 36 5 10 15 20 25 30 35 40 45 6 12 18 24 30 36 42 48 54 7 14 21 28 35 42 49 56 63 8 16 24 32 40 48 56 64 72 9 18 27 36 45 54 63 72 81
N \times N要素の二次元配列を使っているので空間計算量もO(N^2)となります。
O(\log N)
初めに簡単に\logを説明します。
\log_x Nという式は「xを何乗したらNになるか」を表します。 例えば、2^4 = 16なので、\log_2 16 = 4です。
次の図を見てください。長さ8の棒を長さが1になるまで半分に切る(2で割る)ことを繰り返したときに切る回数は\log_2 8回です。

このように計算量に出てくる\logは「半分にする回数」を表すことが多いです。
\log NはNに対して非常に小さくなるので、計算量の中にO(\log N)が出てきた場合でも実行時間にそこまで影響しないことが多いです。 具体的な値が知りたい場合は、Google検索で「log_2 値」のように検索することで確認できます。
補足:厳密な定義は高校数学の範囲なので詳しく知りたい人は別で勉強してください。
また、オーダー記法ではlogの底は省略して書かれることが多いです。この場合は2が省略されていると考えましょう。
実はlogの底の違いは定数倍の違いだけとみなすことができるので、係数を省略するオーダー記法では省略されます。
次のプログラムはNが2で何回割れるかを数えるものです。 このプログラムの計算量はO(\log N)です。
上に挙げたイメージと同じような処理を行うプログラムなので、ループする回数が大体\log_2 N回になることが分かります。
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
int cnt = 0;
while (N > 1) {
cnt++;
N /= 2;
}
cout << cnt << endl;
}
計算量のおおまかな大小
主な計算量の大まかな大小は次のようになります。
O(1) < O(log N) < O(N) < O(N log N) < O(N ^ 2) < O(2 ^ N)
時間計算量ならO(1)側ほど高速に計算可能で、O(2^N)側ほど時間が掛かります。
これらの関係をグラフに示すと次のようになります。
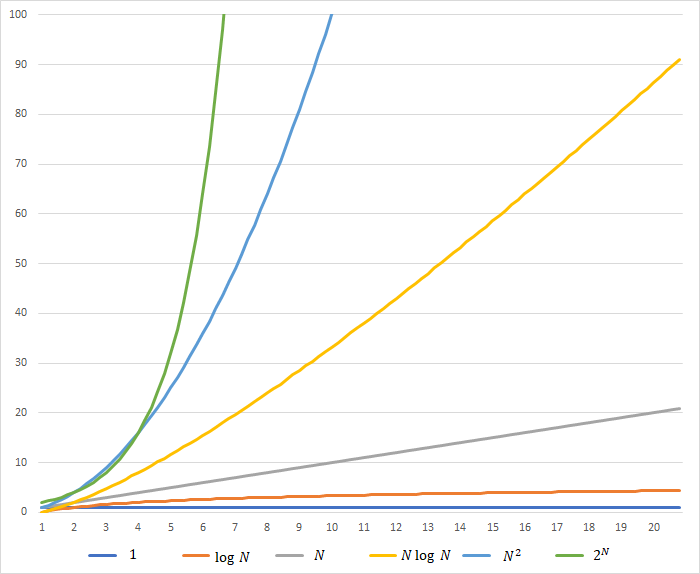
入力Nと実行時間の感覚の対応を次の表に示します。
| N | O(1) | O(\log N) | O(N) | O(N \log N) | O(N^2) | O(2^N) |
|---|---|---|---|---|---|---|
| 1 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 一瞬 |
| 10 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 一瞬 |
| 1000 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 0.01秒くらい | 地球爆発 |
| 10^6 | 一瞬 | 一瞬 | 0.01秒くらい | 0.2秒くらい | 3時間くらい | 地球爆発 |
| 10^8 | 一瞬 | 一瞬 | 1秒くらい | 30秒くらい | 3年くらい | 地球爆発 |
| 10^{16} | 一瞬 | 一瞬 | 3年くらい | 170年くらい | 地球爆発 | 地球爆発 |
1秒くらいで計算が終わるようなプログラムを作ろうというときは、 入力の大きさの上限を見積もった上で1秒以内に収まるような計算量のアルゴリズムを選択する必要があります。
例えば、N=10^6くらいまでの入力で1秒以内に計算を終えるプログラムを作成するのであれば、 O(N^2)のアルゴリズムでは間に合わないので、O(N)のアルゴリズムを用いて実装する必要があります。
AtCoderの問題では実行時間制約が2秒くらいであることが多いです。 コンテストに参加する人は、1秒あたり10^8回くらいの計算ができることを覚えておきましょう。
複数の入力がある場合のオーダー記法
プログラムの入力が複数ある場合もオーダー記法で計算量を表すことができます。 この場合それぞれの変数を残して書きます。 例えば、2つの入力NとMを受け取る場合はO(N + M), O(NM), O((N + M) \log N)のように書きます。
N^2 M + NM + NM^2という計算ステップ数になった場合は、影響が一番大きくなりうる項のみ残すのでO(N^2M + NM^2)となります。
どの項を残すのかが分からなくても計算量が比較できればよいので問題無いです。複数の入力が計算量に影響することがあるということは頭に入れておきましょう。
細かい話
オーダー記法の落とし穴
計算量をオーダー記法で表記すると比較しやすくなりますが、オーダー記法は大まかな比較しかできない点に注意する必要があります。
オーダー記法では影響の一番大きな項のみを残して係数を省略して書きます。 これによって、例えば計算ステップ数が20Nになるアルゴリズムと2Nになるアルゴリズムを比較しようとしたときに、 実際には10倍もの差があるのに、オーダー記法ではどちらもO(N)となってしまいます。
同様の理由で、O(N)のアルゴリズムAとO(N \log N)のアルゴリズムBを比較するときに、 計算量上はアルゴリズムAの方が高速でも、実際に動かしてみるとアルゴリズムBの方が高速だったということも起こり得ます。
正確に比較する必要がある場合は、実際に時間を計測して比較する必要があります。
STLの関数の計算量
1.14 STLの関数で紹介した関数の計算量は以下のようになります。
| STLの関数 | 計算量(配列の要素数N) |
|---|---|
| sort | O(N \log N) |
| reverse | O(N) |
次のプログラムは入力される配列をソートして出力するものです。
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
vector<int> A(N);
// O(N)
for (int i = 0; i < N; i++) {
cin >> A.at(i);
}
// O(N log N)
sort(A.begin(), A.end());
// O(N)
for (int i = 0; i < N; i++) {
cout << A.at(i) << endl;
}
}
N回のループが2つあるので全体の計算量がO(N)であるように思えますが、
sort関数の計算量はO(N \log N)でループ部分のO(N)より大きいので、このプログラム全体の計算量はO(N \log N)となります。
logの性質
-
O(\log 5N) → O(\log N) logの中の係数は省略します。
-
O(\log NM) → O(\log N + \log M) どちらで書いてもよいですが、大きさを考えるときにこの関係を知っていると見積もりやすいかもしれません。
-
O(\log N^2) → O(\log N)
-
O(\log 2^N) → O(N)
演習問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
第2章修了

第2章お疲れ様でした。
2.01から2.06までの問題を全てACしたあなたは、実際に全ての「計算処理」を行うプログラムを書ける程の知識を身に着けました。
3章以降はC++をより深く学びたい人や、競技プログラミングに取り組みたい人向けの説明が多くなっています。 そのため、他にもっと学びたい言語がある人やアプリやゲームを作りたい人は、ここで他の教材に移っても良いです。
APG4bでは第2章に関するアンケートを実施しています。回答していただけると嬉しいです。
第3章について
第3章では、複雑なプログラムを書く際に役立つ機能や、これまでに扱ってこなかった事項を紹介します。
これらの「複雑な計算処理をより簡単に実装するための便利な機能」を使いこなすことで、より効率的に高度なプログラムを作成できるようになります。
AtCoder Beginners Selection の紹介
AtCoder Beginners Selection(ABS)では、AtCoderで競技プログラミングを始める際に解くと良い問題を10問紹介しています。
第1章で「ABCの問題」として紹介したものと一部重複がありますが、競技プログラミングに興味がある人は解いてみると良いでしょう。
解説はQiitaの元記事で見ることができます。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 整数型には扱える値の範囲が決まっている
- 計算の途中で扱える範囲を超えることをオーバーフローといい、正しく計算が行えなくなる
- int型より大きい値を扱いたいときは
int64_t型を使う - double型の値を出力する際に出力する小数点以下の桁数を指定するには以下のようにする
cout << fixed << setprecision(桁数);
(型)値で型変換(キャスト)を行うことができる- 暗黙的にキャストが起こる場合もある
数値型
今回は整数型について扱いますが、厳密な挙動は環境によって異なることがあります。 このページに書かれていることはAtCoder上で「C++ (GCC 9.2.1)」として実行することを想定した内容となっています。
int64_t型
今まで整数を扱う場合はint型を使ってきましたが、int型が表せる範囲は以下の通りに限られています。
- 最小値:-2147483648
- 最大値:2147483647
計算の途中でこの範囲を超えてしまうことをオーバーフローと言います。オーバーフローすると正しく計算が行えなくなります。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 2000000000;
int b = a * 2;
cout << b << endl;
int c = (a * 10 + 100) / 100;
cout << c << endl;
}
実行結果
-294967296 -14748363
2000000000 * 2の結果として4000000000が出力されてほしいところですが、-294967296という値が出力されてしまっています。
また、(2000000000 * 10 + 100) / 100の結果は正しく計算できていれば200000001となるので、オーバーフローせずに済むように思えますが、2000000000 * 10の時点で計算結果がint型の範囲を超えてしまうので、最終的な計算結果も正しくない-14748363という値が出力されています。
もっと広い範囲の値を扱いたい場合、int64_t型を使うのが一般的です。
int64_t型で扱える値の範囲は以下のとおりです。
- 最小値:-9223372036854775808
- 最大値:9223372036854775807
#include <bits/stdc++.h>
using namespace std;
int main() {
int64_t a = 2000000000;
int64_t b = a * 2;
cout << b << endl;
}
実行結果
4000000000
int型は20億(2 * 10^9)くらいまでと覚えておき、それより大きな値が出てきそうであればint64_t型を使うようにしましょう。
int64_t型よりも大きな値を扱う方法もありますが、ここでは説明しません。気になる人は調べてみてください。
プログラム中に直接10のように値を書くと、それはint型の数値として扱われます。
int64_t型として扱ってほしい場合は10LLのように末尾にLLをつけましょう。
また、int型とint64_t型の計算結果はint64_t型になります。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << 2000000000 * 2 << endl; // int * int -> int
cout << 2000000000LL * 2LL << endl; // int64_t * int64_t -> int64_t
cout << 2000000000LL * 2 << endl; // int64_t * int -> int64_t
}
実行結果
-294967296 4000000000 4000000000
double型の出力
double型を出力する場合、通常通りcoutで出力してしまうと適当な桁で四捨五入されて表示されてしまいます。
途中の桁まで四捨五入せずに確実に表示したい場合、以下のように書きます。
cout << fixed << setprecision(桁数);
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << 3.14159265358979 << endl;
// 小数点以下10桁まで
cout << fixed << setprecision(10);
cout << 3.14159265358979 << endl;
}
実行結果
3.14159 3.1415926536
明示的な数値型同士の変換
int型とint64_t型の計算結果がint64_t型であったり、int型とdouble型の計算結果がdouble型であったりするように異なる型同士でも計算できることがありました。
計算せずに、ただ型の変換だけを行うこともできます。型変換のことをキャストと言います。
C++には様々なキャスト方法がありますが、ここでは最も原始的なものを紹介します。
キャストの記法は以下のとおりです。
(型)値
以下は数値型を変換する例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
// 小数点以下5桁まで
cout << fixed << setprecision(5);
int a = 5;
cout << (double)a << endl; // int型の値をdouble型に変換
double b = 3.141592;
cout << (int)b << endl; // double型の値をint型に変換
}
実行結果
5.00000 3
1行目の出力では、int型の値をdouble型にキャストしたことで、出力時に小数点以下の数も表示されています。
2行目の出力では、double型の値をint型にキャストしたことで、小数点以下が切り捨てられて整数として表示されています。
double型をint型にキャストすると小数点以下切り捨てになることは重要なので覚えておきましょう。
int型とdouble型に限らず、様々な型同士がキャストできます。
ただし、int型からstring型への変換のように、数値型以外への変換は基本的にはできないということに注意してください。
int N = 12345; string S = (string)N; // コンパイルエラー
暗黙的な数値型同士の変換
計算の際に自動的にキャストが起こることもあります。
異なる数値型同士で計算を行う場合、以下の表のようにキャストされてから計算されます。
| 型の組合せ | 暗黙的なキャスト | 計算結果の型 |
|---|---|---|
| int型とdouble型 | int型→double型 | double型 |
| int型とint64_t型 | int型→int64_t型 | int64_t型 |
| double型とint64_t型 | int64_t型→double型 | double型 |
また以下のような場合にも自動的にキャストが起こります。
- 別の型の変数へ代入しようとした場合
- 関数の引数に別の型の値を渡す場合
次のプログラムは暗黙的なキャストが生じる例です。
#include <bits/stdc++.h>
using namespace std;
void print_int(int x) {
cout << "x = " << x << endl;
}
int main() {
double a = 1.2345;
int b = 1;
// aがdouble型に変換されてからbとの足し算が行われる
// cout << a + (double)b << endl; と同じ結果
cout << a + b << endl;
int c = 2000000000;
int64_t d = 100;
// 初めにcがint64_t型へ変換されてからdとの掛け算が行われる
// cout << (int64_t)c * d << endl; と同じ結果
cout << c * d << endl;
double e = 3.141592;
int f = e; // ここでdouble型からint型への変換が起こる(小数点以下が切り捨てられて3になる)
cout << f << endl;
// int型を引数に取る関数にdouble型を渡す
print_int(e); // int型に変換されてから関数が実行される
}
実行結果
2.2345 200000000000 3 x = 3
なお、上の条件を満たす場合でも、キャストが行えない場合はコンパイルエラーとなります。
#include <bits/stdc++.h>
using namespace std;
void print_int(int x) {
cout << "x = " << x << endl;
}
int main() {
string s = "12345";
int x = s; // コンパイルエラー
print_int(s); // コンパイルエラー
}
関数の引数に別の型の値を渡す場合でも、STLのmin関数やmax関数のように暗黙的な型変換が行われない関数もあるという点に注意してください。
詳しくは4章の「テンプレート」で扱います。
細かい話
double型の精度と誤差
double型の内部について簡単に説明します。 double型では小数を扱うために「数字の並び」と「小数点の位置」を持っています。 そして、「数字の並び」で保持できる桁数はint型などと同じように上限があります。 double型では約16桁の並びを保持できます。逆に16桁を超える小数を正確に扱うことはできません。
表現できる桁数に限りがあるので、計算を行ったときに誤差が生じることがあります。
実際には精度を気にしなければならない場面は少ないかもしれませんが、ここでは情報落ちと桁落ちについて説明します。
情報落ち
差が極端に大きい2つの数を足し算することを考えます。 次のプログラムをみてください。
#include <bits/stdc++.h>
using namespace std;
int main() {
double x = 1000000000;
double y = 0.000000001;
// 1000000000.000000001 を表現するには19桁分必要 → 扱えない
double z = x + y; // yの分が消えてしまう
cout << fixed << setprecision(16);
cout << "x: " << x << endl;
cout << "y: " << y << endl;
cout << "z: " << z << endl;
}
実行結果
x: 1000000000.0000000000000000 y: 0.0000000010000000 z: 1000000000.0000000000000000
足す数それぞれがdoubleの精度で扱うことができても、それを足した後の値が表現できないことがあり、 そのような場合には桁が消えてしまいます。 このような現象を情報落ちといいます。
なるべく小さい数から順に足し算を行うことで、情報落ちの影響を減らすことができます。
桁落ち
差が極端に小さい2つの数を引き算することを考えます。
x, yは本来無限に桁が続く小数とします。 これらをコンピュータで扱おうとしたときに6桁までしか表現できず、それ以降の桁は0になってしまっているとします。
double型を用いた場合は約16桁まで扱えますが、説明のために6桁までしか表現できないとしています。
| 実際の値 | コンピュータ上での値 | |
|---|---|---|
| x | 0.1234567890123... | 0.123456 |
| y | 0.1233456789012... | 0.123345 |
ここで、z = x - yを考えます。
| 実際の値 | コンピュータ上での値 | |
|---|---|---|
| z = x - y | 0.0001111111111... | 0.000111 |
zの真の値は0.0001111111111...ですが、計算した結果は0.000111となっています。 5桁までの精度の数で計算を行ったにも関わらず、計算結果は3桁(3つの数字の並び)の精度になってしまっていることが分かります。
このように差が極体に小さい数同士の引き算を行うことによって値の精度が落ちてしまうことを桁落ちといいます。
桁落ちによって精度が落ちたまま計算を続けてしまうと最終的な計算結果の誤差が大きくなってしまうことがあります。
引き算を行う際にはなるべく差が大きくなるように計算順序を工夫したり、そもそも引き算をなるべく行わないように工夫する必要があります。
printfでの出力
printfという関数を呼ぶことでも出力することができます。
精度指定を行う場合やたくさんの値を出力する場合にはcoutよりもprintf関数を使う方が便利です。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x = 12345;
double pi = 3.14159265358979;
printf("x = %d, pi = %lf\n", x, pi);
}
実行結果
x = 12345, pi = 3.141593
printfの使い方は次の通りです。
printf(フォーマット文字列, 埋め込みたい値1, 埋め込みたい値2, ...)
「フォーマット文字列」の部分は後で説明するフォーマット指定子を含む文字列を自由に指定できます。 フォーマット指定子を書いた部分に「埋め込みたい値」が順番に埋め込まれます。
上のサンプルプログラムでは"x = %d, pi = %lf\n"と指定しています。
%dや%lfの部分がフォーマット指定子です。
1つ目の%dの部分にはxの内容が埋め込まれ、2つ目の%lfの部分にはpiの内容が埋め込まれます。
なお、\nは改行を意味します。
フォーマット指定子
埋め込みたい値の型によって対応するフォーマット指定子を使う必要があります、代表的なものは次の表のようになっています。
| 型 | フォーマット指定子 |
|---|---|
| int | %d |
| int64_t | %ld(%lld) |
| double | %lf |
| char | %c |
32ビットシステム上で
int64_tをprintfで出力する場合、フォーマット指定子は%lldとする必要があります。
なお、string型の文字列を出力する場合、次のように書く必要があります。
#include <bits/stdc++.h>
using namespace std;
int main() {
string s = "hello";
// フォーマット指定子 %s を用い s.c_str() を渡す
printf("%s\n", s.c_str());
}
実行結果
hello
さらにフォーマット指定子の部分を変更することで出力する小数の桁数などの出力の仕方を変更することができます。
#include <bits/stdc++.h>
using namespace std;
int main() {
double pi = 3.14159265358979;
// %.桁数f とすると小数点以下「桁数」だけ出力される
printf("%.10lf\n", pi);
int x = 1;
int y = 99;
int z = 123;
// %0桁数d とすると表示桁数が「桁数」に満たない場合に0埋めされる
printf("%03d, %03d, %03d\n", x, y, z);
}
実行結果
3.1415926536 001, 099, 123
printfにはここで紹介していない機能がたくさんあります。詳しく知りたい人は調べてみてください。
scanfでの入力
scanfという関数で入力を受け取ることもできます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x;
double pi;
// scanfによる入力
scanf("x = %d, pi = %lf", &x, &pi);
printf("x = %d, pi = %lf\n", x, pi);
}
入力
x = 12345, pi = 3.141593
実行結果
x = 12345, pi = 3.141593
scanfの使い方は次のとおりです。
scanf(フォーマット文字列, &変数1, &変数2, &変数3, ...);
引数に渡す変数の前に&が必要なことに注意してください。
この記号の意味については「4.05.ポインタ」で扱います。
フォーマット文字列は基本的にはprintfのものと同じです。
ただし、string型の文字列を直接入力することはできません。
この場合はcinを使ってください。
空白文字の扱い
%dなどのフォーマット指定子を指定した場合、直前に連続する空白文字を読み飛ばします。空白文字とはスペース()、改行文字(\n)、タブ文字(\t)などのことです。
以下のような呼び出しに対し、123 456という文字列を入力した場合、xは123となり、yは456となります。
scanf("%d%d", &x, &y);
文字列との変換
to_string関数
数値型から文字列に変換するには、to_string関数を用います。
to_string関数は、引数の数値をstring型に変換します。
#include <bits/stdc++.h>
using namespace std;
int main() {
int number = 100;
string s = to_string(number);
cout << s + "yen" << endl;
}
実行結果
100yen
stoi関数
文字列からint型に変換するには、stoi関数を用います。
#include <bits/stdc++.h>
using namespace std;
int main() {
string s = "100";
int n = stoi(s);
cout << n << endl;
}
実行結果
100
文字列から他の数値型への変換はそれぞれの型に対応する関数を用います。 対応表を次に示します。
| 型 | 文字列からの変換関数 |
|---|---|
int |
stoi |
int64_t |
stoll |
double |
stod |
これらの関数の使い方はstoi関数と同じです。
その他の型専用の関数も用意されていますが、基本的にint64_t型かdouble型にしてからキャストすればよいです。
他の数値型
int型やdouble型以外にも様々な数値型が用意されています。 これらは扱える値の範囲や精度、使用するメモリの量が異なります。
整数型
主な符号付き整数型
| 型 | 扱える値の範囲 | 使用するメモリ量 |
|---|---|---|
signed char |
-2^{7} 〜 2^{7}-1 | 1 byte (8 bit) |
short |
-2^{15} 〜 2^{15}-1 | 2 byte (16 bit) |
int |
-2^{31} 〜 2^{31}-1 | 4 byte (32 bit) |
long long |
-2^{63} 〜 2^{63}-1 | 8 byte (64 bit) |
int8_t |
-2^{7} 〜 2^{7}-1 | 1 byte (8 bit) |
int16_t |
-2^{15} 〜 2^{15}-1 | 2 byte (16 bit) |
int32_t |
-2^{31} 〜 2^{31}-1 | 4 byte (32 bit) |
int64_t |
-2^{63} 〜 2^{63}-1 | 8 byte (64 bit) |
主な符号無し整数型
| 型 | 扱える値の範囲 | 使用するメモリ量 |
|---|---|---|
unsigned char |
0 〜 2^{8}-1 | 1 byte (8 bit) |
unsigned short |
0 〜 2^{16}-1 | 2 byte (16 bit) |
unsigned int |
0 〜 2^{32}-1 | 4 byte (32 bit) |
unsigned long long |
0 〜 2^{64}-1 | 8 byte (64 bit) |
uint8_t |
0 〜 2^{8}-1 | 1 byte (8 bit) |
uint16_t |
0 〜 2^{16}-1 | 2 byte (16 bit) |
uint32_t |
0 〜 2^{32}-1 | 4 byte (32 bit) |
uint64_t |
0 〜 2^{64}-1 | 8 byte (64 bit) |
int??_t系やuint??_t系以外については、環境によっては上の表と異なることがあります。
使用するメモリについては、たとえば「long long型は64bitなので、変数1つに対してint型変数2つ分のメモリが必要」のように考えてください。
たくさんあってどう使い分けるのか分からなくなるかもしれませんが、
int??_t系やuint??_t系を使うことをおすすめします。
極端な話ですが、使用するメモリ量をそこまで気にしないのであれば全てint64_t型かuint64_t型を使ってしまうという手もあります。
実数型
| 型 | 扱える値の範囲(絶対値) | 扱える精度(10進数) | 使用するメモリ量 |
|---|---|---|---|
float |
約1.17×10^{-38} 〜 約3.40×10^{38} | 約8桁 | 4 byte (32 bit) |
double |
約2.22×10^{-308} 〜 約1.79×10^{308} | 約16桁 | 8 byte (64 bit) |
環境依存の仕様
環境によって扱える範囲が変わる整数型としてlongがあります。
longの扱える範囲は次の表のとおりです。
| Windows | Linux | mac OS X | |
|---|---|---|---|
| 32ビットシステム | int32_tと同じ |
int32_tと同じ |
int32_tと同じ |
| 64ビットシステム | int32_tと同じ |
int64_tと同じ |
int64_tと同じ |
AtCoder上で実行した場合は、longが扱える範囲はint64_tと同じになります。
プログラム中に直接書いた数値をlong型として扱うには、10Lのように末尾に1つのLをつけて書きます。
AtCoder上では
int64_tはlong型として扱われるため、厳密にはプログラム中に直接書いた数値をint64_tとして扱いたい場合には10Lのようにlong型に合わせて書いた方が正確ですが、他のシステム上でも同様に動くようにするために、「int64_t型として扱うためにはLLと書く」と説明しています。
size_t
配列や文字列のsize()で返ってくる要素数の値はsize_tという符号なしの整数型です。
C++ (GCC 9.2.1)においてsize_tはunsigned long(単なる別名)として定義されています。
実行環境によって、for文で
for (int i = 0; i < 配列.size(); i++)と書いたときに警告が出るのは、int型(符号付き)とsize_t型(符号無し)を比較しているためです。 しかし、暗黙的にキャストが行われるので動作には影響ありません。
符号なし整数のオーバーフロー
符号なし整数は負の数を扱えないため、例えばunsigned char型の0から1を引くと255となってしまいます。
size_t型は符号なしの整数型であるため、次のようなプログラムは意図した挙動になりません。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> data(0); // サイズ0
cout << data.size() - 1 << endl; // -1ではない
// 配列のサイズ-1回だけループしたい
for (int i = 0; i < data.size() - 1; i++) {
cout << i << endl;
}
}
実行結果の例
18446744073709551615 0 1 2 3 4 5 6 7 8 (省略)
この例では、ループ回数のdata.size() - 1がオーバーフローして18446744073709551615という値になってしまっています。
配列のサイズ-1回だけループしたい場合は、次のようにsize()の結果を符号付きにキャストする必要があります。
// 配列のサイズ-1回のループ(ただし、空の場合はループ内は実行されない)
for (int i = 0; i < (int)配列.size() - 1; i++) {
// 適当な処理
}
演習問題
今回は演習問題はありません。
次のAtCoder Beginner Contestの問題を解いてみてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
pair
- pair型は2つの値の組を表す
pair<値1の型, 値2の型> 変数名;で宣言する変数名.firstで1番目の値、変数名.secondで2番目の値にアクセスできるmake_pair(値1, 値2)でpairを生成することができるtie(変数1, 変数2) = pair型の値;でpairを分解することができる
tuple
- tuple型は複数個の値の組を表す
tuple<値1の型, 値2の型, 値3の型, (...)> 変数名;(必要な分だけ型を書く)で宣言するmake_tuple(値1, 値2, 値3, (...))でtupleを生成することができるtie(変数1, 変数2, 変数3, (...)) = tuple型の値;でtupleを分解することができる
pair/tupleの比較
- 1番目の値から比較され、等しい場合は次の値で比較される
auto
- 変数宣言や範囲for文において、autoを用いることで、型を省略して書くことができる
- autoで参照を作ることもできる
pair/tuple
pair
pairは2つの値の組を表す型です。
サンプルコード
#include <bits/stdc++.h>
using namespace std;
int main() {
pair<string, int> p("abc", 3);
cout << p.first << endl; // abc
p.first = "hello";
cout << p.first << endl; // hello
cout << p.second << endl; // 3
p = make_pair("*", 1);
string s;
int a;
tie(s, a) = p;
cout << s << endl; // *
cout << a << endl; // 1
}
実行結果
abc hello 3 * 1
宣言・初期化
pair<型1, 型2> 変数名; pair<型1, 型2> 変数名(値1, 値2);
アクセス
変数名.first // 1つ目の値 変数名.second // 2つ目の値
pairの生成
make_pair(値1, 値2)
make_pairによってpair型の値を得ることができます。
また、次のようにすることでもpairを生成することができます。
pair<型1, 型2>(値1, 値2)
どちらを使っても構いませんが、make_pairでは型を明示的に書く必要がないのでmake_pairを使うとよいでしょう。
細かい話で扱う型エイリアスを用いてpairの型に簡単な名前を付ける場合、後者の方が楽に書ける場合もあります。
pairの分解
型1 変数1; 型2 変数2; tie(変数1, 変数2) = pair型の値;
変数1、変数2にそれぞれpairの1番目の値、2番目の値が代入されます。
tuple
tupleはpairを一般化したもので、「複数個の値の組」を表す型です。
サンプルコード
#include <bits/stdc++.h>
using namespace std;
int main() {
tuple<int, string, bool> data(1, "hello", true);
get<2>(data) = false;
cout << get<1>(data) << endl; // hello
data = make_tuple(2, "WORLD", true);
int a;
string s;
bool f;
tie(a, s, f) = data;
cout << a << " " << s << " " << f << endl; // 2 WORLD 1
}
実行結果
hello 2 WORLD 1
宣言・初期化
tuple<型1, 型2, 型3, ...(必要な分だけ型を書く)> 変数名; tuple<型1, 型2, 型3, ...(必要な分だけ型を書く)> 変数名(値1, 値2, 値3, ...); // 初期化
tupleでは0個以上の組を表現することができます。
アクセス
get<K>(tuple型の変数) // K(定数)番目にアクセス
Kは定数でなければならないことと、Kは0から始まる数であることに注意してください。
次のように、Kとして変数を用いることはできません。
int i = 2; tuple<int, int, int> data(1, 2, 3); cout << get<i>(data) << endl; // コンパイルエラー
tupleの生成
make_tuple(値1, 値2, 値3, ...)
以下のようにして生成することもできます。
tuple<型1, 型2, 型3, ...(必要な分だけ書く)>(値1, 値2, 値3, ...)
tupleの分解
型1 変数1; 型2 変数2; 型3 変数3; ︙ tie(変数1, 変数2, 変数3, ...) = tuple型の値;
pair/tupleの比較
型が同じpairやtuple同士は比較することができます。
例えばpair<int, int>を比較する場合、1番目の値を基準に比較され、もし1番目の値が等しい場合は2番目の値を基準に比較されます。
#include <bits/stdc++.h>
using namespace std;
int main() {
pair<int, int> a(3, 1);
pair<int, int> b(2, 10);
// 3 > 2 なので a < b は false
if (a < b) {
cout << "a < b" << endl;
}
else {
cout << "a >= b" << endl;
}
pair<int, int> c(5, 1);
pair<int, int> d(5, 10);
// 5 == 5 であり 1 < 10 なので c < d は true
if (c < d) {
cout << "c < d" << endl;
}
else {
cout << "c >= d" << endl;
}
}
実行結果
a >= b c < d
tupleを比較する場合もpairと同様に「1番目の値が最優先で比較され、等しい場合は2番目の値で比較する。もし2番目の値も等しい場合は3番目の値を比較する……」と、1番目の値から順に比較されます。
なお、==は全ての値が等しい場合、!=は1つ以上の異なる値が存在する場合にtrueとなります。
pairやtupleの配列をソートする場合も上記の比較順序でソートされます。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<tuple<int, int, int>> a;
a.push_back(make_tuple(3, 1, 1));
a.push_back(make_tuple(1, 2, 100));
a.push_back(make_tuple(3, 5, 1));
a.push_back(make_tuple(1, 2, 3));
sort(a.begin(), a.end());
for (tuple<int, int, int> t : a) {
int x, y, z;
tie(x, y, z) = t;
cout << x << " " << y << " " << z << endl;
}
}
実行結果
1 2 3 1 2 100 3 1 1 3 5 1
auto
初期化を伴って変数を宣言する場合や範囲for文において、型の部分にautoと書くことによって型を省略することができます。
サンプルコード
#include <bits/stdc++.h>
using namespace std;
string concat(string a, string b) {
return a + b;
}
int main() {
string a = "Hello,";
string b = "World";
auto ab = concat(a, b); // string型
cout << ab << endl;
vector<int> c = {1, 2, 3};
auto d = c; // vector<int>型
for (auto elem : d) {
// elemはint型
cout << elem << endl;
}
}
実行結果
Hello,World 1 2 3
変数宣言でのauto
auto 変数名 = 初期値;
範囲for文でのauto
for (auto 変数名 : 配列変数) {
// 変数名 を使う
}
参照でのauto
int a = 12345;
auto &ref = a; // aへの参照 `int &ref = a;`と書くのと同じ
vector<int> b = {1, 2, 3};
// 範囲for文でも参照にすることができる
for (auto &elem : b) {
elem *= 2;
}
cout << b.at(0) << endl; // 2
cout << b.at(1) << endl; // 4
cout << b.at(2) << endl; // 6
細かい話
ignore
pairやtupleを分解する際に要らない要素を捨てたい場合、ignoreをtieの引数に渡すことで、対応する位置の値を捨てることができます。
#include <bits/stdc++.h>
using namespace std;
int main() {
pair<int, int> p(3, 5);
int right;
tie(ignore, right) = p; // 2番目の値だけ取り出す
cout << right << endl; // 5
tuple<int, string, bool> tpl(2, "hello", false);
int x;
string s;
tie(x, s, ignore) = tpl; // 1番目の値、2番目の値だけ取り出す
cout << x << " " << s << endl; // 2 hello
}
実行結果
5 2 hello
型エイリアス
型エイリアスを用いると型に別の名前をつけることができます。 pairやtupleなど型名が長くなってしまう場合に型エイリアスを使うと便利です。
#include <bits/stdc++.h>
using namespace std;
int main() {
using pii = pair<int, int>;
// これ以降 pii という型名はpair<int, int> と同じ意味で使える
pii p;
p = make_pair(1, 2);
cout << "(" << p.first << ", " << p.second << ")" << endl;
p = pii(3, 4); // 別のpairを作って代入
cout << "(" << p.first << ", " << p.second << ")" << endl;
}
実行結果
(1, 2) (3, 4)
次のようにして型エイリアスを宣言することができます。
型エイリアスの宣言
using 新しい型名 = 型名;
宣言した型エイリアスは型名として利用できます。
型エイリアスを用いることで、多次元配列の型を簡単に書くこともできます。
using vi = vector<int>; // intの1次元の型に vi という別名をつける using vvi = vector<vi>; // intの2次元の型に vvi という別名をつける int N = 10, M = 20; vvi data(N, vi(M)); // N * M の2次元配列
これまでプログラムの2行目に書いていたusing namespace std;にもusingというキーワードが出てきますが、このusingと型エイリアスのusingは違う意味なので注意してください。using namespace std;については4章で説明します。
なお、C++では同様の機能としてtypedef宣言が用意されていますが、基本的にはusingを使うようにしましょう。
#include <bits/stdc++.h>
using namespace std;
int main() {
typedef pair<int, int> pii; // pair<int, int> に pii という別名を付ける
pii p = make_pair(1, 2);
cout << "(" << p.first << ", " << p.second << ")" << endl;
}
実行結果
(1, 2)
演習問題
リンク先の問題を解いてください。
ABCの問題
今回紹介した機能を用いて解くことができるAtCoder Beginner Contestの問題を紹介します。 練習問題だけでは物足りない人は是非挑戦してみてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
map
- 連想配列や辞書と呼ばれるデータ構造
mapを用いると「特定の値に、ある値が紐付いている」ようなデータを扱うことができるmapの宣言
map<Keyの型, Valueの型> 変数名;
mapの操作
| 操作 | 記法 | 計算量 |
|---|---|---|
| 値の追加 | 変数[key] = value; |
O(\log N) |
| 値の削除 | 変数.erase(key); |
O(\log N) |
| 値へのアクセス | 変数.at(key) |
O(\log N) |
| 所属判定 | 変数.count(key) |
O(\log N) |
| 要素数の取得 | 変数.size() |
O(1) |
queue
- キューや待ち行列と呼ばれるデータ構造
queueを用いると「値を1つずつ追加していき、追加した順で値を取り出す」ような処理を行うことができるqueueの宣言
queue<型> 変数名;
queueの操作
| 操作 | 記法 | 計算量 |
|---|---|---|
| 要素の追加 | 変数.push(値); |
O(1) |
| 先頭の要素へのアクセス | 変数.front() |
O(1) |
| 先頭の要素を削除 | 変数.pop(); |
O(1) |
| 要素数の取得 | 変数.size() |
O(1) |
priority_queue
- 優先度付きキューと呼ばれるデータ構造
priority_queueを用いると「それまでに追加した要素のうち、最も大きいものを取り出す」という処理を行うことができるpriority_queueの宣言
priority_queue<型> 変数名;
priority_queueの操作
| 操作 | 記法 | 計算量 |
|---|---|---|
| 要素の追加 | 変数.push(値) |
O(\log N) |
| 最大の要素の取得 | 変数.top() |
O(1) |
| 最大の要素を削除 | 変数.pop(); |
O(\log N) |
| 要素数の取得 | 変数.size() |
O(1) |
- 値が小さい順に取り出される
priority_queueの宣言
priority_queue<型, vector<型>, greater<型>> 変数名;
STLのコンテナ
1.14.STLの関数でも触れましたが、 STLには便利な関数やデータ型が含まれています。 今回はこの中からいくつかのコンテナ型を紹介します。
map
mapは連想配列や辞書と呼ばれるデータ型です。
mapを用いると「特定の値に、ある値が紐付いている」ようなデータを簡単に扱うことができます。
例えば、氏名(string型の値)に成績(int型の値)が紐付いた次の表のようなデータを扱うとします。
| 氏名 | 成績 |
|---|---|
| "Alice" | 100 |
| "Bob" | 89 |
| "Charlie" | 95 |
これらのデータをmapを用いて表すと、次のようになります。
#include <bits/stdc++.h>
using namespace std;
int main() {
map<string, int> score; // 名前→成績
score["Alice"] = 100;
score["Bob"] = 89;
score["Charlie"] = 95;
cout << score.at("Alice") << endl; // Aliceの成績
cout << score.at("Bob") << endl; // Bobの成績
cout << score.at("Charlie") << endl; // Daveの成績
}
実行結果
100 89 95
以下説明のために、mapで扱うデータのうち、上の表でいう「氏名」の方をKey、「成績」の方をValueと呼ぶことにします。
宣言
mapは以下のように宣言します。
map<Keyの型, Valueの型> 変数名;
操作
以下の各操作の説明において、次の表のようなデータがscoreという変数に入っているとします。
| 氏名 | 成績 |
|---|---|
| "Alice" | 100 |
| "Bob" | 89 |
| "Dave" | 95 |
#include <bits/stdc++.h>
using namespace std;
int main() {
// 初期状態
map<string, int> score;
score["Alice"] = 100;
score["Dave"] = 95;
score["Bob"] = 89;
// (scoreに対する処理)
}
値の追加
変数[key] = value;
例
scoreに新しい成績のデータ「Charlie→70」を追加する例です。
score["Charlie"] = 70;
「Charlie→70」を追加した直後のscoreの中身は次の表のようになっています。
操作前
| 氏名 | 成績 |
|---|---|
| "Alice" | 100 |
| "Bob" | 89 |
| "Dave" | 95 |
操作後
| 氏名 | 成績 |
|---|---|
| "Alice" | 100 |
| "Bob" | 89 |
| "Charlie" | 70 |
| "Dave" | 95 |
値の削除
変数.erase(key);
keyに対応している関係を削除します。
例
scoreから「Bob→89」を削除するには次のようにします。
score.erase("Bob");
「Bob→89」を削除した直後のscoreの中身は次の表のようになっています。
操作前
| 氏名 | 成績 |
|---|---|
| "Alice" | 100 |
| "Bob" | 89 |
| "Dave" | 95 |
操作後
| 氏名 | 成績 |
|---|---|
| "Alice" | 100 |
| "Dave" | 95 |
アクセス
変数.at(key) // keyに対応するvalueが存在しない場合はエラーになる 変数[key] // keyに対応するvalueが存在しない場合はValueの型の初期値が追加される
アクセスしただけで新しいデータが追加されてしまうのはバグの元になりうるので、基本的には
.atを使うことをおすすめしますが、[]を用いてアクセスすることでプログラムを短く書けることがあります。
例
.atを使ってアクセスする例です。
cout << score.at("Alice") << endl; // 100
cout << score.at("Taro") << endl; // "Taro"に対応する値が存在しないためエラー
[]を使ってアクセスする例です。
score["Bob"] = 90; // "Bob"の成績を90点に変更 cout << score["Alice"] << endl; // 100 cout << score["Taro"] << endl; // 0 (scoreに"Taro"というkeyは存在しないため、0で初期化される)
[]で存在しないkey"Taro"をアクセスした結果、「Taro→0」というデータが追加されます。
また、Bobの成績が変更され、Taroの項目が追加されています。
操作前
| 氏名 | 成績 |
|---|---|
| "Alice" | 100 |
| "Bob" | 89 |
| "Dave" | 95 |
操作後
| 氏名 | 成績 |
|---|---|
| "Alice" | 100 |
| "Bob" | 90 |
| "Dave" | 95 |
| "Taro" | 0 |
所属判定
Keyに対応するValueが存在するか判定するには次のようにします。
if (変数.count(key)) {
// keyに対応する関係が存在する
}
else {
// keyに対応する関係が存在しない
}
例
if (score.count("Alice")) {
cout << "Alice: " << score.at("Alice") << endl;
}
if (score.count("Jiro")) {
cout << "Jiro: " << score.at("Jiro") << endl;
}
出力
Alice: 100
scoreのKeyには、"Alice"は存在し、"Jiro"は存在しないので、Alice: 100だけ出力されます。
この操作ではscoreの内容は変化しません。
操作前
| 氏名 | 成績 |
|---|---|
| "Alice" | 100 |
| "Bob" | 89 |
| "Dave" | 95 |
要素数の取得
変数.size()
いくつの対応関係が存在しているかを返します。
例
cout << score.size() << endl; // 3
scoreには次の表のように3つのデータがあるので、score.size()は3を返します。
この操作ではscoreの内容は変化しません。
操作前
| 氏名 | 成績 |
|---|---|
| "Alice" | 100 |
| "Bob" | 89 |
| "Dave" | 95 |
ループ
// Keyの値が小さい順にループ
for (pair<Keyの型, Valueの型> p : 変数名) {
Keyの型 key = p.first;
Valueの型 value = p.second;
// key, valueを使う
}
autoを用いると簡潔に書くことができます。
// Keyの値が小さい順にループ
for (auto p : 変数名) {
auto key = p.first;
auto value = p.second;
// key, valueを使う
}
ループではKeyの値が小さい順(pairの比較順)で取り出されます。対応関係を追加した順ではないことに注意してください。
例
scoreの内容をすべて出力する例です。
for (auto p : score) {
auto k = p.first;
auto v = p.second;
cout << k << " => " << v << endl;
}
出力
"Alice" => 100 "Bob" => 89 "Dave" => 95
計算量
要素数をNとしたときの各操作の計算量は以下の通りです。
| 操作 | 計算量 |
|---|---|
値の追加 [] |
O(\log N) |
値の削除 erase(key) |
O(\log N) |
値へのアクセス at |
O(\log N) |
所属判定 count |
O(\log N) |
要素数の取得 size |
O(1) |
queue
「値を1つずつ追加していき、追加した順で値を取り出す」ような処理を行うデータ構造をキューや待ち行列といいます。
C++では、STLに用意されているqueueを用いることができます。
キューは幅優先探索などのよく用いられるアルゴリズムに利用します。
キューの動作のイメージを次のスライドに示します。
1枚の図にすると次のようになります。数字はpushした順番を表しています。

使用例
queueの使い方の例です。上のスライドで説明した動作とは異なります。
#include <bits/stdc++.h>
using namespace std;
int main() {
queue<int> q;
q.push(10);
q.push(3);
q.push(6);
q.push(1);
// 空でない間繰り返す
while (!q.empty()) {
cout << q.front() << endl; // 先頭の値を出力
q.pop(); // 先頭の値を削除
}
}
実行結果
10 3 6 1
宣言
次のようにして空のキューを宣言できます。
queue<型> 変数名;
操作
要素を追加
変数.push(値);
先頭の要素へのアクセス
変数.front()
先頭の要素を削除
変数.pop(); // 先頭の要素が削除される
要素数の取得
変数.size()
キューが空であるかを調べる場合には、以下のように.empty()を用いることもできます。
変数.empty() // キューが空ならtrueを返す
計算量
各操作の計算量は以下の通りです。
| 操作 | 計算量 |
|---|---|
要素の追加 push |
O(1) |
先頭の要素へのアクセス front |
O(1) |
先頭の要素を削除 pop |
O(1) |
要素数の取得 size |
O(1) |
priority_queue
「それまでに追加した要素のうち、最も大きいものを取り出す」という処理を行うときには、優先度付きキューというデータ構造を用います。
C++ではSTLのpriority_queueを用いることができます。
優先度付きキューはダイクストラ法などで用いられます。 他にも優先度付きキューをうまく用いることで、計算量を減らすことが出来るケースがよくあります。
使用例
#include <bits/stdc++.h>
using namespace std;
int main() {
priority_queue<int> pq;
pq.push(10);
pq.push(3);
pq.push(6);
pq.push(1);
// 空でない間繰り返す
while (!pq.empty()) {
cout << pq.top() << endl; // 最大の値を出力
pq.pop(); // 最大の値を削除
}
}
実行結果
10 6 3 1
宣言
次のようにして空のpriority_queueを宣言できます。
priority_queue<型> 変数;
操作
要素を追加
変数.push(値);
最大の要素の取得
変数.top()
queueとは異なり、.front()では無いことに注意してください。
また、書き換えることは出来ないという点に注意してください。
最大の要素を削除
変数.pop()
要素数の取得
変数.size()
空であるかを調べる場合には、以下のように.empty()を用いることもできます。
変数.empty() // 空ならtrueを返す
計算量
priorty_queueの要素数をNとすると、各操作の計算量は以下の通りです。
| 操作 | 計算量 |
|---|---|
要素の追加 push |
O(\log N) |
最大の要素の取得 top |
O(1) |
最大の要素を削除 pop |
O(\log N) |
要素数の取得 size |
O(1) |
最小の要素を取り出す
次のようにしてpriority_queueを宣言すると、値が小さい順に取り出されるようになります。
priority_queue<型, vector<型>, greater<型>> 変数;
使用例
#include <bits/stdc++.h>
using namespace std;
int main() {
// 小さい順に取り出される優先度付きキュー
priority_queue<int, vector<int>, greater<int>> pq;
pq.push(10);
pq.push(3);
pq.push(6);
pq.push(1);
// 空でない間繰り返す
while (!pq.empty()) {
cout << pq.top() << endl; // 最小の値を出力
pq.pop(); // 最小の値を削除
}
}
実行結果
1 3 6 10
コピーや比較の計算量
vector, string, map, queue, priority_queueといったコンテナをコピーするときや、vectorやstringを比較するときにかかる計算量はO(N)です。
要素のたくさんあるコンテナを頻繁にコピーするようなコードは計算量が大きくなってしまうことがあるため、注意が必要です。
細かい話
set
setは重複の無いデータのまとまりを扱うためのデータ型です。
「Keyだけのmap」のようなイメージです。実際にmapで代用することもできます。
setは以下のような処理を行う場合などに有用です。
- 配列の中に出現する値の種類数(重複の無い集合の要素数)
- 集合の中にある値が含まれるかを高速に計算する
- 集合の中に含まれる最小値(最大値)を求める
以下はsetの使い方の例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
set<int> S;
S.insert(3);
S.insert(7);
S.insert(8);
S.insert(10);
// 既に3は含まれているのでこの操作は無視される
S.insert(3);
// 集合の要素数を出力
cout << "size: " << S.size() << endl;
// 7が含まれるか判定
if (S.count(7)) {
cout << "found 7" << endl;
}
// 5が含まれるか判定
if (S.count(5)) {
cout << "found 5" << endl;
}
}
実行結果
size: 4 found 7
宣言
set<値の型> 変数名;
操作
値の追加
変数.insert(値);
既に同じ値が存在する場合は追加されません。
値の削除
変数.erase(値);
所属判定
if (変数.count(値)) {
//「値」が含まれる
}
else {
//「値」は含まれない
}
要素数の取得
変数.size()
空であるかを調べる場合には、以下のように.empty()を用いることもできます。
変数.empty() // 空ならtrueを返す
最小値の取得
*begin(変数)
先頭に*を付ける必要があります。この記法については4章の「イテレータ」で扱います。
空のsetに対してこの操作を行ってはいけません。
実行時エラーにならないことがあるので注意してください。
最大値の取得
*rbegin(変数)
先頭に*を付ける必要があります。この記法については4章の「イテレータ」で扱います。
空のsetに対してこの操作を行ってはいけません。
実行時エラーにならないことがあるので注意してください。
ループ
for (auto value : 変数名) {
// valueを使う
}
ループでは値が小さいものから順に取り出されます。値を追加した順ではないことに注意してください。
計算量
要素数をNとしたときの各操作の計算量は以下の通りです。
| 操作 | 計算量 |
|---|---|
| 値の追加 | O(\log N) |
| 値の削除 | O(\log N) |
| 所属判定 | O(\log N) |
| 要素数の取得 | O(1) |
| 最小値の取得 | O(1) |
| 最大値の取得 | O(1) |
stack
「新しく追加したものほど先に取り出される」ような処理を行うデータ構造をスタックといいます。
C++では、STLのstackを用いることができます。
スタックの動作のイメージを次の図に示します。

上の図の数字はpushした順番を表しています。
使用例
#include <bits/stdc++.h>
using namespace std;
int main() {
stack<int> s;
s.push(10);
s.push(1);
s.push(3);
cout << s.top() << endl; // 3 (最後に追加した値)
s.pop();
cout << s.top() << endl; // 1 (その前に追加した値)
}
宣言
stack<値の型> 変数名;
操作
値の追加
変数.push(値);
次の値へのアクセス
変数.top()
値の削除
変数.pop();
要素数の取得
変数.size()
空であるかを調べる場合には、以下のように.empty()を用いることもできます。
変数.empty() // 空ならtrueを返す
計算量
要素数をNとしたときの各操作の計算量は以下の通りです。
| 操作 | 計算量 |
|---|---|
| 値の追加 | O(1) |
| 次の値へのアクセス | O(1) |
| 値の削除 | O(1) |
| 要素数の取得 | O(1) |
deque
「最初に追加したものを取り出す」というキューの操作と
「最後に追加した要素を取り出す」というスタックの操作を同時に行えるデータ構造を両端キューといいます。
C++では、STLのdequeを用いることができます。(「デック」と読みます。)
先頭と末尾に対して追加・削除が行える配列のようなイメージです。 「i番目の値にアクセスする」こともできます。
#include <bits/stdc++.h>
using namespace std;
int main() {
deque<int> d;
d.push_back(10);
d.push_back(1);
d.push_back(3);
// この時点で d の内容は { 10, 1, 3 } となっている
cout << d.front() << endl; // 10 (先頭の要素)
d.pop_front(); // 先頭を削除
// この時点で d の内容は { 1, 3 } となっている
cout << d.back() << endl; // 3 (末尾の要素)
d.pop_back(); // 末尾を削除
// この時点で d の内容は { 1 } となっている
d.push_front(5);
d.push_back(2);
// この時点で d の内容は { 5, 1, 2 } となっている
cout << d.at(1) << endl; // 1
}
宣言
deque<値の型> 変数名;
操作
値の追加
変数.push_back(値); // 末尾への値の追加 変数.push_front(値); // 先頭への値の追加
値のアクセス
変数.front() // 先頭の値へのアクセス 変数.back() // 末尾の値へのアクセス 変数.at(i) // i番目へのアクセス
存在しない要素へのアクセスは実行時エラーとなります。
空のdequeに対して.front()や.back()を呼んだ際の動作は未定義です。
実行時エラーにならないことがあるので注意してください。
値の削除
変数.pop_front(); // 先頭の要素の削除 変数.pop_back(); // 末尾の要素の削除
要素数の取得
変数.size()
空であるかを調べる場合には、以下のように.empty()を用いることもできます。
変数.empty() // 空ならtrueを返す
計算量
要素数をNとしたときの各操作の計算量は以下の通りです。
| 操作 | 計算量 |
|---|---|
| 値の追加 | O(1) |
| 値のアクセス | O(1) |
| 値の削除 | O(1) |
| 要素数の取得 | O(1) |
unordered_map
C++のSTLのunordered_mapは、基本的な機能はmapと同じですがアクセスや検索を高速に行うことができるデータ構造です。
ただし、Keyとしてpairを直接用いることができないなどの制約もあります。
制約
- pairやtupleなどのハッシュ関数が定義されていない型をKeyとして用いることができない
- ループで取り出すときに、どのような順番で取り出されるかが分からない
APG4bでこれまでに紹介した型のうち、pair/tuple以外の型であればKeyとして使用可能です。
ハッシュ関数についてはここでは説明しませんが、詳しく知りたい人は調べてみてください。
計算量
要素数をNとしたときの各操作の計算量は以下の通りです。
| 操作 | 計算量 |
|---|---|
値の追加 [] |
平均O(1) |
値の削除 erase |
平均O(1) |
値へのアクセス at |
平均O(1) |
所属判定 count |
平均O(1) |
要素数の取得 size |
O(1) |
オーダー記法の上ではすべて平均で定数時間となっていますが、定数倍の関係で実際の速度がmapより速いとは限らないということに注意してください。
unordered_set
C++のSTLのunordered_setは、unordered_mapと同様に、制約がある代わりに高速なsetです。
制約
- pairやtupleなどのハッシュ関数が定義されていない型をKeyとして用いることができない
- ループで取り出すときに、どのような順番で取り出されるかが分からない
- 最大値や最小値を取り出すことができない
計算量
要素数をNとしたときの各操作の計算量は以下の通りです。
| 操作 | 計算量 |
|---|---|
値の追加 insert |
平均O(1) |
値の削除 erase |
平均O(1) |
値へのアクセス at |
平均O(1) |
所属判定 count |
平均O(1) |
要素数の取得 size |
O(1) |
オーダー記法の上ではすべて平均で定数時間となっていますが、定数倍の関係で実際の速度がsetより速いとは限らないということに注意してください。
lower_bound / upper_bound (STLの関数)
昇順にソートされた配列において、「x以上の最小の要素」を求める場合にはSTLのlower_boundを使うことができます。同様に、「xを超える最小の要素」を求めるときにはupper_boundを使うことができます。
計算量は、配列の要素数をNとするとどちらもO(\log N)です。
使用例
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> a = {0, 10, 13, 14, 20};
// aにおいて、12 以上最小の要素は 13
cout << *lower_bound(a.begin(), a.end(), 12) << endl; // 13
// 14 以上最小の要素は 14
cout << *lower_bound(a.begin(), a.end(), 14) << endl; // 14
// 10 を超える最小の要素は 13
cout << *upper_bound(a.begin(), a.end(), 10) << endl; // 13
}
使い方
*lower_bound(配列.begin(), 配列.end(), 値) // 「値」以上の最小の値 *upper_bound(配列.begin(), 配列.end(), 値) // 「値」を超えるの最小の値
先頭に*を付ける必要があります。この記法については4章の「イテレータ」で扱います。
空のコンテナに対する操作
空のqueueに対して.front()を呼び出したり、空のsetに対する*変数.begin()のような操作を行った場合の動作は未定義で、実行時エラーになるとは限らないということを説明しました。
1.13.配列でも紹介したように、#define _GLIBCXX_DEBUG(Clang環境では#define _LIBCPP_DEBUG 0)をプログラムの1行目に書くことによって、このような操作を行ってしまった際に実行時エラーにすることができます。
#define _GLIBCXX_DEBUG
#include <bits/stdc++.h>
using namespace std;
int main() {
// ...
}
演習問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 構造体によって、「複数の型をまとめた新しい型」を作ることが出来る
- 構造体の定義
struct 構造体名 {
型1 メンバ変数名1
型2 メンバ変数名2
型3 メンバ変数名3
...(必要な分だけ書く)
}; // ← セミコロンが必要
- 構造体の変数の宣言
構造体名 変数名;
- 構造体型の値のことをオブジェクトという
- 宣言と同時に初期化
構造体名 オブジェクト名 = {メンバ変数1の値, メンバ変数2の値, メンバ変数3の値, ...(必要な分だけ書く)};
- メンバ変数・メンバ関数はそれぞれオブジェクトに紐付いた変数・関数として使うことができる
- メンバ変数へのアクセス
オブジェクト.メンバ変数
- メンバ関数の定義
struct 構造体名 {
返り値の型 メンバ関数名(引数の型1 引数名1, 引数の型2 引数名2, ...) {
// 関数の内容
// (ここではメンバ変数に直接アクセスすることができる)
}
};
- メンバ関数の呼び出し
オブジェクト.メンバ関数(引数1, 引数2, ...)
構造体
「3.02.pair/tupleとauto」で複数のデータをまとめる方法としてSTLのpair/tupleを紹介しました。 別の方法として構造体を利用することもできます。 実はSTLのpair/tupleも構造体を使って実装されています。
構造体関連の機能はたくさんあるので、このページでは主要なものを簡単に説明します。
構造体を用いることで、「複数の型をまとめた新しい型」を定義することができます。
次のプログラムを見てください。
#include <bits/stdc++.h>
using namespace std;
struct MyPair {
int x; // 1つ目のデータはint型であり、xという名前でアクセスできる
string y; // 2つ目のデータはstring型であり、yという名前でアクセスできる
};
int main() {
MyPair p = {12345, "hello"}; // MyPair型の値を宣言
cout << "p.x = " << p.x << endl;
cout << "p.y = " << p.y << endl;
}
実行結果
p.x = 12345 p.y = hello
MyPairという構造体を定義しています。
この構造体はint型とstring型をまとめたもので、それぞれx, yという名前がついています。
これら1つ1つのデータをメンバ変数といいます。
構造体の定義
次の形式で構造体を定義します。
struct 構造体名 {
型1 メンバ変数名1
型2 メンバ変数名2
型3 メンバ変数名3
...(必要な分だけ書く)
}; // ← セミコロンが必要
構造体の定義は関数の外側、内側のどちらにも書くことができます。
構造体を定義することによって新しい型が使えるようになります。
例えば、上の例ではMyPairという構造体を定義したので、それ以降MyPairという型が使えるようになります。
宣言・初期化
構造体の変数を宣言するには、通常の変数の宣言と同じように次のように書きます。
構造体名 変数名;
また、次のように構造体名を用いて構造体の値を生成することもできます。
auto 変数名 = 構造体名();
構造体名を使う方法は一時変数を作りたい場合に便利です。
なお、構造体型の値のことをオブジェクトといいます。
例えば、はじめのサンプルプログラムの
pはMyPair型のオブジェクトです。
宣言と同時に、メンバ変数の初期化を行う場合は次のようにします。
構造体名 オブジェクト名 = {メンバ変数1の値, メンバ変数2の値, メンバ変数3の値, ...(必要な分だけ書く)};
メンバ変数
構造体が持っている変数をメンバ変数といいます。
メンバ変数へのアクセスは次のようにします。
オブジェクト.メンバ変数
メンバ変数は、通常の変数と同じように使うことができます。
なお通常の変数と同様に、オブジェクトを宣言しただけではメンバ変数の値は未定である点に注意してください。
メンバ関数
構造体には、オブジェクトに関連した処理を行う関数を定義することができ、この関数をメンバ関数といいます。
メンバ関数は次のように定義します。
struct 構造体名 {
返り値の型 メンバ関数名(引数の型1 引数名1, 引数の型2 引数名2, ...) {
// 関数の内容
// (ここではメンバ変数に直接アクセスすることができる)
}
};
メンバ関数を呼び出すには次のようにします。
オブジェクト.メンバ関数(引数1, 引数2, ...)
メンバ関数の特徴は「メンバ関数が紐付いているオブジェクトのメンバ変数」に関数内からアクセスする場合に、オブジェクトの指定なしに直接アクセスできることです。 この点を除けば、通常の関数と同じように使うことができます。
メンバアクセスの機能を使う場合には、メンバ関数と通常の関数では違いがありますが、 APG4bで扱う範囲内では基本的に通常の関数と同様に使うことができます。
次のサンプルプログラムで確認してください。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
struct MyPair {
int x;
string y;
// メンバ関数
void print() {
// 直接x, yにアクセスできる
cout << "x = " << x << endl;
cout << "y = " << y << endl;
}
};
int main() {
MyPair p = { 12345, "Hello" };
p.print(); // オブジェクト`p`の`print`を呼び出す
MyPair q = { 67890, "APG4b" };
q.print(); // オブジェクト`q`の`print`を呼び出す
}
実行結果
x = 12345 y = Hello x = 67890 y = APG4b
細かい話
コンストラクタ
オブジェクトが作られるときに、独自の初期化処理などを行いたい場合にコンストラクタを使うことができます。
コンストラクタは次のように定義します。
struct 構造体名 {
// コンストラクタ
構造体名() {
// コンストラクタの内容
}
};
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
struct MyPair {
int x;
string y;
// コンストラクタ
MyPair() {
cout << "constructor called" << endl;
}
};
int main() {
MyPair p; // ここでコンストラクタが呼ばれる
p.x = 12345;
p.y = "hello";
cout << "p.x = " << p.x << endl;
cout << "p.y = " << p.y << endl;
}
実行結果
constructor called p.x = 12345 p.y = hello
コンストラクタはメンバ関数と同様に引数を取ることができます。
struct 構造体名 {
// コンストラクタ
構造体名(引数1の型 引数1の名前, 引数2の型 引数2の名前, ...) {
// コンストラクタの内容
}
};
コンストラクタが引数を取る場合、次のようにオブジェクトの宣言時にコンストラクタの引数に対応する値を渡す必要があります。
構造体名 オブジェクト名(引数1, 引数2, 引数3, ...);
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
struct NumString {
int length;
string s;
// コンストラクタ
NumString(int num) {
cout << "constructor called" << endl;
// 引数のnumを文字列化したものをsに代入し、sの文字数をlengthに代入する
s = to_string(num); // (STLの関数)
length = s.size();
}
};
int main() {
NumString num(12345); // コンストラクタに 12345 が渡される
cout << "num.s = " << num.s << endl;
cout << "num.length = " << num.length << endl;
}
実行結果
constructor called num.s = 12345 num.length = 5
コンストラクタは複数定義することができ、与える引数の型や引数の個数によって自動的に呼び分けることができます。
#include <bits/stdc++.h>
using namespace std;
struct MyPair {
int x;
string y;
// コンストラクタ1
MyPair() {
cout << "初期化無し" << endl;
}
// コンストラクタ2
MyPair(int x_) {
cout << "xのみ初期化" << endl;
x = x_;
}
// コンストラクタ3
MyPair(int x_, string y_) {
cout << "x, y両方初期化" << endl;
x = x_;
y = y_;
}
};
int main() {
MyPair p; // コンストラクタ1が呼ばれる
cout << "p.x = " << p.x << endl;
cout << "p.y = " << p.y << endl;
MyPair q(6789); // コンストラクタ2が呼ばれる
cout << "q.x = " << q.x << endl;
cout << "q.y = " << q.y << endl;
MyPair r(11111, "good bye"); // コンストラクタ3が呼ばれる
cout << "r.x = " << r.x << endl;
cout << "r.y = " << r.y << endl;
}
実行結果(例)
初期化無し p.x = 4198608 p.y = xのみ初期化 q.x = 6789 q.y = x, y両方初期化 r.x = 11111 r.y = good bye
なお、{}を使ったオブジェクトの初期化を行う場合、コンストラクタの引数に対応するものを{}で囲む必要があります。
構造体名 オブジェクト名 = {引数1, 引数2, 引数3, ...};
メンバ変数ではなく、コンストラクタの引数を{}で囲むことに注意してください。
コピーコンストラクタ
コンストラクタはオブジェクトが作られる際に呼ばれますが、 関数の引数としてオブジェクトを渡す場合などの条件を満たした場合には、コピーコンストラクタという特殊なコンストラクタが呼ばれます。
次のような場合にコピーコンストラクタが呼ばれます。
- 関数の引数としてオブジェクトを渡した場合
- オブジェクトを宣言する際に
MyStruct new_obj = old_obj;で初期化する場合 - オブジェクトを宣言する際に
MyStruct new_obj(old_obj);の形で初期化する場合 - など
コピーコンストラクタについては込み入った話が多くなるので、基本的なことのみ紹介します。
コピーコンストラクタは次のように定義します。
struct 構造体名 {
// コピーコンストラクタ
構造体名(const 構造体名 &old) {
// コンストラクタの内容
// (oldの内容を使って初期化などを行う)
}
};
constは変数の内容を書き換えられなくなる機能です。この例では、
oldのメンバ変数を書き換えることができなくなっています。 詳しくは3.07で扱います。
引数名をoldとしましたが、自由に名前をつけて良いです。
なお、コピーコンストラクタを定義しなかった場合には、 「全てのメンバ変数をそのままコピーして新しいオブジェクトを作る」 という動作をするコピーコンストラクタが自動的に作られるので、 ただコピーしたいだけならコピーコンストラクタを自分で書く必要はありません。
コピーコンストラクタの呼び出しはコンパイラの最適化によって省略される場合があるので注意が必要です。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
struct MyPair {
int x;
string y;
// コンストラクタ
MyPair() {
cout << "normal constructor called" << endl;
}
// コピーコンストラクタ
MyPair(const MyPair &old) {
cout << "copy constructor called" << endl;
x = old.x + 1;
y = old.y + " new";
}
};
int main() {
MyPair p; // ここでコンストラクタが呼ばれる
p.x = 12345;
p.y = "hello";
cout << "p.x = " << p.x << endl;
cout << "p.y = " << p.y << endl;
MyPair q(p); // コピーコンストラクタが呼ばれる
cout << "q.x = " << q.x << endl;
cout << "q.y = " << q.y << endl;
MyPair r = q; // コピーコンストラクタが呼ばれる
cout << "r.x = " << r.x << endl;
cout << "r.y = " << r.y << endl;
}
実行結果
normal constructor called p.x = 12345 p.y = hello copy constructor called q.x = 12346 q.y = hello new copy constructor called r.x = 12347 r.y = hello new new
このサンプルプログラムのように、通常のコンストラクタとコピーコンストラクタを同時に定義することもできます。
演算子オーバーロード
新たに定義した構造体型のオブジェクトに対してC++の演算子を使えるようにすることができ、この機能を演算子オーバーロードといいます。
演算子オーバーロードを行える演算子は限られてはいますが、殆どの演算子をオーバーロードすることができます。
演算子オーバーロードの使用はプログラムがシンプルになる一方で、意味がわかりにくくなることもあるので注意しましょう。
極端な例では、
+という演算子に引き算をさせるようなこともできてしまいますが、このような非自明な挙動はなるべく避けるべきです。
+演算子のオーバーロード
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
struct MyPair {
int x;
string y;
// 別のMyPair型のオブジェクトをとって、x, yにそれぞれ+したものを返す
// +演算子をオーバーロード
MyPair operator+(const MyPair &other) {
MyPair ret;
ret.x = x + other.x; // ここではint型の+演算子が呼ばれる
ret.y = y + other.y; // ここではstring型の+演算子が呼ばれる
return ret;
}
};
int main() {
MyPair a = {123, "hello"};
MyPair b = {456, "world"};
// MyPair型の+演算子が呼ばれる
MyPair c = a + b;
cout << "c.x = " << c.x << endl;
cout << "c.y = " << c.y << endl;
}
実行結果
c.x = 579 c.y = helloworld
演算子オーバーロードをメンバ関数として定義しています。
+演算子をオーバーロードする場合は次のように定義します。
struct 構造体名 {
返り値の型 operator+(引数の型 引数) {
// 処理内容
}
};
返り値や引数の型は自由に決めることができます。ただし、引数の個数は1つです。
+演算子のオーバーロードは構造体の外側で定義することもできます。
下の「外側で定義する場合」で説明します。
代入演算子のオーバーロード
=演算子(代入演算子)も他の演算子と同様にオーバーロードによって動作をカスタマイズすることができます。
オーバーロードを行わなかった場合、代入演算子は自動的に定義されます。 自動的に定義される代入演算子では、「全てのメンバ変数をそのまま代入していく」というような処理が行われます。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
struct MyPair {
int x;
string y;
// 代入演算子をオーバーロード
void operator=(const MyPair &other) {
cout << "= operator called" << endl;
x = other.x;
y = other.y;
}
};
int main() {
MyPair a = {123, "hello"};
MyPair b;
b = a; // 代入演算子が呼ばれる
cout << "b.x = " << b.x << endl;
cout << "b.y = " << b.y << endl;
}
実行結果
= operator called b.x = 123 b.y = hello
代入演算子のオーバーロードは次のように定義します。
void operator=(const 構造体名 &other) {
// 処理内容
}
その他の演算子のオーバーロード
他の演算子も同様にオーバーロードすることができます。 メンバ関数として演算子オーバーロードを定義する場合、次のようにします。
struct 構造体の型 {
返り値の型 operator演算子(引数の型 引数) {
// 処理内容
}
};
「演算子」の部分には、+, -, *, /, %, <, >, ==, !=, &&, ||などを書きます。
外側で定義する場合
構造体の外側で演算子オーバーロードを行うと、
自分が定義していない構造体(例えばSTLのpairなど)に対しても演算子をオーバーロードすることができます。
構造体の外側で演算子オーバーロードを定義する場合は、次のようにします。
返り値の型 operator演算子(引数の型1 引数1, 引数の型2 引数2) {
// 処理内容
}
以下はpair<int, int>に対する演算子オーバーロードのサンプルプログラムです。
pairに対して+演算子をオーバーロードする例
+演算子をオーバーロードする例#include <bits/stdc++.h>
using namespace std;
pair<int, int> operator+(pair<int, int> a, pair<int, int> b) {
pair<int, int> ret;
ret.first = a.first + b.first;
ret.second = a.second + b.second;
return ret;
}
int main() {
pair<int, int> a = {1, 2};
pair<int, int> b = {3, 4};
auto c = a + b;
cout << c.first << ", " << c.second << endl; // 4, 6
}
実行結果
4, 6
pairの<演算子をオーバーロードして.secondを優先して比較するように変更する例
<演算子をオーバーロードして.secondを優先して比較するように変更する例#include <bits/stdc++.h>
using namespace std;
// .second → .first の順に比較
bool operator<(pair<int, int> l, pair<int, int> r) {
if (l.second != r.second) {
return l.second < r.second;
} else {
return l.first < r.first;
}
}
// <演算子 を用いて定義
bool operator> (pair<int, int> l, pair<int, int> r) { return r < l; }
bool operator<=(pair<int, int> l, pair<int, int> r) { return !(r < l); }
bool operator>=(pair<int, int> l, pair<int, int> r) { return !(l < r); }
int main() {
pair<int, int> a = {1, 5};
pair<int, int> b = {3, 2};
cout << (a < b) << endl; // 0
cout << (a > b) << endl; // 1
}
実行結果
0 1
なお、複合代入演算子(+=, -=, *=, /=, %=など)は構造体の外側で定義することはできないことに注意してください。
STLのコンテナの要素として使う場合の注意
STLのコンテナや関数は、特定の演算子を要求することがあります。
次のような場合には比較演算子<をオーバーロードする必要があります。
mapのKeyとして構造体を使う場合priority_queueの要素の型として構造体を使う場合- 構造体の配列に対して
sort関数を使う場合
比較演算子<は次のように定義します。
bool operator<(const 構造体名 &left, const 構造体名 &right) {
// left < right の場合に true を返すように実装する
}
メンバ初期化子リスト
メンバ変数を初期化する方法として、メンバ初期化子リストを使う方法があります。
基本的にはコンストラクタ内で代入するのと変わりませんが、 例えばメンバ変数が参照型である場合のように、コンストラクタ内で初期化することができない場合には、 メンバ初期化子リストで初期化する必要があります。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
struct MyPair {
int x;
string y;
// 初期化子リストを用いた初期化
MyPair() : x(123), y("hello") {
}
};
int main() {
MyPair p; // コンストラクタにより初期化される
cout << "p.x = " << p.x << endl;
cout << "p.y = " << p.y << endl;
}
実行結果
p.x = 123 p.y = hello
メンバ初期化子リストは次のようにコンストラクタに:を続けて書きます。
struct 構造体名 {
型1 メンバ変数1;
型2 メンバ変数2;
...(必要な分だけ書く)
構造体名() : メンバ変数名1(初期化内容), メンバ変数名2(初期化内容), ...(必要な分だけ書く)
{
}
};
初期化の部分には、メンバ変数名{初期化内容1, 初期化内容2, ...}のように書くこともできます。
クラス
C++には構造体とほとんど同じ機能であるクラスがあります。
クラスと構造体の違いはメンバアクセスのデフォルトの挙動です。 メンバアクセスについてはAPG4bでは扱いませんが、メンバ変数やメンバ関数を使用できる範囲を制限する機能です。 「メンバ関数の中からしか扱えないメンバ変数」や「メンバ関数の中でしか呼べないメンバ関数」などを実現できます。
デフォルトのメンバアクセスが、クラスはプライベートメンバアクセス(
private:を指定したときの挙動)で、構造体はパブリックメンバアクセス(public:を指定したときの挙動)です。
クラス(構造体)には継承という機能もあり、 オブジェクト指向プログラミングを行う際に便利なさまざまな機能が用意されています。 興味のある人は調べてみてください。
扱わなかった構造体関連の機能のリスト
このページで紹介しきれなかった機能のリストを次に示します。 より詳しく勉強したい人は調べてみてください。
- デストラクタ
- メンバアクセス
- 継承
- 静的メンバ変数/関数
- friend宣言
- union
- ビットフィールド
- など
演習問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 「0」か「1」の2通りの状態を表現することができるデータの単位をビットといい、ビットを複数並べたものをビット列という
- 次の表のようなビット列に関する演算をビット演算という
| ビット演算 | 演算子 | 意味 |
|---|---|---|
| ビット毎のAND演算 | & |
各ビットについて「両方のビットが1ならば1」という操作を適用する。 |
| ビット毎のOR演算 | | |
各ビットについて「少なくとも一方のビットが1ならば1」という操作を適用する。 |
| ビット毎のXOR演算 | ^ |
各ビットについて「どちらか一方だけが1ならば1」という操作を適用する。 |
| ビット毎のNOT演算 | ~ |
各ビットについて「ビットを反転する」という操作を適用する。 |
| 左シフト演算 | << |
指定したビット数だけビット列を左にずらす。範囲外のビットは切り捨てられ、足りないビットは0で埋められる。 |
| 右シフト演算 | >> |
指定したビット数だけビット列を右にずらす。範囲外のビットは切り捨てられ、足りないビットは0で埋められる。 |
- ビット演算を用いると集合を便利に扱えることがある
- C++でビット列を扱うときは
bitsetを用いる
bitset<ビット数> 変数名; // すべてのビットが0の状態で初期化される
bitset<ビット数> 変数名("ビット列(長さはビット数に合わせる)"); // 指定したビット列で初期化される
変数.set(位置, 値); // ビットの値を変更
変数.test(位置); // ビットの値を調べる
- C++の整数型を用いることで(通常)64ビットまでのビット列を扱うことができる
- ビット演算の演算子は優先順位を間違えやすいため、明示的に
()でくくるようにする
ビット演算
初めにビット演算の概念について説明し、その後にC++でビット演算を行う方法を紹介します。
ビット
「0」か「1」の2通りの状態を表現することができるデータの単位をビットといいます。
ビットをいくつか並べたものをビット列といいます。 例えば「0011」は4ビットのビット列で、「10101010」は8ビットのビット列です。
ビット演算
ビット列に関する演算をビット演算といいます。
以下の6つのビット演算を紹介します。
- AND演算
- OR演算
- XOR演算
- NOT演算
- 左シフト演算
- 右シフト演算
AND演算
下の表で定義される演算をAND演算(または論理積)といいます。 このAND演算をビット毎に適用する演算をビット毎のAND演算(bitwise AND)といいます。
| x | y | x AND y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
AND演算ではx, yのビットが共に1の場合のみ結果が1になります。
具体例
0111 AND 0100 = 0100
縦に並べると次のようになります。
0111 AND 0100 -------- = 0100
OR演算
下の表で定義される演算をOR演算(または論理和)といいます。 ビット毎にOR演算を適用する演算をビット毎のOR演算(bitwise OR)といいます。
| x | y | x OR y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
OR演算ではx, yのビットの少なくとも一方が1の場合に結果が1となります。 逆に言うと、共に0の場合のみ結果が0となります。
具体例
0111 OR 0100 = 0111
縦に並べると次のようになります。
0111 OR 0100 -------- = 0111
XOR演算
下の表で定義される演算をXOR演算(または排他的論理和)といいます。 ビット毎にXOR演算を適用する演算をビット毎のXOR演算(bitwise XOR)といいます。
| x | y | x XOR y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
XOR演算ではx, yのビットの一方が1の場合に限り結果が1となります。 x, yのビットが等しい場合に0になると見ることもできます。
具体例
0111 XOR 0100 = 0011
縦に並べると次のようになります。
0111 XOR 0100 -------- = 0011
NOT演算
下の表で定義される演算をNOT演算といいます。 ビット毎にNOT演算を適用する演算をビット毎のNOT演算(bitwise NOT)といいます。
| x | NOT x |
|---|---|
| 0 | 1 |
| 1 | 0 |
NOT演算は単にビットを反転する演算で、0のビットは1に、1のビットは0になります。
具体例
NOT 0111 = 1000
縦に並べると次のようになります。
NOT 0111 -------- = 1000
左シフト演算
ビット列を左向きにずらす操作を論理左シフト演算や単に左シフトといいます。
論理左シフト演算ではずらした後にはみ出た部分のビットは捨てられ、足りない部分のビットは0で埋められます。
具体例
0111 を2ビット左シフトすると 1100
縦に並べると次のようになります。
2ビット左シフト
|0111|
01|11 |
----------
= |1100|
はみ出た「01」の部分は切り捨てられ、右端の2ビット分は0で埋められます。
右シフト演算
ビット列を右向きにずらす演算を論理右シフト演算や単に右シフトといいます。
論理左シフト演算と同様に、ずらした後にはみ出た部分のビットは捨てられ、足りない部分のビットは0で埋められます。
具体例
0111 を2ビット右シフトすると 0001
縦に並べると次のようになります。
2ビット右シフト
|0111|
| 01|11
----------
= |0001|
はみ出た「11」の部分は切り捨てられ、左端の2ビット分は0で埋められます。
ビット演算の使い道
ビット演算は集合の演算を行ったり、高速な演算が必要な場合に用いられます。
集合の操作
ビット列を用いると物の集まり(以下、集合と呼びます)を表現することができます。 ある要素を含むなら対応するビットを1にし、含まないなら対応するビットを0にすることで表現することができます。
具体例
例えば、1〜10の数が書かれたカードのうち、いくつかを手札として持っているとき、この手札を10ビットのビット列を用いて表現できます。 ここでは「カードに書かれた数に対応する位置のビットを1にする」というルールで手札をビット列に対応付けることにします。 例えば{2, 3, 7}という手札は「0110001000」というビット列に対応します。 2が書かれたカードは含まれるので、(左から)2ビット目が1になっています。 5が書かれたカードは含まれないので、5ビット目は0になっています。
このようにビット列で表現しておくと、 例えば「2人の手札に共通して含まれるカードを求めたい」ときに、 2人の手札のビット列に対してビット毎のAND演算を行うことで 「2人の手札に共通して含まれるカードの集合」に対応するビット列を一度に得ることができます。
集合の操作とビット演算の対応の例
| 操作 | 対応するビット演算 |
|---|---|
| 2つの集合に共通している要素を取り出す | ビット毎のAND演算 |
| 2つの集合のうち少なくとも一方に存在する要素を取り出す | ビット毎のOR演算 |
| ある集合に含まれない要素取り出す | ビット毎のNOT演算 |
もちろん、配列を用いて同様の集合演算を行うことは出来ます。 しかし、上の表に挙げたような単純な集合の操作であれば、 ビット演算を用いることでプログラムがシンプルになったり高速になったりするメリットがあります。
2つの集合から共通する要素を取り出す例
A = {1, 2, 3, 5, 7}とB = {1, 3, 5, 7, 9}という2つの集合に共通する要素は{1, 3, 5, 7}です。 Aに対応するビット列は「1110101000」で、Bに対応するビット列は「1010101010」です。 これらにビット毎のAND演算を適用すると、「1010101000」となり、これは集合{1, 3, 5, 7}を意味しており、共通する要素を取り出せていることが分かります。
高速化
ビット演算では複数のビットについての計算をまとめて行えるので、 この性質をうまく活かすとプログラムを高速化できることがあります。
STLのbitset
C++でビット列を扱うにはbitsetを用います。
宣言・初期化
bitset<ビット数> 変数名; // すべてのビットが0の状態で初期化される
bitset<ビット数> 変数名("ビット列(長さはビット数に合わせる)"); // 指定したビット列で初期化される
「ビット数」の部分は定数でなければならず、変数を使うことはできないことに注意してください。
例
bitset<4> b("1010");
ビット演算
bitsetに対するビット演算はC++の演算子として定義されています。
対応は次の表の通りです。
| ビット演算 | bitsetの演算子 |
使い方 |
|---|---|---|
| ビット毎のAND演算 | & |
変数1 & 変数2 |
| ビット毎のOR演算 | | |
変数1 | 変数2 |
| ビット毎のXOR演算 | ^ |
変数1 ^ 変数2 |
| ビット毎のNOT演算 | ~ |
~変数 |
| 論理左シフト演算 | << |
変数 << シフトするビット数 |
| 論理右シフト演算 | >> |
変数 >> シフトするビット数 |
これらのビット演算の末尾に=を付けることで複合代入演算子として用いることができます。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
bitset<8> a("00011011");
bitset<8> b("00110101");
auto c = a & b;
cout << "1: " << c << endl; // 1: 00010001
cout << "2: " << (c << 1) << endl; // 2: 00100010
cout << "3: " << (c << 2) << endl; // 3: 01000100
cout << "4: " << (c << 3) << endl; // 4: 10001000
cout << "5: " << (c << 4) << endl; // 5: 00010000
c <<= 4;
c ^= bitset<8>("11010000"); // XOR演算の複合代入演算子
cout << "6: " << c << endl; // 6: 11000000
}
実行結果
1: 00010001 2: 00100010 3: 01000100 4: 10001000 5: 00010000 6: 11000000
bitsetの操作
bitsetにはビット列を扱うときに便利な関数が用意されています。
以下に主要なものを挙げます。
| 操作 | 書き方 | 備考 |
|---|---|---|
| 特定のビットの値を変更する | 変数.set(位置, 値); |
変更するビットの位置を0始まりのインデックスで指定します。値は0か1を指定します。 |
| 特定のビットが1になっているかを調べる | 変数.test(調べる位置); |
調べるビットの位置を0始まりのインデックスで指定します。ビットが1ならtrueを、ビットが0ならfalseを返します。 |
位置の指定についてですが、ビット列の右から左にかけて0, 1, 2, ...と対応します。 配列の位置の指定とは逆になっていることに注意してください。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
bitset<4> S;
S.set(0, 1); // 0番目のビットを1にする
cout << S << endl;
if (S.test(3)) {
cout << "4th bit is 1" << endl;
} else {
cout << "4th bit is 0" << endl;
}
}
実行結果
0001 4th bit is 0
その他の関数については「細かい話」で紹介します。
整数とビット列の対応
実はこれまで扱ってきたintやint64_tなどの整数型は、
コンピュータの内部ではビット列で表現されています。
さらに言えば、通常のコンピュータで扱えるものは全てビット列です。
コンピュータはビット列の01のパターンに対して数値を割り当てることで数値を扱っています。 例えば「00000111」は7に、「00100100」は36に対応しています。
このようなビット列と数値の対応は、二進法というルールに基づいています。
以下、簡単のために符号なし整数を表現する場合について説明します。
多くのコンピュータでは負の数を2の補数表現という形式で表現します。 ビット演算の話から少しそれるので扱いませんが、興味のある人は調べてみてください。
二進法
二進法は整数を「1, 2, 4, 8, 16, 32, 64, ... (2の累乗)」の和で表す表し方で、足すか足さないかを0, 1に対応させます。
また、二進法で表記することを二進数表記といいます。 これに対して普段私達が使っている0〜9の数字の並びで表現したものを十進数といいます。
例えば、十進数の「7」は、7 = 4 + 2 + 1 なので、二進数表記は「111」となります。先頭に続く0は省略することが多いです。
以下にいくつか例を挙げます。ビット列の右端から順に 1, 2, 4, 8, ... と対応していることに注意してください。
| 十進数 | 二進数 | |
|---|---|---|
| 4 | 100 | 4 = 2^2 |
| 5 | 101 | 5 = 4 + 1 = 2^2 + 2^0 |
| 36 | 100100 | 36 = 32 + 4 = 2^5 + 2^2 |
| 100 | 1100100 | 100 = 64 + 32 + 4 = 2^6 + 2^5 + 2^2 |
0〜15の二進数表記は以下の通りです。二進数に不慣れな人は確認してみてください。
| 十進数 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 二進数 | 0000 | 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 | 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 |
整数でのビット演算
C++には、整数をビット列として扱うための演算子が用意されています。
整数でのビット演算の演算子はbitsetのものと同じです。
ただし、整数型に応じてビット列の長さが固定されているので、bitsetほど柔軟には使えません。
例えば、uint32_tは32ビットのビット列として扱うことができ、uint8_tは8ビットのビット列として扱うことができます。
さらに、C++の標準で扱える最大の整数型はuint64_tであり、これは64ビットのビット列なので、
整数をビット列として扱えるのは64ビット以下の場合に限定されることになります。
また、coutで出力しようとした場合に10進数の整数として出力されてしまうため分かりにくいという欠点があります。
基本的にはbitsetを使うのが便利ですが、
「ありうる集合すべてを列挙する」ような処理を行う場合には整数をビット列として扱う方が簡潔に書けることがあります。
詳しくは「細かい話」の「ビット全探索」で説明します。
注意点
演算子の優先順位
ビット演算に用いる演算子は優先順位が低いものが多いので、明示的に()でくくる必要がある場合があります。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
int x = 5; // 0101
int y = 10; // 1010
// if (x & y > 0) { // &演算子よりも>演算子の優先度の方が高いので x & (y > 0) と解釈される
if ((x & y) > 0) {
cout << "yes" << endl;
} else {
cout << "no" << endl;
}
}
実行結果
no
主要な演算子の優先順位を以下に示します。上ほど優先度が高いです。
優先順位を全て暗記するのは大変なので、ミスを防ぐためにもビット演算を行う際には常に()でくくるようにしましょう。
| 演算子 | 説明 |
|---|---|
a++, a--, . |
インクリメント、デクリメント、メンバアクセス |
!, ~ |
論理否定、ビット毎のNOT演算 |
a*b, a/b, a%b |
乗算、除算、剰余 |
a+b, a-b |
加算、減算 |
<<, >> |
左シフト演算、右シフト演算 |
<, <=, >, >= |
比較演算 |
==, != |
関係演算子 |
& |
ビット毎のAND演算 |
^ |
ビット毎のXOR演算 |
| |
ビット毎のOR演算 |
&& |
論理演算(かつ) |
|| |
論理演算(または) |
=, ◯= |
代入演算、複合代入演算 |
細かい話
bitsetの関数
以下の表にbitsetのビット列に対する操作をまとめます。
| 操作 | 書き方 | 備考 |
|---|---|---|
| 全てのビットを1にする | 変数.set(); |
|
| 特定のビットを1にする | 変数.set(1にする位置); |
1にするビットの位置を0始まりのインデックスで指定します。 |
| 特定のビットの値を変更する | 変数.set(位置, 値); |
変更するビットの位置を0始まりのインデックスで指定します。値は0か1を指定します。 |
| 全てのビットを0にする | 変数.reset(); |
|
| 特定のビットを0にする | 変数.reset(0にする位置); |
0にするビットの位置を0始まりのインデックスで指定します。 |
| 全てのビットを反転する | 変数.flip(); |
|
| 特定のビットを反転する | 変数.flip(反転する位置); |
反転するビットの位置を0始まりのインデックスで指定します。 |
| 特定のビットが1になっているかを調べる | 変数.test(調べる位置); |
調べるビットの位置を0始まりのインデックスで指定します。ビットが1ならtrueを、ビットが0ならfalseを返します。 |
| 全てのビットが1になっているかを判定する | 変数.all() |
全てのビットが1ならtrueを、そうでなければfalseを返します。 |
| いずれかのビットが1になっているかを判定する | 変数.any() |
1のビットが存在するならtrueを、そうでなければfalseを返します。 |
| 1のビットの個数を数える | 変数.count() |
|
| ビット列を出力する | cout << 変数; |
|
| ビット列を文字列化する | 変数.to_string() |
|
| ビットに対するアクセス | 変数[位置] |
基本的にはtest、set/resetと同等ですが、範囲外の位置を指定した場合にエラーにならないことに注意する必要があります。 |
ビット全探索
「ビット全探索」と呼ばれるテクニックを紹介します。
ビット全探索によって、組合せの全列挙をシンプルに実装することができます。
ビット全探索とは「すべてのビット列の組合せ」に対して何らかの処理を行うことをいいます。
例えば、長さ2のビット列ならば、すべてのビット列の組合せは「00」「01」「10」「11」の4通りです。
各ビットについて0か1の2通りなので長さNのビット列は2^N通り存在します。
次のサンプルプログラムでは、すべての「長さ3のビット列」を列挙しています。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
// 3ビットのビット列をすべて列挙する
for (int tmp = 0; tmp < (1 << 3); tmp++) {
bitset<3> s(tmp);
// ビット列を出力
cout << s << endl;
}
}
実行結果
000 001 010 011 100 101 110 111
6行目はtmpという変数を0から始めて8になるまでのfor文です。
1 << 3は、2の3乗を得るための式です。
1を3ビット左シフトすると、ビット列は「1000」となり、これを2進数として解釈すると2の3乗=8になります。
2のk乗の値を得るために、
1 << kという書き方をすることがよくあります。シンプルな形なので覚えておきましょう。
7行目では、tmpをビット列として解釈してbitset<3>型のsを初期化しています。
9行目ではsのビット列を出力しています。
0から7のビット列は次のようになっています。
| 十進数 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 二進数 | 000 | 001 | 010 | 011 | 100 | 101 | 110 | 111 |
これらの中に長さ3のビット列が全て現れているということが分かります。
より一般には、0から2^N-1の範囲でループすることで、 長さNのビット列をすべて列挙することができます。
ビット全探索の雛形
次の形でビット全探索を行うことができます。
for (int tmp = 0; tmp < (1 << ビット数); tmp++) {
bitset<ビット数> s(tmp);
// (ビット列sに対する処理)
}
bitsetの長さの指定に変数は使えないことに注意してください。
また、このアルゴリズムはビット列の長さをNとして、少なくとも2^N回以上のループになるので計算量に注意しましょう。
例題
A_1, A_2, \cdots A_NのN個の整数が与えられます。 これらの整数からいくつかを選んで、その総和がKとなるような選び方が存在するかを求めてください。
制約
- 1 \leq N \leq 20
- 1 \leq K \leq 100
- 1 \leq A_i \leq 100 (1 \leq i \leq N)
入力
N K A_1 A_2 \ldots A_N
出力
総和がKとなるような整数の組合せが存在するなら1行にYESを、そうでなければNOを出力してください。
入力例1
5 11 2 8 4 2 9
出力例1
YES
2 + 9 = 11となるように、2, 9を選べばよいです。
入力例2
5 3 2 8 4 2 9
出力例2
NO
入力例3
5 25 2 8 4 2 9
出力例3
YES
解答例
#include <bits/stdc++.h>
using namespace std;
int main () {
int N, K;
cin >> N >> K;
vector<int> A(N);
for (int i = 0; i < N; i++) {
cin >> A.at(i);
}
bool ans = false;
// すべての選び方を試して、総和がKになるものがあるかを調べる
for (int tmp = 0; tmp < (1 << 20); tmp++) {
bitset<20> s(tmp); // 最大20個なので20ビットのビット列として扱う
// ビット列の1のビットに対応する整数を選んだとみなして総和を求める
int sum = 0;
for (int i = 0; i < N; i++) {
if (s.test(i)) {
sum += A.at(i);
}
}
if (sum == K) {
ans = true;
}
}
if (ans) {
cout << "YES" << endl;
} else {
cout << "NO" << endl;
}
}
bitsetと整数の相互変換
整数からbitsetへの変換
bitsetのコンストラクタに整数を渡すことで整数をビット列としてみなしてbitsetに変換することができます。
bitset<ビット数> 変数名(整数);
bitsetから整数への変換
mapのKeyとして使う場合や四則演算を行う場合に、bitsetを整数に変換したいことがあります。このような場合には、bitsetのto_ullong関数を用います。
bitsetの変数.to_ullong()
bitsetのビット数が64ビットを超えている場合は、整数に変換できずに実行時エラーになります。
2進数リテラル
2進数リテラルを用いることで、2進数表記で整数を書くことができます。
2進数リテラルは0b0101や0b11111111のように、0bに続けて01のビット列を書きます。
#include <bits/stdc++.h>
using namespace std;
int main() {
uint32_t x = 0b100;
cout << x << endl; // 4
cout << (x | 0b010) << endl; // 計算結果は 0b110 = 6
}
実行結果
4 6
ビット演算の計算量
整数をビット列として用いる場合
全てO(1)です。
bitsetを用いる場合
基本的にはbitsetの操作の計算量はビット数をNとしてO(N)です。
しかし、内部的には整数のビット演算を用いて複数のビットをまとめて処理するように実装されていることが多いため、 64ビット以内であれば基本的にO(1)になります。 64ビットを超える場合でも、計算量から見積もられる実行時間より高速に動作することが多いです。
負の整数の右シフト
論理右シフトでは、空いたビットは0で埋められるということを説明しましたが、 負の数を右シフトした場合には、空いたビットは基本的に1で埋められます。 この動作を算術右シフトといいます。
演習問題
リンク先の問題を解いてください。
ABC/ARCの問題
ここまでの知識で解ける問題をAtCoder Beginner Contest / AtCoder Regular Contestの過去問題から紹介します。 練習問題だけでは物足りない人は是非挑戦してみてください。
「2.05.再帰関数」でも取り上げた問題ですが、ビット全探索を用いて解くこともできます。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- コンピュータの内部では「文字」を数値として扱っており、文字に対応する数値を文字コードという
- char型の値は実質的に数値なので、int型と同じように四則演算や比較ができる
- 関数の外で宣言した変数をグローバル変数と呼び、プログラム全体がスコープになる
- const修飾子を付けて宣言した変数は定数として扱える
- 条件演算子を使うと「if文で分岐して値を選ぶ処理」を短く書ける
条件式 ? 真の時の式 : 偽の時の式
&&と||は左の式から実行し、結果が確定した時点で条件判定処理を中断する- マクロを使うと変数や関数を使う感覚でプログラムを置換することができる
- ラムダ式を使うと関数の内部で関数を定義できる
- do-while文とnext_permutation関数を使うと「順列の全列挙」が簡単に書ける
- goto文は多重ループからの脱出に便利
3.06.その他の機能
このページでは競技プログラミングに役立つことがあり、今まで説明してこなかった細々とした知識について説明します。
今回の問題はこのページで説明した内容を使わなくても解けるので、読まずに問題を解いても良いです。
EX26.電卓を作ろう3
文字コード
コンピュータの内部では「文字」を数値として扱っています。
ある文字が内部でどのような数値になっているかは、char型の値をint型にキャストすることで見られます。
また、int型をchar型にキャストすることで、数値と対応している文字を見ることもできます。
次のプログラムは文字とそれに対応する数値を出力する例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << (int)'A' << endl;
cout << (int)'B' << endl;
cout << (int)'Z' << endl;
cout << (char)65 << endl;
cout << (char)66 << endl;
cout << (char)90 << endl;
}
実行結果
65 66 90 A B Z
「ある文字に対応する数値」のことを文字コードと呼びます。また、「全ての文字と数値の対応関係」をまとめて文字コードと呼ぶこともあります。
後者の意味で、文字コードには様々な物があります。char型やstring型は通常ASCII文字コード(アスキー文字コード)というものを用いています。
ASCII文字コードは基本的に半角英数字と半角記号('0'、'A'、'a'、'!'等)を扱うためのものです。char型やstring型では日本語がうまく扱えないのはそれらがASCIIコードを前提としているためです。
ASCII文字コードにおける文字と数値の対応はWikipediaで見ることができます。
これらの文字と数値の対応を覚える必要は全くありませんが、「『'0'~'9'』、『'A'~'Z'』、『'a'~'z'』がそれぞれ連続していること」と、
「大文字は小文字より小さい数値に対応していること」は覚えておくと役に立つことがあります。
文字コードを利用したプログラム
char型の値は実質的に数値なので、int型と同じように四則演算や比較ができます。
char型に対する加算
次のプログラムはこれを用いて'A'~'Z'を出力します。
#include <bits/stdc++.h>
using namespace std;
int main() {
for (int i = 0; i <= ('Z' - 'A'); i++) {
cout << (char)('A' + i);
}
}
実行結果
ABCDEFGHIJKLMNOPQRSTUVWXYZ
i <= ('Z' - 'A')とすることで出力したい文字数分だけループし、(char)('A' + i)で「'A'からi文字進めた文字」を計算しています。
char型に対して四則演算をした結果はint型になるため、出力する前にchar型にキャストし直す必要があることに注意してください。
他にも、次のようにして大文字と小文字を変換することもできます。
(char)('x' + ('A' - 'a')) // 'X' 小文字→大文字
(char)('X' - ('A' - 'a')) // 'x' 大文字→小文字
この処理はC++で用意されている関数を使って行うこともできます。小文字→大文字の変換は
(char)toupper(文字)、大文字→小文字の変換は(char)tolower(文字)で利用できます。
char型の比較
次のプログラムは文字コードを比較することにより、大文字と小文字の判定を行っています。
#include <bits/stdc++.h>
using namespace std;
int main() {
char c = 'X';
if ('A' <= c && c <= 'Z') {
cout << "YES" << endl;
}
else {
cout << "NO" << endl;
}
}
実行結果
YES
文字コード上で'A'~'Z'は連続しているため、'A' <= c && c <= 'Z'だけで判定ができます。
大文字の判定はC++で用意されている関数を使って
isupper(文字)で行うこともできます。同様の便利な関数として小文字の判定を行うislower(文字)や、10進数の数字かどうかをチェックするisdigit(文字)などもあります。
グローバル変数
今まで出てきた変数のように、関数の中で宣言した変数をローカル変数と呼びます。
変数は関数の外で宣言することもできます。関数の外で宣言した変数はグローバル変数と呼びます。
グローバル変数の使い方はローカル変数と全く同じです。
#include <bits/stdc++.h>
using namespace std;
//グローバル変数
int number = 10;
int main() {
cout << number << endl;
}
実行結果
10
グローバル変数のスコープ
グローバル変数のスコープはプログラム全体、つまり「宣言された場所からプログラムの終わりまで」になります。
そのため、複数の関数をまたいで使うことができます。
#include <bits/stdc++.h>
using namespace std;
//グローバル変数
int number = 10;
void change() {
number = 5;
}
int main() {
cout << number << endl;
change();
cout << number << endl;
}
実行結果
10 5
グローバル変数名の衝突
ローカル変数と同様に、同じ名前のグローバル変数は宣言できません。
まれにSTLで定義しているグローバル変数と衝突することもあるので注意してください。
const修飾子
const修飾子を変数の宣言時につけると、その変数を定数(変えられない値)として扱えるようになります。
宣言は次の形式になります。
const 型 変数名 = 値;
値が変えられないこと以外は変数と同じように使うことができます。
#include <bits/stdc++.h>
using namespace std;
int main() {
const int a = 10;
cout << a + 5 << endl;
// 再代入はできない
// a = 5;
}
const修飾子の使い所
const修飾子の使い所として、bitsetのビット数を指定する場合があります。
bitsetのビット数は定数でなければなりませんが、何度もbitsetの型を書かないといけない場合を考えると、直接数値を書くのは面倒な上に書き間違えの恐れもあります。
「const修飾子を付けた変数」を使えば直接数値を書くこと無く、楽かつ安全にbitsetのビット数を指定できます。
const int B = 100;
bitset<B> func1(bitset<B> a) {
...
}
bitset<B> func2(bitset<B> a) {
...
}
他にも1.13.配列の細かい話で紹介した「Cの配列」やarrayの要素数の指定も定数である必要があるため、「const修飾子を付けた変数」が利用できます。
また、値が変わらないことを保証することで安全にプログラムを書くという目的でconst修飾子を利用することもあります。
GCC環境では、ローカル変数であれば「Cの配列」の要素数は変数で指定できます。
条件演算子
if文の書き換え
条件演算子(または三項演算子)を使うとif文を短く書き換えられることがあります。
次のプログラムは2つの数値の入力のうち小さい方を出力をif文を用いて実装しています。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a, b;
cin >> a >> b;
int answer;
// 小さい方の値をanswerに代入する
if (a < b) {
answer = a;
}
else {
answer = b;
}
cout << answer << endl;
}
これは条件演算子を使うと次のように書き換えられます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a, b;
cin >> a >> b;
// 小さい方の値をanswerに代入する
int answer = a < b ? a : b;
cout << answer << endl;
}
このように、if文で分岐して値を選ぶ処理は条件演算子で短く書くことができます。
条件演算子の記法
条件演算子の書き方は次のようになります。
条件式 ? 真の時の式 : 偽の時の式
条件演算子のネスト
条件演算子もif文のようにネストさせることができます。
次のプログラムは3つの入力を受け取り、その中で最小の数値を出力しています。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a, b, c;
cin >> a >> b >> c;
int answer = a < b && a < c ? a : b < a && b < c ? b : c;
cout << answer << endl;
}
このように条件演算子のネストを書いてしまうと読み辛くなりやすいため、次のように改行とインデントを用いて読みやすくした方が良いでしょう。
// インデントのパターンその1
int answer = a < b && a < c
? a
: b < a && b < c
? b
: c;
// インデントのパターンその2
int answer = a < b && a < c ? a
: b < a && b < c ? b
: c;
条件が複雑に入り組んでいる場合は条件演算子を使わないほうが読みやすいこともあります。状況に応じて読み書きしやすい方を使いましょう。
条件演算子の優先順位
演算子の優先順位の関係で、coutの内部で条件演算子を利用する場合は()で囲う必要があります。
#include <bits/stdc++.h>
using namespace std;
int main() {
int a, b;
cin >> a >> b;
cout << (a < b ? a : b) << endl; // ()で囲う
}
細かく言うと、条件演算子は代入演算子=や複合代入演算子◯=の次に演算子の優先順位が低いです。
例えば次の2行のプログラムは同じ意味になります。
a + b < c ? x : y * z (a + b < c) ? (x) : (y * z) // 明示的に()で指定
論理演算の実行順序
論理演算子の&&と||は左の式から実行し、結果が確定した時点で条件判定処理を中断します。
例えば次のプログラムの一つ目のif文は最初の条件s.size() > 10の時点で結果がfalseに確定するのでs.at(10) == 'x'が実行されずエラーになりませんが、二つ目のif文はs.at(10) == 'x'が実行されてしまい実行時エラーになります。
#include <bits/stdc++.h>
using namespace std;
int main() {
string s = "abc";
// 実行時エラーにならない
if (s.size() > 10 && s.at(10) == 'x') {
cout << "ok" << endl;
}
// 実行時エラーになる
if (s.at(10) == 'x' && s.size() > 10) {
cout << "ng" << endl;
}
}
結果が確定した時点で条件判定処理を中断することを短絡評価(またはショートサーキット)と言います。
&&と||の展開
&&に関して以下の二つのプログラムはほとんど同じ意味になります。
if (条件1 && 条件2) {
処理1
}
else {
処理2
}
if (条件1) {
if (条件2) {
処理1
}
else {
処理2
}
}
else {
処理2
}
||に関して以下の二つのプログラムはほとんど同じ意味になります。
if (条件1 || 条件2) {
処理1
}
else {
処理2
}
if (条件1) {
処理1
}
else if (条件2) {
処理1
}
else {
処理2
}
マクロ
マクロ(defineディレクティブ)は付録4.ループの裏技repマクロで紹介した「repマクロ」を作成するために利用した機能です。
マクロを使うと、変数を使う感覚でプログラムを置換することができます。
次のプログラムはmy_coutという名前のマクロを定義しています。my_coutはその部分をcout <<に置き換えます。
#include <bits/stdc++.h>
using namespace std;
// my_coutというマクロを定義
#define my_cout cout <<
int main() {
// 次の行は cout <<"hello"; に置き換わる
my_cout "hello";
}
実行結果
hello
単純なマクロの記法
マクロは次のように書きます。半角スペースで区切って定義することに気をつけてください。
#define マクロ名 置き換えるプログラム
上のプログラムでは「マクロ名」がmy_coutであり、「置き換えるプログラム」がcout <<です。
引数を取るマクロ
マクロは関数のように引数を受け取ることもできます。
次のプログラムはis_not_5という名前のマクロを定義しています。is_not_5(n)はその部分をif (n != 5)に置き換えます。
#include <bits/stdc++.h>
using namespace std;
// is_not_5というマクロを定義
#define is_not_5(n) if (n != 5)
int main() {
// 次の行は if (10 != 5) { に置き換わる
is_not_5(10) {
cout << "NOT 5" << endl;
}
}
実行結果
NOT 5
引数を取るマクロの記法
引数を取るマクロは次のように書きます。
#define マクロ名(引数1, 引数2, ...) 置き換えるプログラム
複数行のマクロ
マクロの「置き換えるプログラム」が複数行に渡る場合、行末に\を書く必要があります。
以下はその定義の例です。
#define my_macro cout << "hello" << endl; \ cout << "AtCoder" << endl; \ cout << "C++" << endl;
repマクロの正体
repマクロの定義は次のようになっています。
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
ここまでの説明でわかるように、これは単にrep(カウンタ変数, 回数)をfor (int カウンタ変数 = 0; カウンタ変数 < (int)回数; カウンタ変数++)という形式に変換しています。
マクロの注意点
マクロを使うと短くプログラムを書くことができますが、「単純にプログラムを置換する」という動作の性質上、多くの落とし穴があります。
競技プログラミングのような小規模なプログラムではあまり問題になりませんが、大規模な開発では不用意にマクロを定義することは避けられることが多いです。
マクロの例 allマクロ
競技プログラミングでrepマクロの次に多く使われているマクロがallマクロです。
allマクロはsort等の関数呼び出しを簡潔にします。自己責任で利用してください。
#include <bits/stdc++.h>
using namespace std;
// allマクロの定義
#define all(v) v.begin(), v.end()
int main() {
vector<int> v = { 2, 3, 1 };
sort(all(v)); // 2回配列変数名を書く必要がない
cout << v.at(0) << endl;
}
ラムダ式
ラムダ式を利用すると関数の内部で関数を定義できます。
次のプログラムはmain関数の内部で、ラムダ式を用いてmy_min関数を定義しています。
#include <bits/stdc++.h>
using namespace std;
int main() {
// my_min関数をラムダ式で定義
auto my_min = [](int a, int b) {
if (a < b) {
return a;
}
else {
return b;
}
};
cout << my_min(5, 10) << endl;
}
実行結果
5
ラムダ式の記法
基本的なラムダ式の記法は次の通りです。セミコロンが末尾に必要だということに注意してください。
auto 関数名 = [](引数の型1 引数名1, 引数の型2, 引数名2, ...) { 関数の処理 };
ラムダ式の外の変数の利用
[&]と書くことでラムダ式の外の変数を利用できます。
次のupdate_max関数はmain関数の内部で定義されているmax_numを利用しています。
#include <bits/stdc++.h>
using namespace std;
int main() {
// 最大値を保持する変数
int max_num = 0;
// 今まで受け取った値の中から最も大きな値を返す関数
auto update_max = [&](int n) {
if (max_num < n) {
max_num = n;
}
return max_num;
};
cout << update_max(5) << endl;
cout << update_max(2) << endl;
cout << update_max(10) << endl;
cout << update_max(4) << endl;
}
実行結果
5 5 10 10
この他にもラムダ式にはいくつかの機能があります。気になる人は調べてみてください。
ラムダ式による再帰関数
ラムダ式で再帰呼び出しのある関数を定義する場合、autoではなくfunctionを型として指定する必要があります。
次のプログラムは0~Nの和を求める再帰関数sumをラムダ式で定義しています。
#include <bits/stdc++.h>
using namespace std;
int main() {
// 再帰関数の定義
function<int(int)> sum = [&](int n) {
if (n == 0) {
return 0;
}
int s = sum(n - 1);
return s + n;
};
cout << sum(3) << endl;
}
実行結果
6
ラムダ式による再帰関数の記法
再帰呼び出しのあるラムダ式は次のように定義します。
返り値の型と引数の型をfunction<>の中に書いたうえ、[&]と書く必要があることに注意して下さい。
function<返り値の型(引数の型1, 引数の型2, ...)> 関数名 = [&](引数の型1 引数名1, 引数の型2, 引数名2, ...) { 関数の処理 };
ラムダ式の使い道
ラムダ式は短い関数をその場で定義したい時に便利です。その例として「sort関数の比較関数の変更」を説明します。
sort関数は通常sort(配列.begin(), 配列.end())のように呼び出しますが、三番目の引数に関数を渡して比較方法を変更することができます。
次のプログラムはsort関数に自分で定義した比較関数を渡すことで、大きい順にソートさせています。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> v = { 2, 3, 1 };
// 大きい順にソートさせる比較関数
auto comp = [](int a, int b) { return a > b; };
sort(v.begin(), v.end(), comp);
cout << v[0] << endl; // v は {3, 2, 1}となっている
}
実行結果
3
名前をつけることを省略してさらに短く書くことも可能です。引数に直接渡す場合はセミコロンが不要になります。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> v = { 2, 3, 1 };
// 大きい順にソートさせる比較関数を直接渡す
sort(v.begin(), v.end(), [](int a, int b) { return a > b; });
cout << v[0] << endl; // {3, 2, 1}となっている
}
do-while文
今まで説明してこなかったループ構文として、do-while文があります。
do-while文は通常のwhile文と異なり、条件式の判定を行うより前に一度だけループ内部の処理を実行します。
つまり、while文が「条件式→処理→条件式→処理...」という順番で実行するのに対し、do-while文は「処理→条件式→処理→条件式...」という順番で実行します。
次のプログラムは入力で受け取った数を0までカウントダウンして出力します。
ただし、入力が負の数だった場合は一度だけ出力してプログラムを終了します。
#include <bits/stdc++.h>
using namespace std;
int main() {
int n;
cin >> n;
// nが負の数でも一度だけ実行される
do {
cout << n << endl;
n--;
} while (n >= 0);
}
入力1
3
実行結果1
3 2 1 0
入力2
-5
実行結果2
-5
この例のように、条件式がはじめから偽でも一度だけ実行することが特徴です。ただし、ほとんどの場合はwhile文で十分なのでdo-while文を使うべき場面は基本的にありません。 ここでは次で紹介するnext_permutation関数の説明を行うためにdo-while文を紹介しました。
next_permutation関数
next_permutation関数は「順列の全列挙」を行うための関数です。
次のプログラムは{ 1, 2, 3 }という配列に対して、すべての順列を出力しています。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> v = { 2, 1, 3 };
sort(v.begin(), v.end());
do {
// 1行で今の並び方を出力
for (int x : v) {
cout << x << " ";
}
cout << endl;
} while (next_permutation(v.begin(), v.end()));
}
実行結果
1 2 3 1 3 2 2 1 3 2 3 1 3 1 2 3 2 1
順列とはこの例のように、値の集合を順番に並べたもののことを言います。
また、より正確にはnext_permutation関数は「区別可能なn個の対象から重複を許してk個の対象を取り出して特定の順番で並べたもの」を全列挙するための関数になります。
next_permutation関数の使い方
next_permutation関数は次のように使います。
事前にsortが必要なことに注意してください。
sort(配列変数.begin(), 配列変数.end());
do {
// 順列に対する処理
} while (next_permutation(配列変数.begin(), 配列変数.end()));
「順列の全列挙」は再帰関数で実装することもできますが、next_permutation関数を使ったほうが簡単に実装することができます。
next_permutation関数の計算量
next_permutation関数を使って順列の全列挙を行った場合の計算量は、配列の長さをNとするとO(N!)になります。
Nが小さくても計算量は大きくなるので、使う際は計算量に気をつけましょう。
練習問題
以下はnext_permutation関数を使って解ける問題です。
goto文
最も単純な制御構文としてgoto文があります。goto文に到達すると、ラベルを付けた行に移動します。
次のプログラムはcout << "world" << endl;を飛ばしてSKIPラベルの行に実行を移します。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "Hello, ";
goto SKIP;
cout << "world!" << endl; //この行は飛ばされる
SKIP:
cout << "AtCoder!" << endl;
}
実行結果
Hello, AtCoder!
goto文の記法
goto文は以下のように使います。
ラベルの定義
ラベルは次のようにラベル名の後に:を書きます。
ラベル名:
goto文
gotoの後にラベル名を指定します。goto文を実行するとラベルの行に実行が移ります。
goto ラベル名;
goto文の使い道
goto文の使い道として最も便利なのが多重ループからの脱出です。
次のプログラムはgoto文を使ってループの外に飛ぶことで、多重ループから簡単に抜けています。
#include <bits/stdc++.h>
using namespace std;
int main() {
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
cout << i << " " << j << endl;
// この条件を満たしたら多重ループから抜ける
if (i == 1 && j == 1) {
goto OUT;
}
}
}
OUT:
cout << "fin" << endl;
}
実行結果
0 0 0 1 0 2 1 0 1 1 fin
goto文の注意点
goto文はシンプルな機能ですが、シンプルすぎるためにプログラムが何を意図しているのか分かりにくいことをはじめ、いくつかの落とし穴があります。
多重ループからの脱出など一部の状況では使っても良いですが、goto文が必要になるケースはほとんどないので、基本的には使わないほうが良いです。
今回の問題はこのページで説明した内容を使わなくても解けるので、読まずに問題を解いても良いです。
演習問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
第3章修了

第3章お疲れ様でした。
ここまでの内容を理解し、すべての問題をACしたたあなたは、競技プログラミングで戦うのに十分なC++の知識が身についています。
このまま第4章を読み進めるのもいいですし、競技プログラミングの学習を始めるのもよいでしょう。
より深くC++を勉強したり、ゲームやアプリの開発を始めることもできるはずです。
APG4bでは第3章に関するアンケートを実施しています。回答していただけると嬉しいです。
競技プログラミング
AtCoder Beginner Contestは競技プログラミングの初心者から楽しめるようなコンテストになっています。
これまでのC++の知識で十分に戦えるはずです。
興味のある人は是非過去問を解いてみてください。
また、競技プログラミングについて学ぶ際には以下の教材が参考になります。
- AtCoder Beginners Selection
- 「プログラミングコンテストチャレンジブック第2版」(通称:蟻本)+「AtCoder 版!蟻本」
- 実践・最強最速のアルゴリズム勉強会 講義資料
便利リンク集も合わせて確認してみてください。
C++をより深く学ぶ
もっと深くC++を学びたい人は、より詳細に解説した書籍で勉強するのもよいでしょう。
C++の詳細な仕様についても言及しているサイトとして「江添亮のC++入門」や「C++11/14コア言語」、「江添亮の詳説C++17」などがあります。 これらは書籍版も販売されています。
なお、これらのサイト・書籍はAtCoderとは関係のないコンテンツです。
ゲーム開発
C++でゲームを開発してみたいという人は、Siv3Dというゲームライブラリをおすすめします。
Siv3DはC++でゲームが開発でき、かつ日本語の情報が充実している良質なゲームライブラリです。
第4章について
第4章ではこれまでに説明していなかった事項について扱います。
また、第4章は練習問題がなく、簡単な説明だけになっています。
第4章は現在更新中です。更新情報はAPG4bのツイッターアカウントで告知しています。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- ソースコードを書いたファイルのことをソースファイルという
- 便利な関数や構造体を書いたソースファイルなどをまとめたものをライブラリという
#include <bits/stdc++.h>はSTL(C++の標準ライブラリ)を用いるためのもの#include <ファイル>をinclude(インクルード)ディレクティブという- 「指定したファイルの内容をこの命令を書いた部分に展開する」という機能
- 複数のソースファイルでプログラムを書く際には、ソースファイルとそれに対応するヘッダファイルを用いることが多い
- ヘッダファイルには関数のプロトタイプ宣言などを書き、ソースファイルにその関数の定義を書く
includeディレクティブ
このページでは、今までプログラムの先頭に書いていた、#include <bits/stdc++.h>の意味を理解できることを目標に説明します。
#includeの機能は複雑であるため、出来る限り簡潔に説明します。
細かい仕様などについてはAPG4bの範囲を越えるので、気になる人は調べてください。
ソースファイル
ソースファイルとはソースコードを記述したコンピュータ上のファイルのことです。 これまで、明示的にはソースファイルを扱ってきませんでしたが、実はAtCoderのコードテストではテキストボックスに入力したソースコードが1つのソースファイルとして処理されています。
なお、AtCoderのコードテストでは複数のソースファイルを扱うことができません。
外部サービスのWandboxでは複数のソースファイルを扱うことができるので、必要に応じて利用してみてください。
ライブラリ
便利な関数や構造体を書いたソースファイルなどをまとめたものをライブラリといいます。
STLもライブラリの1つです。 STLはC++の一部として用意されるため標準ライブラリと呼ばれます。
#include <bits/stdc++.h>の意味
これまでC++の言語機能と標準ライブラリをあまり区別せずに紹介してきました。
例えば、C++の関数呼び出しや四則演算などの機能は言語機能ですが、
変数の値を出力するために使っていたcoutやendlは、実はSTLによって提供されている機能です。
STLなどのライブラリを利用するためには、プログラム中でライブラリを利用することを明示する必要があります。
そして、これまでプログラムの1行目に書いていた「#include <bits/stdc++.h>」は
STLを利用するためのものです。
逆に、#include〜を書かなければcoutやendlの機能は利用できないことになります。
includeディレクティブ
C++には#include <ファイル>という記法があります。
これをinclude(インクルード)ディレクティブといいます。
includeディレクティブは「指定したファイルの内容をこの命令を書いた部分に展開する」という機能です。
例えば、ソースファイルa.cppとソースファイルb.cppがあったとして、それぞれの内容が以下のようになっていたとします。
a.cpp
// STLを使うためのincludeディレクティブ
#include <bits/stdc++.h>
using namespace std;
// b.cppの内容が展開される
#include "b.cpp"
int main() {
// fの定義はb.cppに書かれている
cout << f(10) << endl;
}
b.cpp
// xを2乗して返す
int f(int x) {
return x * x;
}
展開された後のa.cppは次のようになります。
(bits/stdc++.hの内容)
using namespace std;
// xを2乗して返す
int f(int x) {
return x * x;
}
int main() {
// fの定義はb.cppに書かれている
cout << f(10) << endl;
}
実行結果
100
このようにincludeの機能を用いることによって、別のファイルに記述したプログラムを組み込むことができます。
#include <bits/stdc++.h>は「bits/stdc++.hというファイルの内容を、この部分に展開する」という意味になります。
bits/stdc++.hはSTLの関数や構造体が宣言されているファイルです。これをプログラムの先頭に展開することによって、いろいろな機能が利用できるようになります。
includeディレクティブの<ファイル>と"ファイル"の違いについては「細かい話」で説明します。
複数のソースファイルでプログラムを書く
サンプルプログラムや問題の解答プログラムなどのような、規模の小さなプログラムでは1つのソースファイルで十分ですが、 ある程度規模の大きいプログラムや、ライブラリを書く際には1つのソースファイルだけでは開発が大変になってきます。
そのような場合にはソースファイルを複数に分割して記述します。 複数のファイルに分けることで、関連するコード毎にまとめたり、別のプログラムを作る際に再利用しやすくなります。
「ファイルを複数に分け、そのソースファイルをインクルードして使う」ということも可能ですが、いくつかの理由により、 「各ソースファイルについて、対応するヘッダファイルと呼ばれるファイルを作り、ヘッダファイルの方をインクルードする」という方法が一般的です。興味のある人は理由を調べてみてください。
ヘッダファイルを用いた例は「詳しい話」を見てください。
ヘッダファイル
プログラムを複数のソースファイルに分けて書く場合に、ソースファイルとは別にヘッダファイルと呼ばれるファイルが用いられます。
ヘッダファイルは、主に関数のプロトタイプ宣言や構造体の宣言などをまとめたファイルです。
慣習的にファイル名.hやファイル名.hppという名前のファイル名にすることが多いです。
細かい話
プログラムが実行されるまでの流れ
C++でソースコードを書いてプログラムが実行されるまでの流れを簡単に説明します。
- C++でソースコードを書く
- ソースファイルとして保存する
- コンパイラ呼ばれるプログラムを用いてソースファイルを実行ファイルに変換する
- 実行ファイルを実行する
ソースファイルに書かれているC++のソースコードは人間が読みやすい形で書かれているため、コンピュータが直接解釈して実行するのが困難です。
そこで、ソースコードを実行ファイルというコンピュータが扱いやすい形式のファイルに変換します。 この変換処理のことをコンパイルといい、コンパイルを行うのがコンパイラと呼ばれるプログラムです。
AtCoderのオンラインジャッジやコードテストの環境では、2〜4のステップが自動的に行われるようになっているため、C++のソースコードを直接実行しているような感覚でプログラムを作成することができます。
プリプロセッサ
厳密にはincludeディレクティブはプリプロセッサによって処理されます。
プリプロセッサはコンパイルの前段階の処理を行うもので、ソースコードを書き換えるような処理を行います。
プリプロセッサの処理はコンパイルの直前に行われるため、プログラムの実行速度に影響が出るものではありません。 よって、たくさんのファイルをインクルードしたからといって、プログラムの実行性能が悪くなるようなことはありません。
他にも、defineディレクティブ(定数やマクロ)の展開もプリプロセッサが行います。
includeするファイルの検索
includeディレクティブがある場合に、C++のコンパイラは、ファイル名にマッチするファイルを探します。
上の例では、標準ライブラリをインクルードするときに#include <bits/stdc++.h>のように書き、自分で用意したb.cppをインクルードするときには#include "b.cpp"のように書いていました。
ファイルをインクルードするには次の2通りの書き方ができます。
#include <ファイル>#include "ファイル"
1つ目の書き方は、標準ライブラリなど、システムにインストールされているライブラリのファイルをインクルードする場合に用います。 この場合、標準で登録されているディレクトリを順番に見ていき、マッチするファイルを探して展開します。
コンパイラのオプションで指定したディレクトリを検索対象に追加することもできます。
2つ目の書き方は、自分で用意したファイルをインクルードする場合に用いることが多いです。 この場合では、初めに「このファイルと同じディレクトリ」の中を探します。 マッチするファイルが見つからなかった場合には、1つ目の書き方と同じ動作になります。
includeディレクティブをどう扱うかは、厳密には処理系によって異なりますが、多くの環境で上のような動作になっています。
bits/stdc++.h
STLを用いるためにbits/stdc++.hというファイルをインクルードしていることを説明しました。
このファイルは、「標準ライブラリに関連する全てのヘッダファイルをインクルードするファイル」です。
実は、STLは複数のファイルに分けられて書かれています。
例えば、入出力関連のcinやcoutなどの機能はiostreamというヘッダファイルに書かれています。
またstring関連の機能はstringというヘッダファイルに書かれています。
bits/stdc++.hはこれらのSTLのヘッダファイルを全てインクルードするためのヘッダファイルです。
このファイルはGCC(C++コンパイラ)によって用意されているもので、他の環境(ClangやVC++など)では使えません。
bits/stdc++.hの使えない環境では、次で紹介するように必要なヘッダファイルを書き並べる必要があります。
本来は必要な機能に応じてそれぞれincludeディレクティブを書くのが正しい使い方ですが、
簡単なプログラムを書く際にはbits/stdc++.hは便利です。
個別の機能毎にヘッダファイルをインクルードする際は、以下を参考にインクルードするようにしてください。
#include <iostream> // cout, endl, cin #include <string> // string, to_string, stoi #include <vector> // vector #include <algorithm> // min, max, swap, sort, reverse, lower_bound, upper_bound #include <utility> // pair, make_pair #include <tuple> // tuple, make_tuple #include <cstdint> // int64_t, int*_t #include <cstdio> // printf #include <map> // map #include <queue> // queue, priority_queue #include <set> // set #include <stack> // stack #include <deque> // deque #include <unordered_map> // unordered_map #include <unordered_set> // unordered_set #include <bitset> // bitset #include <cctype> // isupper, islower, isdigit, toupper, tolower
ここで挙げていない機能に関してはcppreference.comなどを参照してください。
cppreference.comでは各機能のページに「ヘッダ <ファイル名> で定義」のように書かれています。
ヘッダファイルを用いる例
以下の例についてコンパイルの流れを説明します。
proc.cc(一番左のデフォルトのファイル)
#include <bits/stdc++.h>
using namespace std;
#include "b.h"
int main() {
cout << f(10) << endl;
}
b.cpp
int f(int x) {
return x * x;
}
b.h
int f(int x);
実行結果
100
この例は、proc.ccとb.cppという2つのソースファイルと、b.hという1つのヘッダファイルからなります。
b.hには、b.cppで定義されている関数fのプロトタイプ宣言が書かれています。
includeディレクティブの展開
プリプロセッサによってincludeディレクティブが展開された後は次のようになっています。
include展開後のproc.cc
(bits/stdc++.hの内容)
using namespace std;
int f(int x);
int main() {
cout << f(10) << endl;
}
b.cpp
int f(int x) {
return x * x;
}
それぞれをコンパイルして一時ファイルを生成
次にこれらのソースファイルが別々にコンパイルされ、proc.o、b.oのような一時ファイルが作られます。
この段階で、
proc.cc側から見ると定義の無い関数fを呼び出していることになります。
リンク
最後にリンクという処理によりproc.oとb.oから1つの実行ファイルが作られます。
このリンク時の処理で、定義の無かった関数fがb.cppに書かれたfの定義と繋がり、最終的に正しく実行できる実行ファイルになります。
少し複雑な例
3つのソースファイルでコンパイルする少し複雑な例を紹介します。
proc.cc
#include <bits/stdc++.h>
using namespace std;
#include "b.h"
#include "c.h"
int main() {
cout << f(10) << endl;
cout << g(10) << endl;
}
b.cpp
int f(int x) {
return x * x;
}
b.h
int f(int x);
c.cpp
#include "b.h"
int g(int x) {
return f(f(x));
}
c.h
int g(int x);
proc.ccからb.cppで定義されたfと、c.cppで定義されたgを呼び出しています。
c.cppのgではb.cppで定義されたfを呼び出しています。
なお、Wandbox上でソースファイルとヘッダファイルを用いて複数ファイルでコンパイルする際には、左側の「Compiler options:」にファイル名を改行区切りで列挙する必要があります。
インクルードガード
ヘッダファイルの中で別のヘッダファイルをインクルードする際に、循環参照の問題が発生することがあります。
例えば、a.hというヘッダファイルの中でb.hをインクルードしていて、b.hの中でa.hをインクルードしているとすると、これらのファイルは相互に参照し合っているため、無限に展開されることになってしまいコンパイルできません。
このような状況を防ぐために、ファイルの展開を一度しか展開しないようにする必要があります。 これをインクルードガードといいます。
インクルードガードを行うには、ヘッダファイルの1行目に#pragma onceを書きます。
この方法はコンパイラによる拡張機能ですが、多くのコンパイラで利用可能です。
インクルードガードを追加したb.hの例
#pragma once int f(int x);
このような単純な例ではインクルードガードは必要ではありませんが、 常にインクルードガードを書くようにすることでミスを防ぐことができます。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 名前空間によって、名前の衝突を避けることができる
- 名前空間の定義は以下のように行う
namespace 名前空間名 {
// 内容
}
- 名前空間内の変数や関数にアクセスするには
名前空間名::によって名前空間を指定する - 名前空間はネストすることができる
using namespace 名前空間名;によって名前空間名::の指定を省略することができる- STLの関数や構造体は
std名前空間内に定義されている using namespace std;はstd::を省略するためもの
- STLの関数や構造体は
名前空間
関数や構造体、グローバル変数の名前の衝突を避けるために、名前空間を定義することができます。
次のプログラムでは、名前空間Aと名前空間Bを定義し、それぞれの内部でfという関数を定義しています。
#include <bits/stdc++.h>
using namespace std;
// 名前空間A
namespace A {
void f() {
cout << "namespace A" << endl;
}
}
// 名前空間B
namespace B {
void f() {
cout << "namespace B" << endl;
}
}
int main() {
A::f(); // 名前空間A内の関数fの呼び出し
B::f(); // 名前空間B内の関数fの呼び出し
}
実行結果
namespace A namespace B
名前空間を分けることで、このように同名の関数を定義することが出来るようになります。
関数を呼び出す時はA::f()のように、関数名の前に名前空間を明示します。
名前空間の内部では、関数の定義、構造体の定義、グローバル変数の定義などが行なえます。
名前空間の定義
名前空間を定義するには次のように書きます。
namespace 名前空間名 {
// 内容
}
名前の解決
名前空間の内部に定義した関数や変数にアクセスするには、次のように名前空間名を指定します。
名前空間::関数名 名前空間::グローバル変数名 名前空間::構造体名
名前空間のネスト
名前空間をネストすることもできます。
#include <bits/stdc++.h>
using namespace std;
namespace A {
namespace B{
void f() {
cout << "A::B::f" << endl;
}
}
void f() {
cout << "A::f" << endl;
}
}
int main() {
A::f();
A::B::f();
}
実行結果
A::f A::B::f
using namespace
using namespace 名前空間名;と書くことによって、そのスコープ内において名前空間の指定を省略することができます。
#include <bits/stdc++.h>
using namespace std;
namespace A {
void f() {
cout << "A::f" << endl;
}
}
int main() {
using namespace A;
f(); // A::f();と書くのと同じ
}
実行結果
A::f
using namespace std;
ここまでの説明で、プログラムの2行目に書いていたusing namespace std;の意味を理解することができます。
STLの関数や構造体は、stdという名前空間の内部に定義されています。
そのため、本来はSTLの機能を使うには名前の指定にstd::を前置する必要があります。
using namespace std;を書くことによってstd::の指定を省略出来るようになります。
using namespace std;は小さな規模のプログラムを書く際には便利ですが、
規模が大きくなると名前の衝突を避けることが大変になるため、
グローバルなスコープにusing namespace std;を書くのは避けるべきです。
std::を前置すれば、using namespace std;を書かずにプログラムを書くことができます。
using namespace stdを使わない例
#include <bits/stdc++.h>
int main() {
std::vector<int> a = {3, 4, 1, 2};
std::sort(a.begin(), a.end());
for (int i = 0; i < a.size(); i++) {
std::cout << a.at(i) << std::endl;
}
}
実行結果
1 2 3 4
細かい話
名前空間のエイリアス
名前空間をネストした場合の指定や、長い名前空間名に別名を付けることができます。
#include <bits/stdc++.h>
using namespace std;
namespace A {
namespace B {
namespace C {
void f() {
cout << "A::B::C::f" << endl;
}
}
}
}
namespace too_long_name {
void f() {
cout << "too_long_name::f" << endl;
}
}
int main() {
namespace abc = A::B::C;
abc::f();
namespace s = too_long_name;
s::f();
}
実行結果
A::B::C::f too_long_name::f
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- テンプレートは構造体や関数の「型」を一般化するための機能
- 「同様の処理を行うが、利用する型が異なる関数」は関数テンプレートを用いてまとめることができる
- 関数テンプレートの宣言
template <typename テンプレート引数>
返り値の型 関数名(引数の型 引数...(必要な分だけ書く)) {
// 処理内容
}
- 関数テンプレートとして定義された関数の呼び出し
関数名<テンプレート引数>(引数1, 引数2, ...);
- 構造体の内容を型について一般化したいときにはクラステンプレートを用いてまとめることができる
- クラステンプレートの宣言
template <typename テンプレート引数>
struct 構造体名 {
(構造体の内容)
};
- クラステンプレートを用いて定義された構造体の使用
構造体名<テンプレート引数>
テンプレート
テンプレートは構造体や関数の「型」を一般化するための機能です。
関数テンプレート
関数テンプレートを用いることで「同様の処理を行うが、使用している型が異なる関数」をまとめることができます。
例えば、これまで扱ってきたSTLのmin関数やmax関数は関数テンプレートを用いて定義されています。
これによってint型に対してもdouble型に対しても同じように使えるようになっています。
以下では「ある数値xを取って二乗する関数」を例として説明します。
扱う数値がint型であれば次のように書くことができます。
// xの二乗を返す
int square_int(int x) {
return x * x;
}
ここでdouble型の数値を二乗する関数も必要になったとします。
// xの二乗を返す
double square_double(double x) {
return x * x;
}
これらの関数は次のように使うことができます。
#include <bits/stdc++.h>
using namespace std;
// xの二乗を返す
int square_int(int x) {
return x * x;
}
// xの二乗を返す
double square_double(double x) {
return x * x;
}
int main() {
int a = 3;
double b = 1.2;
cout << square_int(a) << endl;
cout << square_double(b) << endl;
}
実行結果
9 1.44
2つの関数(int用とdouble用)の関数内の記述は全く同じです。
関数テンプレートの機能を用いることでこのような「別の型に対する同じ処理」をまとめることができます。 具体的には次のように関数を定義します。
// xの二乗を返す (関数テンプレート版)
template <typename T>
T square(T x) {
return x * x;
}
この関数を呼び出す側は以下のようになります。
#include <bits/stdc++.h>
using namespace std;
// xの二乗を返す (関数テンプレート版)
template <typename T>
T square(T x) {
return x * x;
}
int main() {
int a = 3;
double b = 1.2;
cout << square<int>(a) << endl; // int版のsquare関数の呼び出し
cout << square<double>(b) << endl; // double版のsquare関数の呼び出し
}
実行結果
9 1.44
関数テンプレートの宣言
関数テンプレートを宣言するには次のようにします。
template <typename テンプレート引数>
返り値の型 関数名(引数の型 引数...(必要な分だけ書く)) {
// 処理内容
}
テンプレートは返り値の型や引数の型として用いることができます。
複数のテンプレート引数を取ることもできます。
template <typename テンプレート引数1, typename テンプレート引数2, ...(必要な分だけ書く)>
返り値の型 関数名(引数の型 引数...(必要な分だけ書く)) {
// 処理内容
}
構造体のメンバ関数もテンプレートを用いて定義することができます。
テンプレートを用いた関数の呼び出し
テンプレートを用いて定義された関数を呼び出すには、以下のように書きます。
関数名<テンプレート引数>(引数1, 引数2, ...);
テンプレート引数は、関数を定義したときに指定した分だけ渡します。
関数名<テンプレート引数1, テンプレート引数2, ...(必要な分だけ書く)>(引数1, 引数2, ...);
ただし、引数の型から推定できる場合には、テンプレート引数の指定を省略することができます。
#include <bits/stdc++.h>
using namespace std;
// xの二乗を返す (関数テンプレート版)
template <typename T>
T square(T x) {
return x * x;
}
int main() {
int a = 3;
double b = 1.2;
// テンプレート引数の省略
cout << square(a) << endl; // int版のsquare関数の呼び出し
cout << square(b) << endl; // double版のsquare関数の呼び出し
}
実行結果
9 1.44
構造体におけるテンプレート
構造体を定義する際にもテンプレートを用いることができます。 これによって、例えばメンバ変数の型を一般化した構造体を作ることができます。
このようなテンプレートをクラステンプレートといいます。
これまで扱ってきたvectorやmapなどのSTLのコンテナはクラステンプレートを用いて定義されています。
例えばvectorはvector<int>としてint型の配列を、vector<double>としてdouble型の配列を使うことができました。
次のプログラムは座標値の型をテンプレートを用いて一般化したPoint構造体の例です。
#include <bits/stdc++.h>
using namespace std;
// クラステンプレートの宣言
template <typename T>
struct Point {
T x;
T y;
void print() {
cout << "(" << x << ", " << y << ")" << endl;
}
};
int main() {
// int型用のPoint構造体
Point<int> p1 = { 0, 1 };
p1.print(); // (0, 1)
// double型用のPoint構造体
Point<double> p2 = { 2.3, 4.5 };
p2.print(); // (2.3, 4.5)
}
実行結果
(0, 1) (2.3, 4.5)
クラステンプレートの宣言
クラステンプレートを宣言するには次のようにします。
template <typename テンプレート引数>
struct 構造体名 {
(構造体の内容)
};
テンプレート引数は型名として用いることができます。
複数のテンプレート引数を取ることもできます。
template <typename テンプレート引数1, テンプレート引数2, ...(必要な分だけ書く)>
struct 構造体名 {
(構造体の内容)
};
テンプレートを用いた構造体の使用
クラステンプレートを用いて定義した構造体を使うには、次のようにテンプレート引数を指定します。
構造体名<テンプレート引数>
上のサンプルプログラムではPointというクラステンプレートに対してPoint<int>やPoint<double>として利用しています。
関数テンプレートと違い、クラステンプレートのテンプレート引数は省略することはできません。
定数のテンプレート
関数テンプレートもクラステンプレートも、整数型の定数をテンプレート引数として用いることができます。 定数のテンプレートは、使う場所に応じて定数を切り替えたい場合などに便利です。
具体例として、tupleの要素取得に用いるget関数や、bitsetは定数のテンプレートを用いて定義されています。
以下は関数テンプレートにおいて定数のテンプレート引数をとる例です。
#include <bits/stdc++.h>
using namespace std;
// タプルのINDEX1番目とINDEX2番目を交換する関数
template <int INDEX1, int INDEX2>
void tuple_swap(tuple<int, int, int> &x) {
swap(get<INDEX1>(x), get<INDEX2>(x));
}
int main() {
tuple<int, int, int> x = make_tuple(1, 2, 3);
tuple_swap<0, 2>(x); // 1番目と3番目を交換
cout << get<0>(x) << ", " << get<1>(x) << ", " << get<2>(x) << endl;
tuple_swap<0, 1>(x); // 1番目と2番目を交換
cout << get<0>(x) << ", " << get<1>(x) << ", " << get<2>(x) << endl;
}
実行結果
3, 2, 1 2, 3, 1
以下はクラステンプレートにおいて定数のテンプレート引数をとる例です。
#include <bits/stdc++.h>
using namespace std;
// MODで割ったあまりをxに保持するような構造体
template <int MOD>
struct Modulo {
int x;
Modulo() {}
Modulo(int v) {
x = v % MOD;
}
// 足し算
Modulo plus(Modulo<MOD> other) {
Modulo<MOD> result;
result.x = (x + other.x) % MOD;
return result;
}
};
int main() {
Modulo<10> a(7), b(5);
auto c = a.plus(b);
cout << c.x << endl; // (5 + 7) % 10 == 2
}
実行結果
2
注意点
テンプレートを用いて宣言された関数や構造体にタイプミスなどのミスがあったとしても、それがプログラムの中で使われていない場合に、コンパイルエラーにならないことがあります。 これは、使われていないテンプレートはコンパイル時に無視されるからです。詳しくは「細かい話の実体化について」を読んでください。
以下は関数テンプレートの中でタイプミスをしている例です。
#include <bits/stdc++.h>
using namespace std;
struct X {
void f() {
cout << "X" << endl;
}
};
struct Y {
void f() {
cout << "Y" << endl;
}
};
template <typename T>
void call_f(T v) {
v.g(); // fと書くところをタイプミスでgと書いてしまったとする
}
int main() {
// 何もしない
}
実行結果
本来、関数fを呼び出すために用意された関数call_fですが、タイプミスで関数gを呼び出そうとしています。 タイプミスしていますが、このテンプレートはプログラム中で使われていないため、正常にコンパイル・実行されます。
次のように、call_fを使おうとしたときに初めてコンパイルエラーが発生します。
#include <bits/stdc++.h>
using namespace std;
struct X {
void f() {
cout << "X" << endl;
}
};
struct Y {
void f() {
cout << "Y" << endl;
}
};
template <typename T>
void call_f(T v) {
v.g(); // fと書くところをタイプミスでgと書いてしまったとする
}
int main() {
X x;
Y y;
call_f(x); // Xのfが呼ばれてほしい
call_f(y); // Yのfが呼ばれてほしい
}
標準エラー出力
./Main.cpp: In instantiation of ‘void call_f(T) [with T = X]’: ./Main.cpp:23:11: required from here ./Main.cpp:17:3: error: ‘struct X’ has no member named ‘g’ v.g(); // fと書くところをタイプミスでgと書いてしまったとする ^ ./Main.cpp: In instantiation of ‘void call_f(T) [with T = Y]’: ./Main.cpp:24:11: required from here ./Main.cpp:17:3: error: ‘struct Y’ has no member named ‘g’
「少しずつ書いてコンパイルして確認して……」というようなコーディングを行う場合には注意が必要です。
細かい話
テンプレートの実体化
テンプレートは同じような処理を一般化できる便利な機能ですが、実は「関数・構造体を自動的に生成するための設計図」にすぎません。 例えば、関数テンプレートは「それぞれの型専用の関数を自動的に生成するための機能」です。
テンプレートを用いて定義された関数・構造体を使うときには、実際にはその実体(関数・構造体)が生成されてから使われることになります。 このようにテンプレートから実体が作られることをテンプレートの実体化といいます。
テンプレートの実体化はコンパイラによって自動的に行われます。 プログラム中でテンプレートが使われているときに、その使われ方に応じて実体化が行われるので、 あるテンプレートがプログラム中で全く使われていない場合には実体化は行われません。
square関数における例
関数テンプレートの具体例として紹介したsquare関数を例として説明します。
#include <bits/stdc++.h>
using namespace std;
/*
// xの二乗を返す
int square_int(int x) {
return x * x;
}
// xの二乗を返す
double square_double(double x) {
return x * x;
}
*/
// xの二乗を返す (関数テンプレート版)
template <typename T>
T square(T x) {
return x * x;
}
int main() {
int a = 3;
double b = 1.2;
cout << square<int>(a) << endl; // int版のsquare関数の呼び出し
cout << square<double>(b) << endl; // double版のsquare関数の呼び出し
}
実行結果
9 1.44
まず、squareの関数テンプレートを宣言しただけでは関数は何も生成されません。
プログラム中でsquare<int>(a)のように使われることで、コンパイラによって「int用のsquare関数」(square_int関数と同等な関数)が生成されます。
同様にsquare<double>(b)のように使われていると「double用の関数」(square_double関数と同等な関数)が作られます。
square<int>(a)とsquare<double>(b)ではそれぞれが実体化されるので、プログラムが実行される際に実際に呼ばれている関数は別のものということになります。
ただし、square<int>(2)とsquare<int>(3)のように同じint型に対する呼び出しについては、同じ関数がよばれることになります。
square<int>(2)によってint型に対する実体化が行われ、square<int>(3)については既に実体化したものを呼び出す、とイメージするとよいでしょう。
競技プログラミングでよく用いられるテンプレートの例
競技プログラミングでよく用いられる関数テンプレートとして、chmax/chminを紹介します。
#include <bits/stdc++.h>
using namespace std;
// aよりもbが大きいならばaをbで更新する
// (更新されたならばtrueを返す)
template <typename T>
bool chmax(T &a, const T& b) {
if (a < b) {
a = b; // aをbで更新
return true;
}
return false;
}
// aよりもbが小さいならばaをbで更新する
// (更新されたならばtrueを返す)
template <typename T>
bool chmin(T &a, const T& b) {
if (a > b) {
a = b; // aをbで更新
return true;
}
return false;
}
//-------------------------------
int f(int n) {
// (適当な関数)
return n * n - 8 * n + 3;
}
int main() {
// f(1), f(2), ..., f(10)の最小値と最大値を求める
int ans_min = 1000000000;
int ans_max = 0;
for (int i = 1; i <= 10; i++) {
chmin(ans_min, f(i)); // 最小値を更新
chmax(ans_max, f(i)); // 最大値を更新
}
cout << ans_min << " " << ans_max << endl;
}
実行結果
-13 23
chminは最小値を求める際に、chmaxは最大値を求める際などに用いると便利です。
typenamとclass
テンプレートの宣言におけるtypenameの部分はclassと書いても全く同じ意味になります。
// template <typename T>と書くのと同じ
template <class T>
T square(T x) {
return x * x;
}
// template <typename T>と書くのと同じ
template <class T>
struct Point {
T x;
T y;
void print() {
cout << "(" << x << ", " << y << ")" << endl;
}
};
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 配列や
mapなどのコンテナの各要素に対して順番に処理を行うときにイテレータを用いることができる - イテレータを変数に入れる場合は
autoを用いる - イテレータの操作
| 操作 | 記法 |
|---|---|
| コンテナの先頭の要素を指すイテレータを得る | コンテナ.begin() |
| コンテナの末尾の要素の次を指すイテレータを得る | コンテナ.end() |
| イテレータの比較 | イテレータ1 == イテレータ2, イテレータ1 != イテレータ2 |
| イテレータ間の距離 | distance(イテレータ1, イテレータ2) |
| イテレータの移動 | advance(イテレータ, k);(イテレータをk回進める), イテレータ++;, イテレータ--; |
| 前後のイテレータを得る | next(イテレータ, k)(k個先のイテレータ。kの指定は省略すると1として扱われる),prev(イテレータ, k)(k個前のイテレータ)イテレータ + k,イテレータ - k(map/setでは使えない) |
| イテレータの指す要素へのアクセス | *イテレータ(map/setのイテレータは読み取り専用) |
| イテレータの指す要素のメンバへのアクセス | イテレータ->メンバ(map/setのイテレータは読み取り専用) |
| イテレータの指す要素の削除 | コンテナ.erase(イテレータ) |
- 要素を削除したり、追加することによってイテレータが無効になることがある
- 無効なイテレータを使用しないように注意が必要
イテレータ
配列やmapなどのコンテナの各要素に対して順番に処理を行うときにイテレータを用いることができます。
イテレータを用いると処理を一般化できることが多く、
実際にSTLにおいて「一連の要素に対して何かを行う」ような関数はイテレータを引数に取る形で実装されています。
例えば配列をソートするときに用いるsortはイテレータを引数に取ります。
sortに渡していた配列.begin()や配列.end()がイテレータを表します。
配列に対するイテレータは次の図のように「各要素を指すもの」として考えることができます。

上の図で、イテレータ1は3つ目の要素である5を指すイテレータで、イテレータ2は7つ目の要素である4を指すイテレータです。
イテレータに対する操作としては、「次の位置のイテレータを得る」ことや「イテレータが指す要素にアクセスする」などの操作ができます。
次のサンプルプログラムは、配列の2番目の要素にアクセスする例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> a = {3, 1, 5, 6, 7, 2, 4};
auto itr1 = a.begin(); // aの先頭を指すイテレータ
itr1 = itr1 + 2; // a[2]を指すイテレータ
auto itr2 = itr1 + 4; // 末尾の要素(a[6])を指すイテレータ
cout << *itr1 << endl; // itr1が指す要素(a[2])へのアクセス
cout << *itr2 << endl; // itr2が指す要素(a[6])へのアクセス
}
実行結果
5 4
次のサンプルプログラムは、for文を用いて配列の要素に順番にアクセスする例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> a = {1, 2, 3};
// a.begin() .. 先頭の要素を指すイテレータ
// a.end() .... 終端を指すイテレータ
// it++ ....... イテレータを1つ分進める (it = it + 1と同じ)
for (auto it = a.begin(); it != a.end(); it++) {
cout << *it << endl;
}
}
実行結果
1 2 3
配列の要素に対するアクセスはインデックスを指定してa[1]のように書くことができるので、
実際に上のサンプルプログラムのように書くことはあまりないかもしれません。
しかしイテレータには配列以外のデータ構造に対しても同じように扱えるというメリットがあります。
これによって、例えば「配列専用のソート関数」を用意しなくてよくなり、
イテレータをサポートする任意のデータ構造に対して、同じソート関数sortを用いることができるようになっています。
イテレータの型
イテレータの型はコンテナ毎に定義されていて、複雑なものになっています。
手書きするのは大変なので通常はautoを用います。
vector<int> a = {1, 2, 3};
auto itr1 = a.begin();
set<int> b = {4, 5, 6};
auto itr2 = b.begin();
// itr1とitr2は別の型
厳密な型が必要な場合はcppreference.comなどを参照してください。
先頭の要素のイテレータ
コンテナ.begin()
コンテナの先頭の要素を指すイテレータを返します。 コンテナが空の場合は「末尾の要素の次」を指すイテレータを返します。
終端のイテレータ
コンテナ.end()
コンテナの終端 (最後の要素の次)を指すイテレータを返します。末尾の要素を指すイテレータではないことに注意してください。
一見扱いにくいように見えますが、for文での終了判定する際などに便利な場合があります。
また、endが返すイテレータの指す位置にアクセスしてはならないことに注意してください。
このような、それが指す位置に要素が存在しないようなイテレータに対してアクセスを行うことは未定義な動作を引き起こします。
イテレータの比較
イテレータ1 == イテレータ2
2つのイテレータが同じ位置を指すときにtrueになります。
イテレータ1 != イテレータ2
2つのイテレータが違う位置を指すときにtrueになります。
イテレータ間の距離
distance(イテレータ1, イテレータ2)
「イテレータ1を何回進めるとイテレータ2に一致するか」を返します。
mapやsetのイテレータの場合、イテレータ1がイテレータ2よりも後ろの要素を指す場合、動作は未定義です。
イテレータの移動
これらの操作ではイテレータの変数自体が変更されます。
1つ進める
イテレータ++;
k個分進める
イテレータをk回進めるときには以下のように書くこともできます。
advance(イテレータ, k);
1つ後ろに進める
イテレータ--;
k個分後ろに進める
advanceに負の値を渡すことで、指定回数分後ろに進めることができます。
advance(イテレータ, -k); // k回分後ろに進める
前後のイテレータを得る
イテレータをコピーした後で、++やadvanceを用いれば同じことができます。
次
next(イテレータ) // 次の要素を指すイテレータ next(イテレータ, k) // k個先の要素を指すイテレータ イテレータ + k // k個先の要素を指すイテレータ (map/setでは使えない)
1つ後ろ
prev(イテレータ) // 1つ後ろの要素を指すイテレータ prev(イテレータ, k) // k個後ろの要素を指すイテレータ イテレータ - k // k個後ろの要素を指すイテレータ (map/setでは使えない)
nextやprevは返り値として前後のイテレータを返します。
引数に渡したイテレータ自体は書き換わりません。
イテレータが指す要素へのアクセス
*イテレータ
コンテナ.end()が返すイテレータや、空のコンテナ.begin()が返すイテレータに対してアクセスを行うことは未定義な動作を引き起こします。
イテレータが指す要素のメンバへのアクセス
イテレータ->メンバ変数 イテレータ->メンバ関数() // メンバ関数の呼び出し
具体例
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<pair<int, int>> a = {{1, 4}, {2, 5}, {3, 6}};
auto itr = a.begin() + 1;
// cout << (*itr).first << ", " << (*itr).second << endl; と書くのと同じ
cout << (itr->first) << ", " << (itr->second) << endl;
}
実行結果
2, 5
イテレータの使用例
i番目の要素を指すイテレータ
next(コンテナ.begin(), i)
各要素に対して処理
for (auto it = コンテナ.begin(); it != コンテナ.end(); it++) {
// 各要素に対する処理
}
要素の削除
イテレータが指す要素を削除することもできます。
コンテナ.erase(イテレータ); // イテレータが指す要素を削除
要素の削除によってそのイテレータが無効化されます。詳しくは注意点で説明します。
for文で各要素に対する処理を行っているときに、削除を行う場合には次のようにします。
for (auto it = コンテナ.begin(); it != コンテナ.end()) {
if (要素を削除する条件) {
// eraseは削除後の次の要素のイテレータを返します。
it = コンテナ.erase(it); // itの指す要素を削除
} else {
it++;
}
}
末尾の要素を指すイテレータ
endは終端を指すイテレータを返すことを説明しましたが、
末尾の要素を指すイテレータが欲しい場合は次のようにすればよいです。
prev(コンテナ.end())
空のコンテナに対してこの操作を行ってはいけないことに注意してください。
イテレータの操作の計算量
イテレータの操作にかかる計算量はコンテナによって異なります。
配列
配列のイテレータを操作するときの計算量は以下の通りです。
| 操作 | 計算量 |
|---|---|
begin(), end() |
O(1) |
next, prev, +, - |
O(1) |
advance, ++, -- |
O(1) |
distance |
O(1) |
*や->によるアクセス |
O(1) |
| 要素の削除 | 削除する要素以降の要素数をNとして、O(N) |
map/set
map/setのイテレータを操作するときの計算量は以下の通りです。
| 操作 | 計算量 |
|---|---|
begin(), end() |
O(1) |
next, prev, ++, -- |
移動する回数をNとしてO(N) |
advance, ++, -- |
移動する回数をNとしてO(N) |
distance |
イテレータ間の距離をNとしてO(N) |
*や->によるアクセス |
O(1) |
| 要素の削除 | 償却計算量でO(1) |
「償却計算量でO(1)」とは、同じ処理をN回行ったときに1回あたりの計算量がO(1)になるという意味です。
注意点
無効なイテレータ
コンテナに対して要素の削除や追加を行うと、操作前のイテレータが無効化されることがあります。 無効なイテレータを使用することは未定義の動作を引き起こします。
イテレータを取っておいて、後から使いまわすような場合には注意する必要があります。
以下にイテレータが無効化される場合の例を挙げます。 詳しくはcppreference.comなどを参照してください。
vector
要素を削除すると、その要素を含むそれより後ろの要素に対するイテレータが無効化されます。
必要に応じてerase関数の戻り値を利用することができます。
また、push_backなどによって、コンテナの容量が変更される場合には、全ての要素に対するイテレータが無効化されます。
要素へのアクセスによってイテレータが無効化されることはありません。
map/set
要素を削除すると、その要素に対するイテレータが無効化されます。
必要に応じてerase関数の戻り値を利用することができます。
読み取りや、要素の追加ではイテレータが無効化されることはありません。
map/setのイテレータは読み取り専用
mapやsetのイテレータの指す要素を変更することはできません。
細かい話
STLの関数の紹介
STLの関数で、イテレータに関連するものをいくつか紹介します。
sort
既に紹介していますが、データを整列するための関数です。
sort(イテレータ1, イテレータ2);
イテレータ1とイテレータ2の間にある要素を整列します。
sort(配列.begin(), 配列.end());のように用いれば配列全体を整列できますし、sort(配列.begin() + 1, 配列.end());のように用いれば先頭以外を整列することができます。
find
イテレータの範囲内から指定した値に一致する最初の要素を探し、その要素を指すイテレータを返します。 見つからなかった場合は、範囲の最後を返します。
配列の場合
find(イテレータ1, イテレータ2, 値) // 見つからなかった場合はイテレータ2を返す
計算量はイテレータの距離をNとしてO(N)です。
map/setの場合
map/setの場合は次のようにして、メンバ関数版のfindを用いる方が高速です。
オブジェクト.find(イテレータ1, イテレータ2, 値) // 見つからなかった場合はイテレータ2を返す
計算量はコンテナの要素数をNとしてO(\log N)です。
具体例
配列の中に3があるかを探す例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> a = {1, 2, 3, 5};
// 3の要素を指すイテレータ
auto itr = find(a.begin(), a.end(), 3);
// もし存在しなければ、a.end()が返る
if (itr == a.end()) {
cout << "not found" << endl;
} else {
// itrが添字の何番目を指すかを求める
int idx = distance(a.begin(), itr);
cout << "a[" << idx << "] = " << *itr << endl;
}
}
実行結果
a[2] = 3
find_if
イテレータの範囲内から、条件を満たす最初の要素を探し、その要素を指すイテレータを返します。 見つからなかった場合は、範囲の最後を返します。
find_if(イテレータ1, イテレータ2, 条件の関数) // 見つからなかった場合はイテレータ2を返す
条件の関数には「要素を引数として受け取りbool値を返す」関数を指定します。
find_ifは、この関数がtrueを返す最初のイテレータを返します。
条件にはラムダ式を用いることもできます。
計算量はイテレータの距離をNとしてO(N)です。
具体例
配列の中から偶数の要素を探す例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> a = {1, 3, 4, 5, 9, 10};
// 偶数であるような最初の要素を指すイテレータ
auto itr = find_if(a.begin(), a.end(), [](int x) { return (x % 2 == 0); });
if (itr == a.end()) {
cout << "not found" << endl;
} else {
cout << *itr << endl;
}
}
実行結果
4
lower_bound
イテレータの範囲内から指定した値以上の最小の要素を探し、その要素を指すイテレータを返します。 見つからなかった場合は、範囲の最後を返します。
lower_boundを用いる場合、指定する範囲がソート済みである必要があります。
配列の場合
lower_bound(イテレータ1, イテレータ2, 値) // 見つからなかった場合はイテレータ2を返す
計算量はイテレータの距離をNとしてO(\log N)です。
map/setの場合
map/setの場合は次のようにして、メンバ関数版のlower_boundを用いる方が高速です。
オブジェクト.lower_bound(値) // 見つからなかった場合はオブジェクト.end()を返す
計算量はコンテナの要素数をNとしてO(\log N)です。
具体例
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> a = {8, 5, 3};
sort(a.begin(), a.end()); // lower_boundを使うためにソートする
// 5以上の最小の要素を指すイテレータ
auto itr = lower_bound(a.begin(), a.end(), 5);
if (itr == a.end()) {
cout << "not found" << endl;
} else {
cout << *itr << endl;
}
// 6以上の最小の要素を指すイテレータ
itr = lower_bound(a.begin(), a.end(), 6);
if (itr == a.end()) {
cout << "not found" << endl;
} else {
cout << *itr << endl;
}
}
実行結果
5 8
upper_bound
イテレータの範囲内から指定した値より大きな最小の要素を探し、その要素を指すイテレータを返します。 見つからなかった場合は、範囲の最後を返します。
使い方や計算量はlower_boundと同じです。
こちらも、map/setの場合はメンバ関数版を用います。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- プログラム上の変数はメモリ上に保存される
- メモリは巨大な配列のようなもの
- メモリ上の位置はアドレスという数値で識別される
- アドレスは配列の添字に対応
- ポインタはアドレスを扱う整数型
- ポインタの使い方
| 操作 | 記法 |
|---|---|
| ポインタの宣言 | 型 *ポインタ; |
| 変数のアドレスを取得 | &変数 |
| ポインタの指す先へのアクセス(読み書き) | *ポインタ |
| ポインタそのものへのアクセス | ポインタ |
| ポインタ経由でのメンバアクセス | ポインタ->メンバ |
- ヒープ領域の確保
型 *ポインタ1 = new 型; // 1つ分の領域を確保 型 *ポインタ2 = new 型[n]; // 連続したn個分の領域を確保
- ヒープ領域の解放
delete ポインタ1; //「new 型」で確保したときに返ってきたポインタ delete[] ポインタ2; //「new 型[n]」で確保したときに返ってきたポインタ
ポインタ
ポインタはメモリを直接扱うために用いられます。 ポインタを用いることで複雑な操作を行うことができます。 ポインタを全く使わずにプログラムを書くこともできますが、ポインタを使うとシンプルに書ける場合や、効率よく動作するプログラムを書ける場合があります。
このページの説明は3.01.整数型の内容を前提としています。忘れてしまった人や理解が曖昧な人はもう一度読み返してみてください。
メモリ
これまでは、変数を使用するとその分だけメモリを消費するというざっくりとした説明をしていましたが、 ここでもう少し詳しく説明しておきます。
メモリというのはコンピュータに取り付けられている記憶装置です。 ここでは巨大な配列のようなものだと思ってください。 コンピュータはプログラムに従って、この巨大な配列に値を書き込んだり、読み込んだりしながら動いていきます。
メモリは1byte(8bit)という単位を区切りとして扱われます。
この1バイトの単位はアドレス(番地)という数値によって識別されます。
アドレスは配列の添字に対応していると考えると分かりやすいでしょう。
C++で書くならvector<uint8_t>のような感じです。
8bit以上のサイズのデータを保存する場合は、8bit毎に分割して保存されます。 詳しくは細かい話で扱います。
メモリとC++
3.01.整数型で説明したように、 C++の数値型は扱える数値の範囲に応じて様々なものが用意されていました。 そして、それぞれの型にメモリ上でのサイズが決まっています。
例えば、int32_tは32bitの整数型なので、メモリ上の32bit(4byte)を使用することになります。
uint8_t型は8bitの整数型なのでメモリ上の8bit(1byte)を使用します。
sizeof演算子
「ある型がメモリ上で何バイトなのか」を知りたいときはsizeof(型)を使うことができます。
cout << sizeof(int32_t) << endl; // 4 cout << sizeof(int8_t) << endl; // 1
ポインタ
メモリのアドレスは整数値で表すことができます。 この整数値を扱うための型がポインタ型であり、ポインタ型の変数をポインタといいます。
ポインタのイメージ
以下の図はメモリの101番地に12が入っていて、そこを指すポインタがあるイメージです。

ポインタの基本的な機能は、以下の2つです。
- ポインタの指すアドレスに値を書き込む
- ポインタの指すアドレスから値を読み込む
具体的な例を見てみます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x = 1;
int *p; // int8_t型に対するポインタを定義
p = &x; // xのアドレスで初期化
*p = 2; // ポインタが指すメモリへの書き込み
cout << x << endl; // 2
int y;
y = *p; // ポインタ経由でxの値を読み取る
cout << y << endl; // 2
}
実行結果
2 2
以下のスライドで一行毎の動作を解説します。
ポインタの基本的な使い方は、この例で示したように以下の3つです。
&変数で変数のアドレスを得ることができる型 *ポインタ名でポインタを定義*ポインタでポインタの指すメモリ領域へのアクセス(書き込み・読み込み)
同じ*という記号が別の意味で使われている点に注意が必要です。
この他の機能として、アドレス値の加算・減算を行うこともできます。
ポインタの使い方
ポインタの宣言
型 *ポインタ名; // ポインタ変数の宣言
複数のポインタを同時に宣言する場合は、次のようにします。
型 *ポインタ名1, *ポインタ名2;
ポインタの指す先の変更
ポインタ = &変数; // 変数のアドレスでポインタを初期化 ポインタ = 別のポインタ; // 別のポインタと同じアドレスを指す
ポインタの指す先へのアクセス
*ポインタ
*を付けることで、ポインタの指す先に対して書き込み・読み取りを行うことができます。
型 *ポインタと*ポインタという形が出てきますが、
前者はポインタの宣言で、後者はポインタのアクセスであることに注意が必要です。
ポインタ関連の演算子はややこしいので、慣れないうちは一つずつ何をしているのかを確認しながら書きましょう。
ポインタの指す先のメンバアクセス
ポインタがオブジェクトを指している場合に、->演算子を用いてメンバへアクセスすることができます。
(*ポインタ).メンバと書くのと同じ意味ですが、よりシンプルに書くことができます。
オブジェクトを指すポインタ->メンバ
具体例
#include <bits/stdc++.h>
using namespace std;
struct A {
int data;
void print() {
cout << data << endl;
}
};
int main() {
A a = A { 1 };
// オブジェクトaを指すポインタ
A *p = &a;
p->print(); // a.print()の呼び出し
p->data = 2; // a.dataの書き換え
p->print();
}
実行結果
1 2
ポインタの値
ポインタ自体はメモリ上のアドレス(整数値)を保持しているということを説明しました。 アドレスはメモリを巨大な配列だとみなしたときに添字に対応する値です。
以下のプログラムは「ポインタの値そのもの」つまりポインタの指すアドレスを直接出力する例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
uint8_t x = 1;
uint8_t *p;
p = &x; // ポインタの内容をxのアドレスで初期化
cout << p << endl; // ポインタの内容を出力
}
実行結果(例)
0x7ffcf0483a6c
*を付けずにポインタ名だけを書いたときにはポインタ自体の値に対するアクセスになる点に注意してください。
上の実行結果では0x7ffcf0483a6cという出力が得られています。
これはアドレスを16進数で表記したものです。10進数で書けば140724339751532です。
この値自体の意味は考える必要はありませんが、この例では変数xがメモリの0x7ffcf0483a6c番地に割り当てられていることが分かります。
16進法について 10進法が0〜9の10個の文字で数を表現するのに対し、0〜9の10文字とA~Fのアルファベットを合わせた16文字を使って数を表現するのが16進法です。
10進法 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 16進法 0 1 2 3 4 5 6 7 8 9 A B C D E F 10 11 12 13 14 15 16 17 18 19 1A また、16進数であることを明示するために先頭に
0xを付けて0x1Aのように表すことがよくあります。 C++でもこのような表記で整数値を書くことができます。
アドレスを書くときには16進法がよく用いられます。
そしてcoutもポインタに対しては16進数でアドレスを出力するようになっています。
アドレス値の比較
ポインタ1 == ポインタ2 ポインタ1 != ポインタ2
==や!=でポインタを比較することができ、これらはアドレス値を比較した結果になります。
具体例
#include <bits/stdc++.h>
using namespace std;
int main() {
int x = 123;
int *p = &x; // xを指すポインタ
int *q = &x; // yを指すポインタ
// アドレスの比較
if (p == q) {
cout << "p == q" << endl;
} else {
cout << "p != q" << endl;
}
}
実行結果
p == q
スタック領域とヒープ領域
C++で変数を使うとそれに対応するメモリ領域が割り当てられるということを説明しました。
変数を使うにはその分だけメモリを割り当てる必要があります。 メモリは有限なので、必要な分だけメモリを割り当て、必要が無くなったらそのメモリを解放する必要があります。
このようなメモリの管理は面倒ですが、ある程度はコンパイラが自動でやってくれます。
ここでは、どのようにメモリが割り当てられるかを簡単に説明します。
メモリ領域の分類
プログラムから使用されるメモリは静的領域、スタック領域、ヒープ領域という大きく分けて3種類の領域に分けられます。
静的領域
グローバル変数はプログラムの開始から終了までずっと有効な変数なので、 ずっとメモリ上に割り当てられている必要があります。
プログラム開始時に割り当てられて終了時に解放されればよいので、 グローバル変数のメモリ割り当て・解放はコンパイラによって自動的に行われます。
このときにグローバル変数が配置されるメモリ領域を静的領域といいます。
スタック領域
ローカル変数はスコープの範囲内で有効なので、 スコープの始まりでメモリを確保し、スコープの終わりでメモリを解放すれば十分です。
ローカル変数の割り当てと解放もコンパイラによって自動的に行われます。 このときに配置されるメモリ領域をスタック領域といいます
ヒープ領域
プログラムを設計する上で、何らかの情報を「スコープの範囲を超えて」扱いたいことがあります。 このような場合に利用するのがヒープ領域です。
ヒープ領域は柔軟に使える分、プログラマが責任を持って割り当て・解放を行わなければなりません。
また、ヒープ領域はポインタを介して読み書きを行う必要があります。
ヒープ領域はメモリを有効活用したい場合のためのものです。 メモリ有効活用する必要のない場合は、予めグローバル変数として必要な分だけメモリを確保しておけば十分なことが多いです。
ヒープ領域の確保
次のようにしてヒープ領域のメモリを確保することができます。
型 *ポインタ1 = new 型; // 1つ分の領域を確保 型 *ポインタ2 = new 型(引数); // 1つ分の領域を確保(コンストラクタに引数を渡す) 型 *ポインタ3 = new 型[n]; // 連続したn個分の領域を確保
「連続してn個分の領域を確保」することで配列のように扱うことができます。
ヒープ領域から確保したメモリは、明示的に解放しない限り、プログラムが終了するまで残り続けます。
メモリを解放するには次のようにします。
delete ポインタ1; //「new 型」や「new 型()」で確保したときに返ってきたポインタ delete[] ポインタ3; //「new 型[n]」で確保したときに返ってきたポインタ
new 型[n]で確保したメモリをdelete ポインタのようにしたり、
明示的に確保した領域以外を指すポインタに対してdeleteしてはいけません。
次の例はヒープ領域を使う必要のないケースですが、使い方の例として見てください。
1つ分の領域を確保する例
#include <bits/stdc++.h>
using namespace std;
int main() {
uint32_t *p;
// uint32_t型の変数の分だけヒープ領域からメモリを確保する
p = new uint32_t;
// ポインタを介して使う
*p = 123;
cout << *p << endl;
// メモリを解放する
delete p;
}
実行結果
123
連続した領域を確保する例
#include <bits/stdc++.h>
using namespace std;
int main() {
uint32_t *p;
// uint32_t型の変数10個分だけ(つまり4*10=40バイト分)ヒープ領域からメモリを確保する
p = new uint32_t[10];
// ポインタを介して使う
uint32_t *tmp = p; // アドレス値のコピー
for (int i = 0; i < 10; i++) {
*tmp = i; // i番目にiを書き込む
tmp++; // 次の要素を指すように変更
}
tmp = p; // pの位置に戻す
for (int i = 0; i < 10; i++) {
cout << *tmp << endl;
tmp++;
}
// メモリを解放する(10個分連続で確保したのでdelete[]を使う)
delete[] p;
}
実行結果
0 1 2 3 4 5 6 7 8 9
注意点
メモリアクセスの制約
ポインタを通して好きな位置に値を書き込んだり読み込んだりできるかと言うと、そうではありません。 基本的に「変数のために確保されたメモリ領域」か「明示的に確保したメモリ領域」にしかアクセスしてはいけません。 めちゃくちゃなアドレスに対して無理やり書き込み・読み込みを行おうと試みるのは意図しない挙動に繋がります。
ポインタを扱うプログラムを書く場合は、許されていないメモリ領域にアクセスしていないかを常に気をつける必要があります。 この意味で、ポインタを扱うプログラムは難しいと言えます。
細かい話
ポインタの宣言における*の位置
ポインタの宣言における*の位置は以下のうちどれでもよいです。
型 *ポインタ名 型* ポインタ名 型 * ポインタ名
どれを使ってもよいですが、プログラムを通して統一するべきです。
複数のポインタを宣言する際に、それぞれに*が必要であるということが分かりやすいように、APG4bでは1番目の書き方を採用しています。
nullptr
ポインタが初期化されていないことを明示したり、有効なアドレスを指していないことを明示するための
特殊な値としてnullptrを用いることができます。nullptrは多くの場合0を意味します。
あるポインタがnullptrでないことを確認するために次のように書くことができます。
if (ポインタ) {
(nullptrでないとき)
} else {
(nullptrのとき)
}
例
#include <bits/stdc++.h>
using namespace std;
int main() {
uint8_t x = 1;
uint8_t *p = nullptr; // 初期値として nullptr を使う
p = &x;
*p = 2;
p = nullptr; // 使い終わったポインタには nullptr を入れておく
cout << (int)x << endl; // 2
if (p) {
cout << "not nullptr" << endl;
} else {
cout << "nullptr" << endl;
}
}
実行結果
2 nullptr
複数バイトの変数
1バイトより大きいデータは複数のバイトに分割されて保存されます。
例えば、12345という数値を保存することを考えてみます。 この数値は1バイト(0~255)の範囲に収まらないデータなので、 「57」と「48」という数に分割し、2バイトに分けて保存することにします。 すると、57 + 48 * 256 = 12345として元の値を復元することができます。
このように複数バイトにまたがって値を保存するときに、 どのように分割するかはコンピュータやコンパイラなどの環境によって決まっています。 詳しく知りたい人はエンディアンというキーワードで調べてみてください。
アドレス値の加減算
ポインタ(自体の値)に対して加減算を行うことで「その分だけずらした位置を指すポインタ」を得ることができます。 メモリを連続的に確保し配列のように用いる際に、ポインタの加減算は有用です。
次のプログラムは、int型10要素分のメモリを確保し、順番にアクセスする例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
// int型10要素分をヒープ領域から確保(先頭のアドレスがpに入っている)
int *p = new int[10];
int *q = nullptr;
for (int i = 0; i < 10; i++) {
q = p + i; // i番目の要素のポインタを取得
*q = i; // q の指す位置に i を書き込む
}
q = p;
for (int i = 0; i < 10; i++) {
cout << *q << endl;
q++; // q = q + 1と同じ意味(次の要素を指すポインタに変更)
}
delete[] p; // メモリ解放
}
実行結果
0 1 2 3 4 5 6 7 8 9
より正確には、Tという型のポインタpに対してp + dと書いた場合、
pのアドレスをd要素分進めたアドレス(つまりsizeof(T)バイト先のアドレス)という意味になります。
参照・イテレータとの関係
C++の参照やイテレータは、ポインタをより扱いやすくするために用意された機能です。
以下にポインタを参照・イテレータのように使う例を挙げますが、 このような処理を実際にポインタを用いて行う必要はありません。
参照として使う例
#include <bits/stdc++.h>
using namespace std;
void f(int &ref) {
ref = 2;
}
// ポインタを用いた参照渡し
void g(int *ptr) {
*ptr = 2;
}
int main() {
int x = 1;
f(x); // 参照渡し
cout << x << endl;
int y = 1;
g(&y); // yのアドレスを渡す
cout << y << endl;
}
実行結果
2 2
イテレータとして使う例
#include <bits/stdc++.h>
using namespace std;
int main() {
// イテレータを用いて順番にアクセス
vector<int> a = { 1, 2, 3 };
for (auto it = a.begin(); it != a.end(); it++) {
cout << *it << endl;
}
// ポインタを用いて順番にアクセス
vector<int> b = { 1, 2, 3 };
// b.data() ... bのデータの先頭アドレスを返す(&b[0] と同じ)
int *begin_addr = b.data();
for (int *ptr = begin_addr; ptr < begin_addr + 3; ptr = ptr + 1) {
cout << *ptr << endl;
}
}
実行結果
1 2 3 1 2 3
voidポインタ
void *という特殊なポインタ型があります。
voidへのポインタは任意のポインタ値を扱うことができます。
voidへのポインタは、指す先へのアクセスを行うことはできません。 アクセスを行うには元のポインタ型にキャストする必要があります。
コンパイラは元々のポインタ型が何であったかをチェックしてくれないので、 voidポインタを扱うときはプログラマが責任を持って元の型を管理する必要があります。
以下はvoidポインタの配列に色々なオブジェクトへのポインタを入れる例です。
#include <bits/stdc++.h>
using namespace std;
int main() {
int x = 123;
string y = "hello";
double z = 4.5;
// voidポインタの配列 順番に int*, string*, double* 型のポインタ
vector<void *> ptrs = { &x, &y, &z };
int *xp = (int *)ptrs[0];
string *yp = (string *)ptrs[1];
double *zp = (double *)ptrs[2];
cout << *xp << endl;
cout << *yp << endl;
cout << *zp << endl;
}
実行結果
123 hello 4.5
STLのコンテナの実装
今まで使ってきたvectorは内部的にポインタを用いて実装されています。
基本的には、コンストラクタなどでヒープメモリを確保しておき、そこに要素を格納し、
デストラクタなどでメモリの解放を行う、といったことを行います。
これまで扱ってきた事項を組み合わせればシンプルなvectorを実装できるので、ぜひ挑戦してみてください。
ポインタの使いどころ
ポインタは参照やイテレータがある分、C++では使いどころが思いつかないかもしれません。
ヒープ領域の確保が絡んだときにポインタが真価を発揮すると言えるでしょう。 従って、メモリを効率的に使いたい場合にはポインタが必要になります。
また、競技プログラミングにおいても木構造やグラフなどのデータ構造を表現するときに ポインタを用いると便利なことがあります。 競技プログラミングを初めたばかりのうちはポインタが必要になるケースはほとんどないと思いますが、 将来使うことがあったら思い出してみてください。
スマートポインタ
C++ではメモリ確保を安全に楽に使うために、スマートポインタと呼ばれるライブラリが用意されています。
大きく分けて次の2種類のスマートポインタがあります
std::unique_ptrstd::shared_ptr
ここでは簡単な説明にとどめますが、興味がある人は調べてみてください。
std::unique_ptrは、メモリの「所有権」をやりとりし、
不必要になったタイミングで自動的にメモリが解放されます。
常に1つのstd::unique_ptrが所有権を持っていて、
所有権を持っていないポインタからは対象のメモリ領域を触ることができないようになっています。
例
#include <bits/stdc++.h>
using namespace std;
int main() {
// int型1つ分の領域を確保(123で初期化)
unique_ptr<int> p1 = make_unique<int>(123);
*p1 += 1;
cout << *p1 << endl;
unique_ptr<int> p2;
p2 = move(p1); // メモリの所有権をp2に移動
//*p1 += 10; // p1は所有権を失ったのでエラー
*p2 += 1;
cout << *p2 << endl;
} // ここでp2の持っていた所有権が無効になり自動的にメモリが回収される
実行結果
124 125
std::shared_ptrは、複数のstd::shared_ptrオブジェクトがメモリの所有権を共有するモデルです。
こちらも、共有しているstd::shared_ptrオブジェクトが0個になったタイミングで対象のメモリが解放されます。
例
#include <bits/stdc++.h>
using namespace std;
int main() {
shared_ptr<int> p3;
{
shared_ptr<int> p1 = make_shared<int>(123);
{
shared_ptr<int> p2 = p1; // p2も所有権を共有
*p2 += 1;
p3 = p2; // p3も所有権を共有
} // p2が所有権を手放す(p1, p3が共有している状態)
*p1 += 1;
} // p1が所有権を手放す(p3が持っている状態)
*p3 += 1;
cout << *p3 << endl;
} // 所有者がいなくなり、メモリが解放される
実行結果
126
std::shared_ptrには循環参照が生じた場合にメモリが回収できなくなるという問題があります。
この場合std::weak_ptrを用いることで循環参照を回避できるようになっています。
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題を解く前に 付録1.コードテストの使い方を読んでください。
問題文
次の出力をするプログラムを書いてください。
実行結果
こんにちは AtCoder
出力の最後(つまりAtCoderの後)に改行する必要があります。注意してください。
回答プログラムの作成方法
回答プログラムは、次のサンプルプログラムを改変して作成することを推奨します。
プログラムをコピーし、コードテストのページに貼り付けましょう。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "Hello, world!" << endl;
cout << "Hello, AtCoder!" << endl;
cout << "Hello, C++!" << endl;
}
このプログラムを実行すると次のように出力されます。
サンプルプログラムの実行結果
Hello, world! Hello, AtCoder! Hello, C++!
これを次の出力を行うようにプログラムを書き換え、正しく動作することが確認できたら提出しましょう。
正しい実行結果
こんにちは AtCoder
「AtCoder」の「C」は大文字であることに注意しましょう。
今後の提出は必ず問題ページから行ってください。説明ページに提出した場合と表示されます。
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "こんにちは" << endl;
cout << "AtCoder" << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題を解く前に 付録2.提出結果の見方を読んでください。
問題文
A君は次の出力をするプログラムを作ろうとしました。
実行結果
いつも2525 AtCoderくん
しかし、書いたプログラムを実行してみるとエラーが発生しました。
A君が書いたプログラムのエラーを修正し、正しく動作するようにしてください。
A君が書いたプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "いつも << 252 << endl;
cout << "AtCoderくん" << endl
}
このコードをコードテストで実行すると、標準エラー出力に以下のエラーメッセージが表示されます。
標準エラー出力
./Main.cpp:5:11: warning: missing terminating " character
cout << "いつも << 252 << endl;
^
./Main.cpp:5:3: error: missing terminating " character
cout << "いつも << 252 << endl;
^
./Main.cpp:6:3: error: stray ‘\343’ in program
cout << "AtCoderくん" << endl
^
./Main.cpp:6:3: error: stray ‘\200’ in program
./Main.cpp:6:3: error: stray ‘\200’ in program
./Main.cpp: In function ‘int main()’:
./Main.cpp:5:8: error: no match for ‘operator<<’ (operand types are ‘std::ostream {aka std::basic_ostream<char>}’ and ‘std::ostream {aka std::basic_ostream<char>}’)
cout << "いつも << 252 << endl;
^
./Main.cpp:5:8: note: candidate: operator<<(int, int) <built-in>
./Main.cpp:5:8: note: no known conversion for argument 2 from ‘std::ostream {aka std::basic_ostream<char>}’ to ‘int’
In file included from /usr/include/c++/5/istream:39:0,
from /usr/include/c++/5/sstream:38,
from /usr/include/c++/5/complex:45,
from /usr/include/c++/5/ccomplex:38,
...
この問題の取り組み方
Aくんのプログラムには複数のエラーが含まれています。
わかるエラーから一つずつ直し、コードテスト上で実行してみて、直っているかどうか確かめましょう。
コードテストの使い方は付録1.コードテストの使い方に書いてあります。
「AtCoder」の「C」は大文字であることに注意しましょう。
ヒント
1.02.プログラムの書き方とエラーの「コンパイルエラーの例」を参考にしましょう。
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "いつも" << 2525 << endl;
cout << "AtCoderくん" << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
Aくんは1から100までの和を求めようと思いました。
数学の授業で習ったとおり、1から100までの和は次の式で求められます。
\frac{1}{2} \times 100 \times (100+1)
この式の値を出力してください。
ヒント(C++版)
「1.03.四則演算と優先順位」の「注意点」に書かれている項目を読んでみましょう。
コードテストで正しく動作することを確認してから提出しましょう。
サンプルプログラム
次のプログラムをコピー&ペーストした後、コメント/* */を消して式を書いてください。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << /* ここに式を書く */ << endl;
}
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
// / 2を最後に計算することで正しい計算結果になる
cout << 100 * (100 + 1) / 2 << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
次のプログラムをコピー&ペーストして、指定した場所にプログラムを追記することで問題を解いて下さい。
#include <bits/stdc++.h>
using namespace std;
int main() {
// 一年の秒数
int seconds = 365 * 24 * 60 * 60;
// 以下のコメント/* */を消して追記する
cout << /* 1年は何秒か */ << endl;
cout << /* 2年は何秒か */ << endl;
cout << /* 5年は何秒か */ << endl;
cout << /* 10年は何秒か */ << endl;
}
int型の変数secondsは一年の秒数を表しています。これを利用して
- 1年は何秒か
- 2年は何秒か
- 5年は何秒か
- 10年は何秒か
を順に一行ずつ表示するプログラムを作って下さい。
うるう秒やうるう年のことは考え無くて良いとします。
実行結果(一部を「?????」で隠しています)
31536000 63072000 ????? ?????
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
// 一年の秒数
int seconds = 365 * 24 * 60 * 60;
// 以下のコメントを消して追記する
cout << seconds << endl;
cout << seconds * 2 << endl;
cout << seconds * 5 << endl;
cout << seconds * 10 << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題を解く前に、以下の2つのリンク先の説明を読んでください。
問題文
2つの整数A, Bが与えられます。A+Bの計算結果を出力してください。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
// ここにプログラムを追記
}
制約
- 0≦A, B≦100
- A, Bは整数
入力
入力は次の形式で標準入力から与えられます。
A B
出力
A+Bの計算結果を出力してください。出力の最後には改行が必要です。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
1 2
出力例1
3
入力例2
100 99
出力例2
199
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
0 0
テスト出力1
0
テスト入力2
0 50
テスト出力2
50
テスト入力3
0 50
テスト出力3
50
テスト入力4
27 81
テスト出力4
108
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
// ここに追記
int A, B;
cin >> A >> B;
cout << A + B << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
1行の計算式が与えられるので、その結果を出力してください。
与えられる計算式のパターンと対応する出力は以下の表の通りです。
| 入力 | 出力 | 備考 |
|---|---|---|
| A + B | A + Bの計算結果を出力 | |
| A - B | A - Bの計算結果を出力 | |
| A * B | A × Bの計算結果を出力 | |
| A / B | A ÷ Bの計算結果を出力 | 小数点以下は切り捨てて出力 Bが0の場合はerrorと出力 |
| A ? B | errorと出力 |
|
| A = B | errorと出力 |
|
| A ! B | errorと出力 |
サンプルプログラム
このプログラムを元に解答を作成することを推奨します。
#include <bits/stdc++.h>
using namespace std;
int main() {
int A, B;
string op;
cin >> A >> op >> B;
if (op == "+") {
cout << A + B << endl;
}
// ここにプログラムを追記
}
制約
- 0≦A, B≦100
- A, Bは整数
- opは+, -, *, /, ?, =, ! のいずれか一つ
入力
入力は次の形式で標準入力から与えられます。
A op B
出力
入力の計算式の計算結果を出力してください。 出力の最後には改行が必要です。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
1 + 2
出力例1
3
入力例2
5 - 3
出力例2
2
入力例3
10 * 20
出力例3
200
入力例4
10 / 3
出力例4
3
計算結果の小数点以下は切り捨てます。
入力例5
100 / 0
出力例5
error
Bが0の場合はerrorと出力することに注意してください。
入力例6
25 ? 31
出力例6
error
入力例7
0 + 0
出力例7
0
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
100 = 100
テスト出力1
error
テスト入力2
17 ! 91
テスト出力2
error
テスト入力3
0 / 20
テスト出力3
0
テスト入力4
0 * 0
テスト出力4
0
テスト入力5
0 - 0
テスト出力5
0
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
int A, B;
string op;
cin >> A >> op >> B;
if (op == "+") {
cout << A + B << endl;
}
else if (op == "-") {
cout << A - B << endl;
}
else if (op == "*") {
cout << A * B << endl;
}
else if (op == "/" && B != 0) {
cout << A / B << endl;
}
else {
cout << "error" << endl;
}
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
次のプログラムで宣言されているbool型の変数a, b, cに対し、trueまたはfalseを代入することで、AtCoderと出力されるようにしてください。
5,6,7行目における変数a,b,cへの代入以外のプログラムの書き換えは行わないものとします。
プログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
// 変数a,b,cにtrueまたはfalseを代入してAtCoderと出力されるようにする。
bool a = // true または false
bool b = // true または false
bool c = // true または false
// ここから先は変更しないこと
if (a) {
cout << "At";
}
else {
cout << "Yo";
}
if (!a && b) {
cout << "Bo";
}
else if (!b || c) {
cout << "Co";
}
if (a && b && c) {
cout << "foo!";
}
else if (true && false) {
cout << "yeah!";
}
else if (!a || c) {
cout << "der";
}
cout << endl;
}
入力
この問題に入力はありません
出力
AtCoderと出力してください。
回答例
答え方の例です。
変数a, b, cの全てにfalseを代入していますが、YoCoderと出力されているので、この解答は不正解となります。
#include <bits/stdc++.h>
using namespace std;
int main() {
// 変数a,b,cにtrueまたはfalseを代入してAtCoderと出力されるようにする。
bool a = false; // true or false
bool b = false; // true or false
bool c = false; // true or false
// ここから先は変更しないこと
if (a) {
cout << "At";
}
else {
cout << "Yo";
}
if (!a && b) {
cout << "Bo";
}
else if (!b || c) {
cout << "Co";
}
if (a && b && c) {
cout << "foo!";
}
else if (true && false) {
cout << "yeah!";
}
else if (!a || c) {
cout << "der";
}
cout << endl;
}
出力例
YoCoder
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
// 変数a,b,cにtrueまたはfalseを代入してAtCoderと出力されるようにする。
bool a = true;// true または false
bool b = false;// true または false
bool c = true;// true または false
// ここから先は変更しないこと
if (a) {
cout << "At";
}
else {
cout << "Yo";
}
if (!a && b) {
cout << "Bo";
}
else if (!b || c) {
cout << "Co";
}
if (a && b && c) {
cout << "foo!";
}
else if (true && false) {
cout << "yeah!";
}
else if (!a || c) {
cout << "der";
}
cout << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
A君はたこ焼きの情報を処理するプログラムを書いています。
このプログラムは以下の2パターンの入力を処理します。
パターン1
入力
1 price N
1行目で、パターンを表す整数1が入力されます。
2行目で、たこ焼き1個あたりの値段priceが入力されます。
3行目で、たこ焼き1セットあたりの個数Nが入力されます。
出力
たこ焼き1セットあたりの値段(=N \times price)を出力します。
パターン2
入力
2 text price N
1行目で、パターンを表す整数2が入力されます。
2行目で、たこ焼きセットの説明文textが入力されます。
3行目で、たこ焼き1個あたりの値段priceが入力されます。
4行目で、たこ焼き1セットあたりの個数Nが入力されます。
出力
1行目で、たこ焼きセットの説明文textの末尾に!をつけて出力します。
2行目で、たこ焼き1セット辺りの値段(=N \times price)を出力します。
A君はこの通りの動作をするプログラムを書いたつもりでしたが、プログラムを実行してみるとエラーが発生しました。
A君が書いたプログラムのエラーを修正し、正しく動作するようにしてください。
A君が書いたプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
int p;
cin >> p;
// パターン1
if (p == 1) {
int price;
cin >> price;
}
// パターン2
if (p == 2) {
string text;
int price;
cin >> text >> price;
}
int N;
cin >> N;
cout << text << "!" << endl;
cout << price * N << endl;
}
もしプログラムを修正した結果、A君が書いたプログラムとの違いが大きくなってしまったとしても、ACができればOKです。
制約
- 0≦price, N≦100
- price, Nは整数
- textは半角英数字からなる
- textは20文字以内
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
1 80 5
出力例1
400
入力例2
2 umai 150 3
出力例2
umai! 450
入力例3
2 good! 30 8
出力例3
good!! 240
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
1 2 3
テスト出力1
6
テスト入力2
2 yeah!...!ok 100 100
テスト出力2
yeah!...!ok! 10000
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
int p;
cin >> p;
// パターン2
if (p == 2) {
string text;
cin >> text;
cout << text << "!" << endl;
}
int price, N;
cin >> price >> N;
cout << price * N << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
整数x,a,bが入力されます。
以下の4つの値を計算し、1行ずつ出力してください。
- xに1を足した値
- (1.で出力した値)に(a+b)を掛けた値
- (2.で出力した値)に(2.で出力した値)を掛けた値
- (3.で出力した値)から1を引いた値
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
int x, a, b;
cin >> x >> a >> b;
// 1.の出力
x++;
cout << x << endl;
// ここにプログラムを追記
}
制約
- 0≦x, a, b≦100
- x, a, bは整数
入力
入力は次の形式で標準入力から与えられます。
入力
x a b
出力
1.の出力 2.の出力 3.の出力 4.の出力
出力の最後には改行が必要です。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
1 2 3
出力例1
2 10 100 99
- xは1なので、xに1を足した値は2です。
- (1.で出力した値)は2であり、a+bは5なので、(1.で出力した値)に(a+b)を掛けた値は10です。
- (2.で出力した値)は10なので、(2.で出力した値)に(2.で出力した値)を掛けた値は100です。
- (3で出力した値)は100なので、(3.で出力した値)から1を引いた値は99です。
入力例2
3 2 5
出力例2
4 28 784 783
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
0 0 0
テスト出力1
1 0 0 -1
テスト入力2
100 100 100
テスト出力2
101 20200 408040000 408039999
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
int x, a, b;
cin >> x >> a >> b;
x++;
cout << x << endl;
x *= a + b;
cout << x << endl;
x *= x;
cout << x << endl;
x--;
cout << x << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
AさんとBさんのテストの点数A, Bが与えられます。
2人の点数を表す横向きの棒グラフを出力してください。
棒グラフは1点を一つの]で表し、次の形式で出力します。
A:Aさんの点数個の「]」 B:Bさんの点数個の「]」
例えば、Aさんの点数が5点、Bさんが9点だった場合、次のように出力します。
A:]]]]] B:]]]]]]]]]
Bさんの棒グラフを出力した後にも改行が必要なことに注意してください。
cout << endl;と書けば改行だけを出力することができます。
ページ末尾に問題のヒントがあります。詰まったら見てみましょう。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
int A, B;
cin >> A >> B;
// ここにプログラムを追記
}
制約
- 0≦A, B≦20
- A, Bは整数
入力
入力は次の形式で標準入力から与えられます。
入力
A B
出力
A:Aさんの点数個の「]」 B:Bさんの点数個の「]」
出力の最後には改行が必要です。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
5 9
出力例1
A:]]]]] B:]]]]]]]]]
問題文にある例と同じものです。
入力例2
0 20
出力例2
A: B:]]]]]]]]]]]]]]]]]]]]
ヒント
次のプログラムはAさんが5点だったときの棒グラフを出力するものです。
このプログラムを書き換えて、Aさんの点数が5点ではなかったときにも対応し、Bさんの棒グラフも出力するようにしてください。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "A:";
int i = 0;
while (i < 5) {
cout << "]";
i++;
}
cout << endl;
}
ヒント出力
A:]]]]]
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
7 3
テスト出力1
A:]]]]]]] B:]]]
テスト入力2
20 20
テスト出力2
A:]]]]]]]]]]]]]]]]]]]] B:]]]]]]]]]]]]]]]]]]]]
テスト入力3
18 0
テスト出力3
A:]]]]]]]]]]]]]]]]]] B:
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
int A, B;
cin >> A >> B;
int i = 0;
cout << "A:";
while (i < A) {
cout << "]";
i++;
}
cout << endl;
i = 0;
cout << "B:";
while (i < B) {
cout << "]";
i++;
}
cout << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
電卓の操作が与えられるので、計算途中の値と計算結果の値を出力してください。
電卓の操作は次の形式で入力されます。
入力の形式
計算の数N 最初の値A 演算子op_1 計算する値B_1 演算子op_2 計算する値B_2 \vdots 演算子op_N 計算する値B_N
次の入力は((2 + 1) × 3) ÷ 2を表しています。
入力例
3 2 + 1 * 3 / 2
出力では「何行目の出力か」と、「計算途中の値」を出力してください。
出力の形式
1:1個目の計算結果 2:2個目の計算結果 \vdots N:N個目の計算結果
次の出力は上の入力例に対する出力です。
出力例
1:3 2:9 3:4
与えられる計算式のパターンと対応する出力は以下の表の通りです。
| 入力 | 出力 | 備考 |
|---|---|---|
| + B | + Bの計算結果を出力する。 | |
| - B | - Bの計算結果を出力する。 | |
| * B | × Bの計算結果を出力する。 | |
| / B | ÷ Bの計算結果を出力する。 | 小数点以下は切り捨てて出力する。 Bが0の場合はerrorと出力し、それ以降は出力を行わない。 |
÷ Bにおいて、Bが0の場合はerrorと出力し、それ以降は出力を行わない ことに注意してください。
ページ末尾に問題のヒントがあります。詰まったら見てみましょう。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
int N, A;
cin >> N >> A;
// ここにプログラムを追記
}
制約
- 0≦N≦7
- 0≦A, B_i≦10
- A, B_i, Nは整数
- op_iは+, -, *, / のいずれか一つ
入力
入力は次の形式で標準入力から与えられます。
N A op_1 B_1 op_2 B_2 \vdots op_N B_N
出力
1:1個目の計算結果 2:2個目の計算結果 \vdots N:N個目の計算結果
出力の最後には改行が必要です。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
3 2 + 1 * 3 / 2
出力例1
1:3 2:9 3:4
問題文中で説明した入出力です。
入力例2
2 3 / 2 / 2
出力例2
1:1 2:0
割り算では小数点以下を切り捨てます。
入力例3
4 3 + 1 / 0 * 2 - 10
出力例3
1:4 error
割り算でB_iが0の場合はerrorと出力し、それ以降は出力をしないことに注意してください。
入力例4
7 10 * 10 * 10 * 10 * 10 * 10 * 10 * 10
出力例4
1:100 2:1000 3:10000 4:100000 5:1000000 6:10000000 7:100000000
ヒント1
次のプログラムは、5つの整数を入力で一つずつ受け取り、受け取った整数を足して出力します。
また、今回の問題と同様に、出力が何行目かも同時に出力します。
今回の問題を解く際の参考にしてください。
#include <bits/stdc++.h>
using namespace std;
int main() {
int sum = 0;
for (int i = 0; i < 5; i++) {
int x;
cin >> x;
sum += x;
cout << i + 1 << ":" << sum << endl;
}
}
ヒント入力
3 4 2 1 10
ヒント出力
1:3 2:7 3:9 4:10 5:20
ヒント2
ジャッジでテストされる入力のうち2つをヒントとして示します。
サンプルは全てあっていてWAの原因がわからない人は、以下のケースに正解しているか確かめてみましょう。
テスト入力1
7 0 - 5 * 7 / 4 + 0 + 0 - 10 * 5
テスト出力1
1:-5 2:-35 3:-8 4:-8 5:-8 6:-18 7:-90
テスト入力2
6 0 / 4 / 3 / 5 + 3 / 7 / 1
テスト出力2
1:0 2:0 3:0 4:3 5:0 6:0
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
7 0 - 5 * 7 / 4 + 0 + 0 - 10 * 5
テスト出力1
1:-5 2:-35 3:-8 4:-8 5:-8 6:-18 7:-90
テスト入力2
6 0 / 4 / 3 / 5 + 3 / 7 / 1
テスト出力2
1:0 2:0 3:0 4:3 5:0 6:0
テスト入力3
3 1 * 4 * 3 / 0
テスト出力3
1:4 2:12 error
テスト入力4
7 0 * 2 / 0 + 1 / 0 + 5 * 2 - 10
テスト出力4
1:0 error
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
int N, A;
cin >> N >> A;
for (int i = 0; i < N; i++) {
int x;
string op;
cin >> op >> x;
if (op == "+") {
A += x;
}
else if (op == "-") {
A -= x;
}
else if (op == "*") {
A *= x;
}
else if (op == "/" && x != 0) {
A /= x;
}
else {
cout << "error" << endl;
break;
}
cout << i + 1 << ":" << A << endl;
}
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
1と+と-のみからなる式Sが1行で与えられるので、計算結果を出力してください。
例えば式Sが1+1+1-1であったとき、計算結果は2です。
具体的な式Sの形式は以下の通りです。
- 式Sの1文字目は必ず1です。
- その後、「+または-」と1が交互に続きます。
- Sの最後の文字も必ず1です。
式と演算子はスペースで区切られていないことに注意してください。
ページ末尾に問題のヒントがあります。詰まったら見てみましょう。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
string S;
cin >> S;
// ここにプログラムを追記
}
制約
- 1≦|S|≦100 (|S|は文字列の長さ)
- Sは1から始まり、その後+または-と1が交互に続き、1で終わる
入力
入力は次の形式で標準入力から与えられます。
S
出力
Sの計算結果を出力してください。
出力の最後には改行が必要です。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
1+1+1-1
出力例1
2
問題文中で説明した入出力です。
入力例2
1-1-1-1-1-1
出力例2
-4
計算結果は負の値になることもあります。
入力例3
1
出力例3
1
入力は1だけで終わることもあります。
入力例4
1-1-1+1+1+1+1-1+1-1+1-1+1
出力例4
3
ヒント
次のプログラムは9文字の式Sにいくつ1が含まれているを出力するプログラムです。
今回の問題を解く際の参考にしてください。
#include <bits/stdc++.h>
using namespace std;
int main() {
string S;
cin >> S;
// 1の数を表す変数
int count = 0;
// 9文字の式に限定していることに注意
for (int i = 0; i < 9; i++) {
// 1があればcountを増やす
if (S.at(i) == '1') {
count++;
}
}
cout << count << endl;
}
ヒント入力
1-1-1+1+1
ヒント出力
5
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1+1
テスト出力1
-25
テスト入力2
1+1+1+1+1+1+1+1+1+1+1+1+1
テスト出力2
13
テスト入力3
1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1
テスト出力3
-33
テスト入力4
1+1-1+1-1+1-1+1-1+1-1+1-1+1-1+1+1-1-1+1+1-1-1+1+1+1-1-1-1+1
テスト出力4
2
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
string S;
cin >> S;
// 計算結果を保持する変数
int answer = 1;
for (int i = 0; i < S.size(); i++) {
if (S.at(i) == '+') {
answer++;
}
if (S.at(i) == '-') {
answer--;
}
}
cout << answer << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
N人のテストの点数が与えられます。
それぞれの人の点数が平均点から何点離れているか計算してください。
平均点は次の式で求められます。i番目の人の点数はA_iで表します。
平均点 = \frac{A_1 + A_2 + \cdots + A_N}{N}
平均点が整数にならない場合、小数点以下を切り捨てた数値を平均点とします。
例えば3人のテストの点数が「2点、1点、4点」だったとき、\frac{2 + 1 + 4}{3} = 2.333 \cdotsなので、平均点は小数点以下を切り捨てて2点になります。
そして、平均点から何点離れているかを計算した結果である「0点、1点、2点」が答えになります。
「0点、-1点、2点」でも「0点、1点、-2点」でも無いことに注意してください。
ページ末尾に問題のヒントがあります。詰まったら見てみましょう。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
}
制約
- 1≦N≦1000
- 0≦A_i≦100
- N, A_iは整数
入力
入力は次の形式で標準入力から与えられます。
N A_1 A_2 \cdots A_N
出力
それぞれの人の点数が平均点から何点離れているかを1行ずつ出力してください。
1人目の計算結果 2人目の計算結果 \vdots N人目の計算結果
出力の最後には改行が必要です。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
3 2 1 4
出力例1
0 1 2
問題文中で説明した入出力です。
入力例2
2 80 70
出力例2
5 5
このケースの平均点は75点です。
どちらの点数も平均点から5点離れています。
入力例3
5 100 100 100 100 100
出力例3
0 0 0 0 0
このケースの平均点は100点です。
入力例4
10 53 21 99 83 75 40 33 62 18 100
出力例4
5 37 41 25 17 18 25 4 40 42
ヒント
今回の問題は次のプログラムに追記すれば解くことができます。
追記箇所が2つあることに注意してください。
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
// N要素の配列
vector<int> A(N);
// 入力処理
for (int i = 0; i < N; i++) {
cin >> A.at(i);
}
// 合計点
int sum = 0;
// 合計点を計算
for (int i = 0; i < N; i++) {
// ①ここにプログラムを追記
}
// 平均点
int mean = sum / N;
// 平均点から何点離れているかを計算して出力
for (int i = 0; i < N; i++) {
// ②ここにプログラムを追記
// 負の数を出力しないように注意
}
}
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
1 80
テスト出力1
0
テスト入力2
データが大きすぎるため省略
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
// N要素の配列
vector<int> A(N);
// 入力処理
for (int i = 0; i < N; i++) {
cin >> A.at(i);
}
// 合計点
int sum = 0;
// 合計点を計算
for (int i = 0; i < N; i++) {
// ①ここにプログラムを追記
sum += A.at(i);
}
// 平均点
int mean = sum / N;
// 平均点から何点離れているかを計算して出力
for (int i = 0; i < N; i++) {
// ②ここにプログラムを追記
// 負の数を出力しないように注意
if (A.at(i) > mean) {
cout << A.at(i) - mean << endl;
}
else {
cout << mean - A.at(i) << endl;
}
}
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
三人兄弟のA君とB君とC君が背くらべをしています。
三人の身長が与えられるので、最も大きい人と最も小さい人の身長差を出力してください。
例えば、A君の身長が160、B君の身長が154、C君の身長が152であるとします。
このとき最も大きいのはA君で、最も小さいのはC君なので、出力は8になります。
この問題はSTLの関数を使わなくても解けますが、STLの関数を使うと簡潔にプログラムを記述できます。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
int A, B, C;
cin >> A >> B >> C;
}
制約
- 1≦A, B, C≦200
- A, B, Cは整数
入力
入力は次の形式で標準入力から与えられます。
A B C
出力
最もが大きい人と最も小さい人の身長差を出力してください。
出力の最後には改行が必要です。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
160 154 152
出力例1
8
問題文で説明したケースです。
入力例2
200 200 200
出力例2
0
三人に身長差は無いので0と出力します。
入力例3
145 1 170
出力例3
169
入力例4
150 190 160
出力例4
40
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
150 130 140
テスト出力1
20
テスト入力2
160 180 130
テスト出力2
50
テスト入力3
100 105 190
テスト出力3
90
テスト入力4
100 100 5
テスト出力4
95
テスト入力5
130 180 180
テスト出力5
50
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
int a, b, c;
cin >> a >> b >> c;
int maximum = max(max(a, b), c); // 最大値を計算
int minimum = min(min(a, b), c); // 最小値を計算
cout << maximum - minimum << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
三人兄弟のA君とB君とC君は、お父さんに1つのプレゼントを貰うことになりました。
貰えるプレゼントの予算は「テストの合計点の積」で決まります。
三人兄弟はそれぞれN個のテストを受けました。
A君とB君とC君の「i番目のテストの点数」をそれぞれA_i, B_i, C_iで表すと、プレゼントの予算は次の式で求まります。
プレゼントの予算 = (A_1 + A_2 + \cdots + A_N) \times (B_1 + B_2 + \cdots + B_N) \times (C_1 + C_2 + \cdots + C_N)
例えば、2個のテスト受けた結果、A君は5点と7点、B君は4点と10点、C君は9点と2点だったとします。
この場合、(5 + 7) \times (4 + 10) \times (9 + 2) = 12 \times 14 \times 11 = 1848から、プレゼントの予算は1848円になります。
A君はこの計算を行うプログラムを途中まで書きました。
A君が書いたプログラムに追記し、プログラムを完成させてください。
ページ末尾に問題のヒントがあります。詰まったら見てみましょう。
A君が書いたプログラム
#include <bits/stdc++.h>
using namespace std;
// 1人のテストの点数を表す配列から合計点を計算して返す関数
// 引数 scores: scores.at(i)にi番目のテストの点数が入っている
// 返り値: 1人のテストの合計点
int sum(vector<int> scores) {
// ここにプログラムを追記
}
// 3人の合計点からプレゼントの予算を計算して出力する関数
// 引数 sum_a: A君のテストの合計点
// 引数 sum_b: B君のテストの合計点
// 引数 sum_c: C君のテストの合計点
// 返り値: なし
void output(int sum_a, int sum_b, int sum_c) {
// ここにプログラムを追記
}
// -------------------
// ここから先は変更しない
// -------------------
// N個の入力を受け取って配列に入れて返す関数
// 引数 N: 入力を受け取る個数
// 返り値: 受け取ったN個の入力の配列
vector<int> input(int N) {
vector<int> vec(N);
for (int i = 0; i < N; i++) {
cin >> vec.at(i);
}
return vec;
}
int main() {
// 科目の数Nを受け取る
int N;
cin >> N;
// それぞれのテストの点数を受け取る
vector<int> A = input(N);
vector<int> B = input(N);
vector<int> C = input(N);
// それぞれの合計点を計算
int sum_A = sum(A);
int sum_B = sum(B);
int sum_C = sum(C);
// プレゼントの予算を出力
output(sum_A, sum_B, sum_C);
}
制約
- 1≦N≦10
- 0≦A_i, B_i, C_i≦100
- N, A_i, B_i, C_iは整数
入力
入力は次の形式で標準入力から与えられます。
N A_1 A_2 \cdots A_N B_1 B_2 \cdots B_N C_1 C_2 \cdots C_N
出力
プレゼントの予算を出力してください。
出力の最後には改行が必要です。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
2 5 7 4 10 9 2
出力例1
1848
問題文で説明したケースです。
入力例2
3 100 100 100 100 100 100 100 100 100
出力例2
27000000
300 \times 300 \times 300 = 27000000なので、三人兄弟は27000000円分のプレゼントを貰えることになりました。
入力例3
5 95 20 74 81 10 100 50 32 84 31 0 0 0 0 0
出力例3
0
C君の合計点が0点だったので、プレゼントの予算も0円になります。
入力例4
2 10 0 0 5 1 1
出力例4
100
ヒント1
クリックでヒントを見る
今回の問題は今までの問題とは少し異なり、用意されたプログラムの動作を理解し、意図を読み取る必要があります。
プログラムがどのような順番で実行されていくかに注意して、A君が書いたプログラムを読んでみましょう。
ヒント2
この問題は「A君が書いたプログラムに追記して完成させる」という問題ですが、ヒントとして関数を使わずにこの問題と同じ処理をするプログラムを示します。このプログラムを参考にしてA君のsum関数とoutput関数を完成させてください。
#include <bits/stdc++.h>
using namespace std;
int main() {
// 科目の数Nを受け取る
int N;
cin >> N;
// それぞれのテストの点数を受け取る
// N要素の配列A,B,Cを宣言
vector<int> A(N), B(N), C(N);
// N個の入力をそれぞれ受け取る
for (int i = 0; i < N; i++) {
cin >> A.at(i);
}
for (int i = 0; i < N; i++) {
cin >> B.at(i);
}
for (int i = 0; i < N; i++) {
cin >> C.at(i);
}
// プレゼントの予算を出力
// テストの点数を表す配列から合計点を計算
int sum_a = 0;
for (int i = 0; i < A.size(); i++) {
sum_a += A.at(i);
}
int sum_b = 0;
for (int i = 0; i < B.size(); i++) {
sum_b += B.at(i);
}
int sum_c = 0;
for (int i = 0; i < C.size(); i++) {
sum_c += C.at(i);
}
// 3人の合計点からプレゼントの予算を計算して出力する
cout << sum_a * sum_b * sum_c << endl;
}
ヒント3
output関数の部分のみ答えを示します。これを参考にsum関数を完成させてください。
#include <bits/stdc++.h>
using namespace std;
// 1人のテストの点数を表す配列から合計点を計算して返す関数
// 引数 scores: scores.at(i)にi番目のテストの点数が入っている
// 返り値: 1人のテストの合計点
int sum(vector<int> scores) {
// ここにプログラムを追記
}
// 3人の合計点からプレゼントの予算を計算して出力する関数
// 引数 sum_a: A君のテストの合計点
// 引数 sum_b: B君のテストの合計点
// 引数 sum_c: C君のテストの合計点
// 返り値: なし
void output(int sum_a, int sum_b, int sum_c) {
cout << sum_a * sum_b * sum_c << endl;
}
// -------------------
// ここから先は変更しない
// -------------------
// N個の入力を受け取って配列に入れて返す関数
// 引数 N: 入力を受け取る個数
// 返り値: 受け取ったN個の入力の配列
vector<int> input(int N) {
vector<int> vec(N);
for (int i = 0; i < N; i++) {
cin >> vec.at(i);
}
return vec;
}
int main() {
// 科目の数Nを受け取る
int N;
cin >> N;
// それぞれのテストの点数を受け取る
vector<int> A = input(N);
vector<int> B = input(N);
vector<int> C = input(N);
// それぞれの合計点を計算
int sum_A = sum(A);
int sum_B = sum(B);
int sum_C = sum(C);
// プレゼントの予算を出力
output(sum_A, sum_B, sum_C);
}
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
10 2 8 3 1 10 8 32 15 9 100 5 1 2 0 3 2 1 10 43 20 0 100 7 10 0 82 19 0 90 51
テスト出力1
5871804
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
// 1人のテストの点数を表す配列から合計点を計算して返す関数
// 引数 scores: scores.at(i)にi番目のテストの点数が入っている
// 返り値: 1人のテストの合計点
int sum(vector<int> scores) {
int s = 0;
for (int i = 0; i < scores.size(); i++) {
s += scores.at(i);
}
return s;
}
// 3人の合計点からプレゼントの予算を計算して出力する関数
// 引数 sum_a: A君のテストの合計点
// 引数 sum_b: B君のテストの合計点
// 引数 sum_c: C君のテストの合計点
// 返り値: なし
void output(int sum_a, int sum_b, int sum_c) {
cout << sum_a * sum_b * sum_c << endl;
}
// -------------------
// ここから先は変更しない
// -------------------
// N個の入力を受け取って配列に入れて返す関数
// 引数 N: 入力を受け取る個数
// 返り値: 受け取ったN個の入力の配列
vector<int> input(int N) {
vector<int> vec(N);
for (int i = 0; i < N; i++) {
cin >> vec.at(i);
}
return vec;
}
int main() {
// 科目の数Nを受け取る
int N;
cin >> N;
// それぞれのテストの点数を受け取る
vector<int> A = input(N);
vector<int> B = input(N);
vector<int> C = input(N);
// それぞれの合計点を計算
int sum_A = sum(A);
int sum_B = sum(B);
int sum_C = sum(C);
// プレゼントの予算を出力
output(sum_A, sum_B, sum_C);
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
5つの要素からなる配列が与えられます。
同じ値の要素が隣り合っているような箇所が存在するかどうかを判定してください。
存在するなら"YES"を、存在しなければ"NO"を出力してください。
この問題も以下の手順で解いてみましょう。
- ループを使わないで書く
- パターンを見つける
- ループで書き直す
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> data(5);
for (int i = 0; i < 5; i++) {
cin >> data.at(i);
}
// dataの中で隣り合う等しい要素が存在するなら"YES"を出力し、そうでなければ"NO"を出力する
// ここにプログラムを追記
}
制約
- 0≦A_i≦100 (1 ≦ i ≦ 5)
- A_i (1 ≦ i ≦ 5)は整数
入力
入力は次の形式で標準入力から与えられます。
A_1 A_2 A_3 A_4 A_5
出力
配列の隣り合う要素のうち、値が等しいものが存在するなら"YES"を、存在しなければ"NO"を出力してください。
出力の最後には改行が必要です。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
5 3 3 1 4
出力例1
YES
入力例2
1 1 2 3 4
出力例2
YES
入力例3
1 2 1 2 1
出力例3
NO
入力例4
100 100 100 100 100
出力例4
YES
ヒント
- ループを使わないで書く
- パターンを見つける
- ループで書き直す
に沿って書く場合の流れをヒントで説明します。
まずは自分で考えてみて、詰まったら見てみましょう。
ヒント1 (ループを使わないで書く)
クリックでヒントプログラムを見る
隣合っている等しい要素があるかを順番に確認します。
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> data(5);
for (int i = 0; i < 5; i++) {
cin >> data.at(i);
}
// dataの中で隣り合う等しい要素が存在するなら"YES"を出力し、そうでなければ"NO"を出力する
if (data.at(0) == data.at(1) || data.at(1) == data.at(2) || data.at(2) == data.at(3) || data.at(3) == data.at(4)) {
cout << "YES" << endl;
}
else {
cout << "NO" << endl;
}
}
ヒント2 (パターンを見つける)
クリックでヒントを見る
繰り返しのパターンを見つけます。 ヒント1のヒントプログラムでは11行目のif文の中身が同じパターンの繰り返しになっています。
if (data.at(0) == data.at(1) || data.at(1) == data.at(2) || data.at(2) == data.at(3) || data.at(3) == data.at(4)) {
cout << "YES" << endl;
}
else {
cout << "NO" << endl;
}
このままだと直接for文に書き換えにくいので,「または」の条件を複数のif文に分解します。
また、答えがYESなのかNOなのかをbool型の変数に入れるようにします。次のプログラムではYESならtrue、NOならfalseとしています。
bool ans = false; // 始めはfalseにしておき、条件を満たすときにtrueになるようにする
if (data.at(0) == data.at(1)) {
ans = true;
}
if (data.at(1) == data.at(2)) {
ans = true;
}
if (data.at(2) == data.at(3)) {
ans = true;
}
if (data.at(3) == data.at(4)) {
ans = true;
}
if (ans) {
cout << "YES" << endl;
}
else {
cout << "NO" << endl;
}
次のパターンが繰り返し存在していることが分かります。
if (data.at(k) == data.at(k+1)) {
ans = true;
}
ヒント3 (ループで書き直す)
クリックでヒントプログラムを見る
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> data(5);
for (int i = 0; i < 5; i++) {
cin >> data.at(i);
}
// dataの中で隣り合う等しい要素が存在するなら"YES"を出力し、そうでなければ"NO"を出力する
bool ans = false; // 始めはfalseにしておき、条件を満たすときにtrueになるようにする
for (int i = 0; i < /* ここを変える */; i++) {
if (data.at(i) == data.at(i + 1)) {
/* ここを変える */
}
}
if (ans) {
cout << "YES" << endl;
}
else {
cout << "NO" << endl;
}
}
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
0 1 2 3 3
テスト出力1
YES
テスト入力2
0 1 100 100 4
テスト出力2
YES
テスト入力3
40 30 66 44 65
テスト出力3
NO
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> data(5);
for (int i = 0; i < 5; i++) {
cin >> data.at(i);
}
// dataの中で隣り合う等しい要素が存在するなら"YES"を出力し、そうでなければ"NO"を出力する
bool ans = false; // 始めはfalseにしておき、条件を満たすときにtrueになるようにする
for (int i = 0; i < 4; i++) {
if (data.at(i) == data.at(i + 1)) {
ans = true;
}
}
if (ans) {
cout << "YES" << endl;
}
else {
cout << "NO" << endl;
}
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
ある果物屋では、リンゴ・パイナップルがそれぞれN個売られています。i個目のリンゴ、パイナップルはそれぞれA_i円、P_i円です。
リンゴ・パイナップルをそれぞれ1つずつ選んで購入しようとするとき、合計金額が丁度S円になるような買い方が何通りあるか求めてください。
ただし、同じ値段の同じ種類の商品でも区別します。たとえば同じ値段のリンゴが複数あった場合、それらを買う場合は別の買い方として数えます。パイナップルについても同様です。また、リンゴ・パイナップルを買う順番は考慮しないものとします。
#include <bits/stdc++.h>
using namespace std;
int main() {
int N, S;
cin >> N >> S;
vector<int> A(N), P(N);
for (int i = 0; i < N; i++) {
cin >> A.at(i);
}
for (int i = 0; i < N; i++) {
cin >> P.at(i);
}
// リンゴ・パイナップルをそれぞれ1つずつ購入するとき合計S円になるような買い方が何通りあるか
// ここにプログラムを追記
}
制約
- 0≦N≦100
- 0≦S≦1000
- 1≦A_i, P_i≦500 (1 ≦ i ≦ N)
- A_i, P_i (1 ≦ i ≦ N)は整数
入力
入力は次の形式で標準入力から与えられます。
N S A_1 A_2 \cdots A_N P_1 P_2 \cdots P_N
出力
リンゴ・パイナップルをそれぞれ1つずつ購入しようとするとき、合計金額が丁度S円になるような 買い方が何通りあるかを出力してください。
出力の最後には改行が必要です。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
3 400 100 100 130 270 300 250
出力例1
3
合計が400円になる買い方は以下の3通りです。
1つ目のリンゴ、2つ目のパイナップルを購入すると、100円 + 300円 = 400円となります。
2つ目のリンゴ、2つ目のパイナップルを購入すると、100円 + 300円 = 400円となります。
3つ目のリンゴ、1つ目のパイナップルを購入すると、130円 + 270円 = 400円となります。
1つ目のリンゴと2つ目のリンゴがどちらも100円ですが、別の買い方として数えることに注意してください。
入力例2
10 600 70 110 90 120 90 20 260 150 220 150 170 100 250 350 60 280 450 460 20 220
出力例2
2
入力例3
3 200 100 100 100 100 100 100
出力例3
9
入力例4
1 0 100 200
出力例4
0
合計0円で買うことはできません。
ヒント
- ループを使わないで書く
- パターンを見つける
- ループで書き直す
に沿って書く場合の流れをヒントで説明します。
まずは自分で考えてみて、詰まったら見てみましょう。
ヒント1 (ループを使わないで書く)
クリックでヒントを見る
合計がS円になるような買い方が何通りあるかを求めるので、 すべての組み合わせをif文で確認できれば答えが求まるはずです。
一般のNでは考えにくいので、試してみるときはNを小さい値で仮定してみるとよいです。 N = 3のケースを全て書き出してみます。(添え字として0始まりの値を使っている点に注意してください。)
int ans = 0;
if (A.at(0) + P.at(0) == S) {
ans++;
}
if (A.at(0) + P.at(1) == S) {
ans++;
}
if (A.at(0) + P.at(2) == S) {
ans++;
}
if (A.at(1) + P.at(0) == S) {
ans++;
}
if (A.at(1) + P.at(1) == S) {
ans++;
}
if (A.at(1) + P.at(2) == S) {
ans++;
}
if (A.at(2) + P.at(0) == S) {
ans++;
}
if (A.at(2) + P.at(1) == S) {
ans++;
}
if (A.at(2) + P.at(2) == S) {
ans++;
}
添え字の変化に着目するとパターン化できそうです。
ヒント2 (パターンを見つける)
クリックでヒントを見る
変数i, jを導入してi番目のリンゴ、j番目のパイナップルを買う場合を考えます。
条件式は次のようになります。
if (A.at(i) + P.at(j) == S) {
ans++;
}
あとはi, jを網羅的に動かして上の文を実行できればよいです。
ヒント3 (ループで書き直す)
クリックでヒントを見る
変数i, jを導入してi番目のリンゴ、j番目のパイナップルを買う場合の判定文は次のようになります。
if (A.at(i) + P.at(j) == S) {
ans++;
}
i, jはそれぞれ別々に0からN - 1までの値を取ります。
このように変数(ここではi, j)の組み合わせを列挙したい場合は、多重ループを用います。
今回の場合は変数がi, jの2つなので、次のような二重ループになります。
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
// i, jを使う
}
}
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
10 520 430 310 230 390 130 220 70 370 400 160 390 120 450 30 250 140 200 300 270 30
テスト出力1
4
テスト入力2
100 500 247 365 116 339 302 274 383 230 444 136 12 100 92 498 16 190 252 438 404 493 46 105 197 254 180 455 233 280 289 286 301 205 200 477 273 481 494 287 202 211 327 359 341 4 51 336 101 416 142 35 401 457 61 179 33 362 180 176 60 247 499 44 279 372 424 439 224 99 379 322 110 159 383 143 164 435 6 461 61 391 38 225 163 273 222 156 33 300 42 228 164 22 244 66 28 208 243 36 417 93 62 231 388 7 434 37 474 357 262 182 36 298 426 331 252 129 113 156 111 441 375 210 492 499 302 287 493 170 262 233 475 406 72 401 468 156 220 1 410 12 223 150 240 159 345 239 455 404 419 19 46 174 499 218 423 145 196 307 401 260 470 424 171 284 437 44 500 316 156 192 422 391 365 485 145 22 410 124 110 182 28 143 203 289 95 85 415 401 191 268 262 341 391 130 364 274 379 443 53 389
テスト出力2
15
テスト入力3
100 1000 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500
テスト出力3
10000
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
解答例1
#include <bits/stdc++.h>
using namespace std;
int main() {
int N, S;
cin >> N >> S;
vector<int> A(N), P(N);
for (int i = 0; i < N; i++) {
cin >> A.at(i);
}
for (int i = 0; i < N; i++) {
cin >> P.at(i);
}
// リンゴ・パイナップルをそれぞれ1つずつ購入するとき合計S円になるような買い方が何通りあるか
int ans = 0; // 買い方が何通りあるか
// 実際に全ての買い方を試してみて、合計がS円ならカウントアップ
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
if (A.at(i) + P.at(j) == S) {
ans++;
}
}
}
cout << ans << endl;
}
解答例2 (範囲for文を用いた解法)
#include <bits/stdc++.h>
using namespace std;
int main() {
int N, S;
cin >> N >> S;
vector<int> A(N), P(N);
for (int i = 0; i < N; i++) {
cin >> A.at(i);
}
for (int i = 0; i < N; i++) {
cin >> P.at(i);
}
// リンゴ・パイナップルをそれぞれ1つずつ購入するとき合計S円になるような買い方が何通りあるか
int ans = 0; // 買い方が何通りあるか
// 実際に全ての買い方を試してみて、合計がS円ならカウントアップ
for (int x : A) {
for (int y : P) {
if (x + y == S) {
ans++;
}
}
}
cout << ans << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
あるゲーム大会にはN人が参加しM試合が行われました。各参加者には1からNの番号が割り当てられています。
試合に関する情報が与えられるので、M回の試合がすべて終了した時点での試合結果の表を作成し、出力してください。
ただし、同じ参加者のペアについて2回以上試合が行われることはないとします。
試合に関する情報は以下のような形式で与えられます。
試合に関する情報
試合1で勝った人の番号A_1 試合1で負けた人の番号B_1 試合2で勝った人の番号A_2 試合2で負けた人の番号B_2 \vdots \vdots 試合Mで勝った人の番号A_M 試合Mで負けた人の番号B_M
同じ参加者のペアについて2回以上試合が行われることはありません。
例えば、次のような情報が与えられることはありません。
1 2 2 1
試合結果の表とは、縦N行、横N列からなる次のような表Rです。
試合結果の表
R_{1, 1} R_{1, 2} R_{1, 3} \cdots R_{1, N}
R_{2, 1} R_{2, 2} R_{2, 3} \cdots R_{2, N}
R_{3, 1} R_{3, 2} R_{3, 3} \cdots R_{3, N}
\vdots \vdots \vdots \vdots \ddots \vdots
R_{N, 1} R_{N, 2} R_{N, 3} \cdots R_{N, N}
R_{i, j}の値は以下のように決まります。
i番の参加者とj番の参加者が試合をして、
- i番の参加者が勝ったならR_{i, j} =
o - i番の負けたならR_{i, j} =
x
i番の人とj番の人が試合を行っていない場合
- R_{i, j} =
-
以下に具体例を示します。
具体例
- 3人が参加した
- 2試合行われた
- 試合に関する情報は次の通り
1 2 3 1
この場合の試合結果の表は次のようになります。
- o x x - - o - -
- 1番の人と2番の人が試合を行い、1番の人が勝ったので、R_{1, 2} =
o、R_{2, 1} =x - 3番の人と1番の人が試合を行い、3番の人が勝ったので、R_{1, 3} =
x、R_{3, 1} =o
ただし、各行の行末に空白を含まないことに注意してください。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
int main() {
int N, M;
cin >> N >> M;
vector<int> A(M), B(M);
for (int i = 0; i < M; i++) {
cin >> A.at(i) >> B.at(i);
}
// ここにプログラムを追記
// (ここで"試合結果の表"の2次元配列を宣言)
}
行末に空白を含めない出力の仕方
以下は配列の要素を空白区切りで出力し末尾には空白を含めないようにする方法の1例です。
vector<int> a = {1, 2, 3, 4, 5};
for (int i = 0; i < 5; i++) {
cout << a.at(i);
if (i == 4) {
cout << endl; // 末尾なら改行
}
else {
cout << " "; // それ以外なら空白
}
}
制約
- 1≦N≦100
- 0≦M≦4950
- 1≦A_i, B_i≦N (1 ≦ i ≦ M)
- A_i \neq B_i (1 ≦ i ≦ M)
- 同じ参加者のペアで2回以上試合が行われることはない
- 入力はすべて整数
入力
入力は次の形式で標準入力から与えられます。
N M A_1 B_1 A_2 B_2 A_3 B_3 : : A_M B_M
出力
M試合が終了した時点での試合結果の表を出力してください。
ただし、各行の行末に空白を含まないことに注意してください。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
3 2 1 2 3 1
出力例1
- o x x - - o - -
- 1番の人と2番の人が試合を行い、1番の人が勝ったので、R_{1, 2} =
o、R_{2, 1} =x - 3番の人と1番の人が試合を行い、3番の人が勝ったので、R_{1, 3} =
x、R_{3, 1} =o
入力例2
7 12 1 5 5 4 6 2 1 7 2 4 6 3 1 3 6 4 3 7 5 7 4 3 6 1
出力例2
- - o - o x o - - - o - x - x - - x - x o - x o - x x - x - - o - - o o o o o - - - x - x - x - -
入力例3
1 0
出力例3
-
ヒント
クリックでヒントを開く
まずは、試合結果の表をプログラムで管理するために、N×Nの2次元配列を用意しましょう。
この2次元配列の型は、表の要素となる-, o, xの型なので、char型にすれば良いです。
縦a行、横b列の2次元配列の宣言方法は次の通りでした。
vector<vector<要素の型>> 変数名(a, vector<要素の型>(b));
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
4 6 1 2 1 3 1 4 2 3 2 4 3 4
テスト出力1
- o o o x - o o x x - o x x x -
テスト入力2
20 56 14 18 8 19 18 20 5 15 17 3 12 15 7 3 14 12 18 17 2 12 4 12 17 5 11 10 14 13 8 5 8 1 16 13 17 7 16 18 20 8 10 7 9 20 17 11 8 2 6 4 9 19 13 3 7 15 13 9 4 2 18 7 20 2 17 2 8 18 5 16 1 12 6 1 11 2 9 6 11 15 17 19 18 6 8 17 15 10 10 6 1 18 15 19 9 7 2 14 4 19 20 11 16 12 5 2 16 9 13 2 12 20
テスト出力2
- - - - - x - x - - - o - - - - - o - - - - - x x - - x - - x o x o - - x - - x - - - - - - x - - - - - x - - - x - - - - o - - - x - - - - - o - - - - - - o - - o - - - - - x - - - - - - o o x - - - o - - o - - - - x x - - - - - - - x - - - - o - - - - - x x - - - - o - x x - - o o - - o - - - - - - - - - - - o o o x - - - - - o o - - - - - x - - x - - o o - - - - - o o - - - x - - - x - - - - - - o - - - - - - - o - - - - o - x - - x x x - x - - - - - - - - - x o x - - - o - o o - - - - - o - - - - x - x - - - - - x - - - - - - - - - o o - - - - o - - - - - - x - x - - o x x - - - - - - o - - - - - x - - - o - - o o - - - - o - - - o o - o - o x - - o - - - - - - x o - x - - - - o o x - - - - - x - x o - - o - - - x - - - x x - - - - - x - x - - - - o - - - - - o x - o x - - - - - x - -
テスト入力3
データが大きすぎるため省略
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
int N, M;
cin >> N >> M;
vector<int> A(M), B(M);
for (int i = 0; i < M; i++) {
cin >> A.at(i) >> B.at(i);
}
// N×Nのchar型の2次元配列のすべての要素を'-'で初期化
vector<vector<char>> table(N, vector<char>(N, '-'));
for (int i = 0; i < M; i++) {
// 1〜N → 0〜N-1 に変換
A.at(i)--; B.at(i)--;
table.at(A.at(i)).at(B.at(i)) = 'o'; // AはBに勝った
table.at(B.at(i)).at(A.at(i)) = 'x'; // BはAに負けた
}
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
cout << table.at(i).at(j);
if (j == N - 1) {
cout << endl; // 行末なら改行
}
else {
cout << " "; // 行末でないなら空白を出力
}
}
}
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
小学校の先生であるあなたはA君に九九の表を埋める宿題を出しました。 次の日、A君は宿題をやってきましたが、いくつかのマスは間違っているようです。
A君の宿題を採点するプログラムを作成してください。
具体的には、以下の要件を満たすプログラムを作成してください。
- A君の回答の表(9×9の二次元配列)を入力として受け取る
- 誤った値が書き込まれたマスを正しい値に書き直す
- 正しい値が書き込まれたマスの個数を数える
- 誤った値が書き込まれたマスの個数を数える
※参照渡しの練習問題なので、「プログラムの雛形」を書き換える形でプログラムを作成してください。
プログラムの雛形
以下のプログラム中のコメントに従って書き換えるようにしてください。
#include <bits/stdc++.h>
using namespace std;
// 参照渡しを用いて、呼び出し側の変数の値を変更する
void saiten(/* 呼び出し側に対応するように引数を書く */) {
// 呼び出し側のAの各マスを正しい値に修正する
// Aのうち、正しい値の書かれたマスの個数を correct_count に入れる
// Aのうち、誤った値の書かれたマスの個数を wrong_count に入れる
// ここにプログラムを追記
}
// -------------------
// ここから先は変更しない
// -------------------
int main() {
// A君の回答を受け取る
vector<vector<int>> A(9, vector<int>(9));
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9; j++) {
cin >> A.at(i).at(j);
}
}
int correct_count = 0; // ここに正しい値のマスの個数を入れる
int wrong_count = 0; // ここに誤った値のマスの個数を入れる
// A, correct_count, wrong_countを参照渡し
saiten(A, correct_count, wrong_count);
// 正しく修正した表を出力
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9; j++) {
cout << A.at(i).at(j);
if (j < 8) cout << " ";
else cout << endl;
}
}
// 正しいマスの個数を出力
cout << correct_count << endl;
// 誤っているマスの個数を出力
cout << wrong_count << endl;
}
制約
- 0 \leq A_{i,j} \leq 100
入力
入力は次の形式で標準入力から与えられます。
A_{1, 1} A_{1, 2} A_{1, 3} A_{1, 4} A_{1, 5} A_{1, 6} A_{1, 7} A_{1, 8} A_{1, 9}
A_{2, 1} A_{2, 2} A_{2, 3} A_{2, 4} A_{2, 5} A_{2, 6} A_{2, 7} A_{2, 8} A_{2, 9}
A_{3, 1} A_{3, 2} A_{3, 3} A_{3, 4} A_{3, 5} A_{3, 6} A_{3, 7} A_{3, 8} A_{3, 9}
A_{4, 1} A_{4, 2} A_{4, 3} A_{4, 4} A_{4, 5} A_{4, 6} A_{4, 7} A_{4, 8} A_{4, 9}
A_{5, 1} A_{5, 2} A_{5, 3} A_{5, 4} A_{5, 5} A_{5, 6} A_{5, 7} A_{5, 8} A_{5, 9}
A_{6, 1} A_{6, 2} A_{6, 3} A_{6, 4} A_{6, 5} A_{6, 6} A_{6, 7} A_{6, 8} A_{6, 9}
A_{7, 1} A_{7, 2} A_{7, 3} A_{7, 4} A_{7, 5} A_{7, 6} A_{7, 7} A_{7, 8} A_{7, 9}
A_{8, 1} A_{8, 2} A_{8, 3} A_{8, 4} A_{8, 5} A_{8, 6} A_{8, 7} A_{8, 8} A_{8, 9}
A_{9, 1} A_{9, 2} A_{9, 3} A_{9, 4} A_{9, 5} A_{9, 6} A_{9, 7} A_{9, 8} A_{9, 9}
A_{i, j}はi \times jの答えとしてA君が書き込んだ値です。
出力
A'_{1, 1} A'_{1, 2} A'_{1, 3} A'_{1, 4} A'_{1, 5} A'_{1, 6} A'_{1, 7} A'_{1, 8} A'_{1, 9}
A'_{2, 1} A'_{2, 2} A'_{2, 3} A'_{2, 4} A'_{2, 5} A'_{2, 6} A'_{2, 7} A'_{2, 8} A'_{2, 9}
A'_{3, 1} A'_{3, 2} A'_{3, 3} A'_{3, 4} A'_{3, 5} A'_{3, 6} A'_{3, 7} A'_{3, 8} A'_{3, 9}
A'_{4, 1} A'_{4, 2} A'_{4, 3} A'_{4, 4} A'_{4, 5} A'_{4, 6} A'_{4, 7} A'_{4, 8} A'_{4, 9}
A'_{5, 1} A'_{5, 2} A'_{5, 3} A'_{5, 4} A'_{5, 5} A'_{5, 6} A'_{5, 7} A'_{5, 8} A'_{5, 9}
A'_{6, 1} A'_{6, 2} A'_{6, 3} A'_{6, 4} A'_{6, 5} A'_{6, 6} A'_{6, 7} A'_{6, 8} A'_{6, 9}
A'_{7, 1} A'_{7, 2} A'_{7, 3} A'_{7, 4} A'_{7, 5} A'_{7, 6} A'_{7, 7} A'_{7, 8} A'_{7, 9}
A'_{8, 1} A'_{8, 2} A'_{8, 3} A'_{8, 4} A'_{8, 5} A'_{8, 6} A'_{8, 7} A'_{8, 8} A'_{8, 9}
A'_{9, 1} A'_{9, 2} A'_{9, 3} A'_{9, 4} A'_{9, 5} A'_{9, 6} A'_{9, 7} A'_{9, 8} A'_{9, 9}
correct\_count
wrong\_count
A'は入力のAの各マスを正しい値に修正したものです。
correct\_countは正しい値が書き込まれていたマスの個数、wrong\_countは誤った値が書き込まれていたマスの個数です。
なお、A'の出力について、各行の末尾に空白を入れないことに注意してください。
プログラムの雛形の出力部分を変更しなければ問題ありません。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
1 2 3 4 5 6 7 8 9 2 4 100 8 10 12 14 16 18 3 6 9 12 15 18 21 24 27 4 8 12 16 20 24 28 32 36 5 10 15 20 25 30 35 40 45 6 12 18 24 30 36 42 48 54 7 14 21 28 35 42 49 56 63 8 16 24 32 40 48 56 64 72 9 18 27 36 45 54 63 72 81
出力例1
1 2 3 4 5 6 7 8 9 2 4 6 8 10 12 14 16 18 3 6 9 12 15 18 21 24 27 4 8 12 16 20 24 28 32 36 5 10 15 20 25 30 35 40 45 6 12 18 24 30 36 42 48 54 7 14 21 28 35 42 49 56 63 8 16 24 32 40 48 56 64 72 9 18 27 36 45 54 63 72 81 80 1
A君はA_{2, 3} = 100と書き込みましたが、2 \times 3 = 6なので正しくはA_{2,3} = 6です。
それ以外のマスは正しいので、correct\_count = 80, wrong\_count = 1となります。
入力例2
1 2 3 4 5 6 7 8 9 2 4 6 8 10 37 14 79 18 3 6 9 12 15 18 21 24 39 4 8 12 16 20 24 28 32 36 5 10 15 20 25 30 35 40 41 6 67 18 24 50 36 42 10 9 7 14 21 28 35 42 49 56 63 8 16 24 32 40 48 56 64 14 9 18 27 36 45 54 63 72 81
出力例2
1 2 3 4 5 6 7 8 9 2 4 6 8 10 12 14 16 18 3 6 9 12 15 18 21 24 27 4 8 12 16 20 24 28 32 36 5 10 15 20 25 30 35 40 45 6 12 18 24 30 36 42 48 54 7 14 21 28 35 42 49 56 63 8 16 24 32 40 48 56 64 72 9 18 27 36 45 54 63 72 81 72 9
ヒント
クリックでヒントを開く
関数の内部から呼び出した側の変数を変更するには、引数を参照にします。
関数の引数を参照にする例を次に示します。
#include <bits/stdc++.h>
using namespace std;
void f(int &i, string &s) {
i = 123;
s = "hello";
}
int main() {
int x;
string y;
f(x, y); // x = 123, y = "hello"となる
cout << x << endl; // "123"
cout << y << endl; // "hello"
}
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
1 2 3 4 5 6 7 8 9 2 4 6 8 10 12 14 16 18 3 6 9 12 15 18 21 24 27 4 8 12 16 20 24 28 32 36 5 10 15 20 25 30 35 40 45 6 12 18 24 30 36 42 48 54 7 14 21 28 35 42 49 56 63 8 16 24 32 40 48 56 64 72 9 18 27 36 45 54 63 72 81
テスト出力1
1 2 3 4 5 6 7 8 9 2 4 6 8 10 12 14 16 18 3 6 9 12 15 18 21 24 27 4 8 12 16 20 24 28 32 36 5 10 15 20 25 30 35 40 45 6 12 18 24 30 36 42 48 54 7 14 21 28 35 42 49 56 63 8 16 24 32 40 48 56 64 72 9 18 27 36 45 54 63 72 81 81 0
テスト入力2
1 2 3 4 5 6 7 8 9 2 4 29 8 10 12 14 16 18 3 24 9 12 15 18 21 96 27 4 8 12 16 20 24 28 32 36 5 10 15 20 25 30 35 40 45 6 12 18 24 30 36 42 48 54 7 14 21 28 35 42 49 56 63 83 16 24 32 40 48 12 15 72 9 18 27 36 45 54 63 72 81
テスト出力2
1 2 3 4 5 6 7 8 9 2 4 6 8 10 12 14 16 18 3 6 9 12 15 18 21 24 27 4 8 12 16 20 24 28 32 36 5 10 15 20 25 30 35 40 45 6 12 18 24 30 36 42 48 54 7 14 21 28 35 42 49 56 63 8 16 24 32 40 48 56 64 72 9 18 27 36 45 54 63 72 81 75 6
テスト入力3
1 31 3 4 5 6 7 8 9 2 4 27 8 10 62 14 16 18 83 6 1 27 33 18 91 24 27 4 8 38 16 20 38 31 32 36 5 10 15 35 25 30 35 56 45 6 60 49 67 11 36 6 48 54 7 14 21 28 35 63 49 16 63 8 10 24 90 40 48 70 40 20 34 91 27 36 45 54 63 52 81
テスト出力3
1 2 3 4 5 6 7 8 9 2 4 6 8 10 12 14 16 18 3 6 9 12 15 18 21 24 27 4 8 12 16 20 24 28 32 36 5 10 15 20 25 30 35 40 45 6 12 18 24 30 36 42 48 54 7 14 21 28 35 42 49 56 63 8 16 24 32 40 48 56 64 72 9 18 27 36 45 54 63 72 81 53 28
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
// 参照渡しを用いて、呼び出し側の変数の値を変更する
void saiten(vector<vector<int>> &A, int &correct_count, int &wrong_count) {
// 呼び出し側のAの各マスを正しい値に修正する
// Aのうち、正しい値の書かれたマスの個数を correct_count に入れる
// Aのうち、誤った値の書かれたマスの個数を wrong_count に入れる
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9; j++) {
if (A.at(i).at(j) != (i + 1) * (j + 1)) {
// 誤った値が書き込まれている場合
A.at(i).at(j) = (i + 1) * (j + 1); // 正しい値に修正
wrong_count++; // 誤っているマスの個数を +1
}
else {
// 正しい値が書き込まれている場合
correct_count++; // 正しいマスの個数を +1
}
}
}
}
// -------------------
// ここから先は変更しない
// -------------------
int main() {
// A君の回答を受け取る
vector<vector<int>> A(9, vector<int>(9));
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9; j++) {
cin >> A.at(i).at(j);
}
}
int correct_count = 0; // ここに正しい値のマスの個数を入れる
int wrong_count = 0; // ここに誤った値のマスの個数を入れる
// A, correct_count, wrong_countを参照渡し
saiten(A, correct_count, wrong_count);
// 正しく修正した表を出力
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9; j++) {
cout << A.at(i).at(j);
if (j < 8) cout << " ";
else cout << endl;
}
}
// 正しいマスの個数を出力
cout << correct_count << endl;
// 誤っているマスの個数を出力
cout << wrong_count << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
あなたはA社を経営する社長です。 A社はN個の組織からなり、それぞれに0番からN - 1番の番号が付いています。 0番の番号が付いた組織はトップの組織です。
組織間には親子関係があり、0番以外のN - 1個の組織には必ず1つの親組織があります。 子組織は複数になることがあります。 また、それぞれの組織は直接的または間接的にトップの組織と関係があるものとします。
あなたは全ての組織に報告書を提出するように求めました。 混雑を避けるために、「各組織は子組織の報告書がそろったら、自身の報告書を加えて親組織に渡す」ことを繰り返します。 子組織が無いような組織はすぐに親組織に報告書を渡します。 トップの組織は子組織の報告書がそろったら、自身の報告書を加えて社長に提出します。
それぞれの組織が1枚の報告書を提出します。
各組織について、「その組織が親組織に提出することになる報告書の枚数」を出力するプログラムを作成してください。 ただしトップの組織については「社長に提出する報告書の枚数」を出力してください。
サンプルプログラム
#include <bits/stdc++.h>
using namespace std;
// x番の組織が親組織に提出する枚数を返す
// childrenは組織の関係を表す2次元配列(参照渡し)
int count_report_num(vector<vector<int>> &children, int x) {
// (ここに追記して再帰関数を実装する)
}
// これ以降の行は変更しなくてよい
int main() {
int N;
cin >> N;
vector<int> p(N); // 各組織の親組織を示す配列
p.at(0) = -1; // 0番組織の親組織は存在しないので-1を入れておく
for (int i = 1; i < N; i++) {
cin >> p.at(i);
}
// 組織の関係から2次元配列を作る
vector<vector<int>> children(N); // ある組織の子組織の番号一覧
for (int i = 1; i < N; i++) {
int parent = p.at(i); // i番の親組織の番号
children.at(parent).push_back(i); // parentの子組織一覧にi番を追加
}
// 各組織について、答えを出力
for (int i = 0; i < N; i++) {
cout << count_report_num(children, i) << endl;
}
}
関数count_report_numの引数childrenは二次元配列で、
x番の組織の子組織の番号一覧の配列はchildren.at(x)とすることで得ることができます。
制約
- 1 \leq N \leq 50
- 0 \leq p_i < i (1 \leq i \leq N - 1)
入力
入力は次の形式で標準入力から与えられます。
N
p_1 p_2 p_3 \ldots p_{N - 1}
p_iはi番の組織の親組織がp_i番の組織であることを示します。
0番の組織はトップの組織であり、親組織が存在しないことに注意してください。
出力
ans_0
ans_1
ans_2
\vdots
ans_{N - 1}
0番の組織から順に、i番の組織についての答えans_iを1行毎に出力してください。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
6 0 0 1 1 4
出力例1
6 4 1 1 2 1
組織の関係は次の図のようになります。(子組織から親組織の向きに矢印が向いています。)
番号の隣に書いてある青い数字が各組織についての答えです。
入力例2
8 0 0 1 2 0 3 6
出力例2
8 4 2 3 1 1 2 1
組織の関係は次の図のようになります。(子組織から親組織の向きに矢印が向いています。)
番号の隣に書いてある青い数字が各組織についての答えです。
ヒント
クリックでヒントを開く
- 「組織xが親組織へ提出する枚数」= 組織xの全ての子組織cについて「cから受け取った報告書の枚数」の合計 + 1
- 「cから受け取った報告書の枚数」=「cが親組織に提出する枚数」
- 子組織が無いような組織について、その組織が親組織に提出する報告書の枚数は1枚
次のようにすることでx番の組織の子組織についての処理が行えます。
for (int c : children.at(x)) {
// (cについての処理)
}
この問題は2.05.再帰関数の例題に非常に近い問題となっているので、そちらも参考にしてください。
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
20 0 1 1 3 0 0 1 3 5 9 6 8 8 8 0 4 7 12 13
テスト出力1
20 13 1 9 2 3 2 2 6 2 1 1 2 2 1 1 1 1 1 1
テスト入力2
30 0 1 0 1 0 3 1 2 8 6 1 3 0 4 2 3 0 14 16 13 5 2 16 14 19 2 7 2 26
テスト出力2
30 16 8 8 4 2 2 2 2 1 1 1 1 2 3 1 4 1 1 2 1 1 1 1 1 1 2 1 1 1
テスト入力3
50 0 0 0 2 3 1 6 3 4 0 9 5 2 12 7 13 14 1 3 14 2 10 17 7 8 1 15 11 19 29 26 20 7 18 10 24 19 2 19 29 29 9 21 42 0 19 24 44 26
テスト出力3
50 14 13 18 7 7 8 7 2 6 3 2 6 2 5 2 1 2 2 8 2 2 1 1 3 1 3 1 1 4 1 1 1 1 1 1 1 1 1 1 1 1 3 1 2 1 1 1 1 1
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
// x番の組織が親組織に提出する枚数を返す
// childrenは組織の関係を表す2次元配列(参照渡し)
int count_report_num(vector<vector<int>> &children, int x) {
// ベースケース
if (children.at(x).size() == 0) {
// 子組織から受け取ることは無いので1枚であることが確定している
return 1;
}
// 再帰ステップ
int sum = 0;
for (int c : children.at(x)) {
sum += count_report_num(children, c);
}
sum += 1; // x番の組織の報告書の枚数(1枚)を足す
return sum;
}
// これ以降の行は変更しなくてよい
int main() {
int N;
cin >> N;
vector<int> p(N); // 各組織の親組織を示す配列
p.at(0) = -1; // 0番組織の親組織は存在しないので-1を入れておく
for (int i = 1; i < N; i++) {
cin >> p.at(i);
}
// 組織の関係から2次元配列を作る
vector<vector<int>> children(N); // ある組織の子組織の番号一覧
for (int i = 1; i < N; i++) {
int parent = p.at(i); // i番の親組織の番号
children.at(parent).push_back(i); // parentの子組織一覧にi番を追加
}
// 各組織について、答えを出力
for (int i = 0; i < N; i++) {
cout << count_report_num(children, i) << endl;
}
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
次のプログラムではf0〜f5の6つの関数が定義されており、main関数から呼び出されています。 それぞれの関数の計算量を見積もって、最も計算時間のかかる関数を呼び出している行をコメントアウトしてください。
制限時間は2秒です。AtCoderのジャッジでは1秒あたり10^8回程度の計算が可能です。不正解だった場合となります。
制約を読み、各関数の実行時間を見積もりましょう。
プログラム
#include <bits/stdc++.h>
using namespace std;
int f0(int N) {
return 1;
}
int f1(int N, int M) {
int s = 0;
for (int i = 0; i < N; i++) {
s++;
}
for (int i = 0; i < M; i++) {
s++;
}
return s;
}
int f2(int N) {
int s = 0;
for (int i = 0; i < N; i++) {
int t = N;
int cnt = 0;
while (t > 0) {
cnt++;
t /= 2;
}
s += cnt;
}
return s;
}
int f3(int N) {
int s = 0;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
s++;
}
}
return s;
}
int f4(int N) {
int s = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
s += i + j;
}
}
return s;
}
int f5(int N, int M) {
int s = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
s += i + j;
}
}
return s;
}
int main() {
int N, M;
cin >> N >> M;
int a0 = -1, a1 = -1, a2 = -1, a3 = -1, a4 = -1, a5 = -1;
// 計算量が最も大きいもの1つだけコメントアウトする
a0 = f0(N);
a1 = f1(N, M);
a2 = f2(N);
a3 = f3(N);
a4 = f4(N);
a5 = f5(N, M);
cout << "f0: " << a0 << endl;
cout << "f1: " << a1 << endl;
cout << "f2: " << a2 << endl;
cout << "f3: " << a3 << endl;
cout << "f4: " << a4 << endl;
cout << "f5: " << a5 << endl;
}
制約
- 0 \leq N \leq 10^6
- 0 \leq M \leq 10^2
回答例
答え方の例です。
この例ではf0の呼び出しをコメントアウトしていますが、f0はO(1)なのでこの回答は不正解となります。
#include <bits/stdc++.h>
using namespace std;
int f0(int N) {
return 1;
}
int f1(int N, int M) {
int s = 0;
for (int i = 0; i < N; i++) {
s++;
}
for (int i = 0; i < M; i++) {
s++;
}
return s;
}
int f2(int N) {
int s = 0;
for (int i = 0; i < N; i++) {
int t = N;
int cnt = 0;
while (t > 0) {
cnt++;
t /= 2;
}
s += cnt;
}
return s;
}
int f3(int N) {
int s = 0;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
s++;
}
}
return s;
}
int f4(int N) {
int s = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
s += i + j;
}
}
return s;
}
int f5(int N, int M) {
int s = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
s += i + j;
}
}
return s;
}
int main() {
int N, M;
cin >> N >> M;
int a0 = -1, a1 = -1, a2 = -1, a3 = -1, a4 = -1, a5 = -1;
// 計算量が最も大きいもの1つだけコメントアウトする
// a0 = f0(N);
a1 = f1(N, M);
a2 = f2(N);
a3 = f3(N);
a4 = f4(N);
a5 = f5(N, M);
cout << "f0: " << a0 << endl;
cout << "f1: " << a1 << endl;
cout << "f2: " << a2 << endl;
cout << "f3: " << a3 << endl;
cout << "f4: " << a4 << endl;
cout << "f5: " << a5 << endl;
}
ヒント
クリックでヒントを開く
それぞれの関数の計算量を示します。
| 計算量 | |
|---|---|
f0 |
O(1) |
f1 |
O(N+M) |
f2 |
O(N \log N) |
f3 |
O(1) |
f4 |
O(N^2) |
f5 |
O(NM) |
NとMの大きさを考えて実行時間が最も長いものを選びましょう。
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
1000000 100
テスト出力1
f0: 1 f1: 1000100 f2: 20000000 f3: 9 f4: -1 f5: -1404227328
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int f0(int N) {
return 1;
}
int f1(int N, int M) {
int s = 0;
for (int i = 0; i < N; i++) {
s++;
}
for (int i = 0; i < M; i++) {
s++;
}
return s;
}
int f2(int N) {
int s = 0;
for (int i = 0; i < N; i++) {
int t = N;
int cnt = 0;
while (t > 0) {
cnt++;
t /= 2;
}
s += cnt;
}
return s;
}
int f3(int N) {
int s = 0;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
s++;
}
}
return s;
}
int f4(int N) {
int s = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
s += i + j;
}
}
return s;
}
int f5(int N, int M) {
int s = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
s += i + j;
}
}
return s;
}
int main() {
int N, M;
cin >> N >> M;
int a0 = -1, a1 = -1, a2 = -1, a3 = -1, a4 = -1, a5 = -1;
// 計算量が最も大きいもの1つだけコメントアウトする
a0 = f0(N);
a1 = f1(N, M);
a2 = f2(N);
a3 = f3(N);
// a4 = f4(N);
a5 = f5(N, M);
cout << "f0: " << a0 << endl;
cout << "f1: " << a1 << endl;
cout << "f2: " << a2 << endl;
cout << "f3: " << a3 << endl;
cout << "f4: " << a4 << endl;
cout << "f5: " << a5 << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
整数a_i, b_iのペア(a_i, b_i)がN個与えられます(1 \leq i \leq N)。b_iが小さい順にペアを並べ替えてください。
制約
- 1 \leq N \leq 100
- 1 \leq a_i, b_i \leq 10^9
- b_iは全て異なる
- 入力はすべて整数
入力
入力は次の形式で標準入力から与えられます。
N a_1 b_1 a_2 b_2 ︙ ︙ a_N b_N
出力
ペアを並べ替えた順に1行毎に出力してください。 各ペアはa_i、b_iをスペース区切りで出力してください。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
3 5 2 2 7 4 1
出力例1
4 1 5 2 2 7
(5, 2), (2, 7), (4, 1)という3つのペアがあり、b_iの値が小さい順に並べ替えると、(4, 1), (5, 2), (2, 7)となります。
入力例2
5 1 2 3 4 5 6 7 8 9 10
出力例2
1 2 3 4 5 6 7 8 9 10
ヒント
クリックでヒントを開く
pair<int, int>で2つの整数のペアを表すことができます。- pairを比較すると、1番目の値で比較され、等しい場合は2番目の値で比較されます。
- 配列を要素が小さい順に並べ替えるには
sort(a.begin(), a.end());とします。
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
100 93 4 54 22 36 41 55 65 48 27 12 1 37 67 68 39 80 10 56 8 87 90 16 47 76 88 38 13 46 87 40 48 84 68 94 33 49 29 3 11 98 6 18 21 85 77 23 45 73 58 78 42 31 12 21 60 66 54 47 14 9 7 28 53 41 82 91 83 61 74 92 91 96 95 90 81 17 66 22 89 72 43 39 56 57 80 70 100 58 69 74 34 51 64 25 20 67 25 97 62 63 55 19 26 15 2 82 5 20 92 34 31 43 73 79 28 1 57 99 32 13 38 88 36 24 51 59 19 64 23 89 79 65 3 81 84 27 78 44 52 53 59 6 61 50 71 14 40 2 49 83 75 77 96 30 85 95 15 71 86 35 50 52 44 42 18 75 70 29 94 8 46 60 76 5 98 69 93 11 99 10 72 32 35 7 9 86 24 26 16 62 17 100 97 4 30 45 63 33 37
テスト出力1
12 1 15 2 65 3 93 4 82 5 98 6 9 7 56 8 7 9 80 10 3 11 31 12 38 13 47 14 95 15 26 16 62 17 42 18 59 19 25 20 18 21 54 22 64 23 86 24 67 25 19 26 48 27 79 28 49 29 4 30 34 31 99 32 94 33 74 34 32 35 88 36 33 37 13 38 68 39 14 40 36 41 78 42 72 43 52 44 23 45 8 46 16 47 40 48 2 49 35 50 24 51 44 52 28 53 66 54 63 55 39 56 1 57 73 58 53 59 21 60 6 61 97 62 45 63 51 64 55 65 17 66 37 67 84 68 58 69 75 70 50 71 10 72 43 73 61 74 83 75 60 76 85 77 27 78 89 79 57 80 90 81 41 82 91 83 81 84 30 85 71 86 46 87 76 88 22 89 87 90 92 91 20 92 69 93 29 94 96 95 77 96 100 97 5 98 11 99 70 100
テスト入力2
100 516111320 607515272 222610184 248356480 61883986 245487676 206662228 533989888 69129331 777444148 240199961 432234636 426231114 336813804 321022003 57262799 987178129 850725892 947102866 972781313 925126447 138391343 616274448 355808755 714725587 135574527 242294936 747031846 712001433 210877082 181182763 770306728 93942008 774494957 724829041 835108740 344285556 521741371 833231327 603241645 607948534 214246948 918457894 886239485 235309772 705607918 283022479 376033551 274016160 224876948 119317651 487762742 86470334 681700654 230829137 667556773 786823599 522783812 552745413 742568795 187877449 678955882 92450487 797581025 57997903 741784382 15453784 899476414 228873791 489714188 923423708 985237362 178220373 117577774 523186879 681227121 841286768 74441749 229826134 478391450 62710049 210080103 594857199 60772664 728567957 220290043 277000690 799270840 828251052 813032112 322627026 328640184 630777206 93015078 143835290 305081041 78963996 850741582 185710453 415807807 224069168 194535462 765198511 925540935 67423218 161316172 139362266 380170512 23387958 140419953 727968221 212850176 929329071 680065291 80699708 674702419 824108967 489282458 563350357 865651077 580350921 922504314 124656307 134201888 513360123 776145804 161691774 176062866 681917529 535777959 798798922 678858034 778992896 889103485 983935974 111383938 589373003 592835023 980332103 729109938 586355723 562793775 424189799 402925777 326355130 246164484 106061524 868992059 175266265 361785497 247489202 829929333 872172162 585678993 725362470 819053997 856167633 586840059 474710785 856608830 638675377 822416002 176847119 78399228 238118171 211620634 302761599 410660344 340827370 584914156 840925927 471614751 278196506 194743308 921788254 661004915 418241172 372234551 423524176 744703832 79167871 125578990 808014283 603127562 319194141 766981002 81534592 626533314 359147052 464468288 279768551 598170192 659558263 966172428 339372240 602852466 583878922 371264416 674367424 759010423
テスト出力2
321022003 57262799 594857199 60772664 841286768 74441749 176847119 78399228 630777206 93015078 983935974 111383938 178220373 117577774 79167871 125578990 124656307 134201888 714725587 135574527 925126447 138391343 23387958 140419953 67423218 161316172 161691774 176062866 224069168 194535462 278196506 194743308 62710049 210080103 712001433 210877082 238118171 211620634 727968221 212850176 607948534 214246948 728567957 220290043 274016160 224876948 61883986 245487676 326355130 246164484 222610184 248356480 143835290 305081041 322627026 328640184 426231114 336813804 616274448 355808755 175266265 361785497 583878922 371264416 418241172 372234551 283022479 376033551 139362266 380170512 424189799 402925777 302761599 410660344 185710453 415807807 240199961 432234636 359147052 464468288 840925927 471614751 229826134 478391450 119317651 487762742 824108967 489282458 228873791 489714188 344285556 521741371 786823599 522783812 206662228 533989888 681917529 535777959 586355723 562793775 340827370 584914156 872172162 585678993 856167633 586840059 589373003 592835023 279768551 598170192 339372240 602852466 808014283 603127562 833231327 603241645 516111320 607515272 81534592 626533314 921788254 661004915 230829137 667556773 80699708 674702419 798798922 678858034 187877449 678955882 929329071 680065291 523186879 681227121 86470334 681700654 235309772 705607918 980332103 729109938 57997903 741784382 552745413 742568795 423524176 744703832 242294936 747031846 674367424 759010423 319194141 766981002 181182763 770306728 93942008 774494957 513360123 776145804 69129331 777444148 92450487 797581025 277000690 799270840 828251052 813032112 725362470 819053997 638675377 822416002 247489202 829929333 724829041 835108740 987178129 850725892 78963996 850741582 474710785 856608830 563350357 865651077 106061524 868992059 918457894 886239485 778992896 889103485 15453784 899476414 580350921 922504314 765198511 925540935 659558263 966172428 947102866 972781313 923423708 985237362
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
pair<int, int>の配列を用意して、(b_i, a_i)となるように格納すれば、sortするだけでbが小さい順に並べ替えることができます。
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
vector<pair<int, int>> p(N);
for (int i = 0; i < N; i++) {
int a, b;
cin >> a >> b;
p.at(i) = make_pair(b, a); // b, a の順でペアにする
}
sort(p.begin(), p.end());
for (int i = 0; i < N; i++) {
int b, a;
tie(b, a) = p.at(i); // b, a の順であることに注意
cout << a << " " << b << endl;
}
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
N要素の配列A_1, A_2, \ldots, A_Nが与えられます。 この配列の中の値のうち、出現回数が最も多い値とその出現回数を求めてください。
ただし、出現回数が最大になる値は複数存在しないものとします。
制約が大きいため計算量に注意してプログラムを作成してください。
制約
- 0 \leq N \leq 10^5
- 0 \leq A_i \leq 10^9 (1 \leq i \leq N)
- 出現回数が最大になるような値は複数存在しない。
入力
入力は次の形式で標準入力から与えられます。
N A_1 A_2 \ldots A_N
出力
値 出現回数
出現回数が最も多い値と、その出現回数をスペース区切りで出力してください。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
特に、ジャッジのテストケースには大きい入力が含まれているのでTLEにならないように注意してください。
入力例1
5 1 4 4 2 3
出力例1
4 2
入力の配列に含まれる各値の出現回数は以下のようになっています。
- 1の出現回数は1回
- 2の出現回数は1回
- 3の出現回数は1回
- 4の出現回数は2回
出現回数2回が最大でその値は4なので、"4 2"と出力します。
入力例2
6 3 2 3 1 3 2
出力例2
3 3
入力例3
1 1000000000
出力例3
1000000000 1
ヒント
クリックでヒントを開く
- 「値→出現回数」の関係を
mapで管理しましょう。 mapへの値の追加、アクセスの計算量はO(\log N)です。- この問題ではN^2は10^{10}なので、O(N^2)の計算量ではTLEとなります。
- N \log Nは約1.6*10^6なので、O(N \log N)の計算量であれば間に合います。
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
データが大きすぎるため省略
テスト入力2
データが大きすぎるため省略
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
int main() {
int N;
cin >> N;
vector<int> A(N);
for (int i = 0; i < N; i++) {
cin >> A.at(i);
}
map<int, int> cnt;
for (int x : A) {
if (cnt.count(x)) {
// 既に含まれているならインクリメント
cnt.at(x)++;
} else {
// 含まれていないなら、1を追加
cnt[x] = 1;
}
}
int max_cnt = 0; // 出現回数の最大値を保持
int ans = -1; // 出現回数が最大になる値を保持
for (int x : A) {
// 今見ているxの出現回数が、その時点の最大よりも大きければ更新
if (max_cnt < cnt.at(x)) {
max_cnt = cnt.at(x);
ans = x;
}
}
cout << ans << " " << max_cnt << endl;
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
構造体の練習として、24時間表記の時計を表す構造体を実装してみましょう。
以下のプログラムの雛形のコメントに従って構造体を実装してください。
プログラムの雛形
#include <bits/stdc++.h>
using namespace std;
// 以下に、24時間表記の時計構造体 Clock を定義する
// Clock構造体のメンバ変数を書く
// int hour 時間を表す (0~23の値をとる)
// int minute 分を表す (0~59の値をとる)
// int second 秒を表す (0~59の値をとる)
// メンバ関数 set の定義を書く
// 関数名: set
// 引数: int h, int m, int s (それぞれ時、分、秒を表す)
// 返り値: なし
// 関数の説明:
// 時・分・秒を表す3つの引数を受け取り、
// それぞれ、メンバ変数 hour, minute, second に代入する
// メンバ関数 to_str の定義を書く
// 関数名: to_str
// 引数: なし
// 返り値: string型
// 関数の仕様:
// メンバ変数が表す時刻の文字列を返す
// 時刻の文字列は次のフォーマット
// "HH:MM:SS"
// HH、MM、SSはそれぞれ時間、分、秒を2桁で表した文字列
// メンバ関数 shift の定義を書く
// 関数名: shift
// 引数: int diff_second
// 返り値: なし
// 関数の仕様:
// diff_second 秒だけメンバ変数が表す時刻を変更する(ただし、日付やうるう秒は考えない)
// diff_second の値が負の場合、時刻を戻す
// diff_second の値が正の場合、時刻を進める
// diff_second の値は -86400 ~ 86400 の範囲を取とりうる
// -------------------
// ここから先は変更しない
// -------------------
int main() {
// 入力を受け取る
int hour, minute, second;
cin >> hour >> minute >> second;
int diff_second;
cin >> diff_second;
// Clock構造体のオブジェクトを宣言
Clock clock;
// set関数を呼び出して時刻を設定する
clock.set(hour, minute, second);
// 時刻を出力
cout << clock.to_str() << endl;
// 時計を進める(戻す)
clock.shift(diff_second);
// 変更後の時刻を出力
cout << clock.to_str() << endl;
}
制約
- 0 \leq \mathrm{hour} \leq 23
- 0 \leq \mathrm{minute} \leq 59
- 0 \leq \mathrm{second} \leq 59
- -86400 \leq \mathrm{diff\_second} \leq 86400
入力
入力は次の形式で標準入力から与えられます。
\mathrm{hour} \mathrm{minute} \mathrm{second}
\mathrm{diff\_second}
出力
HH1:MM1:SS1 HH2:MM2:SS2
HH1:MM1:SS1は入力で与えられた時刻を表す文字列です。HH2:MM2:SS2は\mathrm{diff\_second}秒だけ時刻を変更した後の時刻を表す文字列です。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
0 0 0 90
出力例1
00:00:00 00:01:30
「0時0分0秒」の90秒後(1分30秒後)なので、変更後の時刻は「0時1分30秒」です。 値が1桁の場合でも、出力は2桁に揃える必要がある点に注意してください。
入力例2
0 0 0 -5
出力例2
00:00:00 23:59:55
「0時0分0秒」の5秒前なので、変更後の時刻は「23時59分55秒」です。
入力例3
23 59 30 30
出力例3
23:59:30 00:00:00
入力例4
6 57 9 -4195
出力例4
06:57:09 05:47:14
ヒント
クリックでヒントを開く
- 構造体は次のように定義します。
struct 構造体名 {
型1 メンバ変数名1
型2 メンバ変数名2
型3 メンバ変数名3
...(必要な分だけ書く)
返り値の型 メンバ関数名(型1 引数1, 型2 引数2, ...) {
// メンバ関数の内容
}
...(必要な分だけ書く)
}; // ← セミコロンが必要
- 時刻の処理は、繰り上げや繰り下げを考慮する必要があるので、注意して実装しましょう。
- 秒→分→時の順で処理するとよいでしょう。
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
0 0 0 0
テスト出力1
00:00:00 00:00:00
テスト入力2
0 0 0 -86400
テスト出力2
00:00:00 00:00:00
テスト入力3
10 25 44 14240
テスト出力3
10:25:44 14:23:04
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
// 以下に、24時間表記の時計構造体 Clock を定義する
struct Clock {
// メンバ変数の宣言
int hour; // 時間を表す (0~23の値をとる)
int minute; // 分を表す (0~59の値をとる)
int second; // 秒を表す (0~59の値をとる)
// メンバ関数 set の定義
void set(int h, int m, int s) {
hour = h;
minute = m;
second = s;
}
// メンバ関数 to_str の定義
string to_str() {
string ret;
// 必要ではないが、書いておくと誤りがある場合に気づきやすくなる
if (!(0 <= hour && hour <= 23 &&
0 <= minute && minute <= 59 &&
0 <= second && second <= 59)) {
return "error";
}
if (hour < 10) ret += "0";
ret += to_string(hour);
ret += ":";
if (minute < 10) ret += "0";
ret += to_string(minute);
ret += ":";
if (second < 10) ret += "0";
ret += to_string(second);
return ret;
}
// メンバ関数 shift の定義
void shift(int diff_second) {
int diff_hour = diff_second / 3600;
diff_second %= 3600;
int diff_minute = diff_second / 60;
diff_second %= 60;
second += diff_second;
if (second >= 60) {
// 分へ繰り上げ
minute += 1;
second -= 60;
} else if (second < 0) {
// 分から繰り下げ
minute -= 1;
second += 60;
}
minute += diff_minute;
if (minute >= 60) {
// 時へ繰り上げ
hour += 1;
minute -= 60;
} else if (minute < 0) {
// 時から繰り下げ
hour -= 1;
minute += 60;
}
hour += diff_hour;
if (hour >= 24) {
hour -= 24;
} else if (hour < 0) {
hour += 24;
}
}
};
// -------------------
// ここから先は変更しない
// -------------------
int main() {
// 入力を受け取る
int hour, minute, second;
cin >> hour >> minute >> second;
int diff_second;
cin >> diff_second;
// Clock構造体のオブジェクトを宣言
Clock clock;
// set関数を呼び出して時刻を設定する
clock.set(hour, minute, second);
// 時刻を出力
cout << clock.to_str() << endl;
// 時計を進める(戻す)
clock.shift(diff_second);
// 変更後の時刻を出力
cout << clock.to_str() << endl;
}
shift関数は次のように書いてもよいでしょう。
void shift(int diff_second) {
while (diff_second > 0) {
// diff_secondが正なら1秒進める
second += 1;
diff_second -= 1;
if (second == 60) {
second = 0;
minute += 1;
}
if (minute == 60) {
minute = 0;
hour += 1;
}
if (hour == 24) {
hour = 0;
}
}
while (diff_second < 0) {
// diff_secondが負なら1秒戻す
second -= 1;
diff_second += 1;
if (second == -1) {
second = 59;
minute -= 1;
}
if (minute == -1) {
minute = 59;
hour -= 1;
}
if (hour == -1) {
hour = 23;
}
}
}
この問題では制約が小さいので、このように直接計算しても十分高速に答えが求まります。 ときには「効率的だが実装が煩雑になってしまうアルゴリズム」よりも、「もっと効率的な方法があることは分かっているが、実装がシンプルなアルゴリズム」を選択した方がよいこともあります。
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
0から49までの整数からなる集合A, Bがあります。
プログラムの雛形をもとに、集合A, Bに対して操作を行う関数を実装してください。
実装する操作は以下の通りです。
| 操作 | 説明 | 例 |
|---|---|---|
intersection |
AとBに共通して含まれる要素からなる集合を返す。 | A: {1, 2, 3}, B:{2, 3, 4} 結果:{2, 3} |
union_set |
AとBのうち少なくとも一方に含まれる要素からなる集合を返す。 | A: {1, 2, 3}, B:{2, 3, 4} 結果:{1, 2, 3, 4} |
symmetric_diff |
AとBのうちどちらか一方にだけ含まれる要素からなる集合を返す。 | A: {1, 2, 3}, B:{2, 3, 4} 結果:{1, 4} |
subtract x |
集合Aから値xを削除する。xは存在することが保証される。 | A: {1, 2, 3}, x: 2 結果:{1, 3} |
increment |
集合Aに含まれる要素すべてに1を加える。 ただし、操作前の集合に含まれる49は操作後は0になるものとする。 |
A: {1, 2, 49} 結果:{2, 3, 0} |
decrement |
集合Aに含まれる要素すべてから1を引く。 ただし、操作前の集合に含まれる0は操作後は49になるものとする。 |
A: {0, 1, 2} 結果:{49, 0, 1} |
プログラムの雛形
#include <bits/stdc++.h>
using namespace std;
// 各操作を行う関数を実装する
// AとBに共通して含まれる要素からなる集合を返す
bitset<50> intersection(bitset<50> A, bitset<50> B) {
}
// AとBのうち少なくとも一方に含まれる要素からなる集合を返す
bitset<50> union_set(bitset<50> A, bitset<50> B) {
}
// AとBのうちどちらか一方にだけ含まれる要素からなる集合を返す
bitset<50> symmetric_diff(bitset<50> A, bitset<50> B) {
}
// Aから値xを除く
bitset<50> subtract(bitset<50> A, int x) {
}
// Aに含まれる要素に1を加える(ただし、要素49が含まれる場合は0になるものとする)
bitset<50> increment(bitset<50> A) {
}
// Aに含まれる要素から1を引く(ただし、要素0が含まれる場合は49になるものとする)
bitset<50> decrement(bitset<50> A) {
}
// Sに値xを加える
bitset<50> add(bitset<50> S, int x) {
S.set(x, 1); // xビット目を1にする
return S;
}
// 集合Sの内容を昇順で出力する(スペース区切りで各要素の値を出力する)
void print_set(bitset<50> S) {
vector<int> cont;
for (int i = 0; i < 50; i++) {
if (S.test(i)) {
cont.push_back(i);
}
}
for (int i = 0; i < cont.size(); i++) {
if (i > 0) cout << " ";
cout << cont.at(i);
}
cout << endl;
}
// これより下は書き換えない
int main() {
bitset<50> A, B;
int N;
cin >> N;
for (int i = 0; i < N; i++) {
int x;
cin >> x;
A = add(A, x);
}
int M;
cin >> M;
for (int i = 0; i < M; i++) {
int x;
cin >> x;
B = add(B, x);
}
// 操作
string com;
cin >> com;
if (com == "intersection") {
print_set(intersection(A, B));
} else if (com == "union_set") {
print_set(union_set(A, B));
} else if (com == "symmetric_diff") {
print_set(symmetric_diff(A, B));
} else if (com == "subtract") {
int x;
cin >> x;
print_set(subtract(A, x));
} else if (com == "increment") {
print_set(increment(A));
} else if (com == "decrement") {
print_set(decrement(A));
}
}
制約
- Aの要素数はNで、要素はA_1, A_2, \cdots, A_Nです。
-
Bの要素数はMで、要素はB_1, B_2, \cdots, B_Mです。
-
1 \leq N, M \leq 50
- 0 \leq A_i \leq 49 (1 \leq i \leq N)
- 0 \leq B_i \leq 49 (1 \leq i \leq M)
- \mathrm{command}は以下のうちのいずれか
intersectionunion_setsymmetric_diffsubtract x- 0 \leq x \leq 49
- 集合Aにxが存在することが保証される
incrementdecrement
入力
入力は次の形式で標準入力から与えられます。
N
A_1 A_2 \cdots A_N
M
B_1 B_2 \cdots B_M
\mathrm{command}
出力
操作の結果の集合について、含まれる要素を昇順、空白区切りで1行に出力してください。 末尾に空白を含めないことに注意してください。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
3 0 1 2 3 1 2 3 intersection
出力例1
1 2
集合Aには{0, 1, 2}が含まれ、集合Bには{1, 2, 3}が含まれるので、これらに共通して含まれる要素は{1, 2}となります。
入力例2
3 0 1 2 3 1 2 3 union_set
出力例2
0 1 2 3
入力例3
3 0 1 2 3 1 2 3 symmetric_diff
出力例3
0 3
入力例4
3 0 1 2 3 1 2 3 subtract 2
出力例4
0 1
入力例5
3 0 1 49 3 1 2 3 increment
出力例5
0 1 2
入力例6
3 0 1 49 3 1 2 3 decrement
出力例6
0 48 49
ヒント
クリックでヒントを開く
intersectionはビット毎のAND演算を用いて実装できます。union_setはビット毎のOR演算を用いて実装できます。-
symmetric_diffはビット毎のXOR演算を用いて実装できます。 -
subtract xはSを表すビット列のxビット目を0にすればよいです。 -
increment,decrementは全ての要素が1ずつ増える(減る)ので論理シフト演算が利用できます。
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
3 0 1 2 3 10 11 12 intersection
テスト出力1
テスト入力2
50 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 3 1 2 3 increment
テスト出力2
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49
テスト入力3
50 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 3 1 2 3 decrement
テスト出力3
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
// 各操作を行う関数を実装する
// AとBに共通して含まれる要素からなる集合を返す
bitset<50> intersection(bitset<50> A, bitset<50> B) {
return A & B;
}
// AとBのうち少なくとも一方に含まれる要素からなる集合を返す
bitset<50> union_set(bitset<50> A, bitset<50> B) {
return A | B;
}
// AとBのうちどちらか一方にだけ含まれる要素からなる集合を返す
bitset<50> symmetric_diff(bitset<50> A, bitset<50> B) {
return A ^ B;
}
// Aから値xを除く
bitset<50> subtract(bitset<50> A, int x) {
A.set(x, 0);
return A;
}
// Aに含まれる要素に1を加える(ただし、要素49が含まれる場合は0になるものとする)
bitset<50> increment(bitset<50> A) {
bitset<50> ret = A << 1; // 左シフトでまとめて+1する
if (A.test(49)) {
ret.set(0, 1);
}
return ret;
}
// Aに含まれる要素から1を引く(ただし、要素0が含まれる場合は49になるものとする)
bitset<50> decrement(bitset<50> A) {
bitset<50> ret = A >> 1; // 右シフトでまとめて-1する
if (A.test(0)) {
ret.set(49, 1);
}
return ret;
}
// Sに値xを加える
bitset<50> add(bitset<50> S, int x) {
S.set(x, 1); // xビット目を1にする
return S;
}
// 集合Sの内容を昇順で出力する(スペース区切りで各要素の値を出力する)
void print_set(bitset<50> S) {
vector<int> cont;
for (int i = 0; i < 50; i++) {
if (S.test(i)) {
cont.push_back(i);
}
}
for (int i = 0; i < cont.size(); i++) {
if (i > 0) cout << " ";
cout << cont.at(i);
}
cout << endl;
}
// これより下は書き換えない
int main() {
bitset<50> A, B;
int N;
cin >> N;
for (int i = 0; i < N; i++) {
int x;
cin >> x;
A = add(A, x);
}
int M;
cin >> M;
for (int i = 0; i < M; i++) {
int x;
cin >> x;
B = add(B, x);
}
// 操作
string com;
cin >> com;
if (com == "intersection") {
print_set(intersection(A, B));
} else if (com == "union_set") {
print_set(union_set(A, B));
} else if (com == "symmetric_diff") {
print_set(symmetric_diff(A, B));
} else if (com == "subtract") {
int x;
cin >> x;
print_set(subtract(A, x));
} else if (com == "increment") {
print_set(increment(A));
} else if (com == "decrement") {
print_set(decrement(A));
}
}
実行時間制限: 2 sec / メモリ制限: 256 MiB
問題文
この問題は難易度が高いので、詰まったらヒントを見てみて下さい。
変数と配列を扱える電卓を作成してください。
電卓の操作は次のようにプログラムに似た命令の形式で与えられます。1行目の入力は命令の行数を表します。
入力例
4 int x = 1 + 2 ; print_int x + 3 ; vec a = [ 1 , 2 , x ] ; print_vec a + [ 4 , 5 , 6 ] ;
出力例
6 [ 5 7 9 ]
命令の形式
電卓の操作は次の命令のいずれかで表されます。
それぞれの命令の終わりには必ず1つのスペースとセミコロン;があり、=の前後には必ず1つのスペースがあります。
| 形式 | 例 | 説明 |
|---|---|---|
int <変数名> = <int式> ; |
int x = 1 + 2 ; |
整数の変数を宣言 |
print_int <int式> ; |
print_int x + 3 ; |
整数の値を出力 |
vec <変数名> = <vec式> ; |
vec a = [ 1 , 2 , x ] ; |
配列の変数を宣言 |
print_vec <vec式> ; |
print_vec a + [ 4 , 5 , 6 ] ; |
配列の値を出力 |
print_vec命令は[ 値1 値2 ... 値N ]という形式で出力します。
C++プログラムで表すと次のようになります。このプログラムをそのまま回答に利用しても構いません。
// 問題文の形式でvec値を出力
void print_vec(vector<int> vec) {
cout << "[ ";
for (int i = 0; i < vec.size(); i++) {
cout << vec.at(i) << " ";
}
cout << "]" << endl;
}
形式の詳細
-
<変数名>は小文字のアルファベット1文字で表されます。 -
<int式>は以下の形式のいずれかで表されます。
| 形式 | 例 | 説明 |
|---|---|---|
<int項> |
1, x など |
1桁の正の整数 または事前にint 命令で宣言された<変数名> |
<int項> <演算子> <int項> <演算子> ... <演算子> <int項> |
x + 3 |
<演算子>は+または- |
<vec式>は以下の形式のいずれかで表されます。
| 形式 | 例 | 説明 |
|---|---|---|
<vec項> |
[ 1 , 2 , x ], aなど |
詳細は次の表 |
<vec項> <演算子> <vec項> <演算子> ... <演算子> <vec項> |
a + [ 4 , 5 , 6 ] |
<演算子>は+または- |
<vec項>は以下の形式のいずれかで表されます。
| 形式 | 例 | 説明 |
|---|---|---|
<vec値> |
[ 1 , 2 , x ] |
[ <int項> , <int項> , ... , <int項> ]の形式 <int項>と,と]はスペース1つで区切られていることに注意 |
<vec変数> |
a |
事前にvec命令で宣言された<変数名> |
計算の定義
| 式 | 計算 | 例 |
|---|---|---|
<int項> + <int項> |
整数の加算 | 1 + 2 → 3 |
<int項> - <int項> |
整数の減算 | 1 - 2 → -1 |
<vec項> + <vec項> |
要素ごとの加算 | [ 1 , 2 , 3 ] + [ 4 , 5 , 6 ] → [ 5 , 7 , 9 ] |
<vec項> - <vec項> |
要素ごとの減算 | [ 1 , 2 , 3 ] - [ 3 , 2 , 1 ] → [ -2 , 0 , 2 ] |
制約
- 1 \leq N \leq 10
- 配列の要素数は2以上5以下
<int式>に現れる<int項>の数は5以下<vec式>に現れる<vec項>の数は5以下- すでに存在する変数が定義されることはない
- 存在しない変数が式の中で使われることはない
- 要素数の異なる配列同士の計算は存在しない
- その他計算できない不正な命令が入力されることはない
入力
入力は次の形式で標準入力から与えられます。
N 命令1 命令2 \vdots 命令N
出力
print_intまたはprint_vecの結果
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
4 int x = 1 + 2 ; print_int x + 3 ; vec a = [ 1 , 2 , x ] ; print_vec a + [ 4 , 5 , 6 ] ;
出力例1
6 [ 5 7 9 ]
問題文で説明した例です。
入力例2
2 print_int 1 - 2 ; print_vec [ 1 , 2 , 3 ] - [ 3 , 2 , 1 ] ;
出力例2
-1 [ -2 0 2 ]
計算結果が負になることもあります。
入力例3
1 print_int 5 ;
出力例3
5
入力例4
1 print_vec [ 1 , 2 ] ;
出力例4
[ 1 2 ]
入力例5
2 int x = 1 ; print_int x ;
出力例5
1
入力例6
2 vec a = [ 3 , 4 ] ; print_vec a ;
出力例6
[ 3 4 ]
入力例7
4 int x = 1 ; int y = 2 ; int z = 3 ; print_int x + y + z ;
出力例7
6
入力例8
4 vec a = [ 1 , 2 , 3 ] ; vec b = [ 4 , 5 , 6 ] ; vec c = [ 7 , 8 , 9 ] ; print_vec a + b + c ;
出力例8
[ 12 15 18 ]
入力例9
6 vec a = [ 1 , 2 ] ; vec b = a + [ 3 , 4 ] ; vec c = a - [ 5 , 6 ] ; print_vec a ; print_vec b ; print_vec c ;
出力例9
[ 1 2 ] [ 4 6 ] [ -4 -4 ]
ヒント1
ヒント1はちょっとしたアドバイスでしかないので、気軽に開いて良いです。
クリックでヒントを開く
今回の問題は少し長いプログラムを書く必要があります。
機能を一つずつ作っていき、正しく動いているかをコードテストで確認しましょう。
入力3から入力6は特にプログラムのテストに有用です。
まずはこれらの入力に対して正しく出力できるプログラムを作ると良いでしょう。
上記の入出力例だけでは原因が分かりにくいバグが発生した場合は、手動で入出力例を作ってみてテストするのも一つの手です。
ヒント2
ヒント2ではこの問題を解く際に使えるSTLの関数を示します。
クリックでヒントを開く
- stoi関数:文字列を数値に変換(3.01で解説)
使用例
stoi("123") == 123 // true
- isdigit関数:文字が数値かどうか判定(3.06で紹介)
使用例
char c;
cin >> c;
// isdigit関数はchar型を引数に取ることに注意
if (isdigit(c)) {
cout << "cは数字" << endl;
}
else {
cout << "cは数字でない" << endl;
}
なお、これらの関数を使わずに解くことも可能です。
入力には1桁の正の整数しか出てこないため、それだけに対応するstoiやisdigit相当の関数は数行程度で書くことができます。
ヒント3
ヒント3では解答例で実装した関数の概要とmain関数を示します。実装方針の参考にしてください。
クリックでヒントを開く
// 問題文の形式でvec値を出力
void print_vec(vector<int> vec)
// 変数名を読み取りイコールを読み飛ばす
string read_name()
// int式の項を1つ読み取る。
// 数字ならその値を返し、そうでないなら変数として解釈し変数の値を返す
// var_int : intの変数を保持するmap
int read_int(map<string, int> &var_int)
// int式全体を読み取って計算する
// var_int : intの変数を保持するmap
int calc_int(map<string, int> &var_int)
// vec値を読み取る
// 最初の"["は読み取ってある前提であることに注意
// var_int : intの変数を保持するmap
vector<int> read_vec_val(map<string, int> &var_int)
// vec式の項を1つ読み取る
// vec値ならその値を返し、そうでないなら変数として解釈し変数の値を返す
// var_int : intの変数を保持するmap
// var_vec : vecの変数を保持するmap
vector<int> read_vec(map<string, int> &var_int, map<string, vector<int>> &var_vec)
// vec式全体を読み取って計算する
// var_int : intの変数を保持するmap
// var_vec : vecの変数を保持するmap
vector<int> calc_vec(map<string, int> &var_int, map<string, vector<int>> &var_vec)
int main() {
// 命令の行数を取得
int N;
cin >> N;
map<string, int> var_int; // intの変数を管理するmap
map<string, vector<int>> var_vec; // vectorの変数を管理するmap
// 行数分の処理
for (int i = 0; i < N; i++) {
// 命令を受け取る
string s;
cin >> s;
// int命令の処理
if (s == "int") {
// 変数名を読み取る
string name = read_name();
// 右辺の式を計算して変数に代入
var_int[name] = calc_int(var_int);
}
// vec命令の処理
if (s == "vec") {
// 変数名を読み取る
string name = read_name();
// 右辺の式を計算して変数に代入
var_vec[name] = calc_vec(var_int, var_vec);
}
// print_int命令の処理
if (s == "print_int") {
// 式を計算して出力
cout << calc_int(var_int) << endl;
}
// print_vec命令の処理
if (s == "print_vec") {
// 式を計算して出力
print_vec(calc_vec(var_int, var_vec));
}
}
}
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
10 int d = 9 + 1 + 2 - 3 + 1 ; int x = d - 3 - 2 + 1 + d ; int k = x - d + d + x - x ; vec c = [ d , x , k , 1 , x ] ; vec u = [ 8 , 9 ] ; vec n = [ 1 , 2 , 3 , 4 , 5 ] ; vec s = [ 6 , 7 ] ; print_vec u + s + u + s - u ; print_vec n - c - c - c + n ; print_int x + k + k - d + x ;
テスト出力1
[ 20 23 ] [ -28 -44 -42 5 -38 ] 54
テスト入力2
10 int l = 7 - 6 - 5 - 4 + 8 ; vec q = [ l , l , l , l ] ; int e = 9 + 9 + 9 + 9 + 9 ; print_vec [ 9 , 5 , 3 ] + [ 2 , 4 , 6 ] - [ 8 , 8 , 8 ] - [ 2 , 2 , 2 ] ; print_int 8 + 8 + 8 ; int z = e + e + e + e + e ; int b = z + z + z + z + z ; print_vec q + [ e , z , z , z ] ; int r = b + b + b + b + b ; print_int r + z + b + e + l ;
テスト出力2
[ 1 -1 -1 ] 24 [ 45 225 225 225 ] 7020
テスト入力3
10 vec j = [ 3 , 3 , 4 ] ; vec a = [ 2 , 8 ] ; vec s = [ 5 , 2 , 6 , 3 ] ; vec t = [ 1 , 1 , 1 , 1 ] - s - s - s - s ; vec o = [ 2 , 2 , 2 , 2 ] - s - s - s - s ; print_vec s ; print_vec a + a + [ 9 , 9 ] - a ; print_int 7 ; print_vec [ 2 , 5 , 2 , 5 ] ; print_vec s - o - o - o + s ;
テスト出力3
[ 5 2 6 3 ] [ 11 17 ] 7 [ 2 5 2 5 ] [ 64 22 78 36 ]
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
細かく関数分けされたプログラムなので、main関数から処理の流れを追うように読むと良いです。
#include <bits/stdc++.h>
using namespace std;
// 問題文の形式でvec値を出力
void print_vec(vector<int> vec) {
cout << "[ ";
for (int i = 0; i < vec.size(); i++) {
cout << vec.at(i) << " ";
}
cout << "]" << endl;
}
// 変数名を読み取りイコールを読み飛ばす
string read_name() {
string name, equal;
cin >> name >> equal;
return name;
}
// int式の項を1つ読み取る。
// 数字ならその値を返し、そうでないなら変数として解釈し変数の値を返す
// var_int : intの変数を保持するmap
int read_int(map<string, int> &var_int) {
string val;
cin >> val;
// 最初の文字が数字かどうかで数字か変数かを判定(3.06で紹介した条件演算子を使用。if文で書いても良い。)
return isdigit(val.at(0))
? stoi(val) // 数値の場合
: var_int.at(val); // 変数の場合
// isdigit関数は3.06で、stoi関数は3.01で紹介している
// これらを使わず自分で変換する処理を書いても良い
}
// int式全体を読み取って計算する
// var_int : intの変数を保持するmap
int calc_int(map<string, int> &var_int) {
string symbol = ""; // 演算子を受け取る変数
int result = 0; // 結果を保持する変数
// 式の終わりである";"が出てくるまで読み取る
while (symbol != ";") {
// 項を1つ読み取る
int val = read_int(var_int);
// 記号が入力されてない場合(式の最初の項)は結果にそのまま代入
if (symbol == "") {
result = val;
}
// 足し算の場合
if (symbol == "+") {
result += val;
}
// 引き算の場合
if (symbol == "-") {
result -= val;
}
// symbolには"+", "-", ";"のいずれかが入力される
cin >> symbol;
}
return result;
}
// vec値を読み取る
// 最初の"["は読み取ってある前提であることに注意
// var_int : intの変数を保持するmap
vector<int> read_vec_val(map<string, int> &var_int) {
vector<int> result; // 結果を保持する変数
string symbol = ""; // vec値中の記号を受け取る変数
// vec値の終わりである"]"が出てくるまで読み取る
while (symbol != "]") {
// 数値を1つ読み取ってvecに追加
int val = read_int(var_int);
result.push_back(val);
// symbolには","か"]"が入力される
cin >> symbol;
}
return result;
}
// vec式の項を1つ読み取る
// vec値ならその値を返し、そうでないなら変数として解釈し変数の値を返す
// var_int : intの変数を保持するmap
// var_vec : vecの変数を保持するmap
vector<int> read_vec(map<string, int> &var_int, map<string, vector<int>> &var_vec) {
string val;
cin >> val;
// "["かどうかでvec値か変数かを判定(3.06で紹介した条件演算子を使用。if文で書いても良い。)
return val == "["
? read_vec_val(var_int) // vec値の場合
: var_vec.at(val); // 変数の場合
}
// vec式全体を読み取って計算する
// var_int : intの変数を保持するmap
// var_vec : vecの変数を保持するmap
vector<int> calc_vec(map<string, int> &var_int, map<string, vector<int>> &var_vec) {
string symbol; // 演算子を受け取る変数
vector<int> result; // 結果を保持する変数
// 式の終わりである";"が出てくるまで読み取る
while (symbol != ";") {
// 項を1つ読み取る
vector<int> vec = read_vec(var_int, var_vec);
// 記号が入力されてない場合(式の最初の項)は結果にそのまま代入
if (symbol == "") {
result = vec;
}
// 足し算の場合
if (symbol == "+") {
for (int i = 0; i < result.size(); i++) {
result.at(i) += vec.at(i);
}
}
// 引き算の場合
if (symbol == "-") {
for (int i = 0; i < result.size(); i++) {
result.at(i) -= vec.at(i);
}
}
// symbolには"+", "-", ";"のいずれかが入力される
cin >> symbol;
}
return result;
}
int main() {
// 命令の行数を取得
int N;
cin >> N;
map<string, int> var_int; // intの変数を管理するmap
map<string, vector<int>> var_vec; // vectorの変数を管理するmap
// 行数分の処理
for (int i = 0; i < N; i++) {
// 命令を受け取る
string s;
cin >> s;
// int命令の処理
if (s == "int") {
// 変数名を読み取る
string name = read_name();
// 右辺の式を計算して変数に代入
var_int[name] = calc_int(var_int);
}
// vec命令の処理
if (s == "vec") {
// 変数名を読み取る
string name = read_name();
// 右辺の式を計算して変数に代入
var_vec[name] = calc_vec(var_int, var_vec);
}
// print_int命令の処理
if (s == "print_int") {
// 式を計算して出力
cout << calc_int(var_int) << endl;
}
// print_vec命令の処理
if (s == "print_vec") {
// 式を計算して出力
print_vec(calc_vec(var_int, var_vec));
}
}
}
実行時間制限: 0 msec / メモリ制限: 0 KiB
EX1「出力の練習 / 1.01」に戻る
EX5「A足すB問題 / 1.05」に戻る
コードテストの場所
練習問題を解くときは「コードテスト」というページを使ってプログラムを書き、正しく動作することが確認できたら提出するようにしましょう。
コードテストのページは、次の画像の赤い四角で囲った部分をクリックすることで開けます。

コードテストの設定
コードテストの画面は次の画像のようになっています。
設定として、「エディタ切り替え」をオフ、「高さ自動調節」をオンにしましょう。

プログラムの実行
設定ができたら、に「ソースコード」と書かれている場所にプログラムを書きます。
プログラムが書けたら「言語」が「C++ (GCC 9.2.1)」になっていることを確認し、ページ下部にある「実行」ボタンを押してください。
実行結果
プログラムが実行できたら「標準出力」と書かれている場所にプログラムの出力が表示されます。

エラーが発生したとき
エラーが発生した場合は「標準エラー出力」と書かれている場所にエラーの詳細が表示されます。
例えば行末のセミコロンを忘れてしまった場合、次のようなエラーが表示されます。
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "Hello, world!" << endl // セミコロン忘れ
}
標準エラー出力
./Main.cpp: In function ‘int main()’: ./Main.cpp:6:1: error: expected ‘;’ before ‘}’ token } ^
エラーの内容をヒントにプログラムを修正し、また実行してください。
エラーの直し方については1.02.プログラムの書き方とエラーで説明します。
コードテスト以外のプログラミング環境
コードテスト以外のプログラミング環境を紹介します。コードテストが使いづらいと感じた方はこちらを試してみてください。
全てAtCoderとは無関係なWebサービスであることに注意してください。
推奨設定(Editor settings) ・tab:2-spaces ・tab width:2 ・Smart Indentにチェック ・Expandにチェック 使い方 ・実行:Runボタンをクリック or Ctrl+Enter ・標準入力:「Stdin」をクリックして出てきたテキストボックスに入力
手元のコンピュータでプログラムを書きたい場合
今まで紹介したプログラミング環境はWeb上でプログラムを動かすものですが、手元のパソコンでプログラムを動かすこともできます。
ただし面倒な作業になることが多いので、パソコン操作に慣れている&エラー対処に自信がある人以外にはおすすめしません。また、APG4bの解説はコードテストかWandbox等で作業することを前提に書かれています。
それを把握した上で手元のパソコンでプログラムを書きたい人は、「C++ gcc 環境構築」等で検索するか、身近な詳しい人に聞いてみてください。
XCodeやVisual Studio(ClangやVC++)等で作業したい人は追加の設定が必要になります。設定方法を以下に記載しておくので参考にしてください。
#include <bits/stdc++.h>を使うための設定方法を開く
以下の環境で作業する場合も、提出は「C++ (GCC 9.2.1)」で行う必要があることに注意してください。
共通の作業
適当な場所にincludeディレクトリを作成し、その中にbitsディレクトリを作成します。さらにbitsディレクトリの中にstdc++.hファイルを作成し、次の内容で保存します。
#include <iostream> // cout, endl, cin #include <string> // string, to_string, stoi #include <vector> // vector #include <algorithm> // min, max, swap, sort, reverse, lower_bound, upper_bound #include <utility> // pair, make_pair #include <tuple> // tuple, make_tuple #include <cstdint> // int64_t, int*_t #include <cstdio> // printf #include <map> // map #include <queue> // queue, priority_queue #include <set> // set #include <stack> // stack #include <deque> // deque #include <unordered_map> // unordered_map #include <unordered_set> // unordered_set #include <bitset> // bitset #include <cctype> // isupper, islower, isdigit, toupper, tolower
(適当な場所)/include/bits/stdc++.hとなっている状態です。
このstdc++.hファイルにはAPG4bの3章までで使う内容しか記載していません。足りないものがある場合は適宜自分で追加してください。
各行のコメントはそのincludeで読み込まれる関数等のうち、APG4bで紹介している内容を示しています。
Clang(macOS or Linux)の場合
macOSのデフォルトの
gccコマンドは、実際にはclangにオプションを付けたエイリアスになっているため、こちらの設定が必要です。
環境変数CPLUS_INCLUDE_PATHにincludeディレクトリのパスを追加します。
ホームディレクトリの.bash_profile(無い場合は作成)にパスを追加するコマンドを追記してください。
次のコマンドは/home/apg4b/include/bits/stdc++.hという配置になっている場合のコマンドの例です。自分の配置に合わせてパスを書き換えてください。
export CPLUS_INCLUDE_PATH=$CPLUS_INCLUDE_PATH:home/apg4b/include/
XCode(maxOS, Clang)の場合
XCodeのバージョンにより多少異なることがあります。
以下の設定で作成されたプロジェクトがあるとします。
macOS → Command Line Tool Language → C++
以下の設定を行います。
- プロジェクトを選択
- 「Build Settings」を選択
- 「All」を選択
- 「Apple Clang - Custom Compiler Flags」の「Other C++ Flags」の入力欄を選択
-I(includeディレクトリのパス)を追記して「+」をクリック
画像では/home/apg4b/include/bits/stdc++.hという配置になっている場合のパスを追記しています。

Visual Studio(Windows, VC++)の場合
Visual Studioのバージョンにより多少異なることがあります。
また、printfやscanfを使用する場合は次の一文をstdc++.hファイルの最初の行に記述してください。
#define _CRT_SECURE_NO_WARNINGS
以下の手順で作成されたプロジェクトがあるとします。
Visual C++ → 空のプロジェクト ソリューションエクスプローラ → 「ソースファイル」を右クリック → 追加 → 新しい項目 Visual C++ → C++ ファイル → 追加
以下の設定を行います。
- 「プロジェクト」→「(プロジェクト名)のプロパティ」を選択
- 「構成」を「すべての構成」に変更
- 「VC++ディレクトリ」を選択
- 「インクルードディレクトリ」に
includeディレクトリのパスを追記 - 「OK」をクリック
画像ではC:\Users\apg4b\include\bits\stdc++.hという配置になっている場合のパスを追記しています。

EX1「出力の練習 / 1.01」に戻る
ここから先の説明はEX5「A足すB問題 / 1.05」を解く時に読んでください。
コードテストでの入力
コードテスト上で入力機能を使う場合、「標準入力」と書かれている場所に入力を書き、実行ボタンをクリックします。

実行時間制限: 0 msec / メモリ制限: 0 KiB
EX2「エラーの修正 / 1.02」に戻る
EX5「A足すB問題 / 1.05」に戻る
AtCoder上でのエラーの表示
エラーの種類とAtCoder上の表示の対応は次の表の通りです。
| エラーの種類 | ジャッジの判定 | 終了コード |
|---|---|---|
| コンパイルエラー | (Compile Error) | -1 |
| 実行時エラー | (Runtime Error) | 0以外 |
| 論理エラー | (Wrong Answer) | 0(エラーがない時と同じ) |
| 実行時間制限超過※ | (Time Limit Exceeded) | 9 |
「ジャッジの判定」は提出後の採点結果のことです。
「終了コード」はコードテスト上でプログラムを実行した後、画面の下部に表示されている数値のことです。
コードテスト上でコンパイルエラーが発生した場合、「標準エラー出力」にエラーの詳細が表示されます。
エラーの内容を読んだり、表示されているエラー内容を検索したりしてエラーを修正しましょう。
※実行時間制限超過がAPG4bで発生する場合、提出先を間違えている可能性があります。説明ページではなく問題ページ(EX◯◯)に提出しているかを確認しましょう。
EX2「エラーの修正 / 1.02」に戻る
ここから先の説明はEX5「A足すB問題 / 1.05」を解く時に読んでください。
ACを取るには
入力を使う問題では、「ある入力ではACだったが、別の入力ではWAだった」という事がありえます。
例えば「A + Bを計算する問題」で、間違えてプログラムの出力をA - Bとしてしまったとします。
この場合でも、入力がA = 5, B = 0だったとき、プログラムの出力と正解はどちらも5となり一致し、この入力に対しては
となります。
しかし、入力がA = 2, B = 1だったとき、プログラムの出力は1となりますが、正解は3なので一致せず、この入力に対してはとなります。
| 自分のプログラムの出力 | 正解 | 入力に対する採点結果 | |
|---|---|---|---|
| A = 5, B = 0 | 5 | 5 | |
| A = 2, B = 1 | 1 | 3 |
問題の採点結果をにするには、その問題の入力のパターン全てに対して正しい出力をする必要があります。
提出の詳細の確認方法
採点結果がだった場合は「提出の詳細」を見ると、いくつの入力例に対してACであり、いくつの入力例に対してWAであるかを見ることができます。
この画面から実際にどのような入力が行われるかを確認することはできませんが、提出したプログラムがどれくらい正しいかのヒントにはなります。
提出の詳細を見るには、まず問題ページで「提出一覧」→「自分の提出」をクリックします。

すると自分の提出の一覧が表示されるので、見たい提出を選んで「詳細」をクリックすると、提出の詳細を見ることができます。

「提出一覧」→「すべての提出」をクリックすることで、他の人の提出を見ることもできます。
他の人のプログラムを見ることも勉強になるので、うまく活用してください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
コンパイルエラー集
コンパイルの際、コードが間違っていると、コンパイルエラーが発生します。 このページでは代表的なコンパイルエラーの説明と、対処法について説明します。
このページに書かれていることはAtCoder上で「C++14 (GCC 5.4.1)」として実行することを想定した内容となっています。他の環境を使っている人はサンプルプログラムを自分の環境で実行してエラーメッセージを確認してください。
このページの使い方
ブラウザの検索機能を使って、エラーメッセージでページ内検索すると該当するエラーの記事を検索しやすいです。
Chromeの場合
- ツールバー右上にあるChromeメニューをクリックします。
- 検索(F)をクリックします。
- 右上に表示された検索フィールドに検索したいキーワードを入力します。
FireFoxの場合
- メニューボタンをクリックします。
- このページを検索...をクリックします。
- 下部に表示された検索フィールドに検索したいキーワードを入力します。
Edgeの場合
- Ctrl + F キーを押します。
- 画面上部に表示された検索フィールドに検索したいキーワードを入力します。
検索方法
- コンパイルエラーをコピーします
- ブラウザの検索機能を用いて検索します。 見つからない時は、エラーメッセージを短くしてみたりしてみましょう。
セミコロン忘れ
エラーメッセージ例
error: expected ‘,’ or ‘;’ before ‘○○○’
error: expected ';' at end of declaration
原因
行末のセミコロンやコロンの記述を忘れている。
エラーの出るコード
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 2;
int b = 3
int c = a + b;
cout << c << endl;
}
6行目 行末のセミコロンを忘れている。
修正方法
セミコロンを追記しましょう。 セミコロンを忘れている場所はエラーメッセージの出ている行の近くであることが多いです。
修正したコード
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 2;
int b = 3;
int c = a + b;
cout << c << endl;
}
6行目の行末にセミコロンを追記しました。
存在しない変数の利用
エラーメッセージ例
error: ‘○○○’ was not declared in this scope
原因
変数を宣言せずに利用しようとした。
エラーの出るコード
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 2;
int b = 3;
cout << c << endl;
}
7行目 c という名前の変数を宣言せずに使ってしまっています。
修正方法
変数を宣言しましょう。
修正したコード
#include <bits/stdc++.h>
using namespace std;
int main() {
int a = 2;
int b = 3;
int c = a + b;
cout << c << endl;
}
7行目にcという名前の変数を宣言しました。
includeファイル名の間違い
エラーメッセージ例
fatal error: ○○○.h: No such file or directory
原因
includeするファイルの名前を間違えています。
エラーの出るコード
#include <bits/stdoooc++.h>
using namespace std;
int main() {
cout << "Hello World" << endl;
}
修正方法
includeするファイルの名前を訂正しましょう。
修正したコード
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "Hello World" << endl;
}
include忘れ
エラーメッセージ例
error: '○○○’ was not declared in this scope
原因
includeを記述するのを忘れています。
エラーの出るコード
using namespace std;
int main() {
cout << "Hello World" << endl;
}
#include<bits/stdc++.h> を記述せずに coutやendlを使っています。
修正方法
利用したい関数をincludeしましょう。
修正したコード
#include <bits/stdc++.h>
using namespace std;
int main() {
cout << "Hello World" << endl;
}
1行目に #include <bits/stdc++.h> と追記しました。
関数名と変数名が重複してしまう
エラーメッセージ例
error: '○○○’ cannot be used as a function
原因
変数を関数のように使ってしまっています。 関数名と変数名が衝突してしまっているために起こることがあります。
エラーの出るコード
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> vec;
vec = { 25, 100, 64 };
int max = vec.at(0);
for(int i = 1; i < vec.size(); i++) {
max = max(vec.at(i), max);
}
cout << max << endl;
}
10行目 最大値を返す関数であるmax関数と、最大値を格納する変数であるmax変数があり、
名前が衝突してしまっています。
修正方法
変数名を変え、名前が衝突しないようにしましょう。
修正したコード
#include <bits/stdc++.h>
using namespace std;
int main() {
vector<int> vec;
vec = { 25, 100, 64 };
int num_max = vec.at(0);
for(int i = 1; i < vec.size(); i++) {
num_max = max(vec.at(i), num_max);
}
cout << num_max << endl;
}
変数名 max を num_max に変更しました。
for文の構文ミス
エラーメッセージ例
./Main.cpp: In function ‘int main()’:
./Main.cpp:5:29: error: expected ‘)’ before ‘;’ token
for(int i = 0; i < 10; i++;) {
^
./Main.cpp:5:30: error: expected primary-expression before ‘)’ token
for(int i = 0; i < 10; i++;) {
for文の構文付近にエラーが出ているのが特徴です。
原因
for文の構文ミス
エラーの出るコード
#include <bits/stdc++.h>
using namespace std;
int main() {
for(int i = 0; i < 10; i++;) {
cout << i << endl;
}
}
5行目のfor文の構文にミスがあります。 最後の増分処理の部分に余計なセミコロンがあります。
修正方法
for文の構文が正しくなるよう訂正しましょう。
修正したコード
#include <bits/stdc++.h>
using namespace std;
int main() {
for(int i = 0; i < 10; i++) {
std::cout << i << std::endl;
}
}
余計なセミコロンを削除しました。
実行時間制限: 0 msec / メモリ制限: 0 KiB
「1.10.while文」に戻る
「1.11.for文・break・continue」に戻る
キーポイント
- repマクロを使うと「指定した回数だけ処理を繰り返す」ことができる
- repマクロを使うには宣言が必要
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
- 指定した回数だけ処理を繰り返す
rep (i, 回数) {
処理
}
- カウンタ変数
iを使えば「何回目の繰り返しか」という情報が利用できる - カウンタ変数は0から始まり「回数-1」で終わる
- カウンタ変数名は変更できる
- breakを使うとループを途中で抜けられる
- continueを使うと後の処理を飛ばして次のループへ行ける
ループ構文の裏技
この付録では、ループ構文を楽に書くための裏技であるrepマクロについて説明します。
while文やfor文がよくわからなかった人でも、シンプルなループ(繰り返し)の機能であるrepマクロなら理解できるかもしれません。
この付録を読めば1.10.while文と1.11.for文・break・continueを読まなくても、練習問題のEX10.棒グラフの出力とEX11.電卓を作ろうを解くことができます。
ただし、1.12以降の説明ではrepマクロではなくfor文を使って説明するので、EX10とEX11を解き終わったら1.10と1.11も読むようにしましょう。この付録を読む前より簡単に理解できるはずです。
repマクロの是非
この部分はプログラミング経験者向けの文です。経験者の方はクリックで説明を開いて読んでください。
クリックで説明を開く
プログラミング経験者の中にはrepマクロに否定的な人もいると思います。ここではrepマクロをAPG4bで紹介する理由について説明します。
C++14時点では標準で「N回の繰り返し処理」を簡潔に書く構文が用意されていません。その処理には通常for文を用いますが、for文は初心者にとっては2点大きな問題があります。
1点目として、for文1行で複数の処理を行っているため理解しづらいという点があげられます。本来ループ構文で理解してほしいことは「処理を繰り返す」ということですが、for文は構文の動きを考えざるを得ないため、重要でないことに意識を割かれて理解が妨げられてしまいます。
2点目として、カウンタ変数を書き間違えるバグにハマって時間を浪費してしまう点があげられます。for文はカウンタ変数を書く場所が3箇所あるので、書き間違えるリスクが大きいです。1重のループにおいてはコンパイルエラーが出るだけなのでまだましですが、多重ループの場合はiとjを書き間違えることによって非常に発見し辛いバグになり得ます。for文のカウンタ変数の書き間違えによるバグは熟練者でも発生しうるバグであり、完全に防ぐことは難しいです。この問題は学習者のモチベーションを削ぎ、挫折するきっかけになりかねません。(コードスニペットとIDE等のリファクタ機能を用いることを徹底したり、静的コード解析ツールを使いこなせばある程度防ぐことはできますが、それでも完全ではありませんし、ツールの理解や環境構築等も必要になります。)
これらの問題はrepマクロを使うことによってほぼ解決されます。このようにrepマクロは初心者がC++を学ぶ場面において性質が良いため、APG4bでは紹介しています。
それでもマクロによる構文拡張は行うべきではないという方もいるかもしれません。しかし、マクロによる構文拡張の問題は個人で小規模なプログラムを書く分には基本的に発生しませんし、それがrepマクロひとつだけであるならなおさらです。この付録ではrepマクロが標準の記法でないことも説明しているので、しっかりと読んでいれば学習者が勘違いすることもありません。
また、実はマクロによるループ構文の拡張はLinuxカーネルのソースコードでもfor_each_...等の名前でよく利用されています。LinuxカーネルのソースコードはC言語ですし、他にも様々な事情の違いはありますが、for文の扱いづらさが広く認識されている例だと言えるでしょう。
これを期にrepマクロを利用しても良い状況、または利用するべき状況について考え直してみてはいかがでしょうか。
repマクロ
repマクロは「指定した回数だけ処理を繰り返す」という機能です。
次のプログラムは「"Hello"と出力して改行した後、"AtCoder"と出力する処理」を3回繰り返します。
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
int main() {
rep(i, 3) {
cout << "Hello" << endl;
cout << "AtCoder" << endl;
}
}
実行結果
Hello AtCoder Hello AtCoder Hello AtCoder
repマクロの準備
repマクロを使うには、今まで使っていたプログラムの基本形を次のように変える必要があります。
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
int main() {
}
3行目に#define rep(i, n) for (int i = 0; i < (int)(n); i++)と追記しています。この部分の詳細は第4章で説明します。今は理解していなくても良いので、コピー&ペーストして使いましょう。
repマクロの使い方
repマクロは基本的に次のように書き、指定した回数だけ処理を繰り返します。
rep(i, 回数) {
処理
}
はじめのプログラムでは「回数」に3、「処理」にcout << "Hello" << endl; cout << "AtCoder" << endl;を指定しています。
rep(i, 3) {
cout << "Hello" << endl;
cout << "AtCoder" << endl;
}
「回数」の部分には3のように直接値を書いても良いですし、変数や計算処理を書いても良いです。
カウンタ変数
変数iを利用することで「何回目の繰り返しか」という情報を使うことができます。
次のプログラムは「"Hello rep: (何回目の繰り返しか)"と出力する処理」を3回繰り返すものです。
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
int main() {
rep(i, 3) {
cout << "Hello rep: " << i << endl;
}
}
実行結果
Hello rep: 0 Hello rep: 1 Hello rep: 2
iが0から始まることに注意してください。このように、プログラム中では番号を数えるときに1ではなく0から始めることが多いです。
0から始めたほうがプログラムをシンプルに書けることが多いためそうなっています。最初はわかりにくく感じるかもしれませんが、慣れるようにしましょう。
iのように「何回目の繰り返しか」を管理する変数のことをカウンタ変数と呼ぶことがあります。repマクロにおいては、カウンタ変数の型はint型です。
カウンタ変数名の変更
次の例ではiの代わりにatcoderをカウンタ変数にしています。
rep(atcoder, 3) {
cout << "Hello rep: " << atcoder << endl;
}
repの()の最初の部分でカウンタ変数名を指定します。カウンタ変数も他の変数と同じルールで名前を指定できます。
カウンタ変数も考慮すると、より正確にはrepマクロの記法は次のようになります。
rep(カウンタ変数名, 回数) {
処理
}
カウンタ変数名には基本的にiを使い、iが使えない場合はj, k, l...と名前をつけていくのが一般的です。
応用例
N人の合計点を求めるプログラムを作ってみましょう。
次のプログラムは「入力の個数N」と「点数を表すN個の整数」を入力で受け取り、点数の合計を出力します。
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
int main() {
int N;
cin >> N;
int sum = 0; // 合計点を表す変数
int x; // 入力を受け取る変数
rep(i, N) {
cin >> x;
sum += x;
}
cout << sum << endl;
}
入力
3 1 10 100
実行結果
111
合計点を表す変数sumを作っておき、ループするたびに入力を変数xに入れ、sumに足しています。
このプログラムが実行される様子を表したのが次のスライドです。
このように、繰り返し処理を使えば様々な処理が行えるようになります。
ループ構文を使って様々な処理を書く方法は2.01.ループの書き方や2.02.多重ループで詳しく説明します。
breakとcontinue
repマクロのループを制御する命令として、breakとcontinueがあります。
break
breakはループを途中で抜けるための命令です。

breakを使ったプログラムの例です。
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
int main() {
// breakがなければこのループは i == 4 まで繰り返す
rep(i, 5) {
if (i == 3) {
cout << "ぬける" << endl;
break; // i == 3 の時点でループから抜ける
}
cout << i << endl;
}
cout << "終了" << endl;
}
実行結果
0 1 2 ぬける 終了
if文で i == 3 が真になったとき、break;の命令を実行することでループを抜け、終了と出力しています。
continue
continueは後の処理をとばして次のループへ行くための命令です。

continueを使ったプログラムの例です。
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
int main() {
rep(i, 5) {
if (i == 3) {
cout << "とばす" << endl;
continue; // i == 3 のとき これより後の処理をとばす
}
cout << i << endl;
}
cout << "終了" << endl;
}
実行結果
0 1 2 とばす 4 終了
上のプログラムでは、if文で i == 3 が真になったとき、continue;の命令を実行することでcontinueより下の部分を飛ばし、次のループに入ります。
注意点
repマクロを使用するときの注意
repマクロは簡潔でわかりやすい構文ですが、多人数が参加する開発等では利用できない場合もあります。
実はrepマクロはC++の標準の構文ではなく、マクロという機能を使って自分で定義した構文です。
多人数開発でマクロにより様々な構文が定義されるとプログラムが過度に複雑になるなどの理由から、マクロによる構文の定義は禁止されていることがよくあります。 repマクロを使用するときはコーディングルールを確認するようにしましょう。
ただし、競技プログラミングやAPG4bでrepマクロを使う分には何も問題は無いので、気にせず使ってください。個人開発でも基本的には使って良いです。
なお、この付録を除くAPG4bの説明文ではrepマクロは使わずにwhile文やfor文を使いますが、練習問題を解く時はrepマクロを利用しても構いません。
repマクロの定義し忘れ
#define rep(i, n) for (int i = 0; i < (int)(n); i++)と書くことを忘れると次のようなコンパイルエラーが発生します。
#include <bits/stdc++.h>
using namespace std;
int main() {
rep(i, 3) {
cout << "Hello" << endl;
cout << "AtCoder" << endl;
}
}
コンパイルエラー
./Main.cpp: In function ‘int main()’:
./Main.cpp:5:7: error: ‘i’ was not declared in this scope
rep(i, 3) {
^
./Main.cpp:5:11: error: ‘rep’ was not declared in this scope
rep(i, 3) {
^
細かい話
細かい話なので、飛ばして問題を解いても良いです。
repマクロの派生
もう少し自由度を上げて、「カウンタ変数がSからN-1の間処理を繰り返す」というrepマクロを利用することもあります。
次のプログラムは「Hello rep2: (カウンタ変数の値)と出力する処理」をカウンタ変数が2~4の間繰り返します。
#include <bits/stdc++.h>
using namespace std;
#define rep2(i, s, n) for (int i = (s); i < (int)(n); i++)
int main() {
rep2(i, 2, 5) {
cout << "Hello rep2: " << i << endl;
}
}
実行結果
Hello rep2: 2 Hello rep2: 3 Hello rep2: 4
このマクロを利用するには#define rep2(i, s, n) for (int i = (s); i < (int)(n); i++)とはじめの部分に追記する必要があります。
なお、次のようにすれば通常のrepマクロで代用することも可能です。
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
#define rep2(i, s, n) for (int i = (s); i < (int)(n); i++)
int main() {
int s = 2, n = 5;
rep2(i, s, n) {
cout << "Hello rep2: " << i << endl;
}
// 上のループとほとんど同じ処理
rep(ii, n - s) {
int i = ii + s;
cout << "Hello rep: " << i << endl;
}
}
実行結果
Hello rep2: 2 Hello rep2: 3 Hello rep2: 4 Hello rep: 2 Hello rep: 3 Hello rep: 4
カウンタ変数のスコープ
repマクロのカウンタ変数はrepマクロ{ }中でしか使えません。
次の例では、repマクロのカウンタ変数であるiがスコープの範囲外で使われているため、コンパイルエラーが発生しています。
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
int main() {
rep(i, 3) {
cout << "Hello!" << endl;
}
cout << i << endl;
}
コンパイルエラー
In function ‘int main()’:
9:11: error: ‘i’ was not declared in this scope
cout << i << endl;
^
「変数のスコープ」で見たエラーと同じく、‘i’ was not declared in this scope('i'はこのスコープで宣言されていません)というエラーが出ています。
{ }の省略
if文と同様に、repマクロの処理が一文のみの場合も{ }を省略できます。
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
int main() {
rep(i, 3)
cout << "Hello!" << endl;
}
repマクロのネスト
if文と同様に、repマクロもネストさせることができます。そのような書き方は多重ループと呼ばれます。
詳しくは2.02.多重ループで説明します。
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
int main() {
rep(i, 2) {
rep(j, 2) {
cout << "i: " << i << ", j:" << j << endl;
}
}
}
実行結果
i:0, j:0 i:0, j:1 i:1, j:0 i:1, j:1
forループとの関係
repマクロはfor文の機能を制限する代わりにシンプルに書けるようにしたものです。
以下のrepマクロとfor文はほとんど同じ意味になります。
int n = 5;
rep(i, n) {
処理
}
for (int i = 0; i < n; i++) {
処理
}
途中でループ回数やカウンタ変数を書き換えた場合
repマクロの処理の中でループ回数やカウンタ変数を書き換えると、ループの処理に影響が出ます。
次の例ではその両方をループの中で書き換えています。
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
int main() {
int n = 4;
rep(i, n) {
cout << i << ", " << n << endl;
n--; // 回数を書き換え
i++; // カウンタ変数を書き換え
}
}
実行結果
0, 4 2, 3
このように、ループ回数やカウンタ変数を書き換えるとループ回数が変わります。
なぜこのような挙動になるかは上で説明した「forループとの関係」を頭に入れた上で、1.11.for文・break・continueを読めば理解できます。
よくわからないうちは、ループ回数を保持する変数とカウンタ変数は書き換えないほうが無難です。
問題
以下の2つの問題は1.10.while文と1.11.for文・break・continueの練習問題ですが、repマクロを使って解くとことができます。
ヒントと解答例のrepマクロ版を用意したので、挑戦してみてください。
EX10.棒グラフの出力
ヒント
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
int main() {
cout << "A:";
int i = 0;
rep(i, 5) {
cout << "]";
}
cout << endl;
}
ヒント出力
A:]]]]]
解答例
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
int main() {
int A, B;
cin >> A >> B;
cout << "A:";
rep(i, A) {
cout << "]";
}
cout << endl;
cout << "B:";
rep(i, B) {
cout << "]";
}
cout << endl;
}
EX11.電卓を作ろう
ヒント1
クリックでヒントプログラムを見る
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
int main() {
int sum = 0;
rep(i, 5) {
int x;
cin >> x;
sum += x;
cout << i + 1 << ":" << sum << endl;
}
cout << sum << endl;
}
解答例
クリックで解答例を見る
#include <bits/stdc++.h>
using namespace std;
#define rep(i, n) for (int i = 0; i < (int)(n); i++)
int main() {
int N, A;
cin >> N >> A;
rep(i, N) {
int x;
string op;
cin >> op >> x;
if (op == "+") {
A += x;
}
else if (op == "-") {
A -= x;
}
else if (op == "*") {
A *= x;
}
else if (op == "/" && x != 0) {
A /= x;
}
else {
cout << "error" << endl;
break;
}
cout << i + 1 << ":" << A << endl;
}
}