実行時間制限: 2 sec / メモリ制限: 1024 MiB
第 1 章について
第 1 章では、プログラムの基本的な文法について説明します。
第 1 章をマスターすれば、理論上は全ての「計算処理」を行うプログラムを書ける程の知識が身につきます。
APG4bPython の取り組み方
プログラミングの勉強では手を動かすことが重要です。練習問題はできるだけ解くようにしましょう。
ただし、「説明文中のプログラムを何も考えずに写す」というのは時間の無駄にしかならないことが多いです。
用意されているプログラムを動かすときはコピー&ペーストを使いましょう。
Python の特徴と選ぶ理由
競技プログラミングを始めるにあたって、どの言語を使うかで悩む方も多いと思います。 AtCoder では言語選択は恒久的なものではなく、問題ごとに柔軟に使い分けることもできますが、多くの参加者はほとんどの問題でひとつのメイン言語を使い続けていることも事実です。
このページを見ている方は、多少なりとも Python で競技プログラミングを始めようか検討されていることと思います。以下では、メイン言語として Python を選ぶメリット・デメリットを紹介します。
Python を使うメリット
文法が直感的
トップページでも書きましたが、 Python は文法が直感的でコードが書きやすく可読性が高いと言われています。競技プログラミングでは良い解法を思いついても、時間内にコードに書き出せないと得点が得られません。また 1 分 1 秒でも早く正解した方が有利になります。このため、書きやすいという特徴は有利に働きやすいと言えます1。
多倍長整数
Python では多倍長整数が標準機能で簡単に扱えるため、問題によっては大きなアドバンテージになります。通常は煩雑な考察をすることを想定された問題でも、多倍長整数を使うことで、解法やコードが簡潔になることがあります。
Python を使うデメリット
実行速度
Python はインタプリタ言語であり、 C++ のようなコンパイル言語と比べるとどうしても実行速度が遅くなる傾向があります。
直近の AtCoder のコンテストでは、超上級者向けの問題の一部を除いて、コンテストで出題される問題のほとんどは Python (後述の CPython または PyPy)でも実行時間制限内に無理なく通すことができます。このため、解法は合ってるのに Python だから通せないということはほとんどありません。
もちろん、想定解よりも遅い解法を使う場合や Python が得意でない書き方をする場合などでは TLE (実行時間制限超過)になる可能性はあります。本プログラムでは、 Python を使う場合に TLE に引っかからないために気を付ける点についてもなるべく触れていく予定です(主に 2 章以降になる予定です)。
CPython と PyPy
AtCoder では、 Python コードの実行環境として CPython と PyPy が用意されています。 CPython と PyPy はいずれも Python の実行環境で、多くの場合は全く同じコードで全く同じアウトプットを返しますが、一部挙動が異なる場合があります。それぞれの特徴は以下の通りです。
- CPython は Python の公式の実装です。
- PyPy は JIT(Just-In-Time)コンパイル機能を持っています。 JIT コンパイルにより実行時にコードを機械語に変換することで、 CPython に比べて高速になることが多いです。
AtCoder における競技プログラミングでは、一部の例外を除き、基本的には PyPy で提出する方が実行時間制限の関係で有利になることが多いです。
問題
提出練習
プログラミングの文法の説明に入る前に、自動採点システム(ジャッジ) 2 の使い方を確認しましょう。ジャッジへの提出フォームは、このページの一番下にあります。
提出言語の選択
CPython で提出する場合は "Python(CPython 3.13.7)" を、 PyPy で提出する場合は "Python(PyPy 3.11-v7.3.20)" を選択しましょう。「言語」欄を押して出てくるボックスに言語名の一部("py" など)を入力すると探しやすくなります。 3
ソースコード
「ソースコード」欄にはプログラムのソースコードを入力します。
ここでは、次のプログラムをコピー&ペーストしてみましょう。
コピー&ペーストの仕方:
↓の右上にある「Copy」ボタンをクリック→「ソースコード」のテキストを入力する場所で右クリック→「貼り付け」をクリック
print("Hello, world!")
提出・結果確認
言語選択とソースコードの入力ができたら、「提出」ボタンを押してください。
ページが切り替わり、WJ と表示されているところが AC に変われば提出成功です。
- WA や RE と表示されてしまった場合、正しくコピー&ペーストできているか確認し、再提出してください。
- CE と表示されてしまった場合、「言語」が正しく選択されているか確認してください。 "Python(CPython 3.13.7)" または "Python(PyPy 3.11-v7.3.20)" が選択されているかどうか確認し、再提出してください。
CPython と PyPy の一方で AC が得られたら、もう片方でも提出してみましょう。全く同じコードで AC が得られることが確認できると思います。
コードテスト
ジャッジは、出力結果が正しいかどうかを判定してくれますが、思い通りの結果が得られない場合など、自分のコードがどのような出力をしているのか確認したいこともあると思います。「コードテスト」を使うとプログラムがどのような出力をしているか確認することができます。コードテストはページ上部のリンクから飛ぶことができます。
コードテストの使い方は、上で説明したジャッジの使い方に似ていますが、下記のとおりです。
- 提出言語を選択する
- ソースコードを記載する
- 「標準入力」欄に入力(後述)を記載する
- 実行ボタンを押す
「入力」については 1.05. 節で扱います。このページの Hello, world! を出力するような例では入力はありませんので、「標準入力」欄は空欄で構いません。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 出力には
printを用いるprintは文字列や数値を出力できる- 複数の要素を改行区切り、スペース区切りで出力することも可能
- コメントを書く際は
#や"""を用いる - 全角スペース、行頭の半角スペースに注意
出力を行うプログラム
文字列の出力
Python においてプログラムは上から順に一行ずつ実行されます。以下は前節で提出した "Hello, world!" という文字列を出力する(画面に表示する)プログラムです。
print("Hello, world!")
実行結果
Hello, world!
このプログラムは print という機能2で出力を行っています。print に続けて半角の丸括弧内に要素を記述することで、記述した要素を出力することができます。
この例では "Hello, world!" という文字列を出力しています。Python では " " で囲った部分は文字列として扱われます。print は文字列を受け取るとその内容をそのまま出力します。
異なる文字列を出力したければ、" " の中に入れる文章を書き換えれば良いです。
print("Pythonだいすき")
実行結果1
Pythonだいすき
数値の出力
print は文字列以外にも様々な要素を受け取ることができます。以下は数値を出力するプログラムです。
print(123)
実行結果
123
この例では 123 という数値(整数)を出力しています。Python では数字から成る要素は数値として解釈されます。print 関数は数値も文字列同様に値をそのまま出力することができます。
なお、ここで print("123") と書いても同じ実行結果を得ることができます。
複数の出力
改行区切りの出力
複数の print を続けて記述するとどうなるでしょうか。
print("Hello, world!")
print(123)
実行結果
Hello, world! 123
Python は記述したプログラムを上から順に実行します。また、print は実行のたびに出力の最後に改行を行います。この結果上記のように 2 つの出力要素が順番に 2 行にわたって出力されます。
スペース区切りの出力
print は複数の要素を受け取ることができます。
print("Hello, world!", 123)
実行結果
Hello, world! 123
このプログラムでは半角カンマ , 区切りで 2 つの要素を print に渡しました。この場合、渡した要素を順にスペース区切りで 1 行で出力されます。
なお、要素が 3 つ以上でも同様にすべての要素を順にスペース区切りで出力できます。コードテストから試してみてください。
print の機能を用いる方法
改行区切りで出力する別の方法として、以下のように print の機能を用いる方法があります。
print("Hello, world!", 123, sep="\n")
実行結果
Hello, world! 123
このプログラムでは print に sep="\n" という要素を追加で指定しています。この sep= は「複数要素の間に挿入する文字列」を指定します。この例だと 2 つの要素の間に改行文字 "\n" を挿入することになり、上記のような実行結果が得られます。
スペース区切りで出力する別の方法もあります。以下のように記述します。
print("Hello, world!", end=" ")
print(123)
実行結果
Hello, world! 123
このプログラムでは print に end=" " という要素を追加で指定しています。この end= は「出力後に挿入する文字列」を指定します。この例だと出力後に半角スペースを挿入することになり、上記のような実行結果が得られます。
スペース区切り、改行区切りそれぞれについて 2 通りの方法を紹介しました。難しく感じる場合、慣れないうちは自分の分かりやすい方法だけを使っていれば問題ありません。
もし print の動作仕様について正確な情報が知りたい場合は Python の公式ドキュメント を参照してみてください。
より複雑な要素の出力
より複雑な要素を出力したい場合、print の書き方を工夫するのではなく、出力したい要素を文字列として構築し、その文字列を print で出力する、という方法を取ることになります。
本教材の後半で文字列の処理を学べば、より複雑な出力を行うことができるようになります。
コメント
コメントは人間が「プログラムがどういう動作をしているか」等のメモ書きをプログラム中に残しておくための機能です。
プログラムとしての意味はないので、書いても動作に影響はありません。
2 種類のコメントの書き方
例を見てみてみましょう。
# 123 # 456 # と出力するプログラムです print(123) print(456) """ print は受け取った要素を出力する 最後に改行が自動で挿入される """
実行結果
123 456
1-3行目に # から始まる行はコメントで、プログラムの動作には影響しません。
7-10行目の """ で挟まれた部分も同様にコメントです3。
コメントアウト
一時的に実行させたくない部分をコメントにしてしまうことで、その部分のプログラムを無効化するというテクニックがあります。このテクニックは コメントアウト と呼ばれ、よく使われます。
# print(123) print(456)
実行結果
456
1行目の処理はコメント扱いで実行されないため、123 は出力されません。
123 を出力したくなった場合はコメントを解除すればよい (# を消せば良い) ため、書き直しの手間は小さいです。
注意点
全角スペース
Python は全角文字を扱うことは可能ですが、プログラムの中に全角スペース「 」が入っているとエラーになってしまいます。発見が難しいため注意してください。
書き出し位置
Python では各行の書き出し位置に規則が存在します。特に、今回書くような単純なプログラムではすべての行が行の左端に位置している必要があります。
行の先頭には (全角スペースは勿論ですが) 半角スペースも記述しないように注意してください。
問題
リンク先の問題を解いてください。
EX1.コードテストと出力の練習
-
人によります。 ↩
-
より具体的には、組み込み関数という Python が提供する仕組みになります。組み込み関数については 1.12.組み込み関数で扱います。 ↩
-
厳密には複数行にわたる文字列ですが、コメントを書くために利用されることも多い記法です。 ↩
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- Python プログラムを書く際には行の書き出し位置・改行などのルールに従う必要がある
- 読み込み時エラーとは Python プログラムの記述ルールに従っていない場合に起こるエラーのことで、プログラム自体が実行されない
- 実行時エラーとはプログラムの処理が継続できない事象が生じた場合に起こるエラーのことで、プログラムが異常終了する
- 論理エラーとはプログラムの動作が意図したものと異なる場合に起こるエラーのことで、プログラムの実行は問題なく終了するため発見が難しい
- 読み込み時エラーや実行時エラーが出たときはエラーメッセージをよく読み、少しずつ慣れていくことが重要
プログラムの書き方
プログラムは通常の文章を書くときには無いルールが存在します。他の言語と異なる Python 特有の事情も存在しますので、基本的なルールを紹介していきます。
行の書き出し位置とインデント
Python は各行の書き出し位置を揃える必要があります。理由も無く行の書き出し位置がずれるとエラーになるため、行の先頭に余分なスペースが入らないように注意してください。
逆に、後の節で扱う「構文を表すキーワード + コロン」を記述した場合、次の行では書き出し位置を右にずらす (インデントする) 必要があります。
参考までに、インデントしている部分を含むコードの例を紹介します (現時点で意味が分かる必要はありません)。
# 何もない行は左詰め
print("hoge")
def function():
# 関数定義のコロンの後、インデントする
# 複数行記述する場合、ずっとインデントしたまま
print("foo")
return 0
for i in range(10):
# for 文のコロンの後、インデントする
print("bar")
for j in range(10):
# 二重 (以上) にインデントすることもある
print("baz")
C++などの他の言語では見やすくするためにインデントを行いますが、Python ではルールとして強制的にインデントを行う点が特徴的です1。
改行について
Python では実行文2同士を区切るために改行もしくはセミコロン ; を使用します。
今まで print を複数記述する際には必ず改行をはさんでいましたが、次のようにセミコロン ; を使って複数の実行文を 1 行にまとめて記述することも可能です。
print("hello"); print(123)
実行結果
hello 123
逆に、1 つの実行文を複数の行に分けて記述したい場合、バックスラッシュ \ を用いて次のように書くことができます。次の例は 1 から 8 までの整数を足し合わせた結果を表示するプログラムです。足し合わせる数が多いため、途中でバックスラッシュを用いて改行をはさんでいます。
res = 1 + 2 + 3 + 4 \
+ 5 + 6 + 7 + 8
print(res)
実行結果
36
一部のケースではバックスラッシュなしで改行をはさむことができます。具体的には、丸カッコ () や四角カッコ []、波カッコ {} などの内側です。次のような書き方のイメージになります(意味は気にしなくて構いません)。
print(
123,
"hoge",
"foo",
sep="\n"
)
lst = [
10,
20,
30
]
カッコの中身は記述が長くなりやすいため、改行を使うことで読みやすいコードになります。
スペースについて
Python では記述する要素同士の切れ目には半角スペースを何個でも置くことができます。
print(123, 456 , 789)
注意として、半角スペースでなく全角スペースを記述するとエラーとなってしまうので気をつけてください。
プログラムのエラー
プログラムは書き終わったら完成ではありません。動かしてみてその動作が正しいことを確認して、はじめて完成と言えます。
しかし書き終えたばかりのプログラムを実行しようとすると、たいてい何らかのエラーが発生します。そのときにエラーの原因を理解して修正できることも重要なスキルです。
Python プログラムのエラーは次の3つに大別できます。
- 読み込み時エラー
- 実行時エラー
- 論理エラー
それぞれについて説明します。
読み込み時エラー
書いたプログラムの文法にミスがあるときに発生するエラーです。
全角スペースがプログラム中に入り込んだり、インデントが不正である場合、コードを読み込んだ時点でエラーになります。
プログラミング言語では「文法」が厳密に決められています。
日本語などの人間が使う言語では、文法的に少し崩れた文でも意図が通じますが、プログラミング言語ではそうはいきません。
読み込み時エラーが起きた場合、プログラムは一切動作しません。AtCoder のジャッジの実行結果は CE となります。
実行時エラー
「プログラムを動かす」ことを「プログラムを実行する」といいます。
実行時エラーとは、プログラムの文法に間違いはなかったが、内容に致命的な間違いがあったときに発生するエラーです。
具体的には3÷0のように、0で割り算を行ってしまった場合や、書き間違い (print を pritn と書くなど) で存在しない要素を記述した場合などに発生します。
スマホアプリやゲーム等が強制終了してしまったとき、多くの場合実行時エラーが発生しています。
実行時エラーが起きた場合、実行時エラーが起きる直前までプログラムは動作しますが、エラー以降は動かなくなってしまいます。AtCoder のジャッジの実行結果は RE となります。
論理エラー
論理エラーとは、プログラムは一見正しく動作しているが、その動作が実は正しくないときに発生するエラーです。
例えば、「300円のクッキーと100円のアメを買ったときに払うお金」を計算するプログラムでは300 + 100と計算するべきですが、間違って300 - 100としてしまった場合などは論理エラーに当たります。
論理エラーは勘違いで生まれたり、タイピングのミスで発生したりと様々です。
論理エラーは一見問題なくプログラムが動作しますが、意図と異なる結果を返すため、発見することが難しくなりやすいです。AtCoder のジャッジの実行結果は(偶然実行結果が合うということが無い限りは) WA となります。
エラーの例
この時点でよく遭遇すると思われるエラーを紹介します。
全角スペース
次のコードには文末に全角スペースが入っており、SyntaxError という読み込み時エラーとなっています。エラー文の中で U+3000 と記述されているものが全角スペースに相当します。記述されている箇所も教えてくれるため、修正は容易です。
print(123) # (123) の後に全角スペースがある
File "Main.py", line 1
print(123)
^
SyntaxError: invalid non-printable character U+3000
カッコの閉じ忘れ
開きカッコに対応する閉じカッコがない場合、SyntaxError となります。
print(123
File "Main.py", line 1
print(123
^
SyntaxError: '(' was never closed
インデントのミス
理由もなくインデントしてしまうと IndentationError という読込み時エラーが発生します。
print(123) print(456)
Sorry: IndentationError: unexpected indent (Main.py, line 2)
スペルミス
書き間違いなどで存在しない名称3を記述してしまった場合、NameError という実行時エラーになります。次のエラーでは pritn という名称は存在しないということと、print の書き間違いではないか?というヒントを与えてくれています。
pritn(123)
Traceback (most recent call last):
File "/judge/Main.py", line 1, in <module>
pritn(123)
^^^^^
NameError: name 'pritn' is not defined. Did you mean: 'print'?
エラーへの対処
プログラムにエラーはつきものなので、うまく付き合う必要があります。以下でエラーへの対処方法、心構えについて紹介します。
エラーをよく読む
Python の場合末尾にエラーの要点が書かれていることが多いです。大量のエラーが表示された場合読みたくなくなりますが、まずエラーの最後を見て大意がつかめないかトライしてみてください。
具体的な行数や箇所の表示を見て不自然な点が無いか確認してみるのもよいでしょう。
検索する
初心者の段階で遭遇するエラーはよくあるものが多いので、検索すればすぐにわかるケースも多いと思われます。
検索する場合はエラーの末尾の部分など、自分の環境固有の記述が含まれない部分を検索ワードに設定するとよいでしょう。
エラーの利点?
書くたびにエラーが出てうまく動かないと嫌な気持ちになるかもしれませんが、考えようによってはミスを Python の実行プログラムが教えてくれているだけ有益ともとれます。
前述の論理エラーのような「表示されないエラー」はミスが明らかにならないため発見が遅れ、大きなバグに繋がってしまうこともあります。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
| 演算子 | 計算内容 |
|---|---|
+ |
足し算 |
- |
引き算 |
* |
掛け算 |
// |
割り算(整数) |
/ |
割り算(実数 1 ) |
** |
べき乗 |
% |
割った余り |
(注)割り算の記号がふたつありますが、 // は整数での除算(切り捨て除算)、 / は実数(float)での除算です。違いについては後の例で説明します。
足し算・引き算・掛け算
Python で足し算・引き算・掛け算を行う場合は、 + - * を使います。
print(7 + 2) # 9 print(7 - 2) # 5 print(7 * 2) # 14
実行結果
9 5 14
割り算
割り算については少し注意が必要です。 // は整数範囲での割り算を計算し、切り捨てされた結果を整数として返します。一方で、 / は実数で計算した結果を(次節1.04変数と型で扱う float 型で)返します。
print(7 // 2) # 3 print(7 / 2) # 3.5
実行結果
3 3.5
切り捨て除算は、負の数を割った場合も小さくなる方向(絶対値が大きくなる方向)に丸められます。
print(-7 // 2) # -4 print(-7 / 2) # -3.5
実行結果
-4 -3.5
べき乗
べき乗の計算(指数計算)は ** を使います。次のプログラムでは、 7 の 2 乗である 49 が出力されます。
print(7 ** 2)
実行結果
49
剰余演算
最後に、剰余演算(割った余りを計算する演算)です。 7 を 2 で割った余りは 1 なので、以下のプログラムでは 1 が出力されます。
print(7 % 2)
実行結果
1
負の数の切り捨て除算は、小さい方(絶対値が大きい方)に丸められると説明しましたが、剰余演算もそれと整合的に計算されます。より具体的には、正の整数の除算では a を b で割った商を q 、余りを r とすると a = b \times q + r\ (0\le r<b) が成立しますが、 a が負の数の場合も b が正であればこれが成立します。
例えば -11 を 5 で割ると -3 あまり 4 という計算になります。上の式に当てはめると -11 = 5 \times (-3) + 4 が成立することが確認できます。
print(-11 // 5)
print(-11 % 5)
実行結果
-3 4
演算子の優先順位
演算子には優先順位があります。
例えば 1 + 2 * 3 のような式を書いた場合、先に 2 \times 3 が計算された後に 1 が足され、計算結果は 7 になります。 * の優先順位が + より高いということです。
上で紹介した演算子の優先順位は次のとおりです。
| 優先順位 | 演算子 |
|---|---|
| 高 | ** |
| 中 | * // / % |
| 低 | + - |
print(3 + 4 * 5) # 4 * 5 を先に計算する print(5 * 3 ** 2) # 3 の 2 乗を先に計算する
実行結果
23 45
同じ優先順位の演算子が並んでいる場合は、左から順に計算されます。
括弧 ( ) を使うと、括弧で括った部分が先に計算されます。
print(4 * (1 + 2)) # 括弧の中の 1 + 2 を先に計算する print(3 * 5 // 2) # 3 * 5 の結果を先に計算する
実行結果
12 7
注意点
ゼロ除算
ゼロで割り算を行おうとするとランタイムエラーになります。
次のコードはいずれもランタイムエラーになり、 AtCoder のジャッジだと RE が表示されてしまいます。
print(3 / 0)
print(3 // 0)
print(3 % 0)
割り切れる場合の実数除算
割り算をする際、たとえば 6 \div 3 のように割り切れる計算の場合、数学的には切り捨て除算と実数除算は同じ結果になりそうです。 Python では割り切れる場合であっても結果は少し異なります。具体的には、次節1.04変数と型で説明する「型」が変わます。
print(6 // 3) print(6 / 3)
実行結果
2 2.0
この例では、(数学的な値としては)いずれも 2 と等しいですが、場合によっては有効桁数の関係で値が変わることもあります。競技プログラミングでもこれによる失敗をするケースがあります。整数範囲で考えている場合は整数除算 // を使うのが無難です。
発展的な内容
負の除数による除算
競技プログラミングでは敢えて除数を負にする必要があるケースはあまり見かけませんが、思わぬ罠になる可能性があるので、プログラムの挙動について説明しておきます。
a を b で割った商を q 、余りを r とします。 b が正のときは a = b \times q + r\ (0\le r<b) が成立すると説明しましたが、除数 b が負のときは余りの範囲も負の方向になり、 a = b \times q + r\ (b < r \le 0) を満たすように商・余りが決まります。
11=(-5)\times(-3)+(-4) より、11 を -5 で割った商は -3 、余りは -4 となります。
-11=(-5)\times 2+(-1) より、-11 を -5 で割った商は 2 、余りは -1 となります。
print(11 // -5)
print(11 % -5)
print(-11 // -5)
print(-11 % -5)
実行結果
-3 -4 2 -1
divmod
a を b で割った商は a // b 、余りは a % b で取得できることは既に学びましたが、 divmod 関数を使うことでこれらを同時に取得することもできます。
具体的には、 divmod(a, b) で a を b で割った商と余りのタプルを返します。「タプル」についてはまだ扱っていないので詳細は省略しますが、次のようなコードで取得できることを覚えておけば十分です。
q, r = divmod(20, 7) print(q) print(r)
実行結果
2 6
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
| 型 | 書き込むデータの種類 |
|---|---|
| int | 整数 |
| float | 実数(浮動小数点数) 1 |
| str | 文字列 |
変数について
変数は「メモ」だと考えてください。一度使ったデータをまた後で使いたいときのために、名前を付けてメモをして覚えておくというものです。
「変数の名前」のことを 変数名 と言います。次の例では、整数 10 というデータを name という変数に格納(メモ)して、あとから呼び出して使用しています。
name = 10 print(name) print(name + 2) print(name * 2)
実行結果
10 12 20
型について
「データの種類」のことを 型(かた) と言い、変数はいずれかの型を持ちます。
なお、前節までは変数を使わず print(123) などのようにプログラムに直接整数などを書き込んでいましたが、実はこの 123 などにも型があり、この場合は整数型になっています。
以下に Python でよく使う型を挙げます。
int(整数型)
3 や -10 などの整数を表すことができます。
float(浮動小数点数型)
3.5 などの実数 1 を表すことができます。
str(文字列型)
"a" や "Hello" などの文字列を表すことができます。
代入
変数には値を代入することができます。代入するときは代入演算子「=」を使い、左側に代入先の変数を、右側に代入する値を書きます。複数回代入すると、前の値が上書きされます。
x = 3 # 変数 x に整数 3 が代入される y = -7.3 # 変数 y に浮動小数点数 -7.3 が代入される z = "ABC" # 変数 z に文字列 "ABC" が代入される x = 10 # 変数 x に 10 が代入される(上書きされる)
値が代入された変数は、以下のように呼び出すことで使うことができます。
x = 3 y = -7.3 z = "ABC" print(x * 2) print(y * 3) print(z)
実行結果
6 -21.9 ABC
= の右側は、変数や演算子を含んでいても構いません。
x = 3 y = x # y に x の値である 3 が代入される z = x * 10 + 2 # x * 10 + 2 の計算結果が代入される print(y) print(z)
実行結果
3 32
なお Python の = は代入を意味していて、「等しい」という意味ではないということに注意してください。
指数表記
float 型では指数表記による記述もできます。絶対値が大きいまたは小さい数の場合は、 print 関数で出力した結果も指数表記になります。
x = 1.23e5 y = 3.5e-2 z = 2.7e-10 print(x) print(y) print(z)
実行結果
123000.0 0.035 2.7e-10
変数の型の宣言について
勘の良い方は、変数がどの型になるのかを書かなくて良いのか気になったかもしれません。実は Python ではユーザーが変数の型を指定(宣言)する必要はなく、プログラムで自動的に判定されます。具体的には、代入するもの(= の右側)の型によって決まります。このため、同じ変数を別の型で上書きするということもできます。
x = 3 print(x) x = "AtCoder" print(x)
実行結果
3 AtCoder
複合代入演算子
「x に 5 を足す」のような、計算結果を同じ変数に代入する操作は、 x += 5 のように書くことができます。これは x = x + 5 と書いたことと同じ結果になります。
x = 2 x += 5 print(x)
実行結果
7
+= のような演算子を 複合代入演算子 と言います。前節で扱った演算子は、すべて = を付けることで複合代入演算子として使えます。
| 複合代入演算子 | コード例 | 複合代入演算子を使わない書き方 |
|---|---|---|
+= |
x += 3 |
x = x + 3 |
-= |
x -= 3 |
x = x - 3 |
*= |
x *= 3 |
x = x * 3 |
//= |
x //= 3 |
x = x // 3 |
/= |
x /= 3 |
x = x / 3 |
**= |
x **= 3 |
x = x ** 3 |
%= |
x %= 3 |
x = x % 3 |
例えば次のように書くことができます。
x = 2 x += 5 # 7 x *= 3 # 21 x //= 2 # 10 x **= 3 # 1000 x %= 300 # 100 x -= 20 # 80 print(x)
実行結果
80
複数の変数への代入
変数 x に 2 を、変数 y に 3 を代入するという操作を同時に行いたいときは、カンマ(,)で区切って次のように書くことができます。
x, y = 2, 3 print(x) print(y)
実行結果
2 3
これを使うと、 x と y の値を入れ替える(Swap する)という操作も簡単に書くことができます。
x = 2 y = 3 x, y = y, x # x と y を入れ替える print(x) print(y)
実行結果
3 2
有効数字・範囲
int 型
Python の int 型は 多倍長整数 と呼ばれていて、多くのプログラミング言語の int 型のような大きさの制限(32 bit や 64 bit など)がありません。例えば、 3 の 1000 乗は 478 桁のとても大きな整数ですが、下記のように簡単に計算することができます 2 。
print(3 ** 1000)
実行結果
1322070819480806636890455259752144365965422032752148167664920368226828597346704899540778313850608061963909777696872582355950954582100618911865342725257953674027620225198320803878014774228964841274390400117588618041128947815623094438061566173054086674490506178125480344405547054397038895817465368254916136220830268563778582290228416398307887896918556404084898937609373242171846359938695516765018940588109060426089671438864102814350385648747165832010614366132173102768902855220001
float 型
float 型では、 10 進法で 15~16 桁程度(2 進法で 53 ビット)の有効数字で計算されます。これよりも高い精度が求められる場合は予期せぬ結果になることがあるので注意が必要です。
print(100 / 3)
実行結果
33.333333333333336
なお、浮動小数点数で表せる最大の数は約 1.8\times 10^{308} 程度、最小の数は約 -1.8\times 10^{308} 程度、最小の正の数は約 2.2\times 10^{-308} 程度です。
発展的な内容
異なる型同士の演算
前項で四則演算などの演算を学びました。その際は細かく触れませんでしたが、元の変数の型や値によって計算結果として返される型も自動的に決まります。異なる型同士の演算の場合は(同じ型同士の演算であっても場合によっては)注意が必要になります。ここですべてのパターンを網羅することはできませんが、いくつか例を挙げておきます。
int 型同士の和・差・積
整数(int)型同士の和・差・積は整数(int)型になります。
a = 7 b = 2 print(a + b) # 整数型の 9 print(a - b) # 整数型の 5 print(a * b) # 整数型の 14
実行結果
9 5 14
float 型同士の和・差・積
浮動小数点数(float)型同士の和・差・積は浮動小数点数(float)型になります。
a = 3.2 b = 2.5 print(a + b) print(a - b) print(a * b)
実行結果
5.7 0.7000000000000002 8.0
int 型と float 型の和・差・積
片方が int 型、片方が float 型の場合の和・差・積は float 型になります。 3.5 \times 4 は数学的には整数 14 になりますが、 Python のプログラムは float 型として返します。
a = 3.5 b = 4 print(a + b) print(a - b) print(a * b)
実行結果
7.5 -0.5 14.0
int 型同士のべき乗
a と b がともに int 型のとき、 a ** b の型はどうなるでしょうか。簡単のため a はゼロではないとします。
この場合は b \ge 0 の場合は int 型、 b < 0 の場合は float 型になります。
print(2 ** 3) print(2 ** -3)
実行結果
8 0.125
問題
リンク先の問題を解いてください。
EX4.◯年は何秒?
-
前節1.03四則演算と優先順位の注にも書きましたが、正確には実数ではなく浮動小数点数を表します。簡単のためここでは実数と記載しています。 ↩↩
-
ただしあまりに大きい場合は実行時間やメモリの関係で計算が行えない場合があります。手元環境で実行する際など、 PC の限界を超えるとクラッシュしてしまう可能性があるので注意してください。 ↩
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
変数 = input()で入力を文字列として受け取ることができる- 整数として受け取るためには
変数 = int(input())とする
- 整数として受け取るためには
- 1 行をまとめてひとつの文字列として受け取る
- 空白で区切って複数の文字列として受け取るためには
変数1, 変数2 = input().split()などとする
- 空白で区切って複数の文字列として受け取るためには
入力の受け取り方
プログラムの実行時にデータの入力を受け取る方法を見ていきましょう。
「入力機能」を使うことにより、プログラムを書き換えなくても与える入力を変えることで様々な計算を行えるようになります。
入力を受け取るには input() を使います。
次のプログラムは、入力として受け取った文字列を 3 回出力するプログラムです。
s = input() print(s) print(s) print(s)
入力
Pythonだいすき
実行結果
Pythonだいすき Pythonだいすき Pythonだいすき
文字列以外の入力
入力を文字列以外の形式で扱いたいときは、入力を受け取った後に変換する必要があります。
次のプログラムは、入力として受け取った整数を 10 倍したものを出力するプログラムです。
# 入力を文字列として受け取る a = input() # 文字列として受け取った入力を整数に変換する a = int(a) print(a * 10)
入力
5
実行結果
50
上のプログラムは、以下のように「入力を文字列として受け取り整数に変換する部分」をまとめて書くこともできます。
# 入力を整数として受け取る a = int(input()) print(a * 10)
入力
5
実行結果
50
入力を小数として受け取りたい場合も、float() を使って以下のように書くことができます。
# 入力を小数として受け取る a = float(input()) print(a * 10)
入力
3.14
実行結果
31.4
複数行の入力
input() は 1 行の入力を受け取るものなので、input() を行数分書くことで複数行の入力を受け取ることができます。
s = input() a = int(input()) print(s, a * 10)
入力
Hello 5
実行結果
Hello 50
空白区切りの入力
前述のように、input() は 1 行の入力を文字列として受け取ります。
s = input() print(s)
入力
10 20 30
実行結果
10 20 30
そのため、空白区切りの入力を受け取ると、上のように "10 20 30" というひとまとまりの文字列として受け取ってしまいます。
そこで、次のプログラムのように input() で受け取った文字列を split() で空白区切りで分解することで別々の変数に格納することができます。
a, b, c = input().split() print(a) print(b) print(c)
入力
10 20 30
実行結果
10 20 30
このままだと文字列として扱っていますが、次のプログラムのように int() を使って整数に変換することもできます。
a, b, c = input().split() a = int(a) b = int(b) c = int(c) print(a * 10) print(b * 100) print(c * 1000)
入力
10 20 30
実行結果
100 2000 30000
上のプログラムは、以下のように「入力を空白区切りで分割し整数に変換する部分」をまとめて書くこともできます。
map(int, input().split()) の意味については今の時点では理解する必要はありません。このまま覚えてしまっても良いでしょう。
a, b, c = map(int, input().split()) print(a * 10) print(b * 100) print(c * 1000)
入力
10 20 30
実行結果
100 2000 30000
また、split() は以下のように区切り文字を指定することもできます。
これまでのように何も指定しない場合は、空白文字で区切られます。
a, b, c = input().split(":")
print(a)
print(b)
print(c)
入力
10:20:30
実行結果
10 20 30
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
if文を使うと、「指定した条件に当てはまるときだけ処理をする」というプログラムを書けるelifやelseを使うと、「条件に当てはまらなかったとき」の処理を書ける
if 条件式1:
処理1 (条件式1に当てはまるときに実行)
elif 条件式2:
処理2 (条件式1に当てはまらず、条件式2に当てはまるときに実行)
else:
処理3 (条件式1にも条件式2にも当てはまらないときに実行)
- 一般的な比較演算子のまとめ
| 演算子 | 意味 |
|---|---|
x == y |
x と y は等しい |
x != y |
x と y は等しくない |
x > y |
x は y より大きい |
x < y |
x は y より小さい |
x >= y |
x は y 以上 |
x <= y |
x は y 以下 |
- 一般的な論理演算子のまとめ
| 演算子 | 意味 | 真になるとき |
|---|---|---|
not 条件式 |
条件式 の真偽の反転 |
条件式 が偽 |
条件式1 and 条件式2 |
「条件式1 が真」かつ「条件式2 が真」 |
条件式1 と 条件式2 のどちらも真 |
条件式1 or 条件式2 |
「条件式1 が真」または「条件式2 が真」 |
条件式1 と 条件式2 の少なくとも片方が真 |
if 文
if 文を使うと、ある条件が正しいとき(当てはまるとき)だけ処理をするプログラムを書くことができます。
書き方は次のとおりです。
if 条件式:
処理
条件式が正しいとき、: 以降のインデントが下がった部分の処理が実行され、条件式が正しくないとき、処理は飛ばされます。
次のプログラムは、入力の値が 10 より小さければ「x は 10 より小さい」と出力した後「終了」と出力します。入力の値が 10 より小さくなければ「終了」とだけ出力します。
x = int(input())
if x < 10:
print("x は 10 より小さい")
print("終了")
入力 1
5
実行結果 1
x は 10 より小さい 終了
入力 2
15
実行結果 2
終了
この例では、まず x = int(input()) の部分で入力された値を整数として変数 x に代入しています。
重要なのはその後です。
if x < 10:
print("x は 10 より小さい")
この部分は、「もし x < 10(x が 10 より小さい)ならば x は 10 より小さい と出力する」という意味になります。
最後に print("終了") の部分で 終了 と出力します。
x が 10 より小さくない場合、以下の部分は飛ばされます。
print("x は 10 より小さい")
そのため、2 つ目の実行例では 終了 とだけ出力されています。
また、以下のプログラムのように if 文の中の処理は複数行にわたって書くこともできます。
x = int(input())
if x < 10:
print("x は 10 より小さい")
print(x)
print("終了")
if 文のように、ある条件を満たすかどうかで実行する処理を変えることを条件分岐といいます。
また、「条件式が正しい(条件式が当てはまる)」ことを条件式が真、「条件式が正しくない(条件式が当てはまらない)」ことを条件式が偽といいます。
比較演算子
if 文のところで使った条件式 x < 10 は、比較演算子のひとつです。
一般的な比較演算子には以下の 6 つがあります。
| 演算子 | 意味 |
|---|---|
x == y |
x と y は等しい |
x != y |
x と y は等しくない |
x > y |
x は y より大きい |
x < y |
x は y より小さい |
x >= y |
x は y 以上 |
x <= y |
x は y 以下 |
「x と y は等しい」は「x == y」と = を 2 つ繋げたもので表し、「x と y は等しくない」は「x != y」と表します。
「x は y より大きい」「x は y より小さい」は、数学での記号と同じく >, < で表します。
「x は y 以上」「x は y 以下」は、数学では \geqq, \leqq のように = を下につけますが、Python では = を右につけることで表します。
次のプログラムは、入力された整数値がどのような条件を満たしているかを出力するプログラムです。
x = int(input())
if x < 10:
print("x は 10 より小さい")
if x >= 20:
print("x は 20 以上")
if x == 5:
print("x は 5")
if x != 100:
print("x は 100 ではない")
print("終了")
入力 1
5
実行結果 1
x は 10 より小さい x は 5 x は 100 ではない 終了
入力 2
100
実行結果 2
x は 20 以上 終了
論理演算子
条件式の部分にはもっと複雑な条件を書くこともできます。そのためには論理演算子を使います。
論理演算子には以下の 3 つがあります。
| 演算子 | 意味 | 真になるとき |
|---|---|---|
not 条件式 |
条件式 の真偽の反転 |
条件式 が偽 |
条件式1 and 条件式2 |
「条件式1 が真」かつ「条件式2 が真」 |
条件式1 と 条件式2 のどちらも真 |
条件式1 or 条件式2 |
「条件式1 が真」または「条件式2 が真」 |
条件式1 と 条件式2 の少なくとも片方が真 |
x, y = map(int, input().split())
if not x == y:
print("x と y は等しくない")
if x == 10 and y == 10:
print("x と y は 10")
if x == 0 or y == 0:
print("x か y は 0")
print("終了")
入力 1
2 3
実行結果 1
x と y は等しくない 終了
入力 2
10 10
実行結果 2
x と y は 10 終了
入力 3
0 8
実行結果 3
x と y は等しくない x か y は 0 終了
「前の条件が真でないとき」の処理
else 節
else 節は、if 文の後に書くことで、「if 文の条件が偽のとき」に処理を行えるようになります。
書き方は次のとおりです。
if 条件式:
処理1
else:
処理2
次のプログラムは、入力の値が 10 より小さければ「x は 10 より小さい」と出力し、そうでなければ「x は 10 より小さくない」と出力します。
x = int(input())
if x < 10:
print("x は 10 より小さい")
else:
print("x は 10 より小さくない")
入力 1
5
実行結果 1
x は 10 より小さい
入力 2
15
実行結果 2
x は 10 より小さくない
elif 節
elif 節は「「前の if 文の条件が偽」かつ「elif 節の条件が真」」のときに処理が行われます。
書き方は次のとおりです。
if 条件式1:
処理1
elif 条件式2:
処理2
処理2が実行されるのは「条件式1が偽 かつ 条件式2が真」のときになります。
また、elif 節のあとに続けて elif 節や else 節を書くこともできます。
次のプログラムはその例です。
x = int(input())
if x < 10:
print("x は 10 より小さい")
elif x > 20:
print("x は 10 より小さくなくて、20 より大きい")
elif x == 15:
print("x は 10 より小さくなくて、20 より大きくなくて、15 である")
else:
print("x は 10 より小さくなくて、20 より大きくなくて、15 でもない")
入力 1
5
実行結果 1
x は 10 より小さい
入力 2
30
実行結果 2
x は 10 より小さくなくて、20 より大きい
入力 3
15
実行結果 3
x は 10 より小さくなくて、20 より大きくなくて、15 である
入力 4
13
実行結果 4
x は 10 より小さくなくて、20 より大きくなくて、15 でもない
if 文のネスト
if, elif, else などの節の中にさらに if 文を入れることで、より複雑な条件分岐をすることもできます。
x = int(input())
if x % 2 == 0:
if x % 3 == 0:
print("x は 2 の倍数でも 3 の倍数でもある")
else:
print("x は 2 の倍数ではあるが 3 の倍数ではない")
else:
if x % 3 == 0:
print("x は 2 の倍数ではないが 3 の倍数ではある")
else:
print("x は 2 の倍数でも 3 の倍数でもない")
入力 1
12
実行結果 1
x は 2 の倍数でも 3 の倍数でもある
入力 2
14
実行結果 2
x は 2 の倍数ではあるが 3 の倍数ではない
入力 3
15
実行結果 3
x は 2 の倍数ではないが 3 の倍数ではある
入力 4
17
実行結果 4
x は 2 の倍数でも 3 の倍数でもない
比較演算子の連鎖
次のプログラムは、x が 0 以上 100 以下かどうかを調べるプログラムです。
x = int(input())
if 0 <= x and x <= 100:
print("x は 0 以上 100 以下です")
else:
print("x は 0 以上 100 以下ではありません")
上のプログラムの 0 <= x and x <= 100 の部分を、Python では次のプログラムのように 0 <= x <= 100 と書くこともできます。
x = int(input())
if 0 <= x <= 100:
print("x は 0 以上 100 以下です")
else:
print("x は 0 以上 100 以下ではありません")
また、a < b < c < d のように 3 つ以上繋げて書いたり、a < b > c のように異なる演算子についても繋げて書くことができます(a < b > c は a < b and b > c と同じ意味です)。
💡 ちなみに
この書き方は、あまり濫用するとかえってわかりづらくなってしまうので注意が必要です。例えば、a != b != c と書いたとき、これは a != b and b != c と同じ意味なので、a と c が異なるかどうかを判定していません。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 条件式の値は bool 型という型の値である。
- bool 型は
True(真) とFalse(偽) の2種類の値のいずれかを取る型である。 - 数値や文字列など色々な値は条件式の値として用いることができる。結果は型ごとにルールが決まっている。
- 数値の場合、
0でなければTrue - 文字列の場合、
""(空文字列) でなければTrue
- 数値の場合、
条件式の結果
1.06節では if x == 0: のように if 文を用いることで条件分岐を記述できる、ということを扱いました。じつはこの「x == 0」の部分自体が値を持っています。このことを確認してみましょう:
x = 0 print(x == 0) # 「x が 0 と等しいかどうか」を出力 print(x >= 1) # 「x が 1 以上かどうか」を出力
実行結果
True False
条件式が成り立っている場合の値は "True"、成り立っていない場合は値は "False" と出力されました。これらは、それぞれ日本語でいうところの「真」「偽」に相当します。条件式は、それが成り立っている場合は真、成り立っていない場合は偽、という値を持っている、ということになります。
条件式の結果は値を持つので、これを変数に格納したり、格納した変数同士で演算を行うことも可能です。以下の例では条件式の値を変数 a, b に代入し、それらの論理演算を行っています。
x = 5 a = 0 <= x # a に「xが0以上か」の条件式の値を代入 (ここでは True) b = x <= 10 # b に「xが10以下か」の条件式の値を代入 (ここでは True) c = a and b # c に「a かつ b か」の論理演算式の値を代入 print(a,b,c)
実行結果
True True True
bool 型
True と False
先程出力された条件式の値である True False は bool型というデータ型の値です。bool型はこれらTrue (真) もしくは False (偽) の2種類の値のみを取ります。
bool 型の値は、前節のように条件式を記述する以外にも、True False を直接記述することでも表現することができます。
if True:
print("条件が成り立っています")
if False:
print("条件が成り立っています")
else:
print("条件が成り立っていません")
実行結果
条件が成り立っています 条件が成り立っていません
他の型からの変換
実は if 文の条件式には True False 以外の値を与えることも可能です:
if 10:
print("10 は True 扱い")
if not 0:
print("0 は False 扱い")
if -1:
print("-1 は True 扱い")
実行結果
10 は True 扱い 0 は False 扱い -1 は True 扱い
上記のように数値を条件式に与えた場合、「値が0でなければ True、0 と等しければ False」というルールで変換が行われます。このような型の変換のことをキャストと呼びます。上記の例だと int 型が bool 型にキャストされた、ということになります。
キャストは数値以外でも行われます。代表的な例を次の表に記載します:
| 型 | 変換ルール | True となる例 | False となる例 |
|---|---|---|---|
数値 (int, float) |
値が0と等しいときのみ False |
1, 0.01, -1e18 |
0, 0.0 |
| 文字列 | 空文字列 "" のときのみ False |
"hoge", "A", " " |
"" |
| 配列1 | 配列が空 (長さが 0) のときのみ False |
[1,2,3], ["foo"], [0] |
[] |
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- while 文を使うと繰り返し処理ができる
- 条件式が真のとき処理を繰り返す
while 条件式:
処理
- 「N 回処理する」というプログラムを書く場合、「カウンタ変数を 0 からはじめ、カウンタ変数が N より小さいときにループ」という形式で書く
i = 0 # カウンタ変数
while i < N:
処理
i += 1
while 文
while 文を使うと、プログラムの機能の中でも非常に重要な「繰り返し処理」(ループ処理)を行うことができます。
無限ループ
次のプログラムは、「Hello と出力して改行した後、AtCoder と出力する処理」を無限に繰り返すプログラムです。
while True:
print("Hello")
print("AtCoder")
実行結果
Hello AtCoder Hello AtCoder Hello AtCoder Hello AtCoder Hello AtCoder ...(無限に続く)
while 文は次のように書き、条件式が真のとき処理を繰り返し続けます。
while 条件式:
処理
先のプログラムでは条件式の部分に True と書いているため、無限に処理を繰り返し続けます。
このように、無限に繰り返し続けることを無限ループと言います。
1 ずつカウントする
次のプログラムは、1 から順に整数を出力し続けます。
i = 1
while True:
print(i)
i += 1 # ループのたびに 1 増やす
実行結果
1 2 3 4 5 6 7 8 ...(無限に 1 ずつ増えていく)
ループ回数の指定
1 ずつカウントするプログラムを「1 から 5 までの数を出力するプログラム」に変える場合、次のようにします。
i = 1
# i が 5 以下の間だけループ
while i <= 5:
print(i)
i += 1
実行結果
1 2 3 4 5
カウンタ変数は 0 から N 未満まで
5 回 Hello と出力されるプログラムを考えます。
以下では書き方を二つ紹介します。この教材では二つ目の書き方を推奨します。
推奨しない書き方
# i を 1 からはじめる
i = 1
# i が 5 以下の間だけループ
while i <= 5:
print("Hello")
i += 1
実行結果
Hello Hello Hello Hello Hello
「N 回処理をする」というプログラムを while 文で書く場合、今までは「i を 1 からはじめ、N 以下の間ループする」という形式で書いてきました。
i = 1
while i <= N:
処理
i += 1
この形式は一見わかりやすいと感じるかもしれません。
しかし、この書き方はあまり一般的ではなく、次のように書いたほうがより一般的です。
推奨する書き方
# i を 0 からはじめる
i = 0
# i が 5 未満の間だけループ
while i < 5:
print("Hello")
i += 1
実行結果
Hello Hello Hello Hello Hello
「N 回処理する」というプログラムを書く場合、次のように「i を 0 からはじめ、N より小さいときにループする」という形式で書くのがより一般的です。
i = 0
while i < N:
処理
i += 1
最初は分かりづらく感じるかもしれませんが、この形式で書いた方がプログラムをよりシンプルに書けることがあるので、慣れるようにしましょう。
なお、このプログラムの変数 i のように、「何回目のループか」を管理する変数のことをカウンタ変数と呼ぶことがあります。カウンタ変数には慣例的に i を使い、i が使えない場合は j, k, l ... と名前をつけていくことが多いです。
応用例
N 人の合計点を求めるプログラムを作ってみましょう。
次のプログラムは「入力の個数 N」と「点数を表す N 個の整数」を入力で受け取り、点数の合計を出力します。
N = int(input())
s = 0 # 合計点を表す変数
i = 0 # カウンタ変数
while i < N:
x = int(input())
s += x
i += 1
print(s)
入力
3 1 10 100
実行結果
111
合計点を表す変数 s を用意して、ループするたびに入力を変数 x に受け取り s に足しています。
このように、繰り返し処理を使えば様々な処理が行えるようになります。
細かい話
細かい話なので、飛ばして問題を解いても良いです。
2 ずつ増やす
今までは i を 1 ずつだけ増やしてきましたが、2 ずつ増やすこともできます。
i = 0
while i < 10:
print(i)
i += 2
実行結果
0 2 4 6 8
以下のように書くことで i を 2 ずつ増やしています。
i += 2
同様にして、より多く飛ばしてループすることもできます。
逆順ループ
5 から 0 までの数を出力したい場合は以下のようにします。
i = 5
while i >= 0:
print(i)
i -= 1
実行結果
5 4 3 2 1 0
以下のように書くことで i を 1 ずつ減らしています。
i -= 1
無限ループをコードテストで実行した場合
AtCoder のコードテストでは、実行時間が長すぎるとプログラムが中断されます。また、出力が長すぎる場合も途中から省略されます。
そのため、はじめに紹介した「Hello と出力して改行した後、AtCoder と出力する処理」を無限に繰り返すプログラムをコードテストで実行しても無限には出力されず、一例としては次のように表示されます。
実行結果
Hello AtCoder (中略) Hello AtCoder H
終了コード
9
無限ループが発生した場合、終了コードは実行時間が長すぎることを表す 9 となります。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- for 文は繰り返し処理でよくあるパターンを while 文より短く書くための構文
- 列の中身が順に変数に代入される
for 変数 in 列:
処理
- N 回の繰り返し処理は以下の for 文で書くのが一般的
for i in range(N):
処理
breakを使うとループを途中で抜けることができるcontinueを使うと後の処理を飛ばして次のループへ進むことができる
for 文
for 文は列の中身を順に処理するための構文です。
for 文を使うことで「N 回処理する」というような繰り返し処理でよくあるパターンを while 文より短く書くことができます。
3 回繰り返すプログラムを while 文と for 文で書くと次のようになります。
j = 0
while j < 3:
print("Hello while:", j)
j += 1
for i in range(3):
print("Hello for:", i)
実行結果
Hello while: 0 Hello while: 1 Hello while: 2 Hello for: 0 Hello for: 1 Hello for: 2
for 文は次のように書きます。
for 変数 in 列:
処理
列として代表的なものにはリストや文字列が存在しますが、詳しくは後の節で紹介します。
N 回の繰り返し処理
「N 回処理をする」というような繰り返し処理をしたいときは、range() を使うと楽です。range(a, b) と書くことで、(a, a+1, a+2, \dots , b-1) という数列が生成されます。
for i in range(0, 5):
print(i)
実行結果
0 1 2 3 4
range(a, b) の a は 0 のときに省略することができ、range(b) と書くことができます。よって、次の二つの書き方は同じ意味になります。
for i in range(0, 5):
print(i)
for i in range(5):
print(i)
実行結果
0 1 2 3 4 0 1 2 3 4
つまり、「N 回の繰り返し処理」を書きたいときは次のように書けば良いです。
for i in range(N):
処理
break と continue
while 文と for 文を制御する命令として、break と continue があります。
break
break はループを途中で抜けるための命令です。
# break がなければこのループは i == 4 まで繰り返す
for i in range(5):
if i == 3:
print("ぬける")
break # i == 3 の時点でループから抜ける
print(i)
print("終了")
実行結果
0 1 2 ぬける 終了
上のプログラムでは、if 文で i == 3 が真になったとき break 文を実行することで for ループを抜け、終了 と表示しています。
continue
continue は後の処理をとばして次のループへ進むための命令です。
for i in range(5):
if i == 3:
print("とばす")
continue # i == 3 のとき これより後の処理を飛ばす
print(i)
print("終了")
実行結果
0 1 2 とばす 4 終了
上のプログラムでは、if 文で i == 3 が真になったとき continue 文を実行することで continue より下の部分を飛ばし、次のループに進みます。
細かい話
細かい話なので、飛ばして問題を解いても良いです。
2 ずつ増やす
上では range(a, b) という書き方のみ紹介しましたが、実は range(a, b, c) という書き方もできこれによりいくつずつ増やすかを決めることができます(c を省略したときのデフォルトは 1 なので、これまでの書き方では全て 1 ずつ増えていました)。
よって、次のように書くことで 2 ずつ増やすことができます。
for i in range(0, 10, 2):
print(i)
実行結果
0 2 4 6 8
同様にして、より多く飛ばしてループすることもできます。
なお、いくつずつ増やすかを決めるときは a がたとえ 0 だとしても省略できないことに注意してください。つまり、上のコードで range(10, 2) と書くと異なる挙動になってしまいます。
逆順ループ
5 から 0 までの数を出力したい場合は以下のようにします。
for i in range(5, -1, -1):
print(i)
実行結果
5 4 3 2 1 0
0 まで出力したい場合に二つ目の引数を -1 にする必要があることに注意してください。range(5) としたときに(5 までではなく)4 までしか出力されなかったのと同様に、0 まで出力したい場合はひとつ次の -1 を指定する必要があります。
また、もちろん三つ目の引数に -2 などを指定することでより多く飛ばして逆順ループすることもできます。
より一般的に、range(N) を逆順にするときは range(N - 1, -1, -1) と書くことになります。
N = 5
print("昇順")
for i in range(N):
print(i)
print("降順")
for i in range(N - 1, -1, -1):
print(i)
実行結果
昇順 0 1 2 3 4 降順 4 3 2 1 0
for-else, while-else
Python では for 文と while 文に else 節を書くことができます。
これは、ループが break 文で終了した場合は実行されず、そうでないとき(ループが最後まで回ったとき)に実行されます。
break しない場合
for i in range(5):
print(i)
else:
print("ループが最後まで回りました。")
print("終了")
実行結果
0 1 2 3 4 ループが最後まで回りました。 終了
break する場合
for i in range(5):
if i == 3:
print("ぬける")
break # i == 3 の時点でループから抜ける
print(i)
else:
print("ループが最後まで回りました。")
print("終了")
実行結果
0 1 2 ぬける 終了
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- リスト は様々なデータの列を扱うことができる
[要素0, 要素1, 要素2, ...]でリストを作ることができる[0] * Nで N 個の 0 からなるリストを作ることができるa[i]でリスト a の i 番目の要素を取得できるlist(map(int, input().split()))で 1 行の入力から整数のリストを作ることができる- リストと for 文を組み合わせると、大量のデータを扱うプログラムを簡単に書ける
リスト
リスト(配列、list 型) はデータの列を扱うことができる非常に重要な機能です。例えば、以下のようなコードを書くことができます。
# リスト [3, 1, 4, 1, 5] を作り, a に代入する
a = [3, 1, 4, 1, 5]
# a の 0 番目の要素である 3 を出力
print(a[0])
# a の 1 番目の要素である 1 を出力
print(a[1])
# a の 2 番目の要素 (4) を 7 に変更
a[2] = 7
# a の要素を順に出力
for x in a:
print(x)
出力
3 1 3 1 7 1 5
この章では、リストの使い方について説明します。
リストを作る
[]で空のリストを作ることができます。[要素0, 要素1, 要素2, ...]でリストを作ることができます。list( for文に入れられるもの )でリストを作ることができます。- 例えば、
for i in range(5):と書くと i に 0, 1, 2, 3, 4 が順番に入るので、list(range(5))と書くとリスト[0, 1, 2, 3, 4]を作ることができます。
- 例えば、
- 2 章で紹介する リスト内包表記 を使ってもリストを作ることができます。
# 空のリストを作り、a に代入する a = [] # リスト [3, 1, 4, 1, 5] を作り、a に代入する a = [3, 1, 4, 1, 5] # いろいろな型を持つデータを 1 つのリストに入れることができる a = ["Hello", "AtCoder", 123, 4.5, []] # リスト [0, 1, 2, 3, 4] を作る a = list(range(5))
リストの長さ
- リスト a に対し、
len(a)で a の長さ(要素数)を取得できます。
リストの i 番目の要素
- リスト a と整数 i に対し、
a[i]で a の i 番目の要素を取得できます。- この i のこと(リストの何番目の要素かを表す番号)を 添字(そえじ) と言います。
- リストの添字は 0 から始まることに注意しましょう。 先頭の要素は
a[0]で、末尾の要素はa[len(a)-1]で取得することができます。
a[i] = xで a の i 番目の要素を x に変更できます。
# リスト [3, 1, 4, 1, 5] を作り、a に代入する
a = [3, 1, 4, 1, 5]
# a の長さ 5 を出力する
print(len(a))
# a の 2 番目の要素 (4) を 7 に変更する
a[2] = 7
# range(len(a)) と書けば a の添字 (0, 1, 2, 3, 4) を順に列挙できる
for i in range(len(a)):
# a[i] で a の i 番目の要素を取得する
print(i, ":", a[i])
出力
5 0 : 3 1 : 1 2 : 7 3 : 1 4 : 5
for 文でリストの要素を列挙する
- リスト a に対し、
for x in a:で a の要素を順に x に代入して繰り返し処理を行うことができます。
a = [3, 1, 4, 1, 5]
# a の要素を順に x に代入し、繰り返し処理を行う
for x in a:
# 5 回実行される
print(x)
出力
3 1 4 1 5
入力からリストを作る
- 文字列 s に対し、
s.split()で s を空白で区切って文字列のリストを作ることができます。 - 文字列のリスト a に対し、
list(map(int, a))で a の各要素を整数に変換したリストを作ることができます。 list(map(int, input().split()))で、入力から 1 行読み取り、空白で区切って整数のリストを作ることができます。
# 入力から 1 行読み取り、空白で区切って整数のリストを作る a = list(map(int, input().split())) print(a)
入力
886 551 37 424 531
出力
[886, 551, 37, 424, 531]
リストを出力する
- リスト a に対し、
print(*a)で a の要素を空白区切りで出力できます。
a = [9, 9, 7, 3]
# a の要素を空白区切りで出力する
print(*a)
# a の要素を改行区切りで出力する
for x in a:
print(x)
出力
9 9 7 3 9 9 7 3
リストの使い所
リストと for 文を組み合わせると、以下のように大量のデータを扱うプログラムを書くことができます。
例題
N 人の生徒が数学のテストと英語のテストを受けました。テストはそれぞれ 100 点満点で、生徒 i\ (1 \le i \le N) の数学の点数は M_i 、英語の点数は E_i でした。それぞれの生徒について、数学のテストと英語のテストの合計点を求めてください。
制約
- 入力される値はすべて整数
- 1 \le N \le 1000
- 0 \le M_i \le 100\ (1 \le i \le N)
- 0 \le E_i \le 100\ (1 \le i \le N)
入力
入力は以下の形式で与えられる。
N M_1 M_2 \cdots M_N E_1 E_2 \cdots E_N
出力
S_i\ (1 \le i \le N) を生徒 i の数学のテストと英語のテストの合計点とする。
以下の形式で出力せよ。
S_1 S_2 \vdots S_N
入力例
3 20 100 30 100 5 40
出力例
120 105 70
解答例
N \le 3 のような N が非常に小さいという制約がついていれば、N で場合分けすることによってリストを使わずに解くことも可能です。しかし、N が大きくなるとこれは非現実的になってしまいます。
リストと for 文を用いれば、N の大きさに関わらず簡潔に処理を書くことができます。
# 生徒の人数 N を入力
N = int(input())
# 数学の点数 M を入力
M = list(map(int, input().split()))
# 英語の点数 E を入力
E = list(map(int, input().split()))
# それぞれの生徒について処理する
for i in range(N):
# 生徒 i の合計点 M[i] + E[i] を出力する
print(M[i] + E[i])
リストのさらなる機能
負の添字
- リスト a と負の整数 i に対し、
a[i]で a の 後ろから -i-1 番目の要素を取得することができます。末尾の要素はa[-1]で、先頭の要素はa[-len(a)]で取得することができます。
範囲外アクセス
- 存在しない要素を取得しようとすると、RE が発生します。
a = [3, 1, 4, 1, 5] # 負の添字で後ろから順番に要素を取得 print(a[-1]) print(a[-2]) print(a[-3]) # a の 5 番目の要素は存在しないので、実行時エラーが発生する print(a[5])
出力
5 1 4
エラー出力
Traceback (most recent call last):
File "/judge/Main.py", line 8, in <module>
print(a[5])
^^^^
IndexError: list index out of range
終了コード
256
エラー出力を見ると、8 行目の a[5] の部分で、IndexError: list index out of range (リストの添字の範囲外) というエラーが起きていることがわかります。
リストをつなげる
- リスト a とリスト b に対し、
a + bで a と b をつなげたリストを作ることができます。 - リスト a と整数 n に対し、
a * nで a を n 回繰り返したリストを作ることができます。
# リスト [1, 6] とリスト [1, 8] をつなげて [1, 6, 1, 8] を作り、a に代入する a = [1, 6] + [1, 8] # [1, 6, 1, 8] に [0, 3, 3] をつなげて [1, 6, 1, 8, 0, 3, 3] とする a += [0, 3, 3] # リスト [0, 1, 2] を 3 回繰り返したリスト [0, 1, 2, 0, 1, 2, 0, 1, 2] を作り、a に代入する a = [0, 1, 2] * 3
リストの末尾に要素を追加・削除する
- リスト a と値 x に対し、
a.append(x)で a の末尾に要素 x を追加できます。 - リスト a に対し、
a.pop()で a の末尾の要素を取得しながら削除できます。
# 空のリストを作り、a に代入する a = [] # a の末尾に 1 を追加する。a は [1] になる。 a.append(1) # a の末尾に 2 を追加する。a は [1, 2] になる。 a.append(2) # a の末尾に 3 を追加する。a は [1, 2, 3] になる。 a.append(3) # a の末尾の要素 3 を出力し、削除する。a は [1, 2] になる。 print(a.pop()) # a の末尾の要素 2 を出力し、削除する。a は [1] になる。 print(a.pop()) # a の末尾の要素 1 を出力し、削除する。a は [] になる。 print(a.pop())
出力
3 2 1
リストの好きな位置に要素を追加・削除する
- リスト a と整数 i と値 x に対し、
a.insert(i, x)で a の i 番目の位置 (a[i-1]とa[i]の間) に x を挿入することができます。 - リスト a と整数 i に対し、
a.pop(i)で a の i 番目の要素を取得しながら削除することができます。
リストの途中への挿入・削除は、それ以降の要素をずらす必要があるため、末尾への挿入・削除と比べて時間がかかります。
リストの中に x があるか調べる
- リスト a と値 x に対し、
x in aで x が a の中に 1 個以上存在するかを判定することができます。not (x in a)はx not in aと書くこともできます。
- リスト a と値 x に対し、
a.count(x)で x が a の中に何個存在するかを取得することができます。 - リスト a と値 x に対し、
a.index(x)で a の中に x が出現する最初の位置を取得することができます。
# x が 1, 2, 3 のいずれかであるかを判定する x = 2 print(x in [1, 2, 3]) a = [3, 1, 4, 1, 5] # a の中に存在する 1 の数 (2 個) を数える print(a.count(1)) # a の中に存在する最初の 1 の位置 (a[1]) を調べる print(a.index(1))
出力
True 2 1
リストをソートする
- リスト a に対し、
a.sort()で a の要素を昇順に並べ替えることができます。
リストを反転する
- リスト a に対し、
a.reverse()で a の要素を逆順に並べ替えることができます。
a = [3, 1, 4, 1, 5] # a を昇順に並び替える。a は [1, 1, 3, 4, 5] になる。 a.sort() print(a) # a を反転する。a は [5, 4, 3, 1, 1] になる。 a.reverse() print(a)
出力
[1, 1, 3, 4, 5] [5, 4, 3, 1, 1]
リストを複製する
リスト a に対し b = a とすると、リストは複製されず、a の指すリストと b の指すリストは同一のものになります。
# リスト [3, 1, 4, 1, 5] を作り、a に代入する a = [3, 1, 4, 1, 5] # a が指しているリストを b に代入する b = a # a の指すリストと b の指すリストは同一のため、a を変更すると b も変わっている a[2] = 7 print(b) # b を変更すると a も変わっている b.append(9) print(a)
出力
[3, 1, 7, 1, 5] [3, 1, 7, 1, 5, 9]
これを回避するには、b = a.copy() と書いて、リストを複製する必要があります。
# リスト [3, 1, 4, 1, 5] を作り、a に代入する a = [3, 1, 4, 1, 5] # a が指しているリストを複製して b に代入する b = a.copy() # a の指すリストと b の指すリストは別物のため、a を変更しても b は変わらない a[2] = 7 print(b)
出力
[3, 1, 4, 1, 5]
リストの一部分を複製する(スライス)
- リスト a と整数 l,r\ (0 ≤ l ≤ r ≤ \text{len}(a)) に対し、
a[l:r]で a[l] から a[r-1] までの r-l 要素からなるリストを作ることができます。
a = [3, 1, 4, 1, 5] # a[1] から a[3] までの 3 要素からなるリストを作る print(a[1:4]) # a[0] から a[4] までの 5 要素からなるリストを作る print(a[0:5])
出力
[1, 4, 1] [3, 1, 4, 1, 5]
- リスト a と正整数 l,r\ (0 ≤ l ≤ r ≤ \text{len}(a))、正整数 \mathit{step} に対し、
a[l:r:step]でa[l:r]の範囲から \mathit{step} 要素ごとに取り出したリストを作ることができます。- より正確には、d = \bigl\lceil\frac{r-l}{\mathit{step}}\bigr\rceil とすると、長さ d のリスト
[a[l+step*0], a[l+step*1], ..., a[l+step*(d-1)]]が作られます。 - l を省略すると l = 0 扱いに、r を省略すると r = \text{len}(a) 扱いに、\mathit{step} を省略すると \mathit{step} = 1 扱いになります。特に
a[:]と書くと、リストaを複製することができます。
- より正確には、d = \bigl\lceil\frac{r-l}{\mathit{step}}\bigr\rceil とすると、長さ d のリスト
a = [3, 1, 4, 1, 5, 9] # a[0:6] を作る (リストを複製する) print(a[:]) # a[0:6] から 2 要素ごとに取り出したリストを作る print(a[::2]) # a[1:6] から 2 要素ごとに取り出したリストを作る print(a[1::2]) # a[1:5] から 3 要素ごとに取り出したリストを作る print(a[1:5:3])
出力
[3, 1, 4, 1, 5, 9] [3, 4, 5] [1, 1, 9] [1, 5]
リストを比較する
- リスト a, b に対し、
a == b/a != bでリストの全要素が一致しているかを判定することができます。 - リスト a, b に対し、
a < b/a <= b/a > b/a >= bで a と b を辞書式順序で比較できます。
公式ドキュメント
より詳しい情報を知りたい場合は、以下の公式ドキュメントを参照してください。
https://docs.python.org/ja/3/library/stdtypes.html#list
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
"(二重引用符)や'(一重引用符)で囲んで文字列を作るlen(s)で文字列 s の長さを得られるs[i]で文字列 s の i 文字目を得られるs + tで文字列 s, t を連結できる- 文字列は変更不可能。一部を変更したいときは、文字のリストを作る
文字列
Hello や ABCDEFG や あいうえお のようなテキスト(文字の並び)のことを 文字列 と言います。Python では、str 型(文字列型) を使って文字列を扱います。例えば、以下のようなプログラムを書くことができます。
# 文字列 "ABCDEFG" を作り a に代入 a = "ABCDEFG" # 文字列 a の 0 番目の文字 "A" を出力 print(a[0]) # 入力から 1 行読み取って文字列を作り b に代入 b = input() # 文字列 a, 空白, 文字列 b をつなげた文字列を作り出力 print(a + " " + b)
入力
あいうえお
出力
A ABCDEFG あいうえお
本章では、この文字列の使い方について説明します。
文字列を作る
"(二重引用符)や'(一重引用符)で囲んだ部分が文字列として扱われます。どちらを使っても違いはありません。
# 文字列 "Hello" を作り a に代入 a = "Hello" # 文字列 "AtCoder" を作り b に代入 b = 'AtCoder'
エスケープシーケンス
通常、以下のように文字列の中に改行をそのまま書くことはできません。
# 文字列の中に改行を入れたい s = "Hello AtCoder"
文法エラー
File "Main.py", line 2
s = "Hello
^^^^^^
SyntaxError: unterminated string literal (detected at line 2)
(訳)文法エラー: 終端のない文字列リテラル (2 行目で検出)
このような文法上意味のある文字を文字列に入れたい場合、\(バックスラッシュ)から始まる エスケープシーケンス を利用します。主なエスケープシーケンスは以下の通りです。
| エスケープシーケンス | 意味 |
|---|---|
\n |
改行文字 |
\" |
"(二重引用符) |
\' |
'(一重引用符) |
\\ |
\(バックスラッシュ) |
\t |
水平タブ |
# 文字列の中に改行文字を入れるには \n と書く
print("Hello\nAtCoder")
# 二重引用符で囲まれた文字列の中で二重引用符を入れるには \" と書く
# 文字列の中にバックスラッシュを入れるには \\ と書く
print("\"Hello\\nAtCoder\"")
出力
Hello AtCoder "Hello\nAtCoder"
文字列の長さ
- 文字列 s に対し、
len(s)で s の長さ(文字数)を取得できます。
for 文で文字列の中の文字を列挙する
- 文字列 s に対し、
for x in s:で s の中の文字を順に x に代入して繰り返し処理を行うことができます。
s = "AtCoder"
for x in s:
print(x)
出力
A t C o d e r
入力から文字列を作る
input()で入力から 1 行読み取って文字列を作ることができます。
文字列を出力する
- 文字列 s に対し、
print(s)で s を出力することができます。
例
# 入力から 1 行読み取り、そのまま出力する print(input())
入力
Hello, AtCoder!
出力
Hello, AtCoder!
文字列をつなげる
- 文字列 s, t に対し、
s + tで s, t をこの順に連結した文字列を作ることができます。 - 文字列 s と非負整数 n に対し、
s * nで s を n 回繰り返した文字列を作ることができます。
# "ABC" と "123" をつなげた文字列 "ABC123" を出力する
print("ABC" + "123")
# "ABC" を 3 回繰り返した文字列 "ABCABCABC" を出力する
print("ABC" * 3)
出力
ABC123 ABCABCABC
文字列を整数に変換する
- 文字列 s に対し、
int(s)で s を整数に変換することができます。
整数を文字列に変換する
- 整数 x に対し、
str(x)で x を文字列に変換することができます。
# 999999999999999999999999999999 + 1 を出力
print(int("9" * 30) + 1)
# 3 ** 1000 の桁数を出力
print(len(str(3 ** 1000)))
出力
1000000000000000000000000000000 478
整数・文字列変換における桁数制限
整数から文字列への変換、文字列から整数への変換において、変換に時間がかかることを防ぐため、4300 桁よりも大きな数は変換できないようになっています。整数を出力するときにも整数から文字列への変換が行われるので、この制限が適用されます。
print(10 ** 4300)
エラー出力
Traceback (most recent call last):
File "/judge/Main.py", line 1, in <module>
print(10 ** 4300)
ValueError: Exceeds the limit (4300) for integer string conversion; use sys.set_int_max_str_digits() to increase the limit
(訳) 値エラー: 整数・文字列変換における上限 (4300) を超えています; 上限を増やすには sys.set_int_max_str_digits() を使ってください
sys.set_int_max_str_digits(0) を実行することで、この制限を取り除くことができます。
import sys sys.set_int_max_str_digits(0) print(10 ** 4300)
出力
10000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000
文字列を空白文字で区切る
- 文字列 s に対し、
s.split()で s を空白文字で区切って文字列のリストを作ることができます。
文字列のリストを連結する
- 文字列 s と文字列のリスト a に対し、
s.join(a)で s を区切り文字列として a の各要素を連結することができます。
# "1 23 456" を空白文字で区切り、リスト ["1", "23", "456"] を作る
a = "1 23 456".split()
# ["1", "23", "456"] を文字列 " + " で結合してできる文字列 "1 + 23 + 456" を出力する
print(" + ".join(a))
出力
1 + 23 + 456
文字列の i 番目の文字
- 文字列 s と整数 i に対し、
s[i]で s の i 番目の文字を取得できます。 - リストのときと同様に、負の添字やスライスを使うことができます。
# 文字列 "ABCDE" を作り s に代入する s = "ABCDE" # s の 0 番目の文字 "A" を出力する print(s[0]) # s の最後の文字 "E" を出力する print(s[-1]) # s の 1 番目から 3 番目までの文字列 "BCD" を出力する print(s[1:4]) # s を逆順にした文字列 "EDCBA" を出力する print(s[::-1])
出力
A E BCD EDCBA
部分文字列に x があるか調べる
文字列 s の部分文字列とは、s の連続する一部分のことです。部分文字列とは?
例えば、空文字列、A、BC、ABC は ABC の部分文字列ですが、D や AC は ABC の部分文字列ではありません。
- 文字列 s, t に対し、
t in sで s の部分文字列に t が含まれるかどうか判定することができます。 - 文字列 s, t に対し、
s.index(t)で s に現れる最初の部分文字列 t の位置を求めることができます。 - 文字列 s, t に対し、
s.count(t)で s に部分文字列 t が重ならずに何回出現するかを求めることができます。
# 文字列 "ABABABA" を作り s に代入する
s = "ABABABA"
# "ABABABA" の部分文字列に "BAB" があるか判定する
print("BAB" in s)
# "ABABABA" に現れる最初の部分文字列 "BAB" の位置を求める
# s[1:4] が最初の "BAB" なので、1 を出力する
print(s.index("BAB"))
# "ABABABA" に重ならずに現れる部分文字列 "BAB" の個数を求める
# s[1:4] と s[3:6] が "BAB" であるが、重ならずに取れるのは 1 個までなので、1 を出力する
print(s.count("BAB"))
# "AAAAAAAAAA" (A が 10 個) から重ならずに取れる "AAA" は 3 個まで
print("AAAAAAAAAA".count("AAA"))
出力
True 1 1 3
部分文字列を置換する
- 文字列 s, t, u に対し、
s.replace(t, u)で s に重ならずに出現する部分文字列 t をすべて u に置き換えた文字列を取得できます。
# "1 + 2 + 3" に出現する "+" を "**" に置き換えた文字列 "1 ** 2 ** 3" を出力する
print("1 + 2 + 3".replace("+", "**"))
# "AAAAA" に出現する "AA" を "X" に置き換えた文字列 "XXA" を出力する
print("AAAAA".replace("AA", "X"))
出力
1 ** 2 ** 3 XXA
文字列を比較する
- 文字列 s, t に対し、
s == t/s != tで s と t が同じ文字列であるかを判定できます。 - 文字列 s, t に対し、
s < t/s <= t/s > t/s >= tで s と t を辞書式順序で比較できます。
大文字・小文字かどうか判定する
- 文字列 s に対し、
s.isupper()で s の文字がすべて大文字かどうか判定することができます。- より正確には、
s.isupper()は s に大文字が含まれていて、小文字が含まれないときTrueを返します。
- より正確には、
- 文字列 s に対し、
s.islower()で s の文字がすべて小文字かどうか判定することができます。- より正確には、
s.islower()は s に小文字が含まれていて、大文字が含まれないときTrueを返します。
- より正確には、
# "ATCODER" はすべて大文字からなるので、"ATCODER".isupper() は True
print("ATCODER".isupper())
# "atcoder" はすべて小文字からなるので、"atcoder".islower() は True
print("atcoder".islower())
# 空文字列には小文字が含まれないので、"".islower() は False
print("".islower())
出力
True True False
数字かどうか判定する
- 文字列 s に対し、
s.isdigit()で s が空でなく、s の文字がすべて数字かどうか判定することができます。
# "0123456789" は数字のみからなるので、"0123456789".isdigit() は True
print("0123456789".isdigit())
# "ABC123" には数字ではない文字が含まれるので、"ABC123".isdigit() は False
print("ABC123".isdigit())
# "".isdigit() は False
print("".isdigit())
出力
True False False
大文字・小文字に変換する
- 文字列 s に対し、
s.upper()で s の小文字をすべて大文字に変換した文字列を取得できます。 - 文字列 s に対し、
s.lower()で s の大文字をすべて小文字に変換した文字列を取得できます。
# "AtCoder" の小文字をすべて大文字に変換した文字列 "ATCODER" を出力
print("AtCoder".upper())
# "AtCoder" の大文字をすべて小文字に変換した文字列 "atcoder" を出力
print("AtCoder".lower())
出力
ATCODER atcoder
文字列の一部を変更する
Python の文字列は 一度作ると変更することができません。 文字列の一部を変更したい場合は、一度文字のリストに変換する必要があります。
# 文字列 "AtCoder" を作り s に代入する
s = "AtCoder"
# s は for 文に入れられるものであるから、list(s) で
# リスト ["A", "t", "C", "o", "d", "e", "r"] を作れる
a = list(s)
# a の 0 番目の要素を "M" に変更する
a[0] = "M"
# a の要素をつなげて出力する
print("".join(a))
出力
MtCoder
文字
Python では、1 つの文字は長さ 1 の文字列として str 型で表現されます。 したがって、文字列から取り出した「文字」に対しても文字列に対するさまざまな機能を使うことができます。
# 文字列 "0123456789" の 0 番目の文字 "0" を c に代入 c = "0123456789"[0] # c は長さ 1 の文字列である print(len(c)) # c.isdigit() で "0" が数字であるか判定する print(c.isdigit()) # int(c) で整数に変換できる print(int(c))
出力
1 True 0
文字をコードポイントに変換する
- 文字 c に対し、
ord(c)で c の Unicode コードポイントを取得できます。
コードポイントを文字に変換する
- 整数 x に対し、
chr(x)で Unicode コードポイントが x である文字を取得できます。
Unicode とは
様々な文字に番号を割り当て、文字を番号で管理できるようにしたものを 文字コード と言います。文字コードにおいて、ある文字に割り当てられた番号を コードポイント と言います。
Unicode とは、世界中のあらゆる文字に番号を割り当てた文字コードの規格で、Python の内部でも用いられています。
# 文字 "0" に割り当てられた Unicode コードポイントは 48
print(ord("0"))
# 文字 "a" に割り当てられた Unicode コードポイントは 97
print(ord("a"))
# 文字 "あ" に割り当てられた Unicode コードポイントは 12354
print(ord("あ"))
# Unicode コードポイントが 12354 である文字 "あ" を出力する
print(chr(12354))
出力
48 97 12354 あ
競技プログラミングにおいては、どのような環境でも扱うことのできる ASCII 印字可能文字 の部分しか基本的に使われません。文字コードについては、以下のことを覚えれば十分でしょう。
0,1,2, ...,9のコードポイントが連続している。(48 – 57)A,B,C, ...,Zのコードポイントが連続している。(65 – 90)a,b,c, ...,zのコードポイントが連続している。(97 – 122)
したがって、以下のようなコードを書くことができます。
- 英大文字 c に対して、
ord(c) - ord("A")と書けば、c が何番目のアルファベットであるかがわかる。 - 逆に、i 番目のアルファベットを得るには、
chr(ord("A") + i)と書く。 - 文字 c に対して,
ord("A") <= ord(c) <= ord("Z")と書けば、c が英大文字であるかどうか判定できる。
公式ドキュメント
より詳しい情報を知りたい場合は、以下の公式ドキュメントを参照してください。
https://docs.python.org/ja/3/library/stdtypes.html#text-sequence-type-str
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 関数 は与えられた引数に対して処理を行い返り値を返す機能である
- Python が標準で提供している組み込み関数は準備なしに使うことができる
- 組み込み関数には数値の計算やリストの集計など、様々な便利機能を持つものが用意されている
関数
これまでの節で、標準入力を得るための input やリストの長さを得るための len などの機能を用いてきました。
これらの機能はより正確には「関数」と呼ばれるものになります。関数とは、与えられた値(引数)に対してある定められた処理を行い、処理の結果の値(返り値)を返す道具です。中には引数が無い関数、返り値が無い関数、複数の返り値を返す関数も存在します。
何度も行う処理を関数としてまとめることで、色々な値に対する処理の結果を計算したいときにプログラムの記述量を大きく減らすことができます。そのため、大半のプログラミング言語において関数は必須の機能となっています。
用語の確認のため、これまでに出てきたいくつかの関数の引数・処理内容・返り値を整理します。
| 関数 | 引数 | 処理内容 | 返り値 |
|---|---|---|---|
len |
リストや文字列 | 長さを取得する | 長さ (整数値) |
input |
無し 1 | 標準入力から1行取得する | 標準入力の1行 (文字列) |
print |
文字列, 整数 など | 標準出力に出力する | 無し2 |
divmod |
数値2つ | 剰余を計算する | 1つめの数値を2つめの数値で割った商と余り |
Python 標準の関数
len や input は関数の中でも特別なもので、Python が標準で提供している組み込み機能、とりわけ組み込み関数と呼ばれるものになります。Python が標準で提供しているため、ユーザは特に準備なく使用することができます。
これまでの節で出てきたものを含め、Python では全部で71種類の組み込み関数が用意されています3。
以下ではその中でも競技プログラミングにおいて比較的利用されることの多いものを紹介します。
abs
数値の絶対値を計算して返します。
a = -3 b = 5 a_abs = abs(a) b_abs = abs(b) print(a_abs, b_abs)
実行結果
3 5
pow
pow(a,b) で a の b 乗の値を計算します。
pow(a,b,mod) で a の b 乗を mod で割った余りを計算します。
a = 3 b = 4 mod = 10 res = pow(a, b) res2 = pow(a, b, mod) print(res, res2)
実行結果
81 1
なお、べき乗は 1.3 節で扱った ** 演算子でも計算できますが、組み込み関数 pow を用いたほうが高速に計算できます。
また、余りは pow(a,b) % mod のように後から計算しても同じ結果になりますが、pow(a,b) の値が非常に大きくなる場合は pow(a,b,mod) のほうが高速に計算できます。
競技プログラミングにおいては pow 関数を使うことが必須であるケースが多いため覚えておきましょう。
min max
与えられた2つ以上の数値の中の最小値, 最大値を計算して返します。
min_val = min(1, 3, -5, 2) max_val = max(1, 3, -5, 2) print(min_val, max_val)
実行結果
-5 3
数値をリストとして与えることも可能です。
l = [1, 3, -5, 2] min_val = min(l) max_val = max(l) print(min_val, max_val)
実行結果
-5 3
sum
リストに含まれる値の合計を計算して返します。
l = [1, 3, -5, 2] sum_val = sum(l) print(sum_val)
実行結果
1
sorted
リストをソートし、新たなリストを返します。
l = [1, 3, -5, 2]
new_l = sorted(l)
print("元のリスト:", l)
print("新たなリスト:", new_l)
実行結果
元のリスト: [1, 3, -5, 2] 新たなリスト: [-5, 1, 2, 3]
1.10 節で扱った l.sort() と異なり、元のリストはソートされていない点に注意してください。
all any
all は与えられたリストの要素すべてが条件式として真であるかを判定します。
any は与えられたリストの要素の中に条件式として真であるものが1つ以上存在するかを判定します。
l = [1, 3, -5, 2] res = all([v>0 for v in l]) # l に含まれる値が全て正か? res2 = any([v%2==0 for v in l]) # l に偶数が含まれるか? print(res, res2)
実行結果
False True
なお、空のリストに対して all は True を、any は False を返します。
print(all([]), any([]))
実行結果
True False
enumerate
for i,v in enumerate(リスト): のように書くことでリストのインデックスと値を同時に取得することができます。
l = [1, 3, -5, 2]
for i,v in enumerate(l):
print(i, "番目の要素は", v, "です")
実行結果
0 番目の要素は 1 です 1 番目の要素は 3 です 2 番目の要素は -5 です 3 番目の要素は 2 です
次のように書いても同一の結果になりますが、enumerate を使うほうが単純に記述することができます。
l = [1, 3, -5, 2]
for i in range(len(l)):
v = l[i]
print(i, "番目の要素は", v, "です")
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 関数を定義するためには
def 関数名(パラメータ):という記法を用いる - 関数の戻り値を返すには
return文を用いる - 関数外の変数を更新するには
global文を用いる
関数を自作する
前項では、今まで扱ってきた input や len が関数であったことや、これ以外にも色々な関数があることを学びました。この関数は予め用意されたものだけではなく、自分で動作を定めた関数を作成することも可能です。このように関数を作成することを、「関数を定義する」と呼びます。このように関数を定義するメリットの一つとして、複数の場所で行われる同じ処理をまとめることができるという点があります。
最も単純な関数定義
まず、最も単純な関数定義から見ていきます。以下は、1, 2, 3を 3 行で出力するという処理をする関数の定義です。
def print_numbers():
print(1)
print(2)
print(3)
defは定義の英語であるdefineから来ているキーワードで、関数の定義をすることを表します。それに続く部分(今回の場合はprint_numbers)は関数の名前を表し、変数名と同様に自由な名前が使用できます。その後の (): の部分は後ほど説明しますので、今は読み飛ばすこととします。
2 行目以降は、関数の処理を表す部分です。これは関数が呼ばれる度に処理されます。通常の Python のコードと同じように書くことができますが、インデントをする必要がある点には注意してください。
復習となりますが、関数は関数名の後にカッコをつけることで呼び出すことができます。この場合では、以下のようになります。
print_numbers() # 1, 2, 3が改行されて出力される
なお、関数は定義した後でないと呼び出すことができません。その点には注意してください。たとえば、以下のようなコードは実行時エラーとなります。
print_one() # NameError: name 'print_one' is not defined def print_one(): print(1)
引数を取る関数定義
次に、min(1, 2) のように値を渡すことができる関数を定義してみます。以下は、第一引数と第二引数を足した数を出力する関数の定義と、その実行結果です。
def add_and_print(a, b):
print(a + b)
add_and_print(1, 2) # 3 が出力される
新しく出てきた事項として、一行目の(a, b)という記述があります。これは、関数の後に書かれた一番目の要素(第一引数)をaというパラメータに、二番目の要素(第二引数)をbというパラメータに格納することを意味しています。このパラメータは関数の処理部分で変数のように用いることができます。
よって、この関数をadd_and_print(1, 2)のようにして呼び出した場合、aには1、bには2が格納され、その状態でprint(a + b)が実行された結果として3が出力されることになります。
戻り値を持つ関数定義
ここまでの文法では min のような関数を実装することはできません。これは、return 文を用いることで、関数の中から呼び出し側に値を返すことができます。このような関数の「結果」を戻り値とよびます。以下は、return 分を用いた第一引数に 1 を足した値を返す関数の定義です。
def add_one(a):
return a + 1
return 文の後には、関数の戻り値としたい値を記述します。すると、その値が関数呼び出しの式の値となります。よって、以下のように変数に代入したり、直接関数の引数として渡すことも可能です。
two = add_one(1) # 変数 two は 2 となる print(two) # 2 が出力される print(add_one(1) + 1) # 3 が出力される
また、return文は実行された時点で関数の処理を終了するという役割もあります。これについては、後ほど詳述します。
まとめ
まとめると、関数の定義は以下のような文法で行うこととなります。
def 関数名(パラメータ):
処理
実は、関数のパラメータにはここでは説明しなかった文法がいくつか存在しています。これを用いると、print関数のように引数の数を自由にできたり、sep=''のように名前で指定できたりするパラメータを作成できるようになります。
興味のある方は、Python公式ドキュメント内の用語集 - parameterを参照してください。
関数定義時のテクニック
return 文の特性と複数の return 文を持つ関数
return 文は、同じ関数内の複数の箇所に書くことができます。例えば、以下はaとbの小さい方を戻り値とする関数の定義です。
def my_min(a, b):
if a < b:
return a
else:
return b
if文がどのようなものだったかを思い出すと、aがbより小さいときにreturn aが、そうでないときにreturn bが実行されることになると分かります。
return 文は、実行された時点で関数の処理を終了します。つまり、以下のadd_one関数のreturn a + 1以降に書かれた文が実行されることはありません。
def add_one(a):
return a + 1
print("ここには到達しない")
return a + 2 # この行にも到達しない
print("もちろんここにも到達しない")
これを用いると、my_minを以下のように書き換えることができます。
def my_min(a, b):
if a < b:
return a
# a < b のケースでは return a が実行されているため、ここには到達しない
return b
このコードでは、return bが実行されるのはa < bでないときのみです。何故ならば、a < bのときはreturn aが実行されるので、そこで関数の処理が終了するためです。
また、値を返さない関数1でも、関数の処理を早期に終了する目的でreturn文を使用することができます。
def print_a_is_7(a):
if a == 7:
print("a is 7")
return
# a == 7 のケースでは return が実行されているため、ここには到達しない
print("a is not 7")
例えば、上の例では a == 7 のときには print("a is not 7") が実行されません。これは、a == 7 のときは return が実行されているので、そこで関数の処理が終了するためです。
関数内の変数
通常のプログラムと同様に、関数内でも変数を用いることができます。しかし、関数内で使用した変数は、基本的には関数の外部で使用することはできません。
以下の関数は、add_one関数を変数を使って書き直したものです。
def add_one(a):
result = a + 1
return result
print(add_one(1)) # 2 が表示される
print(result) # NameError: name 'result' is not defined
この関数自体は、想定している通りの動作をします。しかし、関数を呼び出した後にresult変数を参照しようとしても、存在しない変数を使用しようとしたことを示すエラーが発生してしまいます。
変数を使用できる範囲のことをスコープと呼びます。今回の場合、result変数のスコープはadd_one関数内であるということになります。
一方で、関数の外の変数は自由に使用することが可能です。以下は、変数aの値をプリントするprint_a関数を用いた例です。
a = 0
def print_a():
print(a)
print_a() # 0 が表示される
a = 1
print_a() # 1 が表示される
変数aは関数の外で宣言されていますが、その値をprint_a関数の内部で用いることができていることが分かります。これは、変数aのスコープがグローバル(つまり、コード全体)であるためです。このような変数のことをグローバル変数と呼びます2。
一方で、関数内でグローバル変数を変更する場合には注意が必要です。以下は、受け取った変数をaに代入することを意図した関数update_aを用いた例です。
a = 0
def update_a(val):
a = val
update_a(1)
print(a) # 0 が出力される
この例から分かる通り、単に代入文を書くだけでは関数内ではグローバル変数の値を変更することができません3。グローバル変数に値を代入したい場合は、global文を使用します。
a = 0
def update_a(val):
global a
a = val
update_a(1)
print(a) # きちんと 1 が出力される
関数内にてglobal 変数名という形でglobal文を使用すると、関数内で指定した変数を使用した際にグローバル変数として扱うようになります。また、複数の変数を指定したい場合は、global a, b, c のようにカンマで区切ることで指定することができます。
global文が必要な条件については一見複雑そうに見えますが、まとめれば「関数外部でも変数を使用していて、かつ関数内で代入をしている」場合となります。
よく混乱する例として、list等を代入せずに変更するケースがあります。例えば、以下のようなケースではglobal文は必要ありません。
li = []
def update_li(val):
li.append(val)
update_li(1)
print(li) # [1] と出力される
これは、変数liは変更されてはいるものの代入されていないためです。global文が必要となるケースは、以下のように変数liに代入しているケースです。
li = []
def update_li(val):
global li
li = li + [val]
update_li(1)
print(li) # [1] と出力される
nonlocal
ここからは、global文についての補足となります。複雑なプログラムを書かない内は必要となることがないであろう知識なので、読み飛ばしても構いません。
for文の中にfor文を入れることができたのと同様に、Pythonでは関数内で関数を定義することが可能です。この際、以下のように関数内で用いたい外部の変数がグローバル変数でない場合が存在します。
def get_1():
value = 0
def add_1():
# ここで用いている value はグローバル変数ではないので、global は使えない
value += 1 # UnboundLocalError: cannot access local variable 'value' where it is not associated with a value
add_1()
return value
print(get_1())
このような場合に使用できる文として、nonlocal文が存在します。これを用いて上のコードを書き直すと、以下の通りとなります。
def get_1():
value = 0
def add_1():
nonlocal value
value += 1
add_1()
return value
print(get_1())
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
第1章修了

第1章お疲れ様でした。
1.00から1.13までの問題を全てACしたあなたは、理論上は全ての「計算処理」を行うプログラムを書ける程の知識を身に着けました。
第2章について
十分なプログラムの知識があったとしても、実際に複雑な計算をするプログラムを書くのは簡単ではありません。
第2章では「複雑な計算処理の書き方」や Python 特有の記法について解説します。
また、複雑な計算処理をコンピュータが行うのにかかる時間を見積もるための「計算量」という概念について説明します。
第2章をマスターすれば、実際に全ての「計算処理」を行うプログラムを書ける程の知識が身につきます。
ぜひコンテストに参加してみましょう!
AtCoder Beginner Contest
毎週土曜日の午後9時からは、AtCoder Beginner Contestが開催されていますので、ぜひコンテストに参加してみましょう。最新のコンテスト情報はこちらからご確認ください。
AtCoder Daily Training
AtCoder Beginner Contestの過去問を使用した練習用バーチャルコンテストです。
毎週火曜・水曜・木曜の夕方から夜にかけて1日3回行っています。
難易度はEASYをおすすめします。
AtCoderで強くなるには?
AtCoderのコンテストの復習方法やコンテスト以外での学習方法が書いてあります。
上記リンク先は、AtCoderInfo内のページです。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- for 文を使うとループ処理を行うことができる
- range 関数を使うと指定した範囲の処理を行うことができる
- リストの各要素に対して処理を行うこともできる
- enumerate, zip, reversed なども便利
R - 2.01.いろいろな for 文
for 文は第 1 章でも扱いましたが、より発展的な書き方も含めいろいろな書き方を紹介します。
range を使う書き方
1.09 節で扱った内容の復習です。 range 関数を使うと指定した範囲のループ処理を行うことができます。
range(stop)
stop 未満の整数をループします。
# 0 以上 5 未満をループ
for i in range(5):
print(i)
実行結果
0 1 2 3 4
range(start, stop)
range 関数に引数を 2 つ指定すると、その範囲をループします。
# 2 以上 5 未満をループ
for i in range(2, 5):
print(i)
実行結果
2 3 4
range(start, stop, step)
range の第 3 引数は、ループのステップを指定できます。
# 4 以上 10 未満の範囲を 2 ずつ増やしながらループ
for i in range(4, 10, 2):
print(i)
実行結果
4 6 8
第 3 引数に負の整数を指定した場合、数値を減らしながらループします。
# 5 から 0 まで降順にループ
for i in range(5, -1, -1):
print(i)
実行結果
5 4 3 2 1 0
リストなどに対する for 文
リストに対する for 文
単純なリストに対する for 文は 1.10 でも扱いました。
L = [10, 20, 40, 80, 160]
# L の要素を順に出力
for x in L:
print(x)
実行結果
10 20 40 80 160
文字列に対する for 文
文字列に対して for 文を使うと、 1 文字ごとに処理することができます。より一般的な型の変数に対する for 文については「発展的な内容」も参照してください。
S = "AtCoder"
# s の要素を順に出力
for x in S:
print(x)
実行結果
A t C o d e r
リストのリスト
リストのリスト
リストを要素とするリストの場合などには、カンマ区切りで受け取ると複数の変数に一気に格納することができます。
L = [[5, 10], [6, 20], [7, 50]]
for a, b in L:
print("a は", a, "です。 b は", b, "です。")
実行結果
a は 5 です。 b は 10 です。 a は 6 です。 b は 20 です。 a は 7 です。 b は 50 です。
3 要素以上の場合
内側のリストが 3 要素以上になっても同様に書けますが、受け取る側の引数の個数が異なるとエラーになるので注意してください。
L = [[1, 2, 3], [4, 5, 6]]
for a, b, c in L:
print("a は", a, "です。 b は", b, "です。 c は", c, "です。")
実行結果
a は 1 です。 b は 2 です。 c は 3 です。 a は 4 です。 b は 5 です。 c は 6 です。
次の例では長さ 4 の配列を 3 つの変数( a, b, c )で受け取ろうとしているため、 ValueError: too many values to unpack (expected 3) というエラーになります。
L = [[1, 2, 3, 4], [5, 6, 7, 8]]
for a, b, c in L:
print("a は", a, "です。 b は", b, "です。 c は", c, "です。")
enumerate
enumerate 関数を使うと、リストのインデックスと要素をまとめて取得できます。
L = [10, 20, 40, 80, 160]
# L のインデックスと要素を取得
for i, x in enumerate(L):
print(i, "番目の要素は", x)
実行結果
0 番目の要素は 10 1 番目の要素は 20 2 番目の要素は 40 3 番目の要素は 80 4 番目の要素は 160
インデックスは 0 から始まる点に注意してください。開始インデックスを明示的に指定したい場合は、第2引数に指定します。
L = [10, 20, 40, 80, 160]
# インデックスを 10 から開始
for i, x in enumerate(L, 10):
print(i, "番目の要素は", x)
実行結果
10 番目の要素は 10 11 番目の要素は 20 12 番目の要素は 40 13 番目の要素は 80 14 番目の要素は 160
リストを逆順に処理
reversed 関数を使うと、リストを逆順に処理することができます。
L = [10, 20, 40, 80, 160]
# L の逆順
for a in reversed(L):
print(a)
実行結果
160 80 40 20 10
リストの場合は reversed(L) の代わりに 1.10 節で扱ったスライスを使って L[::-1] と書いても逆順に処理することができます。
zip
複数のリストを同時に前からループ処理したい場合、 zip 関数が便利です。
A = [3, 4, 5, 6, 7]
B = [10, 20, 40, 80, 160]
# A と B から 1 つずつ要素を取得し a および b に格納する
for a, b in zip(A, B):
print(a, b)
実行結果
3 10 4 20 5 40 6 80 7 160
ふたつのリストの長さが異なる場合は短い方が終わるまで処理されます。
A = [3, 4, 5, 6, 7, 8, 9, 10]
B = [10, 20, 40, 80, 160]
# A と B から 1 つずつ要素を取得し a および b に格納する
for a, b in zip(A, B):
print(a, b)
実行結果
3 10 4 20 5 40 6 80 7 160
continue, break, else
こちらも 1.09 節で扱いましたが、復習のため再度紹介します。
continue
continue はその後の処理を飛ばします。
for i in range(5):
# i == 2 の場合はその後の処理を飛ばす
if i == 2:
continue
print(i)
実行結果
0 1 3 4
break
ループを抜ける場合は break を使います。
for i in range(5):
# i == 2 の場合はループを抜ける
if i == 2:
break
print(i)
実行結果
0 1
break-else
break を含むループ処理の後に else 節を書くと、 break で抜けなかった場合にのみ else 節が処理されます。
次の例では break により抜けるので else 節は処理されません。
for i in range(5):
if i == 2:
break
print(i)
else:
print("else 節が処理されたよ")
実行結果
0 1
次の例では break により抜けないので、 else 節が処理されます。
for i in range(5):
if i == 7:
break
print(i)
else:
print("else 節が処理されたよ")
実行結果
0 1 2 3 4 else 節が処理されたよ
発展的な内容
イテラブルオブジェクト
本節では主にリストや文字列の要素を順に処理するループを紹介しましたが、より一般的には イテラブル(iterable) なオブジェクトに対して同様の処理を行うことができます。イテラブルなオブジェクトとは、要素を一つずつ順番に取り出すことができるオブジェクトのことです。 list、 tuple、 str、 set、 dict などがイテラブルオブジェクトに該当し、これらはfor文などで逐次的に処理できます。また本節では range を使う書き方はおまじないのように説明しましたが、 range もイテラブルオブジェクトのひとつです。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- ループ構文の中にさらにループ構文があるものを多重ループと呼ぶ
- 多重ループを一度に抜けたい場合は、フラグ変数を用意してそれぞれのループを抜けるようにする必要がある
多重ループ
1.08 節で扱った while 文や 1.09 節で扱った for 文などのループは、さらにその中にループを書くことができます。
for i in range(3):
for j in range(3):
print(i, j)
実行結果
0 0 0 1 0 2 1 0 1 1 1 2 2 0 2 1 2 2
このように、ループの内側にループがあるようなものを二重ループと呼びます。
二重だけでなく、当然三重ループや四重ループなどもあります。それらをまとめて多重ループと呼びます。
for i in range(2):
for j in range(2):
for k in range(2):
print(i, j, k)
実行結果
0 0 0 0 0 1 0 1 0 0 1 1 1 0 0 1 0 1 1 1 0 1 1 1
二重ループを使って次の例題を解いてみましょう。
例題
要素数 3 の 2 つの数列 A, B に同じ要素が含まれているかどうかを判定してください。
入力の形式
A_1 A_2 A_3 B_1 B_2 B_3
入力例
1 3 2 4 5 3
出力例
YES
次のプログラムをベースに説明していきます。
# スペース区切りの整数をリストとして受け取る
A = list(map(int, input().split()))
# スペース区切りの整数をリストとして受け取る
B = list(map(int, input().split()))
# 答えを保持する変数
answer = False
# ここにプログラムを追記
if answer:
print("YES")
else:
print("NO")
「A と B の要素の組み合わせを全て見て、一致しているものがあるかを調べる」という方針で解くことにしましょう。
まず、ループを使わないで書いてみます。
# スペース区切りの整数をリストとして受け取る
A = list(map(int, input().split()))
# スペース区切りの整数をリストとして受け取る
B = list(map(int, input().split()))
# 答えを保持する変数
answer = False
if (A[0] == B[0] or A[0] == B[1] or A[0] == B[2] or
A[1] == B[0] or A[1] == B[1] or A[1] == B[2] or
A[2] == B[0] or A[2] == B[1] or A[2] == B[2]):
answer = True
if answer:
print("YES")
else:
print("NO")
A に着目してパターン化すると次のような形式になっていることがわかります。
A[i] == B[0] or A[i] == B[1] or A[i] == B[2]
これをループ化してみます。
# スペース区切りの整数をリストとして受け取る
A = list(map(int, input().split()))
# スペース区切りの整数をリストとして受け取る
B = list(map(int, input().split()))
# 答えを保持する変数
answer = False
for i in range(3):
if A[i] == B[0] or A[i] == B[1] or A[i] == B[2]:
answer = True
if answer:
print("YES")
else:
print("NO")
次は B に着目してパターン化します。
A[i] == B[j]
最終的なプログラムは次のようになります。
# スペース区切りの整数をリストとして受け取る
A = list(map(int, input().split()))
# スペース区切りの整数をリストとして受け取る
B = list(map(int, input().split()))
# 答えを保持する変数
answer = False
for i in range(3):
for j in range(3):
if A[i] == B[j]:
answer = True
if answer:
print("YES")
else:
print("NO")
多重ループの break/continue
for 文や while 文には break や continue という命令がありました。多重ループはループ文の中にループ文を入れたものなので、通常の for 文と同様に break/continue 命令を使うことができます。
多重ループで break 命令を使うと 1 段階ループを抜けることができます。内側のループの中で break すると内側のループを抜けることができますが、この break によって外側のループを抜けることはできません。
例えば、「i と j が両方 1 になったらループを抜ける」という処理を以下のようなコードで書いた場合、実行結果は意図したものにはなりません。
for i in range(3):
for j in range(3):
print(i, j)
if i == 1 and j == 1:
print("i と j が両方 1 なので終了(?)")
break
実行結果
0 0 0 1 0 2 1 0 1 1 i と j が両方 1 なので終了(?) 2 0 2 1 2 2
多重ループを抜ける方法はいくつかありますが、そのうちのひとつとして「ループを抜けるかどうかを管理する変数(フラグ変数)を用意し、フラグ変数の値に応じてループを抜けるかどうか分岐する」という方法があります。
「i と j が両方 1 になったらループを抜ける」という処理を、フラグ変数を持つ方法で書くと以下のようになります。
# 外側のループを抜ける条件を満たしているかどうか(フラグ変数)
finished = False
for i in range(3):
for j in range(3):
print(i, j)
if i == 1 and j == 1:
print("i と j が両方 1 なので終了。")
finished = True
if finished:
break
if finished:
break
実行結果
0 0 0 1 0 2 1 0 1 1 i と j が両方 1 なので終了。
また、フラグ変数を持つ方法以外に、多重ループの部分を関数化し return を用いて抜ける方法もあります。
def func():
for i in range(3):
for j in range(3):
print(i, j)
if i == 1 and j == 1:
print("i と j が両方 1 なので終了。")
return
func()
実行結果
0 0 0 1 0 2 1 0 1 1 i と j が両方 1 なので終了。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- (リスト内包表記)
[(変数を使った処理) for (変数名) in (変数を動かす範囲)]のように書くことで変数を使った処理の結果を要素に持ち、- 変数は for 文で指定の範囲を動く
リストを取得できる。
* (標準入力から数値リストを取得)
数値の列を標準入力から受け取ってリストにする処理は
[int(item) for item in input.split()] として記述できる
* (フィルタリング)
[(変数を使った処理) for (変数名) in (変数を動かす範囲) if (条件式)] のように書くことで
* 変数を使った処理 の結果を要素に持ち、
* 変数は for 文で指定の範囲を動くが、
* 条件式 が True の範囲のみに絞り込んだ
リストを取得できる。
- 多重の for 文や内包表記をネストさせることも可能。
リストの内包表記 : for のもう一つの使い方
今回は for の新しい使い方について説明します。
以下のコードの方法1は今までの for の使い方によって5つの要素からなるリストを作っていますが、方法2のように書き換えることが可能です。
# 方法1 : 従来の for 文
l = []
for i in range(5):
l.append(i*i)
# 方法2 : リスト内包表記
l2 = [i*i for i in range(5)]
# l と l2 はともに [0, 1, 4, 9, 16] であり、等しい
print(l)
print(l2)
出力
[0, 1, 4, 9, 16] [0, 1, 4, 9, 16]
この [i*i for i in range(5)] は新しいリストの作成を簡潔に記述するための記法で、リスト内包表記と呼びます。この部分は次のように解釈すると読みやすいでしょう:
i*iを要素に持つリストであるiはrange(5)の範囲 (=0,1,2,3,4) を動く- 結果として、
[0*0, 1*1, 2*2, 3*3, 4*4]すなわち[0, 1, 4, 9, 16]というリストが作成される
より一般的に、リスト内包表記では
[(変数を使った処理) for (変数名) in (変数を動かす範囲)]
のように記述します。
これによって、
変数を使った処理の結果を要素に持ち、- 変数は for 文で指定の範囲を動く
ような要素からなるリストを得ることができます。
※ 注意として、四角括弧([...])ではなく丸括弧((...))で内包表記を書いてしまうと結果はリストではなくジェネレータという別の型になってしまいます。この場合リストに対して行えるようなスライスなどの操作が行えなくなってしまいます。
l = (i*i for i in range(5)) print(l[0])
出力
TypeError Traceback (most recent call last)
<ipython-input-5-38cb2059caa6> in <module>
1 l = (i*i for i in range(5))
----> 2 print(l[0])
TypeError: 'generator' object is not subscriptable
(訳 : 「ジェネレータ」オブジェクトは添字アクセスできません)
競技プログラミングの文脈でジェネレータが必要になることは稀ですので、内包表記はリスト([...])の記法で書く、と覚えてしまうのがよいでしょう。
リスト内包表記の例
内包表記は全く新しい記法になるため慣れるのに時間がかかると思いますが、慣れると非常に便利な記法ですのでぜひ習熟しておくとよいでしょう。
下記に内包表記を使ったコード例を示します:
# 例1. range(3) の要素それぞれに 1 を足す処理をする -> [1,2,3] l = [hoge+1 for hoge in range(3)] # 例2. l の要素それぞれに 2 倍する処理をする -> [2,4,6] l2 = [2*i for i in l] # 例3. l2 の要素それぞれに、「要素とそれから 1 を引いた値の2要素からなるリストを作る」処理をする -> [[2,1], [4,3], [6,5]] l3 = [[val, val - 1] for val in l2]
例1. のように、変数の名前は最初の宣言と for 文の中で整合していれば何でも良いです1。
例2. のように、変数を動かす範囲 は range に限らず 2.01 節で説明したような色々な記述方法を使うことができます。この例では既に作成したリストを動かす範囲に指定しています。
例3. のように、変数を使った処理の結果 は数値に限らず任意の型の要素をとることができます。この例では処理の結果としてリストが得られています。そのため、リスト内包表記全体として得られるものはネストしたリスト(二重リスト)になっています。
もうひとつ例を紹介します。空白で区切られた数値の列を入力を受け取るために内包表記を使うことができます。
次の例は入力として与えられる数値の列をリストで受け取り、その合計を出力します:
入力
3 1 4 1 5
l = [int(item) for item in input.split()] print(sum(l))
出力
14
この例のように、内包表記の「変数を使った処理」で記述する処理は関数呼び出しを使うことも可能です。
組み込み関数に渡す
1.12節で扱った組み込み関数に対し、内包表記で引数を与えることが可能です。
l = [-3, -1, 1, 2] a = max(v*v for v in l) b = min(v*v for v in l) c = sum(v*v for v in l) print(a,b,c)
出力
9 1 15
上記の例ではリストの要素をそれぞれ二乗した値の最大 / 最小 / 総和を max / min / sum 関数を使って計算しています。これらの関数は内包表記2を引数として受け取れるように実装されているため、このような書き方が可能です。
もちろん、a = max([v*v for v in l]) のようにリスト内包表記で作ったリストを関数に渡しても同じ結果になります。
この場合リストを作る処理が一度行われるため、計算速度・メモリ使用量が僅かではありますが大きくなります。
if 文によるフィルタリング
内包表記の for 文では直後に if 文をつなげて書くことが可能です。この場合、リストの要素は if 文の判定が真である要素のみに絞り込まれ(フィルタリングされ)ます。
ひとつ例を示します:
l = [3, 1, 4, 1, 5] l_only_even = [v for v in l if v%2==0] l_only_odd = [v for v in l if v%2==1] print(l_only_even) print(l_only_odd)
出力
[4] [3, 1, 1, 5]
この例では与えられたリストに対し、そのうち偶数/奇数であるもののみからなるリストを作成しています。
l_only_odd のように該当する要素が複数ある場合、元のリストにおける順番で取得されます。
整理すると、
[(変数を使った処理) for (変数名) in (変数を動かす範囲) if (条件式)]
のように書くことで
* 変数を使った処理 の結果を要素に持ち、
* 変数は for 文で指定の範囲を動くが、
* 条件式 が True の範囲のみに絞り込んだ
ような要素からなるリストを得ることができます。
(発展) 複雑な内包表記
発展として、より複雑な内包表記の記法について説明します。
ただし、ここに示す書き方はコードを短く書くには便利ですが、内包表記を使わずに同じ処理を実現することもできるため、必ずしも習得する必要はありません。
興味のある方はご覧ください。
二重ループを伴う内包表記
前節で二重ループを扱いましたが、内包表記でも同様に書くことが可能です。
次の例は2つのリストが与えられたときに、それぞれから1つの要素を取るリストを要素に持つ二重リストを計算しています:
xs = [1, 2, 3]
ys = ["a", "b", "c"]
xys = []
for x in xs:
for y in ys:
xys.append([x,y])
print(xys)
出力
[[1, 'a'], [1, 'b'], [1, 'c'], [2, 'a'], [2, 'b'], [2, 'c'], [3, 'a'], [3, 'b'], [3, 'c']]
このコードは次のように内包表記で書き換えることが可能です。
xs = [1, 2, 3] ys = ["a", "b", "c"] xys = [[x,y] for x in xs for y in ys] print(xys)
多重の for 文の場合でも、for 文を通常通り書いたものをリストの中に入れ込めばよいです。
若干複雑な記法になるため、難しく感じる場合は冒頭のように二重ループを使って書くほうが確実でしょう。
ネストした内包表記
先程のコードを少し変えた例を紹介します。次のコードはどのような出力になるでしょうか?
xs = [1, 2, 3] ys = ["a", "b", "c"] xys = [[[x,y] for x in xs] for y in ys] print(xys)
このコードでは内側のリスト内包表記 [(x,y) for x in xs] が外側のリスト内包表記における 変数を使った処理 に相当します。
そのため、リストを要素として持つリスト、すなわち二重リストが生成されます:
出力
[[[1, 'a'], [2, 'a'], [3, 'a']], [[1, 'b'], [2, 'b'], [3, 'b']], [[1, 'c'], [2, 'c'], [3, 'c']]]
ネストした内包表記が複雑だと感じる場合、以下のように二重ループを使うか、1つのループと1つの内包表記に分解することもできます:
xys = []
for y in ys:
item = []
for x in xs:
item.append([x,y])
xys.append(item)
xys = []
for y in ys:
xys.append([[x,y] for x in xs])
はじめのうちは自分が書きやすいと感じる方法を使って慣れていくのが良いでしょう。
二重ループとフィルタリングとの組み合わせ
上述した二重ループを伴う内包表記、ネストした内包表記はいずれも if 文を用いたフィルタリングと組み合わせることが可能です。
二重ループとフィルタリングの組み合わせの例を以下に示します:
xs = [1,2,3] ys = [4,5,6] # 和が3の倍数である (x,y) のリスト xys_filter = [[x,y] for x in xs for y in ys if (x+y)%3==0] print(xys_filter)
出力
[[1, 5], [2, 4], [3, 6]]
二重ループにフィルタリングも組み合わせると、慣れているプログラマにとっても読みづらくなるため、あまり推奨はしません。このような場合は通常の for 文で記述したほうが良いでしょう。
この例は次のようにすれば内包表記を使わずに記述することができます:
xys_filter2 = []
for x in xs:
for y in ys:
if (x+y)%3==0:
xys_filter2.append([x,y])
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 二次元配列 = リストを要素として持つリストで、数値が縦横に並んだデータ
- 二次元配列
aに対してa[i][j]とすることでその i 行 j 列の要素にアクセスできる - 二次元配列
aに対してlen(a)とすることでaの行数を、len(a[0])とすることでaの列数を取得できる [list(map(int, input().split())) for _ in range(N)]とすることで行数 N の二次元配列を入力から受け取ることができる[[0]*M for _ in range(N)]とすることですべての値が 0 のサイズ N \times M の二次元配列を作ることができる[[] for _ in range(N)]とすることでサイズ N\times 0 の二次元配列(空リストを N 個含むリスト)を作ることができる
二次元配列
第一章では複数の要素を含むデータ構造であるリストを扱いました。
l = [1,3,5,7]
実はリストの要素は数値に限る必要はありません。次のように様々な型の要素を並べて保持することが可能です:
l = [1, None, "hoge", False]
特に、「数値を要素に持つリスト」を要素として持つリストのことを二次元配列といいます。
a = [[1,3,5],[2,4,6]]
この場合、リストの 0 番目の要素は [1,3,5] というリスト、1 番目の要素は [2,4,6] というリストになります。
print(a[0]) print(a[1])
出力
[1, 3, 5] [2, 4, 6]
このように数値が行方向・列方向に並んだものは数学においては行列と呼ばれますが、競技プログラミングにおいても頻出するデータ構造になります。
行列の中の数値に直接アクセスしたい場合、カッコをつなげることでが可能です。
print(a[0][0]) print(a[1][1]) print(a[0][-1])
出力
1 4 5
二次元配列のイメージがうまく湧かない方は C++ 版のこちらの記事も参考にしてみてください。
二重ループと二次元配列
理解を深めるために、2.02節で扱った多重 for 文を利用することで二次元配列の要素を出力してみましょう1。
a = [[1,3,5],[2,4,6]]
for i in range(len(a)):
print(f"リストの第 {i} 成分は {a[i]} です")
for j in range(len(a[i])):
print(f"リストの第 ({i}, {j}) 成分は {a[i][j]} です")
出力
リストの第 0 成分は [1, 3, 5] です リストの第 (0, 0) 成分は 1 です リストの第 (0, 1) 成分は 3 です リストの第 (0, 2) 成分は 5 です リストの第 1 成分は [2, 4, 6] です リストの第 (1, 0) 成分は 2 です リストの第 (1, 1) 成分は 4 です リストの第 (1, 2) 成分は 6 です
上記の例では行 (i) 方向と列 (j) 方向について二次元配列全体を走査しています。
具体的には以下のような処理が行われています:
len(a)とすることで二次元リストの長さ(ここでは2)を取得していますiを 0 以上len(a)未満の整数値で動かしながらa[i]とすることで内側のリストにアクセスしていますlen(a[i])とすることで内側のリストの長さ(ここでは常に3)を取得していますjを 0 以上len(a[i])未満の整数値で動かしながらa[i][j]とすることで内側のリストの要素(数値)にアクセスしています
練習も兼ねて、同じことをするプログラムの別の書き方の挙げます:
a = [[1,3,5],[2,4,6]]
for item in a:
print(item)
for val in item:
print(val)
出力
[1, 3, 5] 1 3 5 [2, 4, 6] 2 4 6
こちらの例では以下のような流れで二次元リスト全体を走査しています:
* for item in a: とすることで変数 item に二次元配列の要素(=内側のリスト)を順に格納しています
* for val in item とすることで内側のリストの要素(=数値)を変数 val に順に格納しています
二次元配列を入力から取得する
競技プログラミングでは入力として二次元配列が与えられることがしばしばあります。
練習として、次のような入力が与えられる状況を考えます:
N M
A_{11} A_{12} \cdots A_{1M}
A_{21} A_{22} \cdots A_{2M}
\vdots
A_{N1} A_{N2} \cdots A_{NM}
1行目に与えられる N は二次元配列の行の数を、M は二次元配列の列の数を示しており、2行目以降には二次元配列の値が N 行にわたって与えられます。各行は M 個の整数からなっています。
この入力から二次元配列を取得してみましょう。以下に3つの方法を示します:
方法 1
N, M = list(map(int, input().split()))
a = []
for i in range(N):
a.append(list(map(int, input().split())))
方法 2
N, M = list(map(int, input().split()))
a = [None]*N
for i in range(N):
a[i] = list(map(int, input().split()))
方法 3
N, M = list(map(int, input().split())) a = [list(map(int, input().split())) for _ in range(N)]
出力
[[1, 3, 5], [2, 4, 6]]
3つの方法はいずれも、1行目で N, M の値を受け取っています。
list(map(int ... の書き方は 1.10 節 で扱った、1行に空白区切りで与えられる数値をリストで取得する方法です。1行の中の要素数(ここでは 2)がわかっている場合はこのように 2 つの変数に直接代入することが可能です。
3つの方法それぞれ2行目以降で二次元配列を受け取っています。
- 方法1 においては
aを最初に空のリストとして定義し、 N 個与えられる行を都度リストに変換してaにappendすることで二次元配列を得ています。 - 方法2 においては
aを長さ N のリストとして定義し、i を 0 以上 N 未満の範囲で動かし、N 個与えられる行を都度リストに変換してa[i]に代入することで二次元配列を得ています。 - 方法3 は前節で扱った内包表記を用いており、1行を読み込んでリストにする処理を N 回行い、二次元配列を得ています。
二次元配列を作成する
要素がすべて 0 の二次元配列を作る
競技プログラミングでは要素がすべて 0 の二次元配列を用意したくなることがしばしばあります。
以下のように書くことでサイズ N \times M の二次元配列を作ることができます:
N = 2 M = 3 a = [[0 for _ in range(M)] for _ in range(N)] # a = [[0] * M for _ in range(N)] としてもよい print(a)
出力
[[0, 0, 0], [0, 0, 0]]
この例では内側の [0 for _ in range(M)]2 が 0 を M 回取得したリスト、すなわちサイズ M の配列を作る処理になっており、それを N 回行うことでサイズ N \times M の二次元配列を作っています。
コメントしているように、内側のサイズ M の配列を作る処理は [0] * M のように記述することも可能です。
N\times 0 の二次元配列を作る
後から配列に要素を追加して使う場合などに N\times 0 の配列を宣言することがあります。
以下のように書くと、N\times 0 の二次元配列になります。
N = 10 a = [[] for _ in range(N)] print(a)
出力
[[], [], [], [], [], [], [], [], [], []]
この書き方では内包表記で「空のリストを作る」処理を N 回繰り返すことで N\times 0 の二次元配列を作成しています。
二次元配列を作成する際の注意
行数と列数の指定方法の注意
サイズ N \times M の二次元配列を作る際に、[[0 for _ in range(N)] for _ in range(M)] のように、N と M を逆にしてしまわないように気を付けてください。内包表記の動作から、最後の range の中に書いた数値が外側のリストのサイズになります。そのため、N を最後に書くことになります。
二次元配列の初期化方法の注意
サイズ N \times M の二次元配列を初期化する際、次のように書いてしまわないように注意してください:
a = [[0] * M] * N
このように書くと配列自体は作成できますが、いずれかのリストに対する変更が全てのリストに共有されるという不具合が生じてしまいます:
a = [[0] * 2] * 3
print("更新前:", a)
a[0][0] = 1
print("更新後:", a)
出力
更新前: [[0, 0], [0, 0], [0, 0]] 更新後: [[1, 0], [1, 0], [1, 0]]
上記のコードでは (0,0) 成分に 1 を代入したため、[[1, 0], [0, 0], [0, 0]] となることが期待されますが、出力を見ると配列の1列目の値がすべて 1 に変更されてしまっています。
この原因の詳細は「ポインタ」等の未解説の概念が必要になるため省略しますが、この記法では二次元配列内のリストがすべて同じ実体を共有するためこのようなことが起こってしまいます。
同様に、N\times 0 の二次元配列を作る際に以下のように書いてしまわないように注意してください:
N = 10 a = [[]] * N
このように書くと、二次元配列内の空リストがすべて同じ実体を持つため、いずれかのリストに対する変更がすべてのリストに共有されてしまいます:
N = 10
a = [[]] * N
print("更新前:", a)
a[0].append(100)
print("更新後:", a)
出力
更新前: [[], [], [], [], [], [], [], [], [], []] 更新後: [[100], [100], [100], [100], [100], [100], [100], [100], [100], [100]]
各要素の長さが異なる二次元配列
これまでの例では二次元配列の中のすべてのリストが同じ長さを持っていましたが、リストを使っていれば各要素の長さは異なっていても問題ありません。
a = [[] for _ in range(4)] a[0].append(10) a[0].append(20) a[2].append(30) a[3].append(40) a[3].append(50) a[3].append(60) print(a)
出力
[[10, 20], [], [30], [40, 50, 60]]
多次元配列
二次元配列を拡張して、三次元、四次元... の配列を作ることも可能です。
次の例では三次元配列を内包表記によって初期化し、次に三重ループでその要素を書き換えています:
N = 2
M = 2
D = 2
lst3d = [[[0]*D for _ in range(M)] for _ in range(N)]
for i in range(N):
for j in range(M):
for k in range(D):
lst3d[i][j][k] = (i,j,k)
print(lst3d)
出力
[[[(0, 0, 0), (0, 0, 1)], [(0, 1, 0), (0, 1, 1)]], [[(1, 0, 0), (1, 0, 1)], [(1, 1, 0), (1, 1, 1)]]]
[[[0]*D for _ in range(M)] for _ in range(N)] の部分で三次元配列を作っています。
この中の [[0]*D for _ in range(M)] はサイズ M \times D の配列を作っています。この処理を後ろから for _ in range(N) で囲むことで、「サイズ M \times D の配列 N 個からなるリスト」すなわちサイズ N \times M \times D の配列を得ています。
より一般に、K 次元配列を作るためには一般には複数の K-1 次元配列を作り、それをリストに入れればよいです。
ABCの問題
ここまでの知識で解ける問題をAtCoder Beginner Contestの過去問題から紹介します。練習問題だけでは物足りない人は挑戦してみてください。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 関数の中で自身を呼び出すことを 再帰呼び出し と言う
- 再帰呼び出しをする関数を 再帰関数 と言う
sys.setrecursionlimitで再帰深さの上限を変更できる
再帰関数を理解するためには関数を理解している必要があります。 1.13. 関数 を復習しておきましょう。
再帰関数は難しいので、説明を読んでみて分からなかった場合はそのまま次に進んでもかまいません。
再帰関数
関数の中で自身を呼び出すことを 再帰呼び出し と言います。
また、再帰呼び出しをする関数を 再帰関数 と言います。
例えば、0 から n までの整数の総和を計算する関数 sum_triangle を考えます。
以下のように実装された関数 sum_triangle は、その処理の中で sum_triangle を呼び出しているので、再帰関数であると言えます。
# 0 から n までの総和を求める
def sum_triangle(n):
if n == 0:
return 0 # 0 から 0 までの総和は 0
s = sum_triangle(n - 1) # 自身を呼び出して 0 から n-1 までの総和を求める
return s + n # n を足して 0 から n までの総和を求める
sum_triangle(3) を呼び出したときの処理の様子を見てみましょう。
以下のスライドは C++ でコードが書かれていますが、やっていることは同じです。
再帰関数の 3 つの部分
再帰関数は、以下の 3 つの部分に分けることができます。
- ベースケース : 簡単に答えが求められる小さいケースは、再帰呼び出しをせず直接答えを求める。
- 再帰呼び出し : 自身を呼び出して、1 つ小さなケースの答えを計算する。再帰呼び出しを繰り返すことで、必ずベースケースに到達することができる。
- 答えの計算 : 再帰呼び出しの結果を利用して、答えを計算する。
def sum_triangle(n):
if n == 0: # ベースケース
return 0
s = sum_triangle(n - 1) # 再帰呼び出し
return s + n # 答えの計算
sum_triangle の例では、n == 0 の場合がベースケースで、n > 0 のときは再帰呼び出しをして答えを計算しています。
再帰呼び出しのたびに n が 1 小さくなるので、(最初に 0 以上の整数が与えられた場合は)必ずベースケースに到達します。
この条件が満たされない場合、再帰呼び出しをどれだけ繰り返してもベースケースに到達しないので、無限ループになって RE や TLE が発生することに注意しましょう。
再帰関数の例
いくつかの再帰関数の例を見てみましょう。これらの例は、再帰関数を使わず for 文や while 文を使って実装することも可能です。
階乗
# 入力 : 0 以上の整数 n
# 出力 : n の階乗 (1 から n までの総積) を返す
def factorial(n):
# ベースケース : 0 の階乗は 1, 1 の階乗は 1
if n == 0 or n == 1:
return 1
# 再帰呼び出し : 1 から n-1 までの総積を計算する
s = factorial(n-1)
# 答えの計算 : 1 から n までの総積を計算する
return s * n
この例では、再帰呼び出しのたびに n が 1 小さくなるので、必ずベースケースに到達します。
フィボナッチ数
# 入力 : 0 以上の整数 n
# 出力 : fib(0) = 1, fib(1) = 1, fib(n) = fib(n-1) + fib(n-2) で定められた数列の n 項目を返す
def fib(n):
# ベースケース : fib(0) = 1, fib(1) = 1
if n == 0 or n == 1:
return 1
# 再帰呼び出し : fib(n-1) と fib(n-2) を計算する
f1 = fib(n-1)
f2 = fib(n-2)
# 答えの計算 : fib(n) を計算する
return f1 + f2
この例では、再帰呼び出しのたびに n が 1 または 2 小さくなるので、必ずベースケースに到達します。
各桁の和
# 入力 : 0 以上の整数 n
# 出力 : n を 10 進法で表記したときの各桁の和
def digit_sum(n):
# ベースケース : n が 1 桁ならば、各桁の和は n である
if n <= 9:
return n
# n を 1 の位とそれより上の位に分ける
ones = n % 10 # 1 の位は、n を 10 で割った余りで得られる
other = n // 10 # 1 の位を取り除いて左に詰めることは、10 で割って切り捨てることに相当する
# 再帰呼び出し : 1 より上の位の各桁の和を求める
s = digit_sum(other)
# 答えの計算 : 各桁の和を計算
return s + ones
この例では、再帰呼び出しのたびに n の桁数が 1 小さくなるので、必ずベースケースに到達します。
再帰関数の設計
再帰関数がどのようなものかが分かってきたでしょうか?
再帰関数を実装するには、適切な再帰呼び出しを設計する必要があります。
ここでは、sum_triangle を例として、再帰関数の設計方法を説明します。
1. 入力と出力を決める
まずは、関数の入力(引数)と出力(戻り値)を決めます。sum_triangle の場合は、以下のようになります。
- 入力(引数): 0 以上の整数 n
- 出力(戻り値): 0 から n までの総和
2. 再帰呼び出しを設計する
次に、再帰呼び出しを使った計算の方法を考えます。
出力を計算するために、「引数を少し小さくして再帰呼び出しした結果」を利用できないか考えてみましょう。
sum_triangle の場合、sum_triangle(n-1) は「 0 から n-1 までの総和」を返すので、これに n を加えれば「 0 から n までの総和」を計算できることが分かります。
3. ベースケースを考える
次に、どのような場合がベースケースなのか、つまり「再帰呼び出しを行わずに出力を計算できるか」を考えます。
sum_triangle の場合、n = 0 のとき「 0 から 0 までの総和」は 0 と簡単に計算できるので、これがベースケースとなります。
n = 1, 2 などのケースをベースケースに加えても問題はありませんが、n = 0 がベースケースに含まれていれば sum_triangle(1) や sum_triangle(2) は再帰呼び出しで計算できるので、加える必要はありません。
4. 必ずベースケースに到達することを確認する
最後に、再帰呼び出しを繰り返すことでいつかベースケースに到達することを確認しましょう。
sum_triangle の場合、再帰呼び出しのたびに n が 1 小さくなるので、いつか必ず n = 0 に到達します。
【例題】報告書の伝達時間
この問題は難易度が高めなので、少し考えて分からなかったらヒントや解答例を見るようにしてください。
今までの例は for 文や while 文を使って実装することもできましたが、この例は再帰関数を使わずに実装することが難しく、再帰関数の恩恵を感じることができます。
問題文
あなたは A 社を経営する社長です。 A 社は N 個の組織からなり、それぞれに 0 から N-1 までの番号がついています。組織 0 はトップの組織です。
組織間には親子関係があり、組織 0 以外の N - 1 個の組織にはそれぞれ 1 つの親組織が存在します。
組織 i\ (1 ≤ i ≤ N - 1) の親組織は組織 p_i です。
ここで、ある組織からその組織の親組織をたどることを繰り返すと、必ずトップの組織(組織 0)に到達します。
あなたは全ての組織に報告書を提出するように求めました。
混雑を避けるために、「各組織は子組織の報告書がそろったら、自身の報告書を加えて親組織に送る」ことを繰り返します。子組織が無いような組織は自身の報告書だけをすぐに親組織に送ります。
ある組織から報告書を送ってから、その親組織が受け取るまでに 1 分の時間がかかります。
あるタイミングで一斉に報告書の伝達を開始したときに、トップの組織の元に全ての組織の報告書が揃う時刻(伝達を始めてから何分後か)を求めてください。なお、各組織の報告書は既に準備されているため、報告書の伝達以外の時間はかからないものとします。
制約
- 1 ≤ N ≤ 50
- 0 ≤ p_i ≤ N - 1\ (1 ≤ i ≤ N - 1)
- ある組織からその組織の親組織をたどることを繰り返すと、必ずトップの組織(組織 0)に到達する。
- 入力される値はすべて整数である。
入力
入力は以下の形式で標準入力から与えられる。
N
p_1 p_2 \cdots p_{N-1}
p_0 が存在しないことに注意せよ。
出力
一斉に報告書の伝達を開始してから、トップの組織の元に全ての組織の報告書が揃うまでの時間を出力せよ。
入力例 1
6 0 0 1 1 4
出力例 1
3
この入力例では、組織は次のような関係になっています。
- 組織 1 の親組織は組織 0
- 組織 2 の親組織は組織 0
- 組織 3 の親組織は組織 1
- 組織 4 の親組織は組織 1
- 組織 5 の親組織は組織 4
この関係は次のような図になります。(子組織から親組織の向きに矢印が向いています。)

次の図は、子組織からの報告書が揃った時刻(集まった報告書を親組織へ送った時刻)を青い文字で、各子組織から受け取った時刻を赤い文字で書き込んだものです。

この図から分かるように、トップの組織の元に全ての組織の報告書が揃う時刻は 3 となります。
入力例 2
8 7 4 0 3 2 4 2
出力例 2
5
下記のサンプルプログラムを書き換え、次のスライドのような動作をするようにプログラムを完成させてください。
スライドは入力例 1 のイメージを示したものです。スライドでは引数として children を受け取っていますが、これは必要ありません。
サンプルプログラム
N = int(input())
# p[i] : 組織 i の親組織
p = [-1] + list(map(int, input().split()))
# 2 次元配列 children
# children[i] : 組織 i の子組織の一覧 であるような 2 次元配列
children = [[] for _ in range(N)]
for i in range(1, N):
children[p[i]].append(i)
# 再帰関数 complete_time
# 入力 : 組織番号 x
# 出力 : 組織 x に子組織からの報告書が揃った時刻(報告書を親組織へ送った時刻)
def complete_time(x):
# ここに実装する
...
# 組織 0 の元に報告書が揃う時刻を出力
print(complete_time(0))
ヒント
クリックでヒントを開く
解答例
自分で考えてみたあと、必ず確認してください。
クリックで解答例を開く
N = int(input())
# p[i] : 組織 i の親組織
p = [-1] + list(map(int, input().split()))
# 2 次元配列 children
# children[i] : 組織 i の子組織の一覧
children = [[] for _ in range(N)]
for i in range(1, N):
children[p[i]].append(i)
# 再帰関数 complete_time
# 入力 : 組織番号 x
# 出力 : 組織 x に子組織からの報告書が揃った時刻(報告書を親組織へ送った時刻)
def complete_time(x):
# ベースケース : 子組織が存在しない場合、答えは 0
if len(children[x]) == 0:
return 0
# 子組織が存在する場合、答えは「子組織から報告書が届く時刻」の最大値
return max(complete_time(y) + 1 for y in children[x])
# 組織 0 の元に報告書が揃う時刻を出力
print(complete_time(0))
この問題における組織のような構造を 木構造 といいます。 木構造に関する処理を行う際には再帰関数が有用です。
再帰関数の注意点
再帰深さの上限
Python では、後述するスタックオーバーフローを防ぐために再帰の深さに制限がかけられており、デフォルトでは、1000 回より多く関数呼び出しが連なると RecursionError が発生して RE になります。
実行するコード
def sum_triangle(n):
if n == 0:
return 0
s = sum_triangle(n - 1)
return s + n
print(sum_triangle(1000))
エラー出力
Traceback (most recent call last):
File "/judge/Main.py", line 7, in <module>
print(sum_triangle(1000))
^^^^^^^^^^^^^^^^^^
File "/judge/Main.py", line 4, in sum_triangle
s = sum_triangle(n - 1)
^^^^^^^^^^^^^^^^^^^
File "/judge/Main.py", line 4, in sum_triangle
s = sum_triangle(n - 1)
^^^^^^^^^^^^^^^^^^^
File "/judge/Main.py", line 4, in sum_triangle
s = sum_triangle(n - 1)
^^^^^^^^^^^^^^^^^^^
[Previous line repeated 996 more times]
RecursionError: maximum recursion depth exceeded
(訳) 再帰エラー: 最大再帰深さを超えました
終了コード
256
エラー出力を見ると、4 行目の sum_triangle(n - 1) の再帰呼び出しが 999 回繰り返されて、sum_triangle(1000) の呼び出しと合わせて 1000 回となって最大再帰深さを超えていることが分かります。
再帰深さの上限を変更するには、sys.setrecursionlimit を実行します。
実行するコード
import sys
sys.setrecursionlimit(10 ** 6) # 再帰深さの上限を 1000000 回に変更する
def sum_triangle(n):
if n == 0:
return 0
s = sum_triangle(n - 1)
return s + n
print(sum_triangle(1000))
出力
500500
スタックオーバーフロー
関数の再帰呼び出しでは、呼び出した関数が終わったときに計算を再開できるように、呼び出したときの関数の状態をメモリに保存する必要があります。したがって、関数の再帰が深くなればなるほど多くのメモリを消費します。このとき、メモリの スタック領域 と呼ばれる部分を消費します。スタック領域には上限があり、スタック領域を使い切ると RE が発生します。これを スタックオーバーフロー と言います。
多くの環境(あなたの手元の PC など)では、スタック領域は OS によりデフォルトで数 MB に制限されており、スタックオーバーフローに注意する必要があります。しかし、AtCoder ではこの制限が緩和されており、スタックオーバーフローで RE となるより先に、TLE や MLE となる可能性が高いです。
PyPy での再帰関数の最適化
PyPy は実行時にコンパイルを行なって処理を高速化しており、大抵の場合は CPython より高速ですが、関数呼び出しのインライン化(関数呼び出しを関数の中身に置き換えて関数呼び出しをなくすこと)に関わる処理と再帰関数の相性が悪く、PyPy で深い再帰を実行すると、CPython と比べて遅くなることがあります。
この場合には、再帰関数の実行前に pypyjit.set_param(inlining=0) を実行し、インライン化をしないように設定することで高速化することができます。
設定を元に戻すには pypyjit.set_param("default") を実行します。
詳しい情報は 公式ドキュメント を参照してください。
import pypyjit
def sum_triangle(n):
if n == 0:
return 0
s = sum_triangle(n - 1)
return s + n
pypyjit.set_param(inlining=0) # 以下のコードではインライン化を行わない
print(sum_triangle(1000))
pypyjit.set_param("default") # 以下のコードではインライン化を行う
さらなる再帰関数の例
(以下の例がよくわからない場合は、飛ばして問題ありません。)
クイックソート
再帰を使うことで、ソート関数を自分で実装することができます。
# 入力 : リスト a
# 出力 : a を昇順にソートしたリスト
def quick_sort(a):
# ベースケース : a が空であれば、出力は空のリストである
if len(a) == 0:
return []
# a から要素を 1 つ取り出して p とする
p = a.pop()
# a から p 未満の要素を集めたリストを lo, p 以上の要素を集めたリストを hi とする
lo = []
hi = []
for x in a:
if x < p:
lo.append(x)
else:
hi.append(x)
# 再帰呼び出し : lo と hi をソートする
lo = quick_sort(lo)
hi = quick_sort(hi)
# 答えの計算 : lo と p と hi をこの順に並べたものが a の昇順ソートである
return lo + [p] + hi
この例では、再帰呼び出しのたびに a の長さが 1 以上減少するので、必ずベースケースに到達します。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- プログラムを実行するときには処理内容に応じた実行時間がかかる
- コンピュータの記憶領域(メモリ)は有限であり、プログラムで変数を使用した分だけメモリを消費する
- プログラムの実行時間・メモリ使用量が入力に応じてどのように変化するかを見積もったものを、それぞれ時間計算量・空間計算量という
- 計算量の表記方法としてオーダー記法が存在する
アルゴリズム
ある処理を行うプログラムを作成するときに、どのような計算を行っていくかという計算手順のことをアルゴリズムといいます。
例えば、1 から 100 まで整数の総和を計算するプログラムを考えます。1 + 2 + 3 + \cdots + 99 + 100 と順番に足していくというのは 1 つのアルゴリズムです。これをアルゴリズム A とします。一方、\frac{100 \times (1 + 100)}{2} という式を用いて計算するというのもアルゴリズムです。これをアルゴリズム B とします。
この例のように、プログラムを作成するにあたって複数のアルゴリズムが考えられることがあります。そのような場合には、どちらのアルゴリズムを用いるのかを選ぶことになります。
コンピュータでの計算は一回一回僅かとはいえ時間が掛かるので、計算回数が多くなるほど実行時間が長くなります。より計算回数が少ないアルゴリズムを選択することによって、高速に動作するプログラムを作成できます。
上の例でのアルゴリズム A は 99 回の足し算が必要ですが、アルゴリズム B では足し算・掛け算・割り算の計 3 回の計算で結果を求めることができます。99 回の計算が必要なアルゴリズム A と、3 回の計算が必要なアルゴリズム B、というように必要な計算の回数で大まかな性能を見積もることができます。
アルゴリズムの性能を比較する方法は色々ありますが、1 つの指標として計算量という考え方があります。
計算量
プログラムは入力に対して計算を行い、結果を出力します。このときに必要な計算時間や記憶領域の大きさが入力に対してどれくらい変化するか、ということを示す指標を計算量といいます。
計算量には時間計算量と空間計算量があります。単に計算量という場合、時間計算量を指すことが多いです。
時間計算量
「プログラムの計算のステップ数が入力に対してどのように変化するか」という指標を時間計算量といいます。計算のステップ数とは、四則演算や数値の比較などの単純な演算の回数です。
空間計算量
「プログラムが使用するメモリの量が入力に対してどのように変化するか」という指標を空間計算量といいます。メモリとはコンピュータの記憶領域のことを指し、変数を使用した分だけメモリを消費します。また、文字列や配列などは内部の要素数等に応じてメモリを消費します。
計算量の例
次のプログラムは 1 から N までの総和 (1 + 2 + 3 + \cdots + N) をループを用いて計算するものです。
N = int(input())
s = 0
for i in range(1, N + 1):
s += i
print(s)
このプログラムでは for 文で N 回の繰り返し処理を行っているので、計算ステップ数は入力の N の大小に応じて変わります。N 回の繰り返しを行うので、計算ステップ数はおおよそ N 回になります。このときの時間計算量は次で紹介するオーダー記法を用いて O(N) と表します。
このプログラムで使用している変数は、入力の N の大小に関わらず N と s と i の 3 つです。 このときの空間計算量はオーダー記法を用いて O(1) と表します。
オーダー記法
厳密な計算ステップ数や必要な記憶領域の量は実装に用いるプログラミング言語や実装方法などによって異なるため、計算にかかる時間や記憶領域を厳密に見積もるのは非常に困難です。
このため、時間計算量や空間計算量の表現としてオーダー記法 O(\cdot) がよく用いられます。
例えば、3N^2 + 7N + 4 という式は、オーダー記法を用いて 3N^2 + 7N + 4 = O(N^2) などと表すことができます。これは、N が大きくなると、定数や詳細な係数を無視した場合にこの式が N^2 と同じ、またはそれよりも緩やかに増加することを意味します。
以下の手順によってオーダー記法による表記を得ることができます。
- ステップ 1: 係数を省略する。ただし定数については 1 とする。
- ステップ 2: N を大きくしたときに一番影響が大きい項を取り出し、O(\text{項}) と書く。
- 補足:N^2 + N + 1 という式の場合、「N^2」「N」「1」 それぞれを項といいます。
「一番影響が大きい項」というのは、基本的には N を大きくしていったときに「大きくなるスピードが最も速い項」と考えることができます。例えば N と N^2 を比較すると以下の表のようになるので、N^2 の方がより影響が大きいといえます。
| N | N^2 | |
|---|---|---|
| N = 1 | 1 | 1 |
| N = 10 | 10 | 100 |
| N = 100 | 100 | 10{,}000 |
| N = 1{,}000 | 1{,}000 | 1{,}000{,}000 |
3N^2 + 7N + 4 という式をオーダー記法で表す場合の手順は以下の通りです。
- ステップ 1: 係数を省略して N^2 + N + 1 とする。
- ステップ 2: N^2 + N + 1 で一番影響の大きい項は N^2 なので O(N^2) とする。
同じように 2N + 10 なら O(N) となります。
例題
次の式をそれぞれオーダー記法で表してください。
- N + 100
- 10N + N^3
- 3 + 5
- 2^N + N^2
- 補足:2^N = \underbrace{2 \times 2 \times \cdots \times 2}_{N \text{個}} であり、例えば 2^3 = 2 \times 2 \times 2 = 8 です。
答え
2^N と N^2 の比較は以下の通りです。クリックで答えを開く
2^N
N^2
N = 1
2
1
N = 3
8
9
N = 10
1{,}024
100
N = 30
1{,}073{,}741{,}824(約 10 億)
900
計算量(オーダー記法)の求め方
計算量を求めるには、計算ステップ数について式で表す必要があります。
次のプログラムについて、計算量がどうなるかを考えてみましょう。
N = int(input())
s = 0
for i in range(1, N + 1):
for j in range(1, N + 1):
s += i * j
for i in range(1, N + 1):
s += i
for i in range(1, N + 1):
s += i * i
print(s)
1 つの二重ループと 2 つの一重ループがあるので、計算ステップはおおよそ N^2 + 2N ほどになります。よってこのプログラムの時間計算量は O(N^2) です。
このように、簡単なアルゴリズムであれば厳密な式を求めなくても「N 回の繰り返し処理があるから O(N)」や「1 から N+1 まで回す二重ループがあるから O(N^2)」などと見積もることができます。
例
いくつかの計算量オーダーについて、具体的なプログラムの例を挙げます。
O(1)
次のプログラムは、1 から N までの総和を公式を使って計算するものです。このプログラムの計算量は O(1) です。
""" 1 から N までの総和を公式を使って計算するプログラム 計算量:O(1) """ N = int(input()) s = N * (N + 1) // 2 print(s)
入力
10
実行結果
55
O(N)
次のプログラムは、要素数 N の配列の中に含まれる偶数の個数を数えるものです。このプログラムの計算量は O(N) です。
"""
要素数 N の配列の中に含まれる偶数の個数を数えるプログラム
計算量:O(N)
"""
N = int(input())
a = list(map(int, input().split()))
cnt = 0
for x in a:
if x % 2 == 0:
cnt += 1
print(cnt)
入力
5 1 4 2 5 9
実行結果
2
O(N^2)
次のプログラムは、九九の要領で N \times N マスを埋めるものです。このプログラムの計算量は O(N^2) です。
"""
九九の要領で N × N マスを埋めるプログラム
計算量:O(N^2)
"""
N = int(input())
table = [[0 for j in range(N)] for i in range(N)]
for i in range(N):
for j in range(N):
table[i][j] = (i + 1) * (j + 1) # N × N 回実行される
for row in table:
print(*row)
入力
9
実行結果
1 2 3 4 5 6 7 8 9 2 4 6 8 10 12 14 16 18 3 6 9 12 15 18 21 24 27 4 8 12 16 20 24 28 32 36 5 10 15 20 25 30 35 40 45 6 12 18 24 30 36 42 48 54 7 14 21 28 35 42 49 56 63 8 16 24 32 40 48 56 64 72 9 18 27 36 45 54 63 72 81
N \times N 要素の二次元配列を使っているので空間計算量も O(N^2) となります。
なお、上のプログラムは以下のように書くこともできます。以下の書き方でも時間計算量、空間計算量ともに元の書き方と変わらず O(N^2) となります。
"""
九九の要領で N × N マスを埋めるプログラム
計算量:O(N^2)
"""
N = int(input())
table = [[(i + 1) * (j + 1) for j in range(N)] for i in range(N)]
for row in table:
print(*row)
O(\log N)
まずはじめに簡単に \log について説明をします。
\log_{x} N という式は「x を何乗したら N になるか」を表します。例えば、2^4 = 16 なので、\log_{2} 16 = 4 です。
以下の図を見てください。長さ 8 の棒を長さが 1 になるまで半分に切る(2 で割る)ことを繰り返したときに切る回数は \log_{2} 8 = 3 回です。

このように計算量に出てくる \log は「半分にする回数」を表すことが多いです。
\log N は N に対して非常に小さくなるので、計算量の中に O(\log N) が出てきた場合でも実行時間にそこまで影響しないことが多いです。
オーダー記法では \log の底( \log_{2} 8 の _2 の部分)は省略して書かれることが多いです。
なぜなら、\log の底の違いは定数倍の違いだけとみなすことができ、オーダー記法では定数倍は省略するからです。
次のプログラムは N が 2 で何回割り切れるかを数えるものです。このプログラムの計算量は O(\log N) です。
上に挙げたイメージと同じような処理を行うプログラムなので、ループする回数が最大でも \log_{2} N 回になることが分かります。
"""
N が 2 で何回割り切れるかを数えるプログラム
計算量:O(log N)
"""
N = int(input())
cnt = 0
while N % 2 == 0:
cnt += 1
N //= 2
print(cnt)
計算量のおおまかな大小
主な計算量の大まかな大小は以下のようになります。
O(1) \lt O(\log N) \lt O(N) \lt O(N \log N) \lt O(N^2) \lt O(2^N)
時間計算量なら O(1) 側ほど高速に計算可能で、O(2^N) 側ほど時間がかかります。
これらの関係をグラフに示すと以下のようになります。
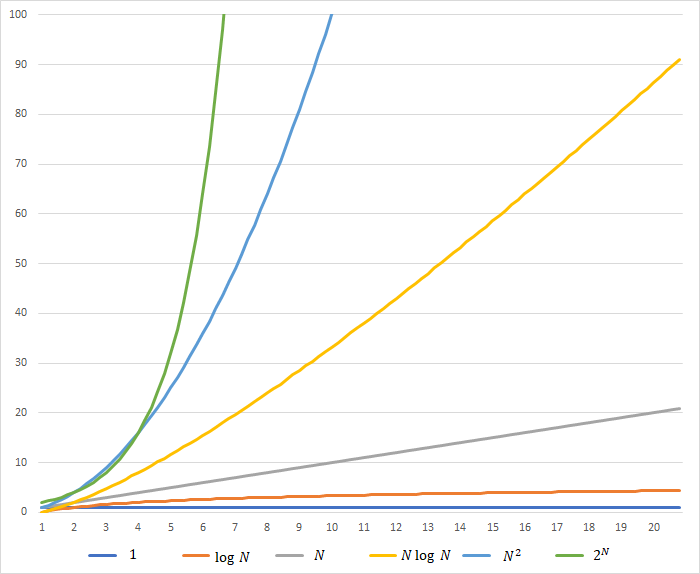
入力 N と実行時間のおおよその感覚との対応を次の表に示します。
| N | O(1) | O(\log N) | O(N) | O(N \log N) | O(N^2) | O(2^N) |
|---|---|---|---|---|---|---|
| 1 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 一瞬 |
| 10 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 一瞬 |
| 1{,}000 | 一瞬 | 一瞬 | 一瞬 | 一瞬 | 0.01 秒くらい | 地球爆発 |
| 10^6 | 一瞬 | 一瞬 | 0.01 秒くらい | 0.2 秒くらい | 3 時間くらい | 地球爆発 |
| 10^8 | 一瞬 | 一瞬 | 1 秒くらい | 30 秒くらい | 3 年くらい | 地球爆発 |
| 10^{16} | 一瞬 | 一瞬 | 3 年くらい | 170 年くらい | 地球爆発 | 地球爆発 |
1 秒くらいで計算が終わるようなプログラムを作りたいときは、入力の大きさの上限を見積もった上で 1 秒以内に収まるような計算量のアルゴリズムを選択する必要があります。
例えば、N = 10^6 くらいまでの入力で 1 秒以内に計算を終えるプログラムを作成するのであれば、O(N^2) のアルゴリズムでは間に合わない可能性が高いので、O(N) や O(N \log N) のアルゴリズムを用いて実装する必要があります。
AtCoder の問題では実行時間制約が 2 秒 ~ 5 秒くらいであることが多いです。コンテストに参加する人は、1 秒あたり 10^8 回くらいの計算ができることを覚えておきましょう。
複数の入力がある場合のオーダー記法
プログラムの入力が複数ある場合もオーダー記法で計算量を表すことができます。この場合それぞれの変数を残して書きます。例えば、2 つの入力 N と M を受け取る場合は O(N+M), O(NM), O((N+M)\log N) などのように書きます。
また、例えば N^2 M + NM + NM^2 という計算ステップ数になった場合は、計算量に影響する入力がひとつのときと同様に影響が一番大きくなりうる項のみを残すので O(N^2 M + NM^2) となります。
どの項を残すのかが分からなくても計算量の比較さえできればよいので問題ありません。複数の入力が計算量に影響することがあるということは頭に入れておきましょう。
細かい話
オーダー記法の落とし穴
計算量をオーダー記法で表記すると比較しやすくなりますが、オーダー記法は大まかな比較しかできない点に注意する必要があります。
オーダー記法では影響の一番大きな項のみを残して係数を省略して書きます。これによって、例えば計算ステップ数が 20N になるアルゴリズムと 2N になるアルゴリズムを比較しようとしたときに、実際には 10 倍もの差があるのに、オーダー記法ではどちらも O(N) となってしまいます。
同様の理由で、O(N) のアルゴリズム A と O(N \log N) のアルゴリズム B を比較するときに、計算量上はアルゴリズム A の方が高速でも、実際に動かしてみるとアルゴリズム B の方が高速だったということも起こり得ます。
正確に比較する必要がある場合は、実際に時間を計測して比較する必要があります。
組み込み関数の計算量
1.12.組み込み関数 で紹介した関数のうち、リストや文字列などを受け取る関数について、計算量は以下のようになります。
| 関数 | 計算量(引数のリスト等の長さを N とする) |
|---|---|
len |
O(1)(以下に補足あり) |
sum |
O(N) |
sorted |
O(N \log N) |
len 関数についてlen 関数は、リストや文字列などの多くの組み込み型に対しては O(1) で動作します。これらの型では要素数が事前に管理されているため、単純な参照で済みます。しかし、カスタムクラスで __len__ メソッドを独自に定義している場合、その計算量は定義内容に依存します。
累乗計算を行う pow 関数についてpow(base, exp, mod) 関数では、指定方法によって計算量が変わります。
mod 引数を指定する場合(例: pow(2, 10, 100))は、モジュロ演算を使うため(mod が非常に大きくなければ)計算量は O(\log(\mathrm{exp})) になります。mod 引数を指定しない場合(例: pow(2, 1000))は、大きな数の掛け算が必要になるため多倍長整数の乗算アルゴリズムに依存した計算量になります。
\log の性質
- O(\log 5N) \rightarrow O(\log N) (\log 5N = \log 5 + \log N なので)
- O(\log NM) \rightarrow O(\log N + \log M) (\log NM = \log N + \log M なので)
- どちらで書いてもよいですが、大きさを考えるときにこの関係を知っていると見積もりやすいかもしれません。
- O(\log N^2) \rightarrow O(\log N) (\log (N^2) = 2 \log N なので)
- O(\log 2^N) \rightarrow O(N) (\log (2^N) = N \log 2 なので)
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
第2章修了

第2章お疲れ様でした。
2.01から2.06までの問題を全てACしたあなたは、実際に全ての「計算処理」を行うプログラムを書ける程の知識を身に着けました。
第3章について
第3章ではプログラミングに本格的に取り組む際に必要になる言語機能について解説します。
これらを習得することで複雑な動作をするプログラムを効率よく実装することが可能になり、多くの競技プログラミングの問題を楽しめるようになります。
学習コンテンツ紹介
AtCoderでは、自由に学習に活用できるコンテンツとして、AtCoderに慣れるための練習問題や、関連書籍の問題を実際に解くことができるコンテストを用意しています。
AtCoderをはじめたばかりの方には、ぜひこれらのコンテンツをご利用いただき、AtCoderの仕組みに慣れていただければ幸いです。
学習コンテンツ紹介
リンク先はAtCoderInfoサイト内にありますので、ご確認ください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
Python ソースコードに現れる要素は概ね以下の3つに分類できる:
- 要素1: 自分で定義した変数や関数
- 要素2: 組み込みで定義された型や関数
- 要素3: import したモジュール
本節の概要と目的
プログラミングを学ぶにあたって、自分でコードを書くだけでなく、他人が書いたり、生成AIによって出力されたコードを読む機会もあると思います。自分で書いていないコードを読むことは、ときにコードを一から書くよりも難しいことがあります。そのようなときでも、コードのひとつひとつの要素の理解があれば、順を追って読むことで処理の内容を理解することが可能です。
本節では Python コードに現れる要素を整理することで、間違いなくコードを理解するための読み方を解説します。
※ 本節の内容はこの後の節の理解には大きく影響しません。読んでみてピンとこない場合は一度飛ばして先に進むことをおすすめします。
Python コードに現れる要素
以下の例をご覧ください。
# 要素1: 自分で定義した変数や関数
a = 0
l = [3,2,1,1]
def func(a):
return 2*a
print(a, l, func, func(a), func(l))
# 要素2: 組み込みで定義された型や関数
t = tuple(l)
sl = sorted(l)
print(t, sl)
# 要素3: import したモジュール
import collections
d = collections.Counter(["a", "b", "a", "c"])
print(d)
出力
0 [3, 2, 1, 1] <function func at 0x7f8894b037e0> 0 [3, 2, 1, 1, 3, 2, 1, 1]
(3, 2, 1, 1) [1, 1, 2, 3]
Counter({1: 2, 3: 1, 2: 1})
処理内容や出力の意味はわからなくても大丈夫です。
以下でコードに現れる要素を整理していきます。
要素1: 自分で定義した変数や関数
第一章で学んだように、変数や関数を自分で定義することができます。
一度定義したこれらの要素はコードの以降の部分で呼び出すことが可能です。
a = 0
l = [3,2,1,1]
def func(a):
return 2*a
print(a, l, func, func(a), func(l))
関数(ここでは func)も「要素」であり print で出力することができます。
要素2: 組み込みで定義された型や関数
Python 言語側が標準で提供している機能もあります。これらは変数や関数と異なり、事前の準備なく呼び出すことが可能です。
t = tuple(l) sl = sorted(l) print(tuple, sorted, t, sl)
tuple は組み込みの型、sorted は組み込み関数になります。
こうした要素はコードに何の前触れもなく登場するため、知っておかないとコードを読み解くことが難しくなります。
競技プログラミングに現れる組み込み機能は種類が限られるため、本教材で学んだものを覚えておけば十分です。
組み込みで定義されている機能の一覧は公式ドキュメントを参照するのがよいでしょう。
要素3: import したモジュール
import collections d = collections.Counter(["a", "b", "a", "c"]) print(d)
import は組み込み機能以外に提供されている Python の標準機能や、自分で外部ファイルに定義した機能を読み込む処理です。
例えば、Python は標準で collections というモジュールを提供しています。collections は競技プログラミングでも役に立つ便利なコンテナ(リストやタプルのようなデータを蓄えるための機能)を複数提供しています。
上記の例でははじめに import 文で collections モジュールを読み込んでいます。
次に collections.Counter という collections が提供するクラスを利用して新たなオブジェクトを定義しています。Counter は要素の個数をカウントできるクラスで、リストを与えることでリストに含まれる要素の個数を辞書形式で返します。
詳しくは collections を扱う4章以降で解説しますが、Counter({'a': 2, 'b': 1, 'c': 1}) という出力結果が示すように、要素の個数がカウントされていることがわかります。
このように、import によって新たな機能を利用することができます。3章の後半ではこの import を使った書き方も登場するため、覚えておくとよいでしょう。
コードの読み方
ここまでで、コードに現れる要素を次の3つに分類しました:
- 要素1: 自分で定義した変数や関数
- 要素2: 組み込みで定義された型や関数
- 要素3: import したモジュール
逆に、これ以外の要素は基本的に現れません。したがって、コードを読んでいて知らない要素が出てきた場合、上に辿っていき以下のいずれかに該当しないかを調べることで、要素が何であるかを必ず明らかにすることができます。
=演算子で定義した変数や、defキーワードで定義した関数でないか?- 公式ドキュメントに乗っている組み込みの型や関数ではないか?
importしたモジュールではないか?
要素の出所を特定したら、それぞれに合った調べ方(変数や関数であれば定義箇所の内容を確認する、組み込み機能やモジュールであればドキュメントを参照する)をすることでその使い方を知ることができます。
競技プログラミングを学ぶ過程では、解説のサンプルコードや他の競技者のコードを参考にすることもあると思います。分からない要素が出てきたときにはこの読み方を思い出してください。
問題
本節には練習問題はありません。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- Python は多くのデータ型を備えており、特に代表的なものに
list,tuple,set,dictが存在する - 扱いたいデータや処理の特徴に応じて使い分けることが望ましい
list / tuple
データの列を扱うことのできるデータ構造
list/tupleの主要な操作
| 操作 | 記法 | 計算量 | list |
tuple |
|---|---|---|---|---|
| 値のアクセス | l[i] |
O(1) | ○ | ○ |
| 値の変更 | l[i] = x |
O(1) | ○ | |
| 末尾への値の挿入 | l.append(x) |
O(1) | ○ | |
| 末尾以外への値の挿入 | l.insert(i, x) |
O(N) | ○ | |
| 末尾の値の削除 | l.pop() |
O(1) | ○ | |
| 末尾以外の値の削除 | l.pop(i) |
O(N) | ○ | |
| 列の長さの取得 | len(l) |
O(1) | ○ | ○ |
| 値の存在判定 | x in l |
O(N) | ○ | ○ |
| 値の出現回数 | l.count(x) |
O(N) | ○ | ○ |
- コード例
# list
l = [3, 1, 4, 1, 5]
print(l[2]) # 4
l[2] = 7
print(l) # [3, 1, 7, 1, 5]
l.append(9)
print(l) # [3, 1, 7, 1, 5, 9]
l.insert(3, 8)
print(l) # [3, 1, 7, 8, 1, 5, 9]
l.pop()
print(l) # [3, 1, 7, 8, 1, 5]
l.pop(0)
print(l) # [1, 7, 8, 1, 5]
print(len(l)) # 5
print(1 in l) # True
print(3 in l) # False
print(l.count(1)) # 2
# tuple
t = (3, 1, 4, 1, 5)
print(t[2]) # 4
print(len(t)) # 5
print(1 in t) # True
print(2 in t) # False
print(t.count(3)) # 1
- [Appendix] その他の操作(Python 公式ドキュメント)
set
集合を扱うことのできるデータ構造
setの主要な操作
| 操作 | 記法 | 計算量 1 |
|---|---|---|
| 値の追加 | s.add(x) |
O(1) |
| 値の削除 | s.remove(x) |
O(1) |
| 集合の要素数の取得 | len(s) |
O(1) |
| 値の存在判定 | x in s |
O(1) |
- コード例
s = {1, 3, 5}
s.add(2)
print(s) # {1, 2, 3, 5}
s.remove(3)
print(s) # {1, 2, 5}
print(len(s)) # 3
print(2 in s) # True
print(3 in s) # False
- [Appendix] その他の操作(Python 公式ドキュメント)
dict
辞書や連想配列と呼ばれるデータ構造
dictの主要な操作
| 操作 | 記法 | 計算量 1 |
|---|---|---|
| 値のアクセス | d[k] |
O(1) |
| 値の追加・更新 | d[k] = v |
O(1) |
| キーの削除 | d.pop(k) |
O(1) |
| 辞書の項目数 | len(d) |
O(1) |
| キーの存在判定 | k in d |
O(1) |
- コード例
d = {3: 31, 1: 31, 4: 30}
d[11] = 30
print(d) # {3: 31, 1: 31, 4: 30, 11: 30}
d.pop(4)
print(d) # {3: 31, 1: 31, 11: 30}
print(len(d)) # 3
print(11 in d) # True
print(4 in d) # False
print(31 in d) # False
- [Appendix] その他の操作(Python 公式ドキュメント)
list
1.10.リスト で扱ったように、list はデータの列を扱うデータ構造です。
キーポイントで触れたように値のアクセス・変更・挿入・削除などができます。
これらは詳しくは 1.10.リスト で扱っていますので、ぜひ復習してみてください。
tuple
tuple も list と同様にデータの列を扱うデータ構造です。list との最大の違いは、(文字列 (str) などと同様に)変更ができないことです。
t = (3, 1, 4, 1, 5) # エラーになる t[0] = 9
エラー出力
Traceback (most recent call last):
File "/judge/Main.py", line 3, in <module>
t[0] = 9
~^^^
TypeError: 'tuple' object does not support item assignment
(意訳:tuple の要素への代入は行えません)
ただ、あくまで tuple の中身の変更ができないだけで、その変数に代入されている tuple 自体を別のものに変更することはできます。
t = (3, 1, 4, 1, 5) # これは OK t = (9, 8, 7)
中身を変更するような操作を除き、tuple でも list と同じような操作を行うことができます。
tuple を作る
tuple()で空のtupleを作ることができます。tupleはlistとは異なり要素を追加することができないので、使うことはほとんどないと思います。
( 要素1, 要素2, 要素3, ... )でtupleを作ることができます。tuple( for 文に入れられるもの )でtupleを作ることができます。tuple([1, 2, 3, 4, 5])などといったように、listをtupleに変換することもできます。
tuple( 内包表記 )でtupleを作ることができます。
# tuple (3, 1, 4, 1, 5) を作り、t に代入する
t = (3, 1, 4, 1, 5)
# いろいろな型を持つデータを 1 つの tuple に入れることができる
t = ("Hello", "AtCoder", 123, 4.5, [])
# 括弧は省略することもできる
t = "Hello", "AtCoder", 123, 4.5, []
# tuple (0, 1, 2, 3, 4) を作る
t = tuple(range(5))
# tuple (0, 1, 4, 9, 16) を作る
t = tuple(i * i for i in range(5))
tuple を作るときの注意点
1 要素の tuple
- 1 要素の
tupleを作るときは、ただ括弧でくくっているだけと区別するため、明示的にカンマをつける必要があります。
t = (3) # カンマをつけないとただ括弧でかこっているだけとされてしまい tuple にならない print(type(t)) # <class 'int'> t = (3,) # 1 要素の tuple を作るときは明示的に最後のカンマをつける必要がある print(type(t)) # <class 'tuple'> t = 3, # 1 要素の tuple を作るときでも括弧は省略することもできる print(type(t)) # <class 'tuple'>
内包表記での初期化
- 内包表記で tuple を初期化するとき、
()でくくるだけだとgeneratorという別のものを作る記法になってしまうため、tuple()でくくる必要があります。
t = [i for i in range(5)] # list ならこの書き方で OK print(type(t)) # <class 'list'> t = (i for i in range(5)) # 上と同じように括弧だけ変えると tuple にならない print(type(t)) # <class 'generator'> t = tuple(i for i in range(5)) # 内包表記で tuple を作るにはこのように書く必要がある print(type(t)) # <class 'tuple'>
tuple の長さ
tuplet に対し、len(t)で t の長さ(要素数)を取得できます。
i 番目の要素
tuplet と整数 i に対し、t[i]で t の i 番目の要素を取得できます。- この i のこと(リストの何番目の要素かを表す番号)を添字(そえじ)と言います。
- 添字は 0 から始まることに注意しましょう。先頭の要素は
t[0]で、末尾の要素はt[len(t)-1](またはt[-1])で取得することができます。
tupleはt[i] = xなどといったような 要素の変更はできない ことに注意しましょう。
for 文で要素を列挙する
tuplet に対し、for x in tで t の要素を順に x に代入して繰り返し処理を行うことができます。
t = (3, 1, 4, 1, 5)
for x in t:
print(x)
出力
3 1 4 1 5
出力する
tuplet に対し、print(*t)で t の要素を空白区切りで出力できます。
t = (3, 1, 4, 1, 5)
# t の要素を空白区切りで出力する
print(*t)
# t の要素を改行区切りで出力する
for x in t:
print(x)
出力
3 1 4 1 5 3 1 4 1 5
tuple のさらなる機能
tuple においても、1.10.リスト - リストのさらなる機能 で紹介した機能の多くを使うことができます(ただし、append, insert, pop などのような中の要素を変更するような機能は使えません)。
packing, unpacking
tuple は、複数の値をひとつの変数に格納していると見ることもできますが、逆に tuple の各要素を別々の変数に格納することもできます。これを、それぞれ packing, unpacking と呼びます。
# 複数の値をひとつの変数に代入 (packing) t = 3, 1, 4, 1, 5 # tuple の各要素を別々の変数に代入 (unpacking) a, b, c, d, e = t # これも OK a, b, c, d, e = (3, 1, 4, 1, 5) # もちろんこれも OK a, b, c, d, e = 3, 1, 4, 1, 5
なので、1.04.変数と型 - 複数の変数への代入 で紹介した x, y = 2, 3 というコードは、(2, 3) という tuple を作り、それを x と y に unpacking していたということになります。
また、x, y = y, x についても同様です。
なお、特に unpacking については list などの他のコンテナでも同様に行えます。
set
set はデータの集合を扱うデータ構造です。集合とは、 重複する要素をもたない、順序づけられていない 要素の集まりです。
Python では、データに対し「ハッシュ値」というものを定義することで集合を扱うデータ構造を実現しています(set を使う上で、基本的には「ハッシュ値」の仕組みについて理解する必要はありません)。
set のメリット
- 追加・削除・存在判定などの操作が高速に行える
set のデメリット
- 同じ要素を複数格納することができない
- 順序を保持することができない
- つまり「i 番目に追加した要素を求める」といったことは基本的にはできない
- また、「i 番目に大きい要素を求める」といったこともできない
例えば、以下のようなコードを書くことができます。
# 30, 10, 40 という 3 要素から set を作り、s に代入する
s = {30, 10, 40}
# s に 50 という要素を追加
s.add(50)
# s に 50 という要素が含まれるかどうかを出力
print(50 in s)
# s から 10 という要素を削除
s.remove(10)
# s に 10 という要素が含まれるかどうかを出力
print(10 in s)
# s の要素を出力
for x in s:
print(x)
出力
True False 40 50 30
set を作る
set()で空のsetを作ることができます。{}だと空のdictになってしまうことに注意してください(dictについてはこの次に説明します)。
{ 要素1, 要素2, 要素3, ... }でsetを作ることができます。set( for 文に入れられるもの )でsetを作ることができます。set([1, 2, 3, 4, 5])などといったように、listからsetを作ることもできます。
{ 内包表記 }でsetを作ることができます。
# 30, 10, 40, 10, 50 という 5 要素から set を作り、s に代入する
# このとき、10 が重複しているので実際には 4 要素の set ができる
s = {30, 10, 40, 10, 50}
# set の中身は順序が保持されるとは限らない
print(s) # {40, 10, 50, 30}
set の要素数
sets に対し、len(s)で s の要素数を取得できます。
# 10 が重複しているので実際には 4 要素の set ができる
s = {30, 10, 40, 10, 50}
print(len(s)) # 4
要素の追加・削除・存在判定
sets と要素 x に対し、s.add(x)で s に要素 x を追加できます。- すでに s に存在する要素を
addしても何も起こりません。
- すでに s に存在する要素を
sets と要素 x に対し、s.remove(x)で s から要素 x を削除できます。- s に存在しない要素を
removeするとエラーになります。 - なお、
s.discard(x)というメソッドもあり、こちらは存在しない要素を指定してもエラーにはなりません(何も起こらない)。
- s に存在しない要素を
sets と要素 x に対し、x in sで s に要素 x が存在するか判定できます(存在するならばTrue、存在しないならばFalseが返る)。- 逆に存在しないか判定したいときは
x not in sと書けます(not (x in s)と同じ)。
- 逆に存在しないか判定したいときは
# 空の set s を作成
s = set()
# s に 100, 200, 300 を追加
s.add(100)
s.add(200)
s.add(300)
print(s) # {200, 100, 300}
# すでに s に存在する要素を add しても何も起こらない
s.add(100)
print(s) # {200, 100, 300}
# s に存在するかどうか判定
print(100 in s) # True
print(404 in s) # False
# s から 100 を削除
s.remove(100)
# s から 100 を削除したので `100 in s` が False になる
print(100 in s) # False
# 存在しない要素を remove するとエラーになるので、条件分岐を挟むとよい
if 404 in s:
s.remove(404)
for 文で要素を列挙する
sets に対し、for x in sで s の要素をひとつずつ x に代入して繰り返し処理を行うことができます。- このとき、要素の列挙される順序は、追加された順や小さい順とは限らないことに注意してください。
s = set()
s.add(100)
s.add(200)
s.add(300)
for x in s:
print(x)
出力
200 100 300
(この出力結果は、実行する環境や Python のバージョンなどで変わる可能性があります)
出力する
sets に対し、print(*s)で s の要素を空白区切りで出力できます。
s = {100, 200, 300}
print(*s)
for x in s:
print(x)
出力
200 100 300 200 100 300
set の注意点
list は set に入れられない
setの要素にはlistを含めることはできません。- これは、
listは整数やstr,tupleなどと違い中身を変更できてしまうからです。 setは中で「ハッシュ値」という値を用いて検索しています。中身が勝手に変わるとこの検索方法が使えないので、Python では「listにはハッシュを定義しない」=「setに入れられない」としています。
- これは、
# エラーにならない
ok = {"Hello", "AtCoder", 123}
# エラーになる
ng = {"Hello", "AtCoder", 123, [4, 5]}
エラー出力
Traceback (most recent call last):
File "/judge/Main.py", line 5, in <module>
ng = {"Hello", "AtCoder", 123, [4, 5]}
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: unhashable type: 'list'
(意訳:list はハッシュ化できません)
set を使ったテクニック
list の重複を除去する
- ある
listを一度setに変換してからもう一度listに変換すると、重複が除去できます。- ただし、順序はバラバラになります。
- 特に、
listl の重複を除去しつつソートしたいときはsorted(set(l))などと書くことができます。
l = [30, 10, 40, 10, 50] # 重複を除去する # ただし順序は保持されない l = list(set(l)) print(l) # [40, 10, 50, 30]
l = [30, 10, 40, 10, 50] # 重複を除去しつつソートする l = sorted(set(l)) print(l) # [10, 30, 40, 50]
set のさらなる機能
set 同士の演算
set では和集合、積集合、差集合などのより高度な集合演算もサポートされています。
なお、これらの演算の計算量は集合の大きさに比例することに注意してください。
集合 (set) が返る演算
| 返り値 | 記法(一例) |
|---|---|
| 和集合(s と t の少なくともどちらかに含まれる要素からなる集合) | s | t |
| 積集合(s と t のどちらにも含まれる要素からなる集合) | s & t |
| 差集合(s に含まれて t に含まれない要素からなる集合) | s - t |
| 対称差集合(s と t の片方だけに含まれる要素からなる集合) | s ^ t |
s = {1, 2}
t = {1, 3}
# 和集合(s と t の少なくともどちらかに含まれる要素からなる集合)
print(s | t) # {1, 2, 3}
# 積集合(s と t のどちらにも含まれる要素からなる集合)
print(s & t) # {1}
# 差集合(s に含まれて t に含まれない要素からなる集合)
print(s - t) # {2}
# 対称差集合(s と t の片方だけに含まれる要素からなる集合)
print(s ^ t) # {2, 3}
真偽値が返る演算
| 判定する内容 | 記法(一例) |
|---|---|
| s と t は集合として一致? (s = t) | s == t |
| s と t は集合として異なる? (s \neq t) | s != t |
| s は t の部分集合? (s \subseteq t) | s <= t |
| s は t の真部分集合? (s \subset t) | s < t |
| s は t の上位集合? (s \supseteq t) | s >= t |
| s は t の真上位集合? (s \supset t) | s > t |
dict
dict は連想配列や辞書と呼ばれるデータ構造です。
dict を用いると、「要素 (key) に値 (value) が紐づいている」といったようなデータを簡単に扱うことができます。
set と同様、Python では、要素 (key) に対し「ハッシュ値」というものを定義することで連想配列を実現しています(なので、set と同様、key に list を用いることはできません)。
例えば、以下のようなコードを書くことができます。
# 各人の氏名にテストの点数を紐づけたデータ
d = {"Alice": 100, "Bob": 89, "Charlie": 95}
# データへのアクセス
print(d["Alice"])
print(d["Bob"])
print(d["Charlie"])
# データの追加
d["Dave"] = 77
print(d)
# データの変更
d["Charlie"] = 59
print(d)
# データの削除
d.pop("Bob")
print(d)
# データを順に出力
for name, score in d.items():
print(name, score)
出力
100
89
95
{'Alice': 100, 'Bob': 89, 'Charlie': 95, 'Dave': 77}
{'Alice': 100, 'Bob': 89, 'Charlie': 59, 'Dave': 77}
{'Alice': 100, 'Charlie': 59, 'Dave': 77}
Alice 100
Charlie 59
Dave 77
dict を作る
{}で空のdictを作ることができます。{ key_1: value_1, key_2: value_2, ... }でdictを作ることができます。
# 同じキーがある場合、より後ろに書かれたものが格納される
d = {"Alice": 100, "Bob": 89, "Charlie": 95, "Alice": -1}
print(d) # {'Alice': -1, 'Bob': 89, 'Charlie': 95}
また、内包表記でも { k: v for ... } という形で書くことで dict を作ることができます
square_root = {i * i: i for i in range(5)}
print(square_root) # {0: 0, 1: 1, 4: 2, 9: 3, 16: 4}
dict の要素数
dictd に対し、len(d)で d の要素数を取得できます。
# "Alice" というキーが重複しているので、要素数 3 の dict が作られる
d = {"Alice": 100, "Bob": 89, "Charlie": 95, "Alice": -1}
print(len(d)) # 3
要素の取得・追加・更新・削除・キーの存在判定
dictd とキー k に対し、d[k]でキー k に割り当てられた値を取得できます。- d に含まれないキーを指定するとエラーになります。
dictd とキー k、値 v に対し、d[k] = vでキー k に v を割り当てます。- すでに d に存在するキーに対して行った場合、割り当てる値を更新する操作になります。
dictd とキー k に対し、d.pop(k)で d からキー k を削除できます。- d に存在しないキーを
popするとエラーになります。
- d に存在しないキーを
dictd とキー k に対し、k in dで d にキー k が存在するか判定できます(存在するならばTrue、存在しないならばFalseが返る)。- 逆に存在しないか判定したいときは
k not in dと書けます(not (k in d)と同じ)。
- 逆に存在しないか判定したいときは
# 空の dict d を作成
d = {}
# d に要素を追加
d[200] = "OK"
d[400] = "Bad Request"
d[418] = "I'm a teapot"
print(d[418]) # I'm a teapot
# すでに存在するキーを指定した場合、上書きされる
d[418] = "(Unused)"
print(d[418]) # (Unused)
# d にキーが存在するかどうか判定
print(200 in d) # True
print(404 in d) # False
# あくまでキーとして存在するかなので、値側のみに存在していても False となる
print("OK" in d) # False
d.pop(418)
# d からキー 418 を削除したので `418 in d` が False になる
print(418 in d) # False
# 存在しない要素にアクセスしたり pop したりするとエラーになるので、条件分岐を挟むとよい
if 404 in d:
print(d[404])
d.pop(404)
また、値が存在しないときに初期化をしてくれる defaultdict というものもあり、これを使用すると存在するかどうかの条件分岐を省略することもできます。defaultdict については 4 章で詳しく説明します。
dict を使う場合
l = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3]
counter = {}
for x in l:
# counter に要素 x が存在しない状態で counter[x] += 1 とするとエラーになるので、
# if 文で判定し、あらかじめ代入しておく
if x not in counter:
counter[x] = 0
counter[x] += 1
for k, v in counter.items():
print(k, v)
defaultdict を使う場合
from collections import defaultdict
l = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3]
counter = defaultdict(int)
for x in l:
# defaultdict の場合エラーにならないので条件分岐が不要
counter[x] += 1
for k, v in counter.items():
print(k, v)
出力(どちらも同じ)
3 2 1 2 4 1 5 2 9 1 2 1 6 1
for 文で要素を列挙する
dictd に対し、for k in d(またはfor k in d.keys())で d のキーを追加された順に k に代入して繰り返し処理を行うことができます。dictd に対し、for v in d.values()で d の値を追加された順に v に代入して繰り返し処理を行うことができます。dictd に対し、for k, v in d.items()で d のキーと値を追加された順にそれぞれ k, v に代入して繰り返し処理を行うことができます。
d = {"Alice": 100, "Bob": 89, "Charlie": 95}
for k in d:
print(k)
for v in d.values():
print(v)
for k, v in d.items():
print(k, v)
出力
Alice Bob Charlie 100 89 95 Alice 100 Bob 89 Charlie 95
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
f"{式}"という書き方で、式の値を埋め込んだ文字列を作ることができる。- 埋め込む値はさまざまなフォーマット指定ができる。
- デバッグ用の情報表示や、複雑な出力形式の整形に便利。
- f-string を用いた
f"{val1} {val2}"という記法は format メソッドを用いた"{} {}".format(val1, val2)や%演算子を用いた"%s %s" % (val1, val2)という記法と等価。
f-string とは
f-string は、変数等を埋め込んだ文字列を作成する際に便利な機能です。
例を見てみましょう。以下のコードは、Hello, Takahashi! と出力します。
name = "Takahashi"
print(f"Hello, {name}!")
この例の f"Hello, {name}!" のような文字列を f-string といい、文字列の先頭に f をつけ、式を {} でくくって書くことでその値を埋め込むことができます。
埋め込むことができる式の値は文字列に限らず、また、1つの文字列の中に複数の式を埋め込むこともできます。
int_val = 123
str_val = "a"
print(f"abc{int_val*2}_{str_val}") # 出力: abc246_a
problem = f"abc{int_val*2}_{str_val}" # 変数 problem の値は 文字列 "abc246_a" になる
できること・使いどころ
f-string 中に埋め込む式の出力フォーマットを細かく指定することもできます。
ここでは競技プログラミングにおいてよく使われる例をいくつか紹介します。ここで紹介するもの以外の詳細は公式ドキュメントを参照してください。
小数点以下の桁数を指定した出力
浮動小数点数を出力する際、小数点以下の桁数を指定することができます。出力される値は、その1つ下の桁で四捨五入1されたものになります。
val = 3.1415
# 小数点以下2桁
print(f"{val:.2f}") # 出力: 3.14
# 小数点以下3桁
print(f"{val:.3f}") # 出力: 3.142
# 小数点以下8桁
print(f"{val:.8f}") # 出力: 3.14150000
数値の10進法以外での出力
2進法、8進法、16進法で出力することができます。
value = 29
# 2進法
print(f"{value:b}") # 出力: 11101
# 8進法
print(f"{value:o}") # 出力: 35
# 16進法
print(f"{value:x}") # 出力: 1d
デバッグ
デバッグの際、プログラムに print 文を追加することで実行途中の変数の値を確認したくなることがあります。もちろん単に print 文を用いてもよいですが、f-string を用いると、式の最後に = をつけるだけで、式そのものとその値を同時に出力することができます。
x = 120
print(f"{x = }") # 出力: x = 120
print(f"{x * 2 = }") # 出力: x * 2 = 240
print(f"{x = :b}") # 出力: x = 1111000
注意
{} 内にクォーテーションを含む場合
python のバージョンが 3.12 より前である場合、f-string 自体を囲むクォーテーションと同じ種類のクォーテーションを {} の中に入れることはできません。
# python 3.11 ではエラー、python 3.12 以降では abc123_a と出力される
print(f"abc123_{"a"}")
# python 3.11 以前でもエラーにならない書き方は以下の通り
print(f"abc123_{'a'}")
format メソッド
f-string は python 3.6 から導入された機能であるため、それ以前の非常に古いバージョンで同様の機能を実現したい場合は、format メソッドや % 演算子を使うことになります。
以下にあげる、f-string を用いた実装、format メソッドを用いた実装、 % 演算子を用いた実装の 3 つのはいずれも同じ結果になります。
int_val = 123
float_val = 3.1415
str_val = "Hello"
# 以下の3つはいずれも "123 7b 3.14 Hello" を出力する
# f-string
print(f"{int_val} {int_val:x} {float_val:.2f} {str_val}")
# format
print("{} {:x} {:.2f} {}".format(int_val, int_val, float_val, str_val))
# % 演算子
print("%d %x %.2f %s" % (int_val, int_val, float_val, str_val))
print, str の機能のみで実現できること
単にいくつかの値を1行にまとめて出力したい場合などは、print メソッドの適切な使い方や、文字列の結合などを用いることで、f-string を使わずに実現することもできます。
val1 = "abc" val2 = 123 print(val1 + str(val2)) # 出力: abc123 print(val1, val2) # 出力: abc 123 print(val1, val2, sep=",") # 出力: abc,123
チートシート表
| やりたいこと | 記述例 |
|---|---|
| 小数点以下の桁数を指定 | f"{val:.13f}" |
| 指数形式にする | f"{val:e}" |
| 2進法にする | f"{val:b}" |
| 16進法にする | f"{val:x}" |
| leading zeroを含て桁数を指定 | f"{val:013}" |
値が負でないとき先頭に + をつける |
f"{val:+}" |
| パーセンテージにする | f"{val:%}" |
| 3桁ごとにカンマで区切る | f"{val:,}" |
| 指定した幅に右詰め | f"{val:>13}" |
| 指定した幅に左詰め | f"{val:<13}" |
これらは複数組み合わせて使うこともできます。例えば f"{val:032b}", f"{val:.3e}" など。
問題
本節には練習問題はありません。
-
正確には、 round() メソッド同様の偶数丸めとなります。1.5, 2.5, 3.5 をそれぞれ
f"{x:.0f}"で出力した結果を確認してみてください。 ↩
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- 「0」か「1」の2通りの状態を表現することができるデータの単位を ビット といい、ビットを複数並べたものを ビット列 という。
- Pythonではビット列を直接扱う型は用意されていないが、 int 型の整数を2進法表記したものをビット列とみなして、ビット毎の演算を行うことができる。
- 具体的には、次の表のような ビット演算 ができる。
| ビット演算 | 演算子 | 意味 | 例(10進表記) | 例(2進表記) |
|---|---|---|---|---|
| ビット毎のAND演算 | & |
各ビットについて「両方のビットが1ならば1」という操作を適用する。 | 6 & 3 → 2 |
110 & 011 = 010 |
| ビット毎のOR演算 | \| |
各ビットについて「少なくとも一方のビットが1ならば1」という操作を適用する。 | 6 \| 3 → 7 |
110 \| 011 = 111 |
| ビット毎のXOR演算 | ^ |
各ビットについて「どちらか一方だけが1ならば1」という操作を適用する。 | 6 ^ 3 → 5 |
110 ^ 011 = 101 |
| 左シフト演算 | << |
指定したビット数だけビット列を左にずらす。 | 3 << 2 → 12 |
11 → 1100 |
| 右シフト演算 | >> |
指定したビット数だけビット列を右にずらす。範囲外のビットは切り捨てられる。 | 13 >> 2 → 3 |
1101 → 11 |
| ビット毎のNOT演算 | ~ |
各ビットについて「ビットを反転する」という操作を適用する。Pythonでは ~x = -(x+1) |
~6 → -7 |
...00110 → ...11001 |
ビット演算
ビット
「0」か「1」の2通りの状態を表現することができるデータの単位を ビット といいます。
ビットを複数並べたものを ビット列 といいます。たとえば 0011 は4ビットのビット列で、 10101010 は8ビットのビット列です。
Python でのビット列の扱い方
Pythonにはbitsetを直接的に扱う型は用意されていません 1 。 int 型でほぼ同様の処理を行うことができます。
この際、整数を2進法で表したものをビット列と同一視し、各桁をビットとみて演算を行います。
整数とビット列の対応
実はこれまで扱ってきた int (整数)型は、コンピュータの内部ではビット列で表現されています。直感的には、整数を 二進法 で表した各桁(0 または 1)をビットとみなし、整数とビット列を対応させています。たとえば十進法の 11 は二進法の 1011 と対応します。
細かい話
すでに学習したとおり、Pythonのint型は符号付きの多倍長整数なので、内部的には通常の固定長(32ビット整数など)とは異なる構造を保持しています。しかし、ユーザー側からすると無限長の 2の補数表現 を仮想的に仮定して演算されている挙動が得られるので、内部的な実装まで気にする必要はありません。2の補数表現というのは負の数を表す方法のひとつです。細かく理解する必要はありませんが、興味がある人は調べてみてください。
ビットごとのAND・OR・XOR演算(& | ^)
ビットごとのAND演算、OR演算、XOR演算はそれぞれ &、 |、 ^ で表現できます。
実行結果
print(6 & 3) # 2 (110 & 011 = 010) print(6 | 3) # 7 (110 | 011 = 111) print(6 ^ 3) # 5 (110 ^ 011 = 101)
ビットシフト(<< >>)
左ビットシフト、右ビットシフトはそれぞれ a << b、a >> b で表現できます。
a および b が非負整数のとき、前者は a * (2 ** b) 、後者は a // (2 ** b) と等価です。
print(3 << 2) # 12 (11 -> 1100) print(13 >> 2) # 3 (1101 -> 0011)
なお、Pythonのintは多倍長整数なので、左右に大きなシフトを行っても誤差なく計算してくれます。
print(1 << 100) # 1267650600228229401496703205376 print(1 << 1000) # 10715086071862673209484250490600018105614048117055336074437503883703510511249361224931983788156958581275946729175531468251871452856923140435984577574698574803934567774824230985421074605062371141877954182153046474983581941267398767559165543946077062914571196477686542167660429831652624386837205668069376 print(100000000000000000000000000000000000 >> 100) # 78886 print(100000000000000000000000000000000000 >> 1000) # 0
ただし、あまりに大きな桁数(十進法で4300桁以上)の整数を「出力」しようとするとエラーになります。
print(1 << 15000) # ValueError
a = 1 << 15000 # 代入するだけならエラーにはならない
なおこれは set_int_max_str_digits で解消できます。
from sys import set_int_max_str_digits set_int_max_str_digits(0) print(1 << 15000) # 28179...09376
負の数のビットシフト
a << b や a >> b の b が負のときはRuntime Errorになります。 a が負のとき、左シフト a << b は非負の場合と同様、 a * (2 ** b) と等価になります。右シフト a >> b は a // (2 ** b) と等価になります。整数除算の丸めはマイナス方向(負の数の場合は絶対値が大きくなる方向)に丸められる点に注意してください。
print(-3 << 2) # -12 print(-13 >> 2) # -4
以下のコードはいずれもRuntime Error(negative shift count)になります。
print(1 << -1) # Runtime Error
print(1 >> -1) # Runtime Error
ビットごとのNOT演算(~)
この演算はややトリッキーであり、実用上も他の演算子で代用できるので、初学者は必ずしも履修する必要はありません。
整数 x に対するビット毎のNOT演算 ~x は、 -(x+1) と等価です。これは仮想的な無限長の2の補数表現を前提にビット毎に反転を行っていると解釈することもできます。負の数のビット表現を前提にしていることから、AND・OR・XORに比べて直感的に理解しづらいかもしれません。
なおこの演算は2回行うと元の整数に戻ります( ~~x = x ) 2 。
print(~6) # -7 print(~-7) # 6 print(~~100) # 100
k ビット反転
NOT演算(~)では符号ビットが変わるためやや複雑になっていました。
k ビットの整数の下 k ビットを反転する場合、NOT演算とマスクを併用するか、下 k ビットの整数とビット毎の排他的論理和を用います。
a = 587 print(bin(a)) # 0b1001001011 mask = (1 << 10) - 1 print(bin(mask)) # 0b1111111111 print(bin(a ^ mask)) # 0b110110100 print(bin((~a) & mask)) # 0b110110100
ビット演算の使い道
ビット演算は集合の演算を行う場合や、高速な演算が必要な場合などに用いられます。
集合の操作
整数をビット列とみなすことで、集合を表現することができます。ある要素を含むなら対応するビットを1に、含まないなら0にすることで表現することができます。
具体例
(以下、〇番目は 0-indexed 3 で表します。)
例えば、0〜4の数が書かれたカードのうち、いくつかを手札として持っているとき、この手札を5ビットの整数(0以上32未満の整数)を用いて表現できます。 ここでは「カードに書かれた数に対応する位置のビットを1にする」というルールで手札をビット列に対応付けることにします。例えば {0, 1, 4} という手札は19という整数に対応します。これは2進法の 10011 と対応します。右から0番目、1番目、4番目のビット(桁)が1になっています。2番目、3番目のカードは持っていないので、2番目・3番目の桁は0になっています。
| 操作 | 対応するビット演算 |
|---|---|
| 2つの集合に共通している要素を取り出す | ビット毎のAND演算 |
| 2つの集合のうち少なくとも一方に存在する要素を取り出す | ビット毎のOR演算 |
| ある集合に含まれない要素取り出す | K要素の集合の場合、M = 2**K - 1とのビット毎のXOR演算 |
もちろん、配列や set を用いて同様の集合演算を行うことは出来ます。 しかし、上の表に挙げたような単純な集合の操作であれば、 ビット演算を用いることでプログラムがシンプルになったり高速になったりするメリットがあります。
コード例
10要素の集合について {0, 1, 3, 4, 5, 8} および {0, 3, 5, 6, 7, 9} について
print(315 & 745) # 41 {0, 1, 3, 4, 5, 8} ∩ {0, 3, 5, 6, 7, 9} = {0, 3, 5}
print(315 | 745) # 1019 {0, 1, 3, 4, 5, 8} ∪ {0, 3, 5, 6, 7, 9} = {0, 1, 3, 4, 5, 6, 7, 8, 9}
M = (1 << 10) - 1 # 1023
print(315 ^ M) # 708 {2, 6, 7, 9}
高速化
ビット演算では1回の演算で複数のビットについての計算をまとめて行うことができるので、この性質をうまく活かすとプログラムを高速化できることがあります。
最下位ビット
整数 x を2進法表記したときの、ゼロでない最も小さいビットは x & (-x) で取得することができます。
x = 12 print(x & (-x)) # 4 x = 99 print(x & (-x)) # 1
注意点
演算子の優先順位
ビット演算に用いる演算子は四則演算に比べ優先順位が低いものが多いので、明示的に ( ) でくくる必要がある場合があります。
優先順位を全て暗記するのは大変なので、ミスを防ぐためにもなるべく ( ) で囲うと良いでしょう。
print(1 << 5 - 1) # 16 print((1 << 5) - 1) # 31 print(1 & 2 + 3) # 1 print((1 & 2) + 3) # 3
主要な演算子の優先順位を以下に示します。上ほど優先度が高いです。
| 演算子 | 説明 |
|---|---|
** |
べき乗 |
+x, -x, ~x |
単項演算子 |
*, /, //, % |
乗除算、整数除算、剰余算 |
+, - |
加減算 |
<<, >> |
ビットシフト |
& |
ビット毎のAND |
^ |
ビット毎のXOR |
\| |
ビット毎のOR |
<, <=, >, >=, !=, == |
比較演算子 |
not x |
否定 |
and |
論理積(かつ) |
or |
論理和(または) |
特定の桁の処理
ビットの取得
整数 i の下から j 番目(0-indexed)のビットを取得したい場合は、右シフトおよびAND演算子でできます。
x = 13 # 2進法で 1101 print((x >> 0) & 1) # 1 print((x >> 1) & 1) # 0 print((x >> 2) & 1) # 1 print((x >> 3) & 1) # 1 print((x >> 4) & 1) # 0 print((x >> 5) & 1) # 0
if 文の判定などでは、 1 を左シフトしたものとANDすることもできます。
x = 13 # 2進法で 1101
for i in range(5):
if x & (1 << i): # x の下から i ビット目が立っている場合に TRUE
print(i)
実行結果
0 2 3
ビット全探索
「ビット全探索」と呼ばれるテクニックを紹介します。ビット全探索とは、長さNのすべてのビット列に対して何らかの処理を行うことをいいます。N要素の集合の部分集合すべてを列挙するとも言えます。
N = 3
for i in range(1 << N):
L = []
for j in range(N):
if (i >> j) & 1: # 下から j 桁目のビットが立っている場合
L.append(j)
print(i, L)
実行結果
0 [] 1 [0] 2 [1] 3 [0, 1] 4 [2] 5 [0, 2] 6 [1, 2] 7 [0, 1, 2]
ビット演算を用いたDP
ビット演算を用いて、各桁をフラグと見てDPのような処理を行うことができます。Pythonのintは多倍長整数なので、それなりに大きな桁(10万桁オーダーなど)でも十分に使えることがあります。
ナップサック問題
N 個の荷物があり、 i 番目の荷物の重さは w_i です。これらから重さの合計が W 以下となるようにいくつかの荷物を選ぶとき、重さの最大値を求めよ。
この問題を解くには、順番に荷物を見て、その時点でどの重さにできるかのリストを更新できれば良いです。リストを使う方法とビット演算を使う方法を比べてみましょう。重さ i が作れる場合、配列では i 番目の要素を1にしますが、ビット演算では下から i 番目のビットを1にします。
リストを使う方法
A = [3, 5, 7, 11] # 荷物の重さ
W = 20 # 重さの最大値
X = [0] * (W+1)
X[0] = 1 # 最初は重さ0だけ可能
for a in A:
for i in range(a, W+1)[::-1]: # 同じ荷物を2回使わないように、大きい方から更新する
if X[i-a] == 1:
X[i] = 1
print(X)
# [1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0]
ビット演算を使う方法
A = [3, 5, 7, 11] # 荷物の重さ
s = 1 # 最初は0番目のbitだけ立てる
for a in A:
s |= s << a
print(bin(s))
# 0b100101011011101110110101001
コードを比べて見ると、配列では2重ループ、ビット演算では1重ループになっています。これは、1回のビット演算で複数ビットを同時に処理していることからループを1つ少なくすることができていると言えます。
2次元グリッドの表現
(ややマニアックなので必ずしも目を通す必要はありません。)
集合の操作の項で説明した内容を応用すると、 H\times W のグリッド上の図形を1つの整数で表現することができます。具体的には、マス (i, j) を i*W+j 番目のビットに対応させると良いです。場合によっては、左右に番兵を置く実装方法も有効です。
問題
以下の2次元グリッドの問題は、ビット演算で実装することができます。
その他の工夫
その他、並列処理による高速化や、ビット演算と加減・乗除算を組み合わせることで様々な処理を行うことができます。多倍長整数のビット演算・四則演算を簡単に扱うことができる点は、Pythonで競技プログラミングをするメリットのひとつであると言えます。ややマニアックな使い方も含むのでここでは割愛しますが、興味がある方は調べてみてください。
ビット演算の計算量
ワードサイズ 4 に収まる場合、1回のビット演算の計算量は O(1) です。桁数が多い場合( 10^{18} 程度を超える場合)は、 k ビット整数のビット演算の計算量はワードサイズを w として O(k/w) です。つまり、ビットごとの計算を並列処理できれば、およそ w 倍の高速化ができることになります。
特定のビットを取り出す処理
Pythonでのビット演算では、特定のビットを取り出す処理の計算量には注意する必要があります。上で紹介した (x >> i) & 1 や x & (1 << i) は定数時間ではなく、 x のビット数 k に比例する時間 O(k/w) がかかります 5 。ただし定数倍はかなり軽いので、多少オーダーが悪そうでも通る可能性はあります。
たとえば以下の処理の計算量は O(N^2/w) です。計算上は N^2 \gt 10^{11} なので厳しそうに見えますが、1秒程度で実行できます 6 。
N = 320000
x = (1 << N) - 1
s = 0
for i in range(N):
if (x >> i) & 1:
s += 1
print(s)
問題
リンク先の問題を解いてください。
EX21.Bitwise Exclusive Or
-
言語によってはビット列を明示的に扱う
bitsetが用意されています。 ↩ -
この性質を用いて、非負整数のインデックスに対して、ある処理を行ったりもとに戻したりする際にNOT演算を使うことで、簡単に反転させるような実装を行うこともできます。 ↩
-
添え字を0から始める数え方 ↩
-
CPUが一度に処理できるビット幅。Pythonの場合、通常は64だと思って問題ないです。 ↩
-
bitsetを直接扱える言語では、特定のビットの取得は O(1) でできる場合が多いです。 ↩ -
2025年9月時点でAtCoderのコードテスト環境で測定。CPython・PyPyいずれも1.0~1.3秒程度。なお判定を
if (x >> i) & 1ではなくif x & (1 << i)にすると、CPythonでは速くなる(600ms程度)がPyPyではやや遅くなる(1500ms程度)。 ↩
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
X if (条件式) else Yは条件式の値がTrueであればX、そうでなければYを値にとる式。- 短絡評価
and演算子の左側の式がFalseの場合、右側の式の評価は行われない。or演算子の左側の式がTrueの場合、右側の式の評価は行われない。
関数名 = lambda 引数: 返り値と記述することで関数を 1 行で定義できる。- 関数定義において
def func(引数名=値)のように記述することで引数にデフォルト値(引数を与えなかった場合に使われる値)を設定することができる
便利な記法
本節ではこれまでに扱わなかった、Python の便利な記法を紹介します。
これらの記法を知ることでコードをより簡潔に書くことができるようになります。また、他の人が書いたコードを理解するのに必要となることもあるでしょう。
三項演算子
X if (条件式) else Y と書くことで、条件式の値が True であれば X 、そうでなければ Y を値にとる式を書くことができます。
次のプログラムでは、「i が偶数なら i そのもの、そうでなければ(奇数なら) i を 100 倍したもの」という式を三項演算子で記述しています1。
l = [(i if i%2==0 else i*100) for i in range(10)] print(l)
実行結果
[0, 100, 2, 300, 4, 500, 6, 700, 8, 900]
次のように書いても同じ結果が得られます:
l = []
for i in range(10):
if i%2==0:
l.append(i)
else:
l.append(i*100)
print(l)
論理演算の処理内容
1.07 節では論理演算子 and と or を扱いました。本節では知っておくと役に立つ、これらの演算の細かい処理内容を説明します。
これらの演算では左から順に与えられた式を評価していき、最終的な結果を返します。このとき、必ずしもすべての式を評価するとは限りません。例えば、A and B の演算において A が False となった場合、B の値によらず式全体の値も False であることが確定します。このような場合、B の評価は行われません。同様に、X or Y の演算において X が True となった場合、Y の値によらず式全体の値も True であることが確定します。この場合も Y の評価は行われません。
このように、不要な評価をスキップして式全体の値を評価を行うことを「短絡評価」と呼びます。
以上をまとめると、次のようになります:
and演算子の左側の式がFalseの場合、右側の式の評価は行われない。or演算子の左側の式がTrueの場合、右側の式の評価は行われない。
例えば次のコードでは2つある if 文のいずれにおいても短絡評価が行われた結果、hello 関数の呼び出しは行われません:
コード例
def hello():
print("Hello")
return True
if True or hello():
print("条件式はTrue")
if False and hello():
print("条件式はFalse")
実行結果
条件式はTrue
ラムダ式
1.13 節では関数定義は以下のように記述することを学びました:
def 関数名(引数):
処理内容
return 返り値
このとき、「処理内容」が存在しない関数であれば、実はこの記述は次のように一行で記述することが可能です。この記法を「ラムダ式」と呼びます:
関数名 = lambda 引数: 返り値
例で確認してみましょう。次の func1 と func2 は全く同じように動作します:
def func1(a):
return a+10
func2 = lambda a: a+10
print(func1(1), func2(1))
実行結果
11 11
慣れないうちは無理にラムダ式を使わず、def ... を使えばよいでしょう。
コードを読む際に lambda ... が出てきたら関数定義をしている、ということが理解できれば十分です。
関数引数のデフォルト値
関数の定義 def 関数名(引数名): において、def 関数名(引数名 = デフォルト値) とすることで、引数を省略したときに デフォルト値 が使われるようになります。
次のコードでは引数 a にデフォルト値 10 を指定しています:
def func(a = 10):
print(a * 3)
func(1) # 引数を与える -> 3
func() # 引数を省略 -> デフォルト値(10) が引数として使われる -> 30
この記法は同じ関数を何度も呼び出すが、一部を除いて同じ値を引数として与えることが殆どであるような場合に重宝します。特に、実装途中に関数に引数を増やした場合に便利です。
例えば以下のようなプログラムを書いたとします:
def add_vals(a):
# リスト a の各要素に対し、先頭から順に 0,1,2,... を足し込む
for i in range(len(a)):
a[i] += i
a = [3,1,2]
b = [4,5,6]
c = [3,3,1]
add_vals(a)
add_vals(b)
add_vals(c)
ここで仮に「c に対してだけ 0,1,2... ではなく 1,2,3... を足したい」となったとします。
同じ関数を使いまわすために、次のように引数を追加してみましょう:
def add_vals(a, start):
# リスト a の各要素に対し、先頭から順に start, start+1, start+2,... を足し込む
for i in range(len(a)):
a[i] += i + start
a = [3,1,2]
b = [4,5,6]
c = [3,3,1]
add_vals(a, 0) # start = 0 -> 0,1,2... が足し込まれる
add_vals(b, 0)
add_vals(c, 1) # start = 1 -> 1,2,3... が足し込まれる
ここで引数 start にデフォルト値 0 を指定することで、例外ケース c のときだけ引数を与えれば済むようになります。
def add_vals(a, start = 0):
# リスト a の各要素に対し、先頭から順に start, start+1, start+2,... を足し込む
# start はデフォルト値 0 を持つ
for i in range(len(a)):
a[i] += i + start
a = [3,1,2]
b = [4,5,6]
c = [3,3,1]
add_vals(a) # start の指定を省略 -> start = 0 が使われる -> 0,1,2... が足し込まれる
add_vals(b)
add_vals(c, 1) # start = 1 -> 1,2,3... が足し込まれる
このように、一度実装したあとに動作を変更したくなることは良くあるため、覚えておくと便利な記法です。
また、コードを読む際もデフォルト値が定義されていることは把握しておく必要があります。
補足と注意
複数のデフォルト値引数
デフォルト値を持つ引数は複数個同時に記述することも可能です。
このとき、呼び出し時に 変数名 = 値 のように記述することで特定の要素のみ値を指定することができます。
変数名を指定しない引数については前から順に割り当てられます。
def func(a=1, b=2):
print(a+b)
func(3,4) # 3 + 4 = 7
func(10) # 10 + 2 = 12
func(b=3) # 1 + 3 = 4
なお、変数名を指定する引数のあとに変数名を指定しない引数を与えるとエラーになるため注意が必要です:
func(a=2, 4) # SyntaxError: positional argument follows keyword argument
位置引数とデフォルト値引数
デフォルト値を持たない引数のことを位置引数と呼びます。
ひとつの関数の引数に位置引数とデフォルト値を持つ引数の両方が存在するとき、位置引数を先に記述しないとエラーになります。
def func(a, b=1):
return a+b
def func(b=1, a):
# SyntaxError: non-default argument follows default argument
return a+b
問題
本節には練習問題はありません。
-
コードの中のカッコは読みやすさのために付しています。無くても結果は変わりません。 ↩
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
l.sort()はlの中身をソートして返り値は返さない。sorted(l)はlの中身は変更せずに新たにソート済みリストを作って返す。- 数値以外にも文字列やタプルなどを要素に持つリストもソートすることができる
sorted関数にはリスト以外に文字列やタプルを与えることが可能- 引数に
reverse=Trueを与えると降順にソートすることができる - 評価値を与える関数や要素同士の比較を行う関数を与えてソートすることもできる。詳細は本文を参照。
いろいろなソート
メソッドと関数
第1章ではリスト l をソートする方法として以下の2つを紹介しました。改めて整理しておきます:
l.sort()としてリスト l の中身を昇順(値の小さい順)に並び変えるl2 = sorted(l)として l の中身を昇順に並べた新たなリスト l2 を作る (l の中身はそのまま)
やり方によって l の中身が変わるのかどうかが異なるので注意してください。特に、
l2 = l.sort()
のように記述しても l2 はリストにはなりません1。
理解の確認のために以下を例を参照してください:
l = [5,4,1,3,2] l2 = sorted(l) print(l, l2) # l は変わっていない, l2 はソートされたリスト l3 = l.sort() print(l3, l) # l はソートされる, l3 は None
実行結果
[5, 4, 1, 3, 2] [1, 2, 3, 4, 5] None [1, 2, 3, 4, 5]
数値以外をソート
ソートされるリストの中身は比較可能なものであれば数値でなくてもよいです。
次の例では、文字列/タプル/リスト をそれぞれ要素にもつリストをソートしています。
l = ["ba", "ac", "a", "abc"] l2 = [(1, 1), (0, 1), (1, 0)] l3 = [[1, 1], [0, 1], [1, 0]] print(sorted(l)) print(sorted(l2)) print(sorted(l3))
実行結果
['a', 'abc', 'ac', 'ba'] [(0, 1), (1, 0), (1, 1)] [[0, 1], [1, 0], [1, 1]]
文字列は辞書順に、タプルやリストは要素の先頭から順に見ていき、最初に現れる異なる要素を比較した結果になります。
文字列と数値の比較はできない(エラーになる)ことに注意してください。
l = ["ba", 0] print(sorted(l)) # TypeError: '<' not supported between instances of 'int' and 'str'
リスト以外をソート
sorted 関数には引数として文字列やタプルなど、リスト以外を与えることが可能です。
# 文字列 -> 各文字が辞書順でソートされ、1文字ずつのリストになる s = "atcoder" print(sorted(s)) # タプル -> 要素がソートされ、リストになる a = (3, 1, 4, 1, 5) print(sorted(a))
実行結果
['a', 'c', 'd', 'e', 'o', 'r', 't'] [1, 1, 3, 4, 5]
降順にソート
以下のように reverse=True 引数を与えることで降順(値の大きい順)にソートすることができます:
l = [1,2,3,4] l2 = sorted(l, reverse=True) print(l2) # [4, 3, 2, 1]
この引数は sort メソッド、sorted 関数のいずれにも与えることが可能です。
l = [1,2,3,4] l.sort(reverse=True) print(l) # [4, 3, 2, 1]
評価指標を与えてソート
要素の値そのものではなく、何らかの評価指標があり、それを基準としてソートをしたいときがしばしばあります。
例として、「整数値のリストを、各値の下1桁でソートする」という問題を考えましょう:
l = [2, 6, 11, 100] # 何らかの処理を行って [100, 11, 2, 6] を得たい
このような場合、以下のいずれかの方法で実現可能です:
方法1: 評価値と元の要素からなるタプルのリストをソートする
一つ目の方法は、先ほど説明した「タプルのソート」を活用します。
- 評価したい値と元の要素を並べたタプルのリストを作る
- そのリストをソートする
- 得られたリストから元の要素を抜き出す
という順で処理します。
「整数の下一桁の値」は「整数を10で割ったあまり」によって得られることに注意してください。
以下がコード例になります:
l = [2, 6, 11, 100] l2 = [(v%10, v) for v in l] # (要素の下一桁, 要素) のリスト print(l2) # [(2, 2), (6, 6), (1, 11), (0, 100)] l2.sort() print(l2) # [(0, 100), (1, 11), (2, 2), (6, 6)] l = [item[1] for item in l2] # l2 の各要素から元の要素を抜き出す print(l) # [100, 11, 2, 6]
方法2: ソートの引数に評価値を与える関数を渡す
ソートの関数は引数 key として関数を渡すことができます。この場合、各要素を関数の返り値が昇順になるようにソートが行われます。
今回の場合、以下のような手順になります。
- 評価値(ここでは数値の下1桁 = 10 で割ったあまり)を計算する関数を実装
- その関数を
key引数として渡してソートを行う
以下のような実装例になります:
l = [2, 6, 11, 100]
def func(x):
return x % 10
l.sort(key = func)
print(l) # [100, 11, 2, 6]
# これは次のように 1 行で記述することも可能:
# l.sort(key = lambda x: x%10)
最後のコメントにあるように、前述のラムダ式を使うことで関数の名称をつけることなく評価指標を与えることも可能です。このようなラムダ式の使い方は競技プログラミングでしばしば出てくるので覚えておくとよいでしょう。
なお、引数 key は sorted 関数を用いる場合も同様に利用することができます。
この「方法2」に慣れるためにいくつかの例を出します。
# x の降順にソート : reverse 引数を使わずに以下のように書くことも可能 l = [2, 6, 11, 100] print(sorted(l, key = lambda x: -x)) # [100, 11, 6, 2] # タプルの2番目の要素でソート l = [(3,1), (4,2), (0,1)] print(sorted(l, key = lambda x: x[1])) # [(3, 1), (0, 1), (4, 2)]
補足 : 「引き分け」の場合のソート順について
上記の最後の例において、(3, 1) と (0, 1) は「タプルの2番目の要素」という評価基準では優劣が付きません。このような場合は元のリストにおける並び順を保ったままになります。上記の例では (3, 1) が (0, 1) よりも先にある、という関係が保たれていることを確認できます。
ソートがこのような性質を持つ場合、安定であるといいます。
比較基準を与えてソート
注意: 本節の内容はやや複雑ですので、飛ばして先に進んでも構いません。
前節の「評価基準を与えてソート」と少し似ていますが、2 つの要素の優劣のつけ方を指定してソートをしたいことがあります。
例として、「タプル (a,b) と (c,d) に対して、 a * d < b * c ならば (a,b) が先になるようにする」という問題を考えましょう。
l = [(3,5), (1,3), (2,4)] # (3,5) と (1,3) の比較: 3*3 > 5*1 なので (3,5) が後 # (3,5) と (2,4) の比較: 3*4 > 5*2 なので (3,5) が後 # (1,3) と (2,4) の比較: 1*4 < 3*2 なので (1,3) が先 # 何らかの処理を行って [(1,3), (2,4), (3,5)] を得たい
この場合もソートに key 引数として関数を与えることで実現することができます。
ただし、以下の点が先ほどと異なります:
- 今回与える関数は 2 つの要素を受け取り大小比較の結果を返すように定義する必要があります。具体的には、以下を満たす必要があります:
- 1つ目の要素が2つ目の要素よりも小さければ負の値を返す
- 1つ目の要素と2つ目の要素が等しい場合は 0 を返す
- 1つ目の要素が2つ目の要素よりも大きければ正の値を返す
- 比較関数関数を
functools.cmp_to_keyという関数でラップしておく必要があります。これは比較関数を評価関数に変換するためのラッパ関数です。なお、functoolsは標準モジュールのひとつで、importすることで利用可能になります。
先の例は次のように記述することができます:
l = [(3,5), (1,3), (2,4)]
# 何らかの処理を行って [(1,3), (2,4), (3,5)] を得たい
def cmp(x,y):
# x,y : 長さ2のタプル -> 書きやすさのためアンパックしておく
a,b = x
c,d = y
if a*d < b*c:
return -1
elif a*d == b*c:
return 0
else:
return 1
import functools
l.sort(key = functools.cmp_to_key(cmp)) # ↑で定義した cmp 関数を functools.cmp_to_key 関数に与える
print(l) # [(1, 3), (2, 4), (3, 5)]
少々複雑ではありますが、想定通りのソートをすることができました。
補足:この比較関数の意味
実はこの比較は (a,b) を分数 a/b で評価してソートすることに相当します。これは b,d が正のとき a/b < c/d と a*d < b*c が同値になることから従います。
そのため今回の例では l.sort(key=lambda x: x[0]/x[1]) としても同じソート結果を得ることができると思います。
しかしながら、割り算の結果として出てくる浮動小数点は実数を厳密に表現できないため、場合によっては正しいソート結果を得られない場合があります。
上記のように比較関数を用いると掛け算のみ(整数のみ)でソート処理を行うことができ、正確なソート結果を得られるようになります。
問題
リンク先の問題を解いてください。
EX22.2つ目の値でソート
ABCの問題
さらに練習問題として以下の AtCoder Beginner Contest の問題を挙げておきます。
この問題は少々意地が悪いですが、本節の内容だけで解くことが可能です。
-
l.sort()の返り値であるNoneになります。 ↩
実行時間制限: 0 msec / メモリ制限: 0 KiB
第3章修了

第3章お疲れ様でした。
この章はこれまでより内容が難しく感じられたかもしれませんが、執筆陣が特に重要と考えるポイントを厳選して紹介しました。
学んだ知識を実際の競技プログラミングの問題で活用しながら、さらに一段上の課題に挑戦していきましょう。
第4章について
第4章では、競技プログラミングで頻繁に使われる Python の標準ライブラリや便利な機能について解説します。
これまでの章で、計算処理の考え方や言語機能の基礎を身につけてきましたが、実際のコンテストでは、正しく実装できることに加えて、限られた時間の中で素早く実装できることも重要になります。
Python には、よくある処理を高速かつ簡潔に書くためのライブラリが数多く用意されています。これらを適切に使いこなすことで、実装量を減らし、ミスの少ないコードを書くことができるようになります。
学習コンテンツ紹介
AtCoderでは、自由に学習に活用できるコンテンツとして、AtCoderに慣れるための練習問題や、関連書籍の問題を実際に解くことができるコンテストを用意しています。
AtCoderをはじめたばかりの方には、ぜひこれらのコンテンツをご利用いただき、AtCoderの仕組みに慣れていただければ幸いです。
学習コンテンツ紹介
リンク先はAtCoderInfoサイト内にありますので、ご確認ください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
permutations関数で並べ替えの全列挙を行うことができるcombinations関数で組み合わせの全列挙を行うことができるproduct関数でネストしたループをまとめることができる
itertools とは
itertools は python の標準モジュールの 1 つです。その名前の通り、イテレーション(ループ処理)を行う際に便利な関数を持っています。
この節では itertools モジュール内の関数のうち、競技プログラミングにおいて比較的使う機会がある permutations, combinations, combinations_with_replacement, product の 4 つの関数について紹介します。
permutations
permutations は、並べ替えの全列挙を行うための関数です。
次のプログラムは [1,2,3] というリストに対してその並べ替え全てを出力しています。
コード
import itertools
for p in itertools.permutations([1, 2, 3]):
print(p)
出力
(1, 2, 3) (1, 3, 2) (2, 1, 3) (2, 3, 1) (3, 1, 2) (3, 2, 1)
permutations 関数には第 2 引数として整数を渡すことができます。その場合、第 1 引数のリストの中からその個数だけ取り出して並べたものを得ることができます。
コード
import itertools
for p in itertools.permutations([1, 2, 3, 4], 2):
print(p)
出力
(1, 2) (1, 3) (1, 4) (2, 1) (2, 3) (2, 4) (3, 1) (3, 2) (3, 4) (4, 1) (4, 2) (4, 3)
permutations 関数は、「タプルを返すジェネレータ」を返します。permutations 関数の戻り値であるジェネレータは、引数に渡したオブジェクトの長さを N 、第 2 引数を K として、必ず {}_NP_K 個1の要素を持ちます。
特に、第 1 引数に渡したリストが重複する値を含む場合、同じ並べ替えが複数回現れます。
コード
import itertools
for p in itertools.permutations("bab"):
print(p)
出力
('b', 'a', 'b')
('b', 'b', 'a')
('a', 'b', 'b')
('a', 'b', 'b')
('b', 'b', 'a')
('b', 'a', 'b')
引数には list, tuple, str, range などのイテラブルオブジェクトを渡すことができます。
練習問題
以下は permutations 関数を使って解ける問題です。
combinations
combinations は組み合わせの全列挙を行うための関数です。
次のプログラムは [1,2,3,4] というリストから 2 個の要素を取り出す方法を全て出力しています。
コード
import itertools
for p in itertools.combinations([1, 2, 3, 4], 2):
print(p)
出力
(1, 2) (1, 3) (1, 4) (2, 3) (2, 4) (3, 4)
combinations 関数は、「タプルを返すジェネレータ」を返します。combinations 関数の戻り値であるジェネレータは、引数に渡したオブジェクトの長さを N 、2 番目の引数として渡した値を K として、必ず {} _ NC _ {K} 2個の要素を持ちます。
特に、第 1 引数に渡したリストが重複する値を含む場合、同じ組み合わせが複数回現れます。
コード
import itertools
for p in itertools.combinations("bbaa", 2):
print(p)
出力
('b', 'b')
('b', 'a')
('b', 'a')
('b', 'a')
('b', 'a')
('a', 'a')
引数には list, tuple, str, range などのイテラブルオブジェクトを渡すことができます。
combinations_with_replacement
combinations_with_replacement は combinations と同様に組み合わせの全列挙を行うための関数です。
次のプログラムは [1,2,3,4] というリストから重複を許して 2 個の要素を取り出す方法を全て出力しています。
コード
import itertools
for p in itertools.combinations_with_replacement([1, 2, 3], 2):
print(p)
出力
(1, 1) (1, 2) (1, 3) (2, 2) (2, 3) (3, 3)
combinations_with_replacement 関数は、「タプルを返すジェネレータ」を返します。combinations_with_replacement 関数の戻り値であるジェネレータは、引数に渡したオブジェクトの長さを N 、2 番目の引数として渡した値を K として、必ず {} _ NH _ {K} 個3の要素を持ちます。
特に、第 1 引数に渡したリストが重複する値を含む場合、同じ組み合わせが複数回現れます。
コード
import itertools
for p in itertools.combinations_with_replacement("bab", 2):
print(p)
出力
('b', 'b')
('b', 'a')
('b', 'b')
('a', 'a')
('a', 'b')
('b', 'b')
引数には list, tuple, str, range などのイテラブルオブジェクトを渡すことができます。
計算量について
permutations, combinations, combinations_with_replacement の 3 つの関数について、その戻り値を for 文で全てループするときの時間量は O(タプルの長さ \times ループ数) となります。4
したがって、通常の for 文と同様の計算量だと考えて問題ありません。参考としていくつかの例を挙げておきます。
| 長さ | |
|---|---|
permutations(range(10)) |
3628800 |
combinations(range(26), 13) |
10400600 |
combinations_with_replacement(range(20), 10) |
20030010 |
combinations(range(500), 3) |
20708500 |
combinations_with_replacement(range(500), 3) |
20958500 |
product
product 関数は、入れ子になったループを1つにまとめるのに役立ちます。
例えば次のような例を考えます。
コード
for x in range(2):
for y in range(3):
print(x, y)
出力
0 0 0 1 0 2 1 0 1 1 1 2
この例では for 文が二重になっています。これを product 関数により次のように書き換えることができます。
import itertools
for x, y in itertools.product(range(2), range(3)):
print(x, y)
これにより複雑なDPを行う際などにループのネストが深くなることを避けることができます。
product 関数には 3 つ以上の引数を与えることができるため、三重ループ以上も同様に1つのループで書くことができます。
product 関数にはキーワード引数 repeat があり、同じ要素のみを繰り返し引数として渡す以下のケースで記述をまとめることができます。
# 以下の2つは同じになる itertools.product(range(5), range(5), range(5)) itertools.product(range(5), repeat=3)
これにより、bit DP を itertools.product(range(2),repeat=20) を用いて実装することもできます。
公式ドキュメント
itertools モジュールに含まれる関数のうち、競技プログラミングで使う機会が多いものは以上となりますが、itertools モジュールはここで紹介したもの以外にも様々な関数を含みます。他の関数について知りたい方は公式ドキュメントを参照してください。
問題
本節にはEX問題はありません。本文中にある練習問題を解いてください。
-
{} _ NP _ K は「N 個の要素から K 個を取り出して並べる方法の個数」を表します。その値は N から降順に K 個の整数の積 N\times (N-1)\times (N-2)\times \dots\times(N-(K-1)) となります。例えば {} _ 8P _ 3=8\times 7\times 6=336 となります ↩
-
{} _ NC _ K は「N 個の要素から K 個を取り出す方法の個数」を表します。その値は N から降順に K 個の整数の積 N\times (N-1)\times (N-2)\times \dots\times(N-(K-1)) を 1 から K までの積で割った値となります。例えば {} _ 8C _ 3=\frac{8\times 7\times 6}{1\times 2\times 3}=56 となります ↩
-
{} _ NH _ K は「N 個の要素から重複を許して K 個を取り出す方法の個数」を表します。その値は N から昇順に K 個の整数の積 N\times (N+1)\times (N+2)\times \dots\times(N+(K-1)) を 1 から K までの積で割った値となります。例えば {} _ 8H _ 3=\frac{8\times 9\times 10}{1\times 2\times 3}=120 となります ↩
-
ただし、各ループが O(タプルの長さ) であることを意味しないことに注意してください。ここでは詳細な説明は省略しますが、「ならし計算量で O(タプルの長さ)」が正確な表現となります。 ↩
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
collections.dequeは両端キューのデータ構造。単なるキューを使いたい場合も、queue.Queueではなくこちらを使うことを推奨。collections.defaultdictはデフォルト値付き辞書。辞書にないキーにアクセスした場合、デフォルト値をセットして返す。collections.Counterは出現数をカウントするデータ構造。
collections とは
collections とは python の標準モジュールの 1 つです。
この節では、競技プログラミングにおいて比較的使う機会の多い deque, defaultdict, Counter の 3 つのクラスについて紹介します。
deque
deque は名前の通り deque (デック、両端キュー) というデータ構造を提供するクラスです1。列の両端への要素の追加、両端からの要素の取り出しを高速に行うことができます。
from collections import deque q = deque([1, 2, 3, 4, 5, 6]) # 左から順に 1, 2, 3, 4, 5, 6 の 6 個の要素が入った deque を生成 val1 = q.pop() # 右端の要素を取り出す。val1 は 6 val2 = q.pop() # val2 は 5 val3 = q.popleft() # 左端の要素を取り出す。val3 は 1 val4 = q.popleft() # val4 は 2 print(q) # 出力: deque([3, 4]) q.append(10) # 右端に要素を追加する。 q.appendleft(20) # 左端に要素を追加する。 print(q) # 出力: deque([20, 3, 4, 10]) print(len(q)) # 出力: 4 print(q[3]) # 出力: 10
pop, popleft, append, appendleft は定数時間で処理されますが、添字による deque 内の要素へのアクセスは線形時間かかることに注意してください。
| 操作 | 最悪計算量 |
|---|---|
| pop | O(1) |
| popleft | O(1) |
| append | O(1) |
| appendleft | O(1) |
| 添字によるアクセス | O(N) (N は要素数) |
以下のコードを、 AtCoder のコードテストで Python(CPython 3.13.7) を選択して実行した場合、case 1 の部分は 10ms 程度、case 2 の部分は 600ms 程度の処理時間がかかります。
from collections import deque
q = deque(range(200000)) # 200000 個の要素が入った deque を作成
# case 1
ans = 0
for _ in range(200000):
ans += q[0] # deque の先頭の要素を取得
print(ans)
# case 1 end
# case 2
ans = 0
for _ in range(200000):
ans += q[100000] # deque の真ん中の要素を取得
print(ans)
# case 2 end
なお、類似の機能を提供する queue.Queue というデータ構造もありますが、こちらは安全性重視の作りになっており2 collections.deque に比べ数倍程度遅いため、競技プログラミングにおいて使う機会はないでしょう。
練習問題
defaultdict
defaultdict は初期値付きの辞書(dict)です。
普通の dict では、存在しないキーにアクセスするとエラー (KeyError) が発生するため、存在しないかもしれないキーにアクセスするときは、get メソッドを用いることになります。
d = dict()
d.get("z", 100) # "z" が d のキーとして存在すればその値を、存在しなければ 100 を返す
# print(d["a"]) # Runtime error
print(d.get("a", 0)) # 出力: 0
# d["x"] += 10 # Runtime error
d["x"] = d.get("x", 0) + 10 # d["x"] は 10 になる
一方、defaultdict では辞書ごとに指定した初期値が自動でセットされます。
from collections import defaultdict d = defaultdict(int) # 0 を初期値とする print(d["a"]) # 出力: 0 d["x"] += 10 # d["x"] は 10 になる
defaultdict の引数に渡すものは「初期値にしたい値を返す関数」だと思うと良いでしょう3。例えば int() は 0 を返すため、defaultdict(int) は初期値が 0 となります。
自身で関数を定義すれば、初期値を自由に定めることができます。
from collections import defaultdict d1 = defaultdict(list) # 空のリストを初期値とする d1["a"].append(0) # d1["a"] は [0] になる d2 = defaultdict(lambda: 100) # 100 を初期値とする d2["x"] += 10 # d2["x"] は 110 になる
defaultdict への要素の追加、読み取りなどの各処理の計算量は、3.02節で説明した dict と同じです。
defaultdict は 便利な一方、意図しないキーにアクセスしたときにもエラーが出ないため、バグを見つけにくくなるデメリットがあります。通常の dict とどちらを使うのがよいか状況に応じて選択してください。
from collections import defaultdict
d1 = defaultdict(int)
N = 10
for i in range(N):
d1[i] = i
d2 = defaultdict(int)
for i in range(N): # range(N-1) を意図していたが誤って range(N) とした
d2[i] = d1[i+1] # d1[N] にアクセスしているがエラーにならない
また、読み出しただけでもそのキーが辞書に追加される点に注意してください。
from collections import defaultdict
d = defaultdict(int)
print(d[123]) # 出力: 0
print(d["x"]) # 出力: 0
print(len(d)) # 出力: 2
print(d) # 出力: defaultdict(<class 'int'>, {123: 0, 'x': 0})
Counter
Counter はその名の通り、数を数えるクラスです。リストなどを引数として渡すと、どの要素が何個あるかを辞書形式にしてくれます。
from collections import Counter
vals = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
c1 = Counter(vals)
print(c1) # 出力: Counter({5: 3, 3: 2, 1: 2, 4: 1, 9: 1, 2: 1, 6: 1})
print(c1[9]) # 出力: 1
print(c1[10]) # 出力: 0
c2 = Counter("abracadabra")
print(c2) # 出力: Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
print(c2["a"]) # 出力: 5
dict と同様に、 .keys(), .values(), .items() により、キー及び値についてイテレーションすることができます。
from collections import Counter
c = Counter([10, 10, 20, 30, 30, 30])
for key, value in c.items():
print(key, value)
実行結果
10 2 20 1 30 3
Counter 同士は加減算を行うことができます。キーが等しいもの同士で演算を行い、値が 0 以下となるものは削除されます。以下の最後の例で d に対応する値が -1 にはならならず、キーそのものが存在しないことに注意してください。
from collections import Counter
c1 = Counter("aaabbc")
c2 = Counter("abbbd")
print(c1) # 出力: Counter({'a': 3, 'b': 2, 'c': 1})
print(c2) # 出力: Counter({'b': 3, 'a': 1, 'd': 1})
print(c1 + c2) # 出力: Counter({'b': 5, 'a': 4, 'c': 1, 'd': 1})
print(c1 - c2) # 出力: Counter({'a': 2, 'c': 1})
Counter 内に存在しないキーにアクセスすると 0 が返されます。defaultdict とは異なりアクセス後もキーが増えることはありません。
from collections import Counter
c1 = Counter("aab")
print(c1) # 出力: Counter({'a': 2, 'b': 1})
print(len(c1)) # 出力: 2
print(c1["x"]) # 出力: 0
print(len(c1)) # 出力: 2
問題
本節にはEX問題はありません。本文中にある練習問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- heapq は優先度付きキューを扱うモジュールで、要素追加と最小値や最大値の取得が可能
- bisect モジュールの関数を利用することでソート済みのリストに対し、一定値以下の要素の個数や値の検索を行うことができる
heapq
heapq は優先度付きキューを実現するためのヒープキューアルゴリズムの実装を提供するモジュールです。
優先度付きキュー
優先度付きキューは次の操作を提供するデータ構造です1:
挿入 : 要素を優先度付きで追加する
参照 : 優先度が最大の要素を取得する
取り出し : 優先度が最大の要素を削除し、それを返す
リストに対して複数の要素を append で追加したのちに pop で取り出すと、追加した順番と逆順で取り出されます。一方、優先度付きキューの取り出しでは追加した順番に関係なく優先度が高い順で取り出されます。
heapq モジュールは「値が小さい = 優先度が高い」とみなす優先度付きキューを実現します。
以下に具体例を示します:
from heapq import heapify, heappop, heappush
a = [4, 6, 1, 8] # リストの定義
heapify(a) # リストの中身がヒープになるように並べ替える
print(a) # [1, 6, 4, 8]
print(a[0]) # 1 : 最小値の参照
print(heappop(a)) # 最小値の取り出し
print(a) # [4, 6, 8]
heappush(a, 2) # 新たな要素の追加
print(a) # [2, 4, 8, 6]
for _ in range(len(a)):
print(heappop(a)) # 2 -> 4 -> 6 -> 8
heappop(a) # エラーとなる!(IndexError: index out of range)
# a は空リストになっているため
上の例では以下のような処理が行われています:
- リスト
aを定義します heapify関数によりaの中身を「ヒープ」になるように並べ替えます。この関数はあくまで並べ替えるだけであり、aは相変わらずリストであることには変わりません。ヒープの詳細は省略しますが、リストの先頭に最小値が来ていることが非常に重要です。heappop(a)によって最小値 1 が削除されます。削除後のリストもヒープ条件が満たされていることを確認してください([4, 6, 8]と先頭に最小値が来ています!)。heappush(a, 2)によって新たな要素 2 を追加します。追加後のリストは[2, 4, 8, 6]であり、やはりヒープ条件が満たされています。リストの先頭以外の要素の順番は入れ替わる可能性があることに注意してください。- 4回の
heappop(a)の呼び出しによって値が小さい方から取り出されます - 空のリストに対する
heappopはエラーになるため注意してください
計算量は以下の通りです。(N は操作対象のリストの要素数)
| メソッド | 計算量 |
|---|---|
heapify |
O(N) |
heappush |
O(\log N) |
heappop |
O(\log N) |
💡 注意
優先度付きキューとして扱っているリストに対して append や pop などの操作を行うとリストがヒープではなくなってしまい、最小値の取得や削除が正しく行えなくなるため注意してください。
from heapq import heapify, heappop, heappush a = [10, 20, 30, 40] heapify(a) a.append(0) print(heappop(a)) # 10 (0 にはならない!)
最大値を優先する優先度付きキュー
最小値ではなく最大値を優先して取り出したい場合、多少の工夫が必要です。
以下の例のように、事前に全ての値を-1倍したリストをヒープ化すると、最小値として「-1 倍する前の最大値を -1 倍したもの」を得ることができます。したがって、得られた値をもう一度 -1 倍することで本来の最大値を得ることができます。
from heapq import heapify, heappop, heappush a = [4, 6, 1, 8] a = [-v for v in a] # 全ての値を -1 倍したリスト heapify(a) x = - heappop(a) # (-1 倍する前の) 最大値を取得し、-1 倍する print(x) # 8 heappush(a, -2) # 2 の追加 ... 追加時にも -1 倍することに注意 y = - heappop(a) print(y) # 6 z = - heappop(a) print(z) # 4
最小値に紐づく要素を取得する方法
要素と値のペアが与えられている設定において、最小値の値そのものではなく、最小値を与える要素を取り出したい場合は「優先度とキーのタプルからなるリスト」をヒープ化すれば良いです。
実装例
from heapq import heapify, heappop, heappush a = [(30, "task_A"), (10, "task_B"), (20, "task_C")] heapify(a) print(heappop(a)) # (10, "task_B") heappush(a, (25, "task_D")) print(heappop(a)) # (20, "task_C") print(heappop(a)) # (25, "task_D")
上の例では、各タスクに値が紐づいています。(値, タスク) のタプルからなるリストをヒープ化することで、値の小さい順にタスクを取り出すことができています。
※ タプルの順番に気を付けてください。(タスク, 値) の順するとタスクが文字列として小さいものから取り出されてしまいます。
優先度付きキューを実現する仕組みや、その他のメソッドについては公式ドキュメントを参照してください。
bisect
bisect はソート済みのリストに対し、指定した要素をソートされた状態を保ったまま挿入するための位置を高速に計算する機能を提供するモジュールです2。
挿入位置の計算
競技プログラミングでは次の2つの関数を使いこなすことが重要になります:
bisect.bisect_left(v, l): リスト3lに値vをソートされたまま挿入できる位置インデックスのうち、最も左のものを返しますbisect.bisect_right(v, l): リストlに値vをソートされたまま挿入できる位置インデックスのうち、最も右のものを返します
両者は挿入する要素 v と等しい要素がリスト中に存在しなければ同じ値を返します。
※ これらの関数は実際の挿入操作をするわけではありません
利用例
from bisect import bisect_left, bisect_right a = [10, 20, 40, 60, 90] # ソート済みのリスト print(bisect_left(a, 30)) # 2 print(bisect_right(a, 30)) # 2 print(bisect_left(a, 60)) # 3 print(bisect_right(a, 60)) # 4 print(bisect_left(a, 99)) # 5 print(bisect_right(a, 99)) # 5 print(bisect_left(a, 5)) # 0 print(bisect_right(a, 5)) # 0
- 30 を挿入する場合、0-indexed で 2 の位置に挿入することができます (
[10, 20, 30, 40, 60, 90])。そのため、値として 2 が返ってきます - 60 は既にリストに存在するため、挿入箇所の候補が2つあります(
[10, 20, 40, 60, 60, 90])。bisect_leftではそのうちの最小値である 3 が、bisect_rightでは最大値である 4 が返ります。 - 99 (リストのどの要素よりも大きい) を挿入できるのはリストの末尾です。そのためリストの要素数 = 5 が返ります。
- 0 (リストのどの要素よりも小さい) を挿入できるのはリストの先頭です。そのため 0 が返ります。
計算量は以下の通りです。(N は操作対象のリストの要素数)
| メソッド | 計算量 |
|---|---|
| bisect_left | O(\log N) |
| bisect_right | O(\log N) |
なお、 bisect_right と全く同じ機能のメソッドが bisect という名前でも提供されていますが、_right をつけた方が取り違いを防ぎやすくなります。
参考:公式ドキュメント
活用方法
以上の説明において、「ソート済みリストへの挿入位置」を知る目的が分からないと思われるかもしれません。
実は bisect_left bisect_right の返り値は次のようにも解釈することができます:
bisect_left(v, l): リストlに含まれるv未満の値を持つ要素の個数bisect_right(v, l): リストlに含まれるv以下の値を持つ要素の個数
この性質はたびたび競技プログラミングで利用することができます。すぐには納得できないかもしれませんが、前項の例と照らし合わせて成り立っていることを確認してみてください。
さらに、次のような解釈も可能です:
bisect_left(v, l): リストlに含まれるv以上の値を持つ要素のうち最も左にあるもののインデックス (存在しない場合はlen(l))bisect_right(v, l): リストlに含まれるvより大きい値を持つ要素のうち最も左にあるもののインデックス (存在しない場合はlen(l))
この性質は「挿入位置を探索する」という当初の役割をうまく言い換えたものになります。この性質を使うとソート済みリストから値を検索することが可能になります。
更に、以下のようなインデックスも検索可能です:
vと等しい値を持つ要素のうち、最も左にあるもののインデックスvと等しい値を持つ要素のうち、最も右にあるもののインデックスv未満の値を持つ要素のうち、最も右にあるもののインデックスv以下の値を持つ要素のうち、最も右にあるもののインデックス
練習問題
ABC253 C - Max - Min Query
ABC217 C - Min Difference
問題
本節にはEX問題はありません。本文中にある練習問題を解いてください。
-
優先度付きキューのアルゴリズムによっては「指定された要素の優先度を変更する」という操作もサポートしますが、
heapqでは提供されていません。
(以下気になる方向け) そのような操作が必要となった場合、「キーと今の優先度の対応を表す辞書を別に保持しておく。優先度変更時には、辞書を更新し、優先度付きキュー内の元の要素に対しては何も行わず、単に新たな要素を優先度付きキューに追加する」とするのが単純な解決方法の1つです。キューから要素を取り出した際には、辞書と照らして今の優先度と一致しているかを確認し、一致していなければ無視する(再び別の要素をキューから取り出す)ことで、古い情報を参照してしまうことを防げます。 ↩ -
二分探索 (binary search) という方法を使用しているためこのようなモジュール名になっています。 ↩
-
本節で現れる「リスト」は全てソート済みとします。 ↩
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
mathモジュールはgcdやsincosなどの数学に関する関数を提供するrandomモジュールはランダムに数値を生成したり、要素を選択する機能を提供するtimeモジュールのtime()関数は時間計測に利用できる
math モジュール : 数学に関する関数・定数
math モジュールは数学に関する関数や定数を定義しています。
数学に関する問題で利用することがあるため、覚えておくとよいでしょう。
約数・倍数に関する演算
gcd と lcm は最大公約数と最小公倍数を求める関数です。
from math import gcd, lcm a = 10 b = 15 g = gcd(a, b) l = lcm(a, b) print(g, l) # 出力: 5 30
次のように任意の個数の数値を引数として与えることができます:
from math import gcd, lcm g1 = gcd(2, 4, 6) g2 = gcd() print(g1, g2) # 2 0 l1 = lcm(2, 4, 6) l2 = lcm() print(l1, l2) # 12 1 a = [8,10,12] print(gcd(*a), lcm(*a)) # 2 120
なお、gcd(0, v) == v となることが約束されています。
組み合わせの数え上げに関する関数
math モジュールには以下のような組み合わせを数える関数も提供されています:
factorial(n):n個のものを一列に並べる並べ方の総数(nの階乗)を返します。comb(n, k):n個の中からk個を重複無く順序をつけずに選ぶ方法の数を返します。perm(n, k):n個の中からk個を重複無く順序をつけて選ぶ方法の数を返します。
しかし、これらの関数が競技プログラミングで使われることは後述の理由により多くありません。
数学関数・定数
以下の関数も利用可能です。いずれも from math import XX(関数名) のようにインポートして利用します。
利用できる関数の一覧は公式ドキュメントを参照ください。
log(x, base = math.e): base を底とする対数を返します。base を省略した場合、自然対数が底として使われます。log10(x): 10 を底とする対数を返します。log2(x): 2 を底とする対数を返します。exp(x): 自然対数の x 乗を返します。sin(x), cos(x), tan(x): サイン、コサイン、タンジェントの値を返します。atan2(y,x): 点(x,y)が座標平面上で x 軸となす角度をラジアンで返します。pi: 円周率 (3.1415...) です。e: 自然対数 (2.7182...) です。
大きな数に関する注意
一部の関数では簡単に大きい値が返ってきます。特に 64bit 整数に収まらないような大きさの整数は競技プログラミングでは一部の特別な問題を除いてあまり扱われず、「(求めるべき)大きな数を 998244353 で割った余りを求めよ」のような形で出題されることがほとんどです。
そのため、これらのライブラリは値が小さいときに限っては利用することが可能ですが、基本的には余りを求められるように特化した実装を別途準備することが必要になります。
from math import comb, factorial, lcm print(comb(100, 20)) # 535983370403809682970 print(factorial(20)) # 2432902008176640000 print(lcm(*[v for v in range(1,50)])) # 3099044504245996706400
練習問題
ABC118C - Monsters Battle Royale (※考察が必要であり、難しいかもしれません)
ABC168C - : (Colon)
random モジュール : ランダムに数値を生成
他のライブラリよりは利用頻度は下がりますが、競技プログラミングではランダムな値を用いることがたびたびあります。確率的に動作するアルゴリズムを実装する場合や、テストケースをランダムに作成する場合などが該当します。
random モジュールはランダムな値を取得するための機能を提供します。
以下によく利用される関数を挙げます:
random(): 0 以上 1 未満のランダムな浮動小数点数を返します。randrange(l, r):range(l, r)の範囲の整数をランダムに選んで返します。choice(l): 空でないリストlの要素をランダムに選んで返します。lが空の場合エラーになります。choices(l, k=1, weights=None): 空でないリストlからk個を重複あり(復元抽出)でランダムに選んで返します。lが空の場合エラーになります。weightsとしてlと同じ長さの数値からなるリストを与えると、各要素の相対的な選択確率がweightsに従うようになります。sample(l, k=1): 長さk以上のリストlからk個を重複なし(非復元抽出)でランダムに選んで返します。lの長さがk未満の場合エラーになります。seed(a=None):aをシードとして乱数生成器を初期化します。同じシードでseed()を呼び出したあとはランダムな関数呼び出しの結果が同一になることが保証されます1。- 以下の例では最初に
seed(0)を呼び出しているため、どの環境で実行しても同じ結果が得られるはずです。 - また、
random()の呼び出しは1回目,3回目で同じ値になります。これはどちらもseed(0)を呼び出した直後に実行しているためです。
- 以下の例では最初に
import random random.seed(0) print(random.random()) # 0.8444218515250481 print(random.random()) # 0.7579544029403025 random.seed(0) print(random.random()) # 0.8444218515250481 print(random.random()) # 0.7579544029403025 print(random.randrange(5,10)) # 8 print(random.choice([1,2,3])) # 1 print(random.choices([1,2,3], k=3, weights=[1,1,100])) # [3, 3, 3] print(random.sample([1,2,3], k=3)) # [2, 3, 1] l = [1,2,3] random.shuffle(l) print(l) # [2, 1, 3]
その他にも、一様分布・指数分布といった分布からサンプリングするための関数も用意されています。
網羅的な機能については公式ドキュメントを参照ください。
また、より強力な乱数生成手法として後述するサードパーティライブラリの numpy における numpy.random モジュールを使う方法もあります。
乱数を大量に用いる場合はこちらの方法のほうが計算速度の面で有利なので覚えておくとよいでしょう。
time
time モジュールは時刻・時間に関する機能を提供します。
ここでは時間計測に使う time() 関数を紹介します。
import time
t0 = time.time() # 処理開始時刻を取得
# 時間のかかる処理を実行
s = 0
for i in range(100000000):
s += i
t1 = time.time() # 処理終了時刻を取得
print(t1 - t0) # 計算時間が出力される
time() 関数は基準日(1970/1/1 00:00)からの経過時間を浮動小数点数(単位=秒)で返します。
この例では処理の開始・終了時にそれぞれ呼び出した結果の差を取ることで、処理にかかった時間を計算しています2。
発展的な使い方として、「同じ処理を1秒間繰り返す」プログラムは次のように記述することができます:
import time
t0 = time.time()
while True:
pass # ここに任意の処理を記述する
if time.time() - t0 > 1:
break
問題
本節にはEX問題はありません。本文中の練習問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
cacheをデコレータとして関数につけることでメモ化できるcmp_to_key関数により、比較関数をキー関数に変換し、ソートの key として渡すことができる
functools とは
functools は python の標準モジュールの 1 つです。関数に対する操作を行う際に便利な関数を持っています。
この節では functools モジュール内の関数のうち、競技プログラミングにおいて比較的使う機会がある cahce, cmp_to_key の 2 つの関数について紹介します。
cache
関数のメモ化
cache について説明するまえに、関数のメモ化について説明します。例えば、次のような再帰関数を考えてみましょう。
def fib(n):
if n <= 0:
return 0
if n == 1:
return 1
return fib(n-1) + fib(n-2)
print(fib(5), fib(6), fib(7)) # 5, 8, 13
この関数で fib(20) を呼ぶと、fib(19) + fib(18) と再帰し、さらに fib(19) は fib(18) + fib(17) と再帰するため、fib(18) は少なくとも2回呼ばれることがわかります。同様に fib(11) は34回1呼ばれ、その全てでfib(11) を計算するためのさらなる再帰が行われます。
しかし、fib 関数は引数のみによって返り値が定まるため、一度 fib(11) が 89 であることがわかれば再計算する必要はありません。このように、計算済みの結果を保持することを関数のメモ化といいます。
メモ化の実装例は次の通りです。
fib_memo = {}
def fib(n):
if n in fib_memo:
return fib_memo[n]
if n <= 0:
return 0
if n == 1:
return 1
fib_n = fib(n-1) + fib(n-2)
fib_memo[n] = fib_n
return fib_n
print(fib(5), fib(6), fib(7)) # 5, 8, 13
functools.cache を用いたメモ化
関数のメモ化は自分で実装することができますが、functools モジュールの cache を使うことでより簡単に実装することができます。
from functools import cache
@cache
def fib(n):
if n <= 0:
return 0
if n == 1:
return 1
return fib(n-1) + fib(n-2)
print(fib(5), fib(6), fib(7)) # 5, 8, 13
cmp_to_key
3.06 いろいろなソート でも既に説明しましたがおさらいしましょう。
sort メソッド及び sorted 関数にはキー関数を与えることができ、キー関数が返す値の順にソートすることができます。
A = [-3, 1, 4, 2, -5] print(sorted(A)) # [-5, -3, 1, 2, 4] print(sorted(A, key=abs)) # [1, 2, -3, 4, -5]
この方法は直感的には「各要素に点数をつけて、その点数の順に並べる」といえます。
一方、「2つの要素を比較して、どちらを前にするか判定する」を繰り返すことでもソートを行うことができます2。キー関数と違い、比較関数を受け取ってその順にソートする機能は sort, sorted にはありませんが、cmp_to_key でラップすることで、キー関数と同様に渡すことができるようになります。
実装例
def compare_by_abs(x, y):
# 絶対値が小さい方を前とするソートのための比較関数
# |x| と |y| を比較し
# |x| の方が小さければ負の値
# |y| の方が小さければ正の値
# |x| と |y| が等しければ 0 を返す
if abs(x) < abs(y):
return -1
if abs(x) > abs(y):
return 1
return 0
from functools import cmp_to_key
A = [-3, 1, 4, 2, -5]
print(sorted(A)) # [-5, -3, 1, 2, 4]
print(sorted(A, key=cmp_to_key(compare_by_abs))) # [1, 2, -3, 4, -5]
この例では単に key=abs としても同様の結果を得ることができるためありがたみは薄いですが、3.06 節により実践的な例があるため、そちらを再度確認してください。
問題
リンク先の問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
fractionモジュールにより有理数型の変数を扱うことができるdecimalモジュールによりDecimal型の変数を扱うことができる
fractions
fractions モジュールが提供する Fraction クラスにより有理数型を扱うことができます。
from fractions import Fraction x = Fraction(1, 2) # 1/2 を表す y = Fraction(1, 3) # 1/3 を表す z = x + y print(z) # 5/6 print(z.numerator, z.denominator) # 5 6 print(x * 4) # 2 print(x / y) # 3/2
Fraction の計算は遅いため、使う必要があるケースを見極める必要があります。
from fractions import Fraction
def f(x):
s = 0
for i in range(10**7):
s += x
f(0.5) # 5.9 ms (AtCoderのコードテストで Python (PyPy 3.11-v7.3.20) を選択し実行した場合, 以下同様)
f(0.286) # 5.4 ms
f(Fraction(1, 2)) # 483 ms
f(Fraction(3, 7)) # 951 ms
f(Fraction(123, 457)) # 1508 ms
decimal
コンピュータの内部では値を 2 進法に変換して保持しています。そのため、2 進法で有限桁で正確に表すことができない小数を含む演算を行うと誤差が発生することがあります。
print(0.1 + 0.2 == 0.3) # False !!!
もし扱う数が 10 進法では有限桁であることが最初から分かっている場合、decimal モジュールが提供する Decimal クラスにより値を扱うことができます。
from decimal import Decimal
a = Decimal("0.1")
b = Decimal("0.2")
c = Decimal("0.3")
print(a + b) # 0.3
print(a + b == c) # True
0.1 など、最初からわかっている値を Decimal 型に変換する際は Decimal(0.1) ではなく Decimal("0.1") と記述する必要があります。 0.1 は 2 進法では有限桁で正確に表すことができないため書いた瞬間から誤差を持ち、誤差を持つ値が Decimal 型に変換されるためです。同様に、float 型で計算したあとの値を Decimal 型に変換しても、それが正確とは限りません。
a = Decimal("0.1")
print(a) # 0.1
x = Decimal(0.1)
print(x) # 0.1000000000000000055511151231257827021181583404541015625
b = 3 / 10
y = Decimal(b)
print(y) # 0.299999999999999988897769753748434595763683319091796875
Decimal 型も float 型と同様、10進法で有限桁で正確に表すことができない小数を含む演算を行うと誤差が発生することがあります。
from decimal import Decimal a = Decimal(1) b = Decimal(3) print(a / b * b) # 0.9999999999999999999999999999 print(a / b * b == a) # False
Decimal 型に対する演算は非常に遅いため、使う必要があるケースを見極める必要があります。
from decimal import Decimal
def f(x):
s = 0
for i in range(10**6):
s+=x
f(0.5) # 1.1 ms (AtCoderのコードテストで Python (PyPy 3.11-v7.3.20) を選択し実行した場合, 以下同様)
f(0.286) # 0.6 ms
f(Decimal(0.5)) # 63 ms
f(Decimal(0.286)) # 1934 ms
f(Decimal(0.123456789)) # 1886 ms
問題
本節には練習問題はありません。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- AtCoder では標準ライブラリ以外の一部のサードパーティライブラリを利用することができる
- 利用可能なサードパーティライブラリは、コンテストページ下部のルールのページから確認可能
- 2025年10月現在の情報はこちら
- 利用可能なサードパーティライブラリとして以下のようなものがある
sortedcontainersモジュールは、二分探索できる set、キーを二分探索できる dict などのデータ構造を持つ- AtCoder Library を Python に移植したモジュールとして
ac-library-pythonモジュール,acl-cpp-pythonモジュールの 2 種類が利用可能 numpy,networkx,pulpなど、競技プログラミング以外の用途でも広く使われているライブラリも利用可能
サードパーティライブラリについて
Python では標準ライブラリ以外に、誰でも自由にライブラリを作成し公開することができます。AtCoder上では様々なライブラリがインストール済みであり利用可能ですが、自身のパソコンで実行する場合にはライブラリをインストールする必要があります。
例えばターミナルで以下のコマンドを入力することで、numpy というライブラリがインストールされを利用できるようになります。
pip install numpy
他のライブラリも同様の方法でインストールすることができます。詳細については一般的なプログラミング解説サイトを参照してください。
AtCoderで利用可能なサードパーティライブラリ
2025年10月現在 AtCoder で利用可能なサードパーティライブラリのうち、利用する機会が比較的多いものをいくつか紹介します。
sortedcontainers
以下では、 sortedcontainers で提供されているデータ構造のいくつかとその使い方について説明します。詳細な説明は公式ドキュメントを参照してください。
github: grantjenks / python-sortedcontainers
SortedSet
次のような2種類の処理を高速に行うことを考えます。
- 要素の追加・要素の削除
- x が与えられ、x 以上の最小の要素を求める
Python の標準ライブラリにはこのような処理を直接行うことができるデータ構造は存在しません。
一方、この処理を直接行うことができるデータ構造が sortedcontainers.SortedSet として提供されています。
3.02.組み込みコンテナ で紹介した set とほぼ同様の使い方ができ、4.03.heapq・bisect で紹介した bisect とほぼ同様に二分探索を行うことができます。
from sortedcontainers import SortedSet s = SortedSet([7, 3, 1, 5]) i = s.bisect_left(4) # s の要素をソートしたリストに対して bisect_left を行ったときと同じ値である 2 が返される print(s[i]) # s の要素をソートしたリストに対して添字アクセスしたときと同じ値である 5 が返される s.add(6) s.discard(5) print(s[s.bisect_left(4)]) # 6
各メソッドの計算量は、 SortedSet が内部で保持する変数 _load の値(デフォルトは 1000 )を M として、次の通りです。
- add, discard, remove などは、平均計算量 \Theta\left(M+\frac{N}{M^2}+\log N\right) です。
- 添字アクセス, bisect などは、 SortedSet に対して変更を加えずに繰り返す場合 \Theta(\log N) です。 SortedSet に対して add や remove を行いながら添字アクセス・ bisect を行う場合、平均計算量は \Theta\left(\frac{N}{M^2}+\log N\right) になります。
SortedSet は、全要素をおよそ M 個ずつに分割し、リストのリストとして保持しています。 償却計算量として表す場合、再構築にかかるコストを add, remove 側に押し付けることで、「 add, remove は償却 \Theta\left(M+\frac{N}{M^2}+\log N\right) 、 添字アクセス・bisect は償却 \Theta(\log N) 」と表すこともできます。計算量に関する詳細
要素の追加・削除の際には、二分探索により位置を特定して insert, pop をしているため、基本的には計算量は \Theta(M + \log N) となります(ただし hash が衝突する要素が与えられた場合は、通常の set と同様 \Theta(N) となります)。
要素の追加・削除によりリストのサイズが M より十分に大きく・小さくなった場合にはリストの分割・合併が行われるため、追加の計算コストとして \Theta\left(M+\frac{N}{M}\right) の時間がかかります。
また、SortedSetは添字アクセス・bisectを高速に行うための情報(各リストの要素数をもつセグメントツリー)を内部で保持していますが、リストの分割・合併が行われた際にはその情報を破棄し、次に添字アクセス・bisectが行われるタイミングで \Theta\left(\frac{N}{M}\right) かけて再構築します。このため、 SortedSet に変更を加えることなく添字アクセス・bisect を繰り返す場合にはこれらの計算量は \Theta(\log N) であり、変更を加えながら行う場合には平均 \Theta\left(\frac{N}{M^2}+\log N\right) になります。
以下に示すように、「add のあとに bisect を繰り返す」と「add しながら bisect を繰り返す」では、今回の検証条件の下、実行時間に数十パーセント程度の差が出ます。(いずれもAtCoderのコードテスト環境で実行)
実行速度検証1(addのみ)
import random from sortedcontainers import SortedSet N = 10**6 s = SortedSet() for _ in range(N): s.add(random.randint(0, 10**9))
実行時間(ミリ秒)
| N | pypy | CPython |
|---|---|---|
| 10^6 | 825 | 1607 |
| 2\times 10^6 | 1833 | 4106 |
| 3\times 10^6 | 3164 | 6902 |
実行速度検証2(addしたあとbisect)
import random from sortedcontainers import SortedSet N = 10**6 s = SortedSet() for _ in range(N): s.add(random.randint(0, 10**9)) for _ in range(N): s.bisect_left(random.randint(0, 10**9))
実行時間(ミリ秒)
| N | pypy | CPython |
|---|---|---|
| 10^6 | 1591 | 3575 |
| 2\times 10^6 | 2988 | 8073 |
| 3\times 10^6 | 4520 | >10000 |
実行速度検証3(addしながらbisect)
import random from sortedcontainers import SortedSet N = 10**6 s = SortedSet() for _ in range(N): s.add(random.randint(0, 10**9)) s.bisect_left(random.randint(0, 10**9))
実行時間(ミリ秒)
| N | pypy | CPython |
|---|---|---|
| 10^6 | 1952 | 4198 |
| 2\times 10^6 | 3888 | >10000 |
| 3\times 10^6 | 5807 | >10000 |
SortedDict
sortedcontainers ではキーを二分探索することができる SortedDict というデータ構造も提供されています。
from sortedcontainers import SortedDict
d = SortedDict({7:49, 3:9, 1:1, 5:25})
i = d.bisect_left(4) # d のキーをソートしたリストに対して bisect_left を行ったときと同じ値である 2 が返される
print(d.peekitem(i)) # d のキーと値の組をソートしたリストに対して添字アクセスしたときと同じ値である (5, 25) が返される
d[6] = 36
d.pop(5)
print(d.peekitem(d.bisect_left(4))) # (6, 36)
各操作の時間計算量は SortedSet と同様です
SortedSet と似たデータ構造を実装した他のライブラリ
SortedSet と同様の機能を提供するデータ構造のより高速な実装も存在します。競技プログラミングでは以下のライブラリがしばしば使われます。このライブラリは 2025年10月時点の AtCoder のジャッジにはインストールされていないため、利用する際には github からコードをコピーしてくる必要があります。
github :tatyam-prime / SortedSet
ac-library-python, acl-cpp-python
競技プログラミングにおいてよく使われるアルゴリズムのうちいくつかを C++ で実装したものが、AtCoder 公式から AtCoder Library(ACL) として提供されています。
AtCoder では、 ACL と同様の機能を Python 向けに実装したライブラリとして、ac-library-python, acl-cpp-python の 2 種類を利用することができます。
提供されているアルゴリズムについては ACL のページを、各ライブラリの使い方については各ライブラリのページを参照してください。これらのライブラリの使い方のテストとしては AtCoder Library Practice Contest が便利です。
競技プログラミングに限らずよく利用されるライブラリ
以下で紹介するライブラリは、競技プログラミング以外の用途で広く一般に使われているライブラリのうち、競技プログラミングにおいても利用場面があるものの例です。ライブラリの使用方法などは各ライブラリの公式ドキュメントや一般の解説サイトを参照してください。
numpy
多次元配列の操作と行列演算を効率よく行うためのライブラリです。
github : numpy / numpy
networkx
単一始点最短経路問題や最大流問題、最大重みマッチングなど、グラフに関する様々な問題を解決するためのメソッドが用意されています。
github : networkx / networkx
pulp
線形最適化問題を解くためのモデリングライブラリです。整数計画問題などを高速に解くことができます。
github : coin-or / pulp
問題
本節にはEX問題はありません。本文中にある練習問題を解いてください。
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- class により変数と処理をまとめた新しい型を定義することができる
__init__でコンストラクタを定義する変数名.インスタンス変数名でインスタンス変数にアクセスすることができる- インスタンスメソッド内でインスタンス変数を参照するには
self.インスタンス変数名とする。
class
class の基礎
変数と処理をまとめた型を class といいます。例えば set や list などもクラスです。
クラスは自分で作ることができます。まずは簡単な例から考えてみましょう。人を表すクラス Person を以下のように作り、名前と年齢を持つようにします。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
p = Person("Taro", 18) # Taroを作成
print(p.name) # Taro 名前を出力
q = Person("Jiro", 17) # Jiroを作成
print(q.age) # 17 年齢を出力
Person クラスは人を定義するものであり、Person インスタンス(上の例では変数 p, q が持つもの)は個々の人を指します1。例えば「車」という言葉は車という概念と個々の具体的な車を両方指しますが、python でのプログラミングではこの2つを「クラス」「インスタンス」と呼び分けるイメージです。
Person インスタンスが持つ変数 name, age をインスタンス変数と呼びます。
__init__ は コンストラクタと呼ばれる特別なメソッドです2。引数の1番目に自分自身、2番目以降にインスタンス生成時に渡される引数を受け取ります。
Person クラスの例では、6 行目の Person("Taro", 18) により __init__(self, "Taro", 18) とコンストラクタが呼ばれ、self.name = name によりインスタンス変数 name に"Taro" が、 self.age = age によりインスタンス変数 age に 18 が代入されています。
インスタンス変数には p.name のように 変数名.インスタンス変数名 でアクセスすることができます。
メソッド
インスタンスに紐づいている関数のようなものをメソッドといいます。例えば list の .sort() はメソッドです。
class にはメソッドを定義することができます。以下の例では、Person クラスに各自の名前を出力するメソッド say_hello() を実装しています。メソッドの中で自身の持つインスタンス変数を参照する際は self.インスタンス変数名 とします。3
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def say_hello(self):
print(f"Hello, I'm {self.name}.")
p = Person("Taro", 18)
p.say_hello() # "Hello, I'm Taro."
q = Person("Jiro", 17)
q.say_hello() # "Hello, I'm Jiro."
メソッドはコンストラクタ同様、引数の1番目に自分自身を表す変数を取り、2番目以降に通常の引数を取ります。上の例で、p.say_hello() で引数を渡していませんが、def say_hello(self): では引数が1つあるのはこのためです。別の例を以下の挙げます。
class Calculator:
def __init__(self, x):
self.x = x
def get_x(self):
return self.x
def add(self, y):
self.x += y
c = Calculator(10)
print(c.get_x()) # 10
c.add(31)
print(c.get_x()) # 41
メソッド内ではインスタンス変数を新たに定義することもできます。ただし、一般に __init__ で定義されていないインスタンス変数を新たに定義することは可読性が低くなるため控えた方がよいです。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def add_money(self):
self.money = 100
def show_money(self):
print(self.money)
p = Person("Taro", 18)
p.add_money()
p.show_money() # 100
q = Person("Jiro", 17)
# q.show_money() # インスタンス変数 money が定義されていないためエラー
特殊メソッド
__init__ のように、前後を2個のアンダースコアで挟まれたメソッドを特殊メソッドといいます。これらを定義することで、演算子による演算の内容を定義したり、print で表示されるものを定義することができます。
以下の例は __add__ メソッドにより + 演算子の内容を定義し、__str__ メソッドにより print で表示されるものを定義しています。その他の特殊メソッドについては、公式ドキュメントなどを参照してください。
class Vector2d:
def __init__(self, x, y):
self.x = x
self.y = y
def __add__(self, other):
return Vector2d(self.x + other.x, self.y + other.y)
def __str__(self):
return f"(x={self.x}, y={self.y})"
v = Vector2d(3, 4)
w = Vector2d(10, 20)
print(v+w) # (x=13, y=24)
class を利用するメリット
以下の例は、リストとその要素の総和を同時に管理するクラスの例です。
class List_with_sum:
def __init__(self, array):
self.array = array
self.sum = sum(array)
def append(self, x):
self.array.append(x)
self.sum += x
def pop(self, i=-1):
x = self.array.pop(i)
self.sum -= x
return x
def get_sum(self):
return self.sum
def __str__(self):
return str(self.array)
a = List_with_sum([20, 30, 10])
print(a.get_sum()) # 出力: 60
print(a.pop()) # 出力: 10
print(a.get_sum()) # 出力: 50
a.append(60)
print(a.get_sum()) # 出力: 110
print(a) # 出力: [20, 30, 60]
このクラスでは、要素を追加・削除するときに総和も自動で更新されます。このため、このクラスを利用する際に総和が常に正しい値に保たれることを意識せずに済みます。
一方、クラスを使わずに同じことを行おうとすると、要素を追加・削除するたびに総和を手動で更新する必要があり、更新忘れによるバグが発生しやすくなります。
このように、操作とそれによる状態の更新をまとめて行いたい場面ではクラスを作成することにメリットがあります。
また、データ構造を表すクラスを適切に用意することで、同じクラスを他の問題にも使い回せることがあります。競技プログラミングにおいては、セグメントツリーや DSU などが典型的な例です4。
問題
本節には練習問題はありません。
-
インスタンスのことをオブジェクトと呼ぶこともありますが、オブジェクトという言葉は別のものを指すこともあるため、インスタンスと呼ぶ方がよいでしょう。 ↩
-
__init__は厳密にはイニシャライザと呼ばれ、コンストラクタは別のものを指しますが、一般的な文脈においては__init__をコンストラクタと呼ぶことが広く慣行となっています。 ↩ -
普通の関数と同様に、メソッドの引数には自由に名前をつけることができますが、1つ目の引数の名前は
selfにすることが強く推奨されており、競技プログラミング用途であるかによらずほとんどのPythonのコードがそのように書かれています。 ↩ -
ここで扱うには高度な内容であるため、セグメントツリーやDSUがどのようなデータ構造であるかの説明は省略します。 ↩
実行時間制限: 0 msec / メモリ制限: 0 KiB
キーポイント
- Python は C++ より遅いため、実行時間制限ギリギリになることがしばしばある。そのため定数倍が高速な実装を身につけることは比較的重要度が高い。
Python の罠と定数倍高速化
Python の罠と定数倍高速化テクニックについてをまとめました。重要度を星の数(星が多いほど重要、最大星3つ)で表しています。
組み込み関数関係
再帰上限(★★★)
関数の再帰呼び出しが深くなるとエラーとなります。上限回数は環境により異なりますが、AtCoder では約1000回となっています。
def dfs(n):
if n==0:
return 0
else:
return dfs(n-1)
# dfs(10000) # RecursionError
sys.setrecursionlimit により上限回数を変更することができます。1
import sys
sys.setrecursionlimit(10**5)
def dfs(n):
if n==0:
return 0
else:
return dfs(n-1)
dfs(10000) # エラーにならない
リストに対する操作(★★)
組み込み関数の処理は必ずしも O(1) とは限りません。リストの長さが N のとき sort メソッドが \Theta(N\log N) 時間であることは 2.06.計算量 で説明しました。この他にも、リストに対する操作には O(1) ではない操作が多く存在するため注意が必要です。
以下は長さ N のリスト a に対する O(1) でない操作の一例です。
| 操作 | 計算量 |
|---|---|
x in a |
O(N) |
a.index(x) |
O(N) |
del a[i], a.pop(i) |
O(N) |
a.insert(i, x) |
O(N) |
pop 及び del は削除する要素が末尾から遠いほど時間がかかります。特に、末尾要素を削除する a.pop() は O(1) です。
絶対値が2^63より大きな整数を扱うと遅い(★)
桁が大きな数を扱うと計算に時間がかかるのは直感的には当たり前ですが、実際には 2^{63} の前後で急激に変化します。ただし、よほど巨大な数に対する演算でない限り 10^6 回の演算で数十ミリ秒程度の差であるため、ほとんどの場面で気にする必要はありません。
速度検証1(足し算)
start = 10**12 # ここの値を変えて検証 sum(range(start, start + 10**6))
実行速度(ミリ秒)
| start | PyPy | CPython |
|---|---|---|
| 10^{12} | 0.7 | 14.4 |
| 2^{62} | 21.7 | 22.5 |
| 2^{63} | 28.2 | 40.4 |
| 10^{100} | 44.6 | 45.9 |
| 10^{1000} | 137 | 159 |
| 10^{10000} | 1033 | 1443 |
速度検証2(掛け算)
start = 10**6 # ここの値を変えて検証
s = 0
for i in range(start, start + 10**6):
s = i*i
実行速度(ミリ秒)
| start | PyPy | CPython |
|---|---|---|
| 10^{6} | 2.5 | 21.7 |
| 10^{18} | 14.1 | 33.0 |
| 10^{24} | 37.1 | 51.7 |
| 10^{100} | 83.7 | 191.4 |
| 10^{1000} | 2004 | 4765 |
int と str の変換(★)
10^{4300} 以上の整数を print したり文字列に変換しようとした場合や、10^{4300} 以上の整数を表す文字列を int に変換しようとした場合、エラーとなります。
N = 10**5000 # print(N) # ValueError # N_str = str(N) # ValueError S = "1" * 5000 # S_int = int(S) # ValueError S_bin = int(S, 2) # 10^1500程度の値になるためエラーにならない
sys.set_int_max_str_digits により上限桁数(4300)を変更することができます。
import sys sys.set_int_max_str_digits(10000) # 0 を指定すると上限を撤廃する # 全てエラーにならない N = 10**5000 print(N) N_str = str(N) S = "1" * 5000 S_int = int(S) S_bin = int(S, 2)
AtCoder 上では実行時引数により上限が撤廃されているため、プログラム中で sys.set_int_max_str_digits を行わなくてもエラーになりませんが、自身のパソコンなどで動かす場合には注意してください。
リストの結合をsumで行うと遅い(★)
N = 10**4 # ここの値を変えて検証 a=[[1] for _ in range(N)] sum(a, []) # この行だけ計測
実行速度(ミリ秒)
| N | PyPy | CPython |
|---|---|---|
| 10^4 | 1.6 | 58 |
| 3\times 10^4 | 2.2 | 820 |
| 10^5 | 5.2 | >10000 |
for 文を使って実装するとこの問題は起こりません。
N = 10**4 # ここの値を変えて検証
a=[[1] for _ in range(N)]
s = []
# ここから下だけ計測
for l in a:
s += l
実行速度(ミリ秒)
| N | PyPy | CPython |
|---|---|---|
| 10^4 | 1.5 | 0.6 |
| 3\times 10^4 | 2.3 | 1.5 |
| 10^5 | 5.0 | 5.5 |
class が遅い(★)
C++ で実装されたAtCoder Library(ACL)では modint クラスがありますが、python の class は遅いため、ACL のような modint クラスを作ることは残念ながら現実的ではありません。
import random
import time
random.seed(777)
class modint1000000007:
def __init__(self, n=0):
self.n = n
def __iadd__(self, other):
self.n = (self.n + other.n) % 1000000007
return self
# int
A=[random.randint(0,10**9) for _ in range(10**7)]
def f(A):
s=0
for a in A:
s=(s+a)%1000000007
# modint
B=[modint1000000007(a) for a in A]
def g(B):
s=modint(0)
for a in B:
s+=a
| PyPy | CPython | |
|---|---|---|
| int | 42 | 221 |
| modint | 271 | 325 |
MOD をグローバルに書くと速い(★)
関数の内部でしか使わない変数であっても、グローバルで宣言することでいくらか高速になります。ただし、10^6 回の関数呼び出しで数十ミリ秒程度であるため、ほとんどの場面で気にする必要はありません。
import random
random.seed(777)
A=[random.randint(0, 10**9) for _ in range(10**7)]
# local
def f(A):
MOD = 10**9+7
s = 0
for a in A:
s = (s+a)%MOD
return s
# global
MOD = 10**9+7
s = 0
for a in A:
s = (s+a)%MOD
実行速度(ミリ秒)
| PyPy | CPython | |
|---|---|---|
| local | 42 | 711 |
| global | 85 | 353 |
標準ライブラリ関係
Queue が遅い(★)
queue のデータ構造を使う場合、queue.Queue ではなく collections.deque を使いましょう。
詳細は 4.02 を参照してください。
deque のランダムアクセスが遅い(★)
deque の要素に添え字を使ってアクセスする処理 d[100] などは遅い(O(N))ため、可能な限り使用は控えましょう。
詳細は 4.02を参照してください。
itertools のオーダーが悪い(★)
「選ばれる要素のindexのリストをin-placeに更新する」などであれば実装方法によっては O(ループ数) とすることができますが、itertools の関数は「選ばれた要素からなるタプルを返す」と、毎回タプルを生成しているためその分の計算量がかかり O(タプルの長さ\times ループ数) となっています。
詳細は 4.01 を参照してください。
サードパーティライブラリ
list と numpy 配列でスライスの挙動が違う(★)
list に対するスライスは新たなリストを生成しますが、numpy 配列に対するスライスはその配列に対するビューを返すため、変更が元のオブジェクトに反映されます。
x1 = [1, 2, 3] x2 = x1[:] x2[0] = 100 print(x1) # [1, 2, 3] import numpy as np y1 = np.array([1, 2, 3]) y2 = y1[:] y2[0] = 100 print(y1) # [100 2 3]
PyPy 関係
タプルの大小比較が遅い(★★★)
タプルの大小関係を比較する操作を多く行うケースでは、タプル (x, y) を整数 x \times 10^9 + y や x \times 2^{20} + y などに置き換えることで数倍の高速化が見込めます。
import random
random.seed(777)
def f(A):
return sorted(A)
def g(A):
B=[x<<20|y for x,y in A]
B.sort()
return [(x>>20, x&0xfffff) for x in B]
N = 10**5
A = [(random.randint(0, 10**5), random.randint(0, 10**5)) for _ in range(N)]
f(A)
g(A)
実行速度(ミリ秒)
| PyPy | CPython | |
|---|---|---|
| f,10^5 | 120 | 36 |
| g,10^5 | 15 | 47 |
| f,10^6 | 1583 | 719 |
| g,10^6 | 173 | 595 |
また、第1要素の大小のみを考慮すればよいケースでは sort メソッドのキー関数を指定する次の実装でも、CPython においては高速になります。
import random
random.seed(777)
def g2(A):
return sorted(A, key=lambda x: x[0])
N = 10**5
A = [(random.randint(0, 10**5), random.randint(0, 10**5)) for _ in range(N)]
g2(A)
| N | PyPy | CPython |
|---|---|---|
| 10^5 | 51 | 22 |
| 10^6 | 947 | 346 |
再帰関数が遅い(★★)
基本的には CPython より PyPy の方が高速です。しかし、再帰呼び出しは PyPy の方が CPython に比べ数倍遅くなります。
import sys
sys.setrecursionlimit(10**7)
def f(n):
if n==0:
return 0
else:
return f(n-1)
実行速度(ミリ秒)
| PyPy | CPython | |
|---|---|---|
| f(10^5) | 105 | 20 |
| f(10^6) | 858 | 129 |
問題
リンク先の問題を解いてください。
EX24.再帰関数2
-
実際に再帰可能な回数は
sys.setrecursionlimitで与えた値より少し小さくなるため、余裕をもって設定する必要があります。 ↩
実行時間制限: 0 msec / メモリ制限: 0 KiB
第4章修了

第4章お疲れ様でした。
この章では多岐にわたる Python の標準ライブラリや機能を紹介しました。これらを理解し、場面に応じて使い分けられるようになると、同じアルゴリズムであっても より短く、より読みやすく、そしてより高速に 実装できるようになります。
第5章について
第5章以降は、年1回程度の不定期更新を予定しています。
ぜひコンテストに参加しましょう!
AtCoder Beginner Contest
毎週土曜日の午後9時からは、AtCoder Beginner Contestが開催されていますので、ぜひコンテストに参加してみましょう。最新のコンテスト情報はこちらからご確認ください。
AtCoder Daily Training
AtCoder Beginner Contestの過去問を使用した練習用バーチャルコンテストです。
毎週火曜・水曜・木曜の夕方から夜にかけて1日3回行っています。
難易度はEASYをおすすめします。
AtCoderで強くなるには?
AtCoderのコンテストの復習方法やコンテスト以外での学習方法が書いてあります。
上記リンク先はAtCoderInfo内のページです。
実行時間制限: 0 msec / メモリ制限: 0 KiB
EX1「出力の練習 / 1.01」に戻る
EX5「A足すB問題 / 1.05」に戻る
コードテストの場所
練習問題を解くときは「コードテスト」というページを使ってプログラムを書き、正しく動作することが確認できたら提出するようにしましょう。
コードテストのページは、次の画像の赤い四角で囲った部分をクリックすることで開けます。

プログラムの実行
設定ができたら、「ソースコード」と書かれている場所にプログラムを書きます。
プログラムが書けたら「言語」が「Python(CPython 3.11.4)」または「Python (PyPy 3.10-v7.3.12)」になっていることを確認し、ページ下部にある「実行」ボタンを押してください。

実行結果
プログラムが実行できたら「標準出力」と書かれている場所にプログラムの出力が表示されます。

エラーが発生したとき
エラーが発生した場合は「標準エラー出力」と書かれている場所にエラーの詳細が表示されます。
たとえば開きカッコに対応する閉じカッコがない場合、SyntaxError となります。
print(123
標準エラー出力
File "Main.py", line 1
print(123
^
SyntaxError: '(' was never closed
エラーの内容をヒントにプログラムを修正し、また実行してください。
エラーの直し方については1.02.プログラムの書き方とエラーで説明します。
EX1「出力の練習 / 1.01」に戻る
ここから先の説明はEX5「A足すB問題 / 1.05」を解く時に読んでください。
コードテストでの入力
コードテスト上で入力機能を使う場合、「標準入力」と書かれている場所に入力を書き、実行ボタンをクリックします。

実行時間制限: 0 msec / メモリ制限: 0 KiB
EX2「エラーの修正 / 1.02」に戻る
EX5「A足すB問題 / 1.05」に戻る
AtCoder上でのエラーの表示
エラーの種類とAtCoder上の表示の対応は次の表の通りです。
| エラーの種類 | ジャッジの判定 | 終了コード |
|---|---|---|
| コンパイルエラー | (Compile Error) | -1 |
| 実行時エラー | (Runtime Error) | 0以外 |
| 論理エラー | (Wrong Answer) | 0(エラーがない時と同じ) |
| 実行時間制限超過※ | (Time Limit Exceeded) | 9 |
「ジャッジの判定」は提出後の採点結果のことです。
「終了コード」はコードテスト上でプログラムを実行した後、画面の下部に表示されている数値のことです。
コードテスト上でコンパイルエラーが発生した場合、「標準エラー出力」にエラーの詳細が表示されます。
エラーの内容を読んだり、表示されているエラー内容を検索したりしてエラーを修正しましょう。
※実行時間制限超過がAPG4bPythonで発生する場合、提出先を間違えている可能性があります。説明ページではなく問題ページ(EX◯◯)に提出しているかを確認しましょう。
EX2「エラーの修正 / 1.02」に戻る
ここから先の説明はEX5「A足すB問題 / 1.05」を解く時に読んでください。
ACを取るには
入力を使う問題では、「ある入力ではACだったが、別の入力ではWAだった」という事がありえます。
例えば「A + Bを計算する問題」で、間違えてプログラムの出力をA - Bとしてしまったとします。
この場合でも、入力がA = 5, B = 0だったとき、プログラムの出力と正解はどちらも5となり一致し、この入力に対しては
となります。
しかし、入力がA = 2, B = 1だったとき、プログラムの出力は1となりますが、正解は3なので一致せず、この入力に対してはとなります。
| 自分のプログラムの出力 | 正解 | 入力に対する採点結果 | |
|---|---|---|---|
| A = 5, B = 0 | 5 | 5 | |
| A = 2, B = 1 | 1 | 3 |
問題の採点結果をにするには、その問題の入力のパターン全てに対して正しい出力をする必要があります。
提出の詳細の確認方法
採点結果がだった場合は「提出の詳細」を見ると、いくつの入力例に対してACであり、いくつの入力例に対してWAであるかを見ることができます。
この画面から実際にどのような入力が行われるかを確認することはできませんが、提出したプログラムがどれくらい正しいかのヒントにはなります。
提出の詳細を見るには、まず問題ページで「提出一覧」→「自分の提出」をクリックします。

すると自分の提出の一覧が表示されるので、見たい提出を選んで「詳細」をクリックすると、提出の詳細を見ることができます。

「提出一覧」→「すべての提出」をクリックすることで、他の人の提出を見ることもできます。
他の人のプログラムを見ることも勉強になるので、うまく活用してください。
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題を解く前に 付録1.コードテストの使い方を読んでください。
問題文
次の出力をするプログラムを書いてください。
実行結果
こんにちは AtCoder
出力の最後(つまり AtCoder の後)に改行する必要があります。注意してください。
回答プログラムの作成方法
回答プログラムは、次のサンプルプログラムを改変して作成することを推奨します。
プログラムをコピーし、コードテストのページに貼り付けましょう。
サンプルプログラム
print("Hello, world!")
print("Hello, AtCoder!")
print("Hello, Python!")
サンプルプログラムの実行結果
Hello, world! Hello, AtCoder! Hello, Python!
これを次の出力を行うようにプログラムを書き換え、正しく動作することが確認できたら提出しましょう。
正しい実行結果
こんにちは AtCoder
「AtCoder」の「C」は大文字であることに注意しましょう。
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
print("こんにちは")
print("AtCoder")
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題を解く前に 付録2.提出結果の見方を読んでください。
問題文
A君は次の出力をするプログラムを作ろうとしました。
実行結果
いつも2525 AtCoderくん
しかし、書いたプログラムを実行してみるとエラーが発生しました。
A君が書いたプログラムのエラーを修正し、正しく動作するようにしてください。
Aくんが書いたプログラム
print("いつも2525"
print(AtCoderくん)
このコードをコードテストで実行すると、標準エラー出力に以下のエラーメッセージが表示されます。
標準エラー出力
File "Main.py", line 1
print("いつも2525"
^
SyntaxError: '(' was never closed
この問題の取り組み方
Aくんのプログラムには複数のエラーが含まれています。
わかるエラーから一つずつ直し、コードテスト上で実行してみて、直っているかどうか確かめましょう。
コードテストの使い方は付録1.コードテストの使い方に書いてあります。
「AtCoder」の「C」は大文字であることに注意しましょう。
ヒント
1.02.プログラムの書き方とエラーの「エラーの例」を参考にしましょう。
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
print("いつも2525")
print("AtCoderくん")
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
Aくんは1から100までの和を求めようと思いました。
数学の授業で習ったとおり、1から100までの和は次の式で求められます。
\dfrac{1}{2} \times 100 \times (100+1)
この式の値を出力してください。
ただし、答えを整数値で出力させるため 割り算に//演算子を使って解いて下さい。 /を使うとWAになります。
ヒント
「1.03.四則演算と優先順位」の「注意点」に書かれている項目を読んでみましょう。
コードテストで正しく動作することを確認してから提出しましょう。
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
# // 2を最後に計算することで正しい計算結果になる print(100 * (100 + 1) // 2)
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
次のプログラムをコピー&ペーストして、指定した場所にプログラムを追記することで問題を解いて下さい。
seconds = 365 * 24 * 60 * 60 print() # 1年は何秒か出力 print() # 2年は何秒か出力 print() # 5年は何秒か出力 print() # 10年は何秒か出力
int型の変数secondsは一年の秒数を表しています。これを利用して
- 1年は何秒か
- 2年は何秒か
- 5年は何秒か
- 10年は何秒か
を順に一行ずつ表示するプログラムを作って下さい。
うるう秒やうるう年のことは考え無くて良いとします。
実行結果(一部を「?????」で隠しています)
31536000 63072000 ????? ?????
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
seconds = 365 * 24 * 60 * 60 print(seconds) # 1年は何秒か出力 print(seconds * 2) # 2年は何秒か出力 print(seconds * 5) # 5年は何秒か出力 print(seconds * 10) # 10年は何秒か出力
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題を解く前に、以下の2つのリンク先の説明を読んでください。
問題文
2つの整数A, Bが与えられます。A+Bの計算結果を出力してください。
制約
- 0 \le A, B \le 100
- A, B は整数
入力
入力は次の形式で標準入力から与えられます。
A B
出力
A+B の計算結果を出力してください。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
1 2
出力例1
3
入力例2
100 99
出力例2
199
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
0 0
テスト出力1
0
テスト入力2
0 50
テスト出力2
50
テスト入力3
0 50
テスト出力3
50
テスト入力4
27 81
テスト出力4
108
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
A, B = map(int, input().split()) print(A + B)
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
1行の計算式が与えられるので、その結果を出力してください。
与えられる計算式のパターンと対応する出力は以下の表の通りです。
| 入力 | 出力 | 備考 |
|---|---|---|
A + B |
A + Bの計算結果を出力 | |
A - B |
A - Bの計算結果を出力 | |
A * B |
A \times Bの計算結果を出力 | |
A / B |
A \div Bの計算結果を出力 | 小数点以下は切り捨てて出力 B が 0 の場合はerrorと出力 |
A ? B |
errorと出力 |
|
A = B |
errorと出力 |
|
A ! B |
errorと出力 |
サンプルプログラム
このプログラムを元に解答を作成することを推奨します。
A, op, B = input().split()
A = int(A)
B = int(B)
if op == "+":
print(A + B)
# ここにプログラムを追記
制約
- 0 \le A, B \le 100
- A, B は整数
- \mathrm{op} は
+,-,*,/,?,=,!のいずれか一つ
入力
入力は次の形式で標準入力から与えられます。
A \mathrm{op} B
出力
入力の計算式の計算結果を出力してください。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
1 + 2
出力例1
3
入力例2
5 - 3
出力例2
2
入力例3
10 * 20
出力例3
200
入力例4
10 / 3
出力例4
3
計算結果の小数点以下は切り捨てます。
入力例5
100 / 0
出力例5
error
B が 0 の場合は error と出力することに注意してください。
入力例6
25 ? 31
出力例6
error
入力例7
0 + 0
出力例7
0
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
100 = 100
テスト出力1
error
テスト入力2
17 ! 91
テスト出力2
error
テスト入力3
0 / 20
テスト出力3
0
テスト入力4
0 * 0
テスト出力4
0
テスト入力5
0 - 0
テスト出力5
0
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
A, op, B = input().split()
A = int(A)
B = int(B)
if op == "+":
print(A + B)
elif op == "-":
print(A - B)
elif op == "*":
print(A * B)
elif op == "/" and B != 0:
print(A // B)
else:
print("error")
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
次のプログラムで宣言されている bool 型の変数 a, b, c に対し、True または False を代入することで、AtCoder と出力されるようにしてください。
1, 2, 3 行目における変数 a,b,c への代入以外のプログラムの書き換えは行わないものとします。
プログラム
a = # True または False
b = # True または False
c = # True または False
# ここから先は変更しないこと
assert (a is True) or (a is False)
assert (b is True) or (b is False)
assert (c is True) or (c is False)
if a:
print("At", end="")
else:
print("Yo", end="")
if not a and b:
print("Bo", end="")
else:
print("Co", end="")
if a and b and c:
print("foo!", end="")
elif True and False:
print("year!", end="")
elif not a or c:
print("der", end="")
print("")
入力
この問題に入力はありません
出力
AtCoder と出力してください。
回答例
答え方の例です。
変数 a, b, c の全てに False を代入していますが、YoCoder と出力されているので、この解答は不正解となります。
a = False # True または False
b = False # True または False
c = False # True または False
# ここから先は変更しないこと
assert (a is True) or (a is False)
assert (b is True) or (b is False)
assert (c is True) or (c is False)
if a:
print("At", end="")
else:
print("Yo", end="")
if not a and b:
print("Bo", end="")
else:
print("Co", end="")
if a and b and c:
print("foo!", end="")
elif True and False:
print("year!", end="")
elif not a or c:
print("der", end="")
print("")
出力例
YoCoder
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
a = True # True または False
b = False # True または False
c = True # True または False
# ここから先は変更しないこと
assert (a is True) or (a is False)
assert (b is True) or (b is False)
assert (c is True) or (c is False)
if a:
print("At", end="")
else:
print("Yo", end="")
if not a and b:
print("Bo", end="")
else:
print("Co", end="")
if a and b and c:
print("foo!", end="")
elif True and False:
print("year!", end="")
elif not a or c:
print("der", end="")
print("")
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
以下の問題を N 回解いてください。
2 つの整数 A, B が与えられます。A+B の計算結果を出力してください。
制約
- 1 \le N \le 10
- 0 \le A_i, B_i \le 100
- N, A_i, B_i は整数
入力
入力は次の形式で標準入力から与えられます。
N A_1 B_1 A_2 B_2 \vdots A_N B_N
出力
N 行出力してください。
i 行目には、A_i+B_i の計算結果を出力してください。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
1 42 37
出力例1
79
入力例2
4 3 1 4 1 5 9 2 6
出力例2
4 5 14 8
ヒント
クリックでヒントを見る
この問題は EX5.A足すB問題 と同じ処理を N 回繰り返すことで解くことができます。また、「N 回繰り返す」という操作は while 文を用いて書くことができます。
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
1 79 68
テスト出力1
147
テスト入力2
4 90 46 73 74 93 21 99 42
テスト出力2
136 147 114 141
テスト入力3
5 49 81 46 39 50 89 26 97 84 46
テスト出力3
130 85 139 123 130
テスト入力4
8 13 54 81 51 8 64 89 85 44 51 51 94 39 84 2 45
テスト出力4
67 132 72 174 95 145 123 47
テスト入力5
10 76 15 58 31 21 40 86 88 77 58 77 33 25 70 8 81 67 79 73 99
テスト出力5
91 89 61 174 135 110 95 89 146 172
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
N = int(input())
i = 0
while i < N:
A, B = map(int, input().split())
print(A + B)
i += 1
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
電卓の操作が与えられるので、計算途中の値と計算結果の値を出力してください。
電卓の操作は次の形式で入力されます。
入力の形式
計算の数N
最初の値A
演算子\mathrm{op}_1 計算する値B_1
演算子\mathrm{op}_2 計算する値B_2
\vdots
演算子\mathrm{op}_N 計算する値B_N
次の入力は ((2 + 1) \times 3) \div 2 を表しています。
入力例
3 2 + 1 * 3 / 2
出力では「何行目の出力か」と、「計算途中の値」を出力してください。
出力の形式
1 1個目の計算結果 2 2個目の計算結果 \vdots N N個目の計算結果
次の出力は上の入力例に対する出力です。
出力例
1 3 2 9 3 4
与えられる入力のパターンと対応する処理は以下の表の通りです。
| 入力 | 処理 | 備考 |
|---|---|---|
+ B |
それまでの計算結果に B を足し、その値を出力する。 | |
- B |
それまでの計算結果から B を引き、その値を出力する。 | |
* B |
それまでの計算結果に B を掛け、その値を出力する。 | |
/ B |
それまでの計算結果を B で割り、その値を出力する。 | 小数点以下は切り捨てて計算を行う。 B が 0 の場合はerrorと出力し、それ以降は出力を行わない。 |
/ B において、B が 0 の場合は error と出力し、それ以降は出力を行わない ことに注意してください。
ページ末尾に問題のヒントがあります。詰まったら見てみましょう。
サンプルプログラム
N = int(input()) A = int(input()) # ここにプログラムを追記
制約
- 1 \le N \le 7
- 0 \le A, B_i \le 10
- A, B_i, N は整数
- \mathrm{op}_i は
+,-,*,/のいずれか
入力
入力は次の形式で標準入力から与えられます。
N
A
\mathrm{op}_1 B_1
\mathrm{op}_2 B_2
\vdots
\mathrm{op}_N B_N
出力
1 1個目の計算結果 2 2個目の計算結果 \vdots N N個目の計算結果
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
3 2 + 1 * 3 / 2
出力例1
1 3 2 9 3 4
問題文中で説明した入出力です。
入力例2
2 3 / 2 / 2
出力例2
1 1 2 0
割り算では小数点以下を切り捨てます。
入力例3
4 3 + 1 / 0 * 2 - 10
出力例3
1 4 error
割り算で B_i が 0 の場合は error と出力し、それ以降は出力をしないことに注意してください。
入力例4
7 10 * 10 * 10 * 10 * 10 * 10 * 10 * 10
出力例4
1 100 2 1000 3 10000 4 100000 5 1000000 6 10000000 7 100000000
ヒント1
次のプログラムは、5つの整数を入力で一つずつ受け取り、受け取った整数を足して出力します。
また、今回の問題と同様に、出力が何行目かも同時に出力します。
今回の問題を解く際の参考にしてください。
クリックでヒントプログラムを見る
total = 0
for i in range(5):
x = int(input())
total += x
# 行番号 合計値 の形式で出力
print(i + 1, total)
ヒント入力
3 4 2 1 10
ヒント出力
1 3 2 7 3 9 4 10 5 20
ヒント2
ジャッジでテストされる入力のうち2つをヒントとして示します。
サンプルは全てあっていてWAの原因がわからない人は、以下のケースに正解しているか確かめてみましょう。
クリックでテストケースを見る
テスト入力1
7 0 - 5 * 7 / 4 + 0 + 0 - 10 * 5
テスト出力1
1 -5 2 -35 3 -9 4 -9 5 -9 6 -19 7 -95
テスト入力2
6 0 / 4 / 3 / 5 + 3 / 7 / 1
テスト出力2
1 0 2 0 3 0 4 3 5 0 6 0
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
7 0 - 5 * 7 / 4 + 0 + 0 - 10 * 5
テスト出力1
1 -5 2 -35 3 -9 4 -9 5 -9 6 -19 7 -95
テスト入力2
6 0 / 4 / 3 / 5 + 3 / 7 / 1
テスト出力2
1 0 2 0 3 0 4 3 5 0 6 0
テスト入力3
3 1 * 4 * 3 / 0
テスト出力3
1 4 2 12 error
テスト入力4
7 0 * 2 / 0 + 1 / 0 + 5 * 2 - 10
テスト出力4
1 0 error
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
N = int(input())
A = int(input())
for i in range(N):
op, x = input().split()
x = int(x)
if op == "+":
A += x
elif op == "-":
A -= x
elif op == "*":
A *= x
elif op == "/" and x != 0:
A //= x
else:
print("error")
break
print(i + 1, A)
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
N 人のテストの点数が与えられます。
それぞれの人の点数が平均点から何点離れているか計算してください。
平均点は次の式で求められます。i 番目の人の点数は A_i で表します。
平均点 = \dfrac{A_1 + A_2 + \cdots + A_N}{N}
平均点が整数にならない場合、小数点以下を切り捨てた数値を平均点とします。
例えば 3 人のテストの点数が「2 点、1 点、4 点」だったとき、\frac{2 + 1 + 4}{3} = 2.333 \cdotsなので、平均点は小数点以下を切り捨てて 2 点になります。
そして、平均点から何点離れているかを計算した結果である「0 点、1 点、2 点」が答えになります。
「0 点、-1 点、2 点」でも「0 点、1 点、-2 点」でも無いことに注意してください。
ページ末尾に問題のヒントがあります。詰まったら見てみましょう。
サンプルプログラム
N = int(input()) # ここにプログラムを追記
制約
- 1 \le N \le 1000
- 0 \le A_i \le 100
- N, A_i は整数
入力
入力は次の形式で標準入力から与えられます。
N A_1 A_2 \cdots A_N
出力
それぞれの人の点数が平均点から何点離れているかを1行ずつ出力してください。
1人目の計算結果 2人目の計算結果 \vdots N人目の計算結果
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
3 2 1 4
出力例1
0 1 2
問題文中で説明した入出力です。
入力例2
2 80 70
出力例2
5 5
このケースの平均点は 75 点です。
どちらの点数も平均点から 5 点離れています。
入力例3
5 100 100 100 100 100
出力例3
0 0 0 0 0
このケースの平均点は 100 点です。
入力例4
10 53 21 99 83 75 40 33 62 18 100
出力例4
5 37 41 25 17 18 25 4 40 42
ヒント
今回の問題は次のプログラムに追記すれば解くことができます。
追記箇所が2つあることに注意してください。
クリックでヒントプログラムを見る
N = int(input())
# スペース区切りの整数をリストとして受け取る
A = list(map(int, input().split()))
# 合計点
total = 0
# 合計点を計算
for i in range(N):
# ①ここにプログラムを追記
# 平均点 (Nで割って切り捨てた値)
mean = total // N
# 平均点から何点離れているかを計算して出力
for i in range(N):
# ②ここにプログラムを追記
# 負の数を出力しないように注意
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
1 80
テスト出力1
0
テスト入力2
データが大きすぎるため省略
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
N = int(input())
# スペース区切りの整数をリストとして受け取る
A = list(map(int, input().split()))
# 合計点
total = 0
# 合計点を計算
for i in range(N):
# ①ここにプログラムを追記
total += A[i]
# 平均点 (Nで割って切り捨てた値)
mean = total // N
# 平均点から何点離れているかを計算して出力
for i in range(N):
# ②ここにプログラムを追記
# 負の数を出力しないように注意
if A[i] > mean:
print(A[i] - mean)
else:
print(mean - A[i])
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
1と+と-のみからなる式 S が 1 行で与えられるので、計算結果を出力してください。
例えば式 S が 1+1+1-1 であったとき、計算結果は 2 です。
具体的な式 S の形式は以下の通りです。
- 式 S の 1 文字目は必ず
1です。 - その後、「
+または-」と1が交互に続きます。 - S の最後の文字も必ず
1です。
式と演算子はスペースで区切られていないことに注意してください。
ページ末尾に問題のヒントがあります。詰まったら見てみましょう。
サンプルプログラム
S = input() # ここにプログラムを追記
制約
- 1 \le |S| \le 100 (|S| は文字列の長さ)
- S は
1から始まり、その後「+または-」と1が交互に続き、1で終わる
入力
入力は次の形式で標準入力から与えられます。
S
出力
Sの計算結果を出力してください。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
1+1+1-1
出力例1
2
問題文中で説明した入出力です。
入力例2
1-1-1-1-1-1
出力例2
-4
計算結果は負の値になることもあります。
入力例3
1
出力例3
1
入力は 1 だけで終わることもあります。
入力例4
1-1-1+1+1+1+1-1+1-1+1-1+1
出力例4
3
ヒント
次のプログラムは 9 文字の式 S にいくつ 1 が含まれているかを出力するプログラムです。
今回の問題を解く際の参考にしてください。
クリックでヒントプログラムを見る
S = input()
count = 0
# 9 文字の式に限定していることに注意
for i in range(9):
if S[i] == "1":
count += 1
print(count)
ヒント入力
1-1-1+1+1
ヒント出力
5
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1+1
テスト出力1
-25
テスト入力2
1+1+1+1+1+1+1+1+1+1+1+1+1
テスト出力2
13
テスト入力3
1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1-1
テスト出力3
-33
テスト入力4
1+1-1+1-1+1-1+1-1+1-1+1-1+1-1+1+1-1-1+1+1-1-1+1+1+1-1-1-1+1
テスト出力4
2
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
S = input()
# 計算結果を保持する変数
answer = 1
for i in range(len(S)):
if S[i] == "+":
answer += 1
if S[i] == "-":
answer -= 1
print(answer)
in の後ろに文字列を指定することで、文字に対して繰り返し処理を行うこともできます。
S = input()
# 計算結果を保持する変数
answer = 1
for c in S:
if c == "+":
answer += 1
if c == "-":
answer -= 1
print(answer)
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
学校の授業で持久走がありました。N 人の生徒がゴールまでにかかった時間(秒数)がそれぞれ T_1, T_2, \dots , T_N で与えられます。一番早くゴールしたのは何番目の生徒でしょうか。
ページ末尾に問題のヒントがあります。詰まったら見てみましょう。
サンプルプログラム
N = int(input()) # 生徒の数Nを読み込む T = list(map(int, input().split())) # 各生徒のゴールまでの時間を読み込む # ここにプログラムを追記
制約
- 1 \leq N \leq 100
- 100 \leq T_i \leq 1000 (全ての i について)
- 全ての生徒のゴールまでにかかった時間は異なる
入力
入力は次の形式で標準入力から与えられます。
N T_1 T_2 ... T_N
出力
一番早くゴールした生徒の番号を出力してください。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
5 300 450 200 400 350
出力例1
3
3 番目の生徒の 200 秒が最速のタイムになります。
入力例2
1 400
出力例2
1
1 人で走るときは常に最速ランナーになることができます。
入力例3
10 883 940 579 641 979 999 331 842 667 518
出力例3
7
ヒント
クリックでヒントを見る
二段階のステップで考えてみましょう。問題を解くために必要な情報は 2 つあります。
1.最小値が何か
2.最小値が何番目に現れるか
一度に求めようとせずに、1. と 2. を順番に調べるコードを書いてみましょう。
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
100 794 341 925 159 319 451 671 720 836 667 664 917 114 112 276 479 623 796 152 910 566 996 656 567 756 105 139 172 694 771 148 906 164 983 852 419 863 357 895 732 608 398 227 165 785 532 613 136 304 198 303 475 434 502 189 477 588 439 969 686 520 168 967 344 972 828 694 786 256 338 493 721 390 874 632 888 702 911 550 971 802 427 646 443 487 594 826 949 245 834 596 674 810 526 395 541 227 665 948 723
テスト出力1
26
テスト入力2
100 171 981 971 462 134 134 174 115 445 664 109 418 836 310 163 198 474 825 200 903 788 933 127 193 781 859 719 215 558 454 306 664 359 692 424 417 337 634 772 343 265 126 159 847 981 577 691 601 713 464 654 572 559 339 177 497 420 112 475 357 297 152 547 382 770 871 787 502 477 138 276 443 349 374 279 873 837 762 769 573 479 216 186 307 798 140 820 976 473 825 606 580 342 370 456 171 266 730 748 810
テスト出力2
11
テスト入力3
100 390 507 538 277 832 570 897 460 638 456 708 466 228 442 672 107 557 599 320 578 979 239 792 541 776 377 878 124 847 262 563 246 369 115 258 380 472 899 139 913 323 637 353 200 804 320 727 687 457 499 206 752 815 522 416 746 964 804 834 548 821 689 981 101 428 862 969 935 173 941 104 891 954 267 466 424 398 231 227 320 488 931 904 494 955 663 499 558 728 396 741 446 219 826 782 893 398 113 904 683
テスト出力3
64
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
N = int(input()) # 生徒の数Nを読み込む
T = list(map(int, input().split())) # 各生徒のゴールまでの時間を読み込む
T_min = min(T)
for i, v in enumerate(T):
if v == T_min:
print(i + 1)
break
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
三人兄弟の A 君と B 君と C 君は、お父さんに 1 つのプレゼントを貰うことになりました。
貰えるプレゼントの予算は「テストの合計点の積」で決まります。
三人兄弟はそれぞれ N 個のテストを受けました。
A 君と B 君と C 君の「i 番目のテストの点数」をそれぞれ A_i, B_i, C_i で表すと、プレゼントの予算は次の式で求まります。
プレゼントの予算 = (A_1 + A_2 + \cdots + A_N) \times (B_1 + B_2 + \cdots + B_N) \times (C_1 + C_2 + \cdots + C_N)
例えば、2 個のテスト受けた結果、A 君は 5 点と 7 点、B 君は 4 点と 10 点、C 君は 9 点と 2 点だったとします。
この場合、(5 + 7) \times (4 + 10) \times (9 + 2) = 12 \times 14 \times 11 = 1848 より、プレゼントの予算は 1848 円になります。
A 君はこの計算を行うプログラムを途中まで書きました。
A 君が書いたプログラムに追記し、プログラムを完成させてください。
ページ末尾に問題のヒントがあります。詰まったら見てみましょう。
A君が書いたプログラム
def sum_scores(scores):
"""
1 人のテストの点数を表すリストから合計点を計算して返す関数
引数 scores: scores[i] に i 番目のテストの点数が入っている
返り値: 1 人のテストの合計点
"""
# ここにプログラムを追記
def output(sum_a, sum_b, sum_c):
"""
3 人の合計点からプレゼントの予算を計算して出力する関数
引数 sum_a: A 君のテストの合計点
引数 sum_b: B 君のテストの合計点
引数 sum_c: C 君のテストの合計点
返り値: なし
"""
# ここにプログラムを追記
# -------------------
# ここから先は変更しない
# -------------------
def input_list(N):
"""
N 個の入力を受け取ってリストに入れて返す関数
引数 N: 入力を受け取る個数
返り値: 受け取った N 個の整数値からなるリスト
"""
l = list(map(int, input().split()))
return l
# 科目の数 N を受け取る
N = int(input())
# それぞれのテストの点数を受け取る
A = input_list(N)
B = input_list(N)
C = input_list(N)
# それぞれの合計点を計算
sum_A = sum_scores(A)
sum_B = sum_scores(B)
sum_C = sum_scores(C)
# プレゼントの予算を出力
output(sum_A, sum_B, sum_C)
制約
- 1 \le N \le 10
- 0 \le A_i, B_i, C_i \le 100
- N, A_i, B_i, C_i は整数
入力
入力は次の形式で標準入力から与えられます。
N A_1 A_2 \cdots A_N B_1 B_2 \cdots B_N C_1 C_2 \cdots C_N
出力
プレゼントの予算を出力してください。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
2 5 7 4 10 9 2
出力例1
1848
問題文で説明したケースです。
入力例2
3 100 100 100 100 100 100 100 100 100
出力例2
27000000
300 \times 300 \times 300 = 27000000 なので、三人兄弟は 27000000 円分のプレゼントを貰えることになりました。
入力例3
5 95 20 74 81 10 100 50 32 84 31 0 0 0 0 0
出力例3
0
C 君の合計点が 0 点だったので、プレゼントの予算も 0 円になります。
入力例4
2 10 0 0 5 1 1
出力例4
100
ヒント1
クリックでヒントを見る
今回の問題は今までの問題とは少し異なり、用意されたプログラムの動作を理解し、意図を読み取る必要があります。
プログラムがどのような順番で実行されていくかに注意して、A 君が書いたプログラムを読んでみましょう。
ヒント2
この問題は「A 君が書いたプログラムに追記して完成させる」という問題ですが、ヒントとして関数を使わずにこの問題と同じ処理をするプログラムを示します。このプログラムを参考にして A 君の sum_scores 関数と output 関数を完成させてください。
クリックでヒントプログラムを見る
# 科目の数 N を受け取る N = int(input()) # それぞれのテストの点数を受け取る # N 個の入力をそれぞれ受け取り、リスト A, B, C とする A = list(map(int, input().split())) B = list(map(int, input().split())) C = list(map(int, input().split())) # 以下はプレゼントの予算を出力する処理 # テストの点数を表すリストからそれぞれの合計点を計算 sum_a = sum(A) sum_b = sum(B) sum_c = sum(C) # 3 人の合計点からプレゼントの予算を計算して出力する print(sum_a * sum_b * sum_c)
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
10 2 8 3 1 10 8 32 15 9 100 5 1 2 0 3 2 1 10 43 20 0 100 7 10 0 82 19 0 90 51
テスト出力1
5871804
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
def sum_scores(scores):
"""
1 人のテストの点数を表すリストから合計点を計算して返す関数
引数 scores: scores[i] に i 番目のテストの点数が入っている
返り値: 1 人のテストの合計点
"""
s = sum(scores)
return s
def output(sum_a, sum_b, sum_c):
"""
3 人の合計点からプレゼントの予算を計算して出力する関数
引数 sum_a: A 君のテストの合計点
引数 sum_b: B 君のテストの合計点
引数 sum_c: C 君のテストの合計点
返り値: なし
"""
print(sum_a * sum_b * sum_c)
# -------------------
# ここから先は変更しない
# -------------------
def input_list(N):
"""
N 個の入力を受け取ってリストに入れて返す関数
引数 N: 入力を受け取る個数
返り値: 受け取った N 個の整数値からなるリスト
"""
l = list(map(int, input().split()))
return l
# 科目の数 N を受け取る
N = int(input())
# それぞれのテストの点数を受け取る
A = input_list(N)
B = input_list(N)
C = input_list(N)
# それぞれの合計点を計算
sum_A = sum_scores(A)
sum_B = sum_scores(B)
sum_C = sum_scores(C)
# プレゼントの予算を出力
output(sum_A, sum_B, sum_C)
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
5つの要素からなる配列が与えられます。
同じ値の要素が隣り合っているような箇所が存在するかどうかを判定してください。
存在するなら"YES"を、存在しなければ"NO"を出力してください。
この問題も以下の手順で解いてみましょう。
- ループを使わないで書く
- パターンを見つける
- ループで書き直す
data = [int(c) for c in input().split()] # dataの中で隣り合う等しい要素が存在するなら"YES"を出力し、そうでなければ"NO"を出力する # ここにプログラムを追記
制約
- 0≦A_i≦100 (1 ≦ i ≦ 5)
- A_i (1 ≦ i ≦ 5)は整数
入力
入力は次の形式で標準入力から与えられます。
A_1 A_2 A_3 A_4 A_5
出力
配列の隣り合う要素のうち、値が等しいものが存在するなら"YES"を、存在しなければ"NO"を出力してください。
出力の最後には改行が必要です。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
5 3 3 1 4
出力例1
YES
入力例2
1 1 2 3 4
出力例2
YES
入力例3
1 2 1 2 1
出力例3
NO
入力例4
100 100 100 100 100
出力例4
YES
ヒント
- ループを使わないで書く
- パターンを見つける
- ループで書き直す
に沿って書く場合の流れをヒントで説明します。
まずは自分で考えてみて、詰まったら見てみましょう。
ヒント1 (ループを使わないで書く)
隣合っている等しい要素があるかを順番に確認します。クリックでヒントプログラムを見る
# dataの中で隣り合う等しい要素が存在するなら"YES"を出力し、そうでなければ"NO"を出力する
if data[0]==data[1] or data[1]==data[2] or data[2]==data[3] or data[3]==data[4]:
print("YES")
else:
print("NO")
ヒント2 (パターンを見つける)
繰り返しのパターンを見つけます。 このままだと直接for文に書き換えにくいので,「または」の条件を複数のif文に分解します。 次のパターンが繰り返し存在していることが分かります。クリックでヒントを見る
ヒント1のヒントプログラムでは2行目のif文の中身が同じパターンの繰り返しになっています。if data[0]==data[1] or data[1]==data[2] or data[2]==data[3] or data[3]==data[4]:
また、答えがYESなのかNOなのかをbool型の変数に入れるようにします。次のプログラムではYESならTrue、NOならFalseとしています。ans = False # 始めはfalseにしておき、条件を満たすときにtrueになるようにする
if data[0]==data[1]:
ans = True
if data[1]==data[2]:
ans = True
if data[2]==data[3]:
ans = True
if data[3]==data[4]:
ans = True
if ans:
print("YES")
else:
print("NO")
if data[k]==data[k+1]:
ans = True
ヒント3 (ループで書き直す)
以下のように for 文を書いてみてください:クリックでヒントを見る
ans = False
for k in (#ここを埋めてください):
if data[k]==data[i+1]:
ans = True
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
0 1 2 3 3
テスト出力1
YES
テスト入力2
0 1 100 100 4
テスト出力2
YES
テスト入力3
40 30 66 44 65
テスト出力3
NO
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
data = [int(c) for c in input().split()]
# dataの中で隣り合う等しい要素が存在するなら"YES"を出力し、そうでなければ"NO"を出力する
ans = False # 始めはfalseにしておき、条件を満たすときにtrueになるようにする
for k in range(len(data)-1):
if data[k]==data[k+1]:
ans = True
if ans:
print("YES")
else:
print("NO")
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
ある果物屋では、リンゴ・パイナップルがそれぞれN個売られています。i個目のリンゴ、パイナップルはそれぞれA_i円、P_i円です。
リンゴ・パイナップルをそれぞれ1つずつ選んで購入しようとするとき、合計金額が丁度S円になるような買い方が何通りあるか求めてください。
ただし、同じ値段の同じ種類の商品でも区別します。たとえば同じ値段のリンゴが複数あった場合、それらを買う場合は別の買い方として数えます。パイナップルについても同様です。また、リンゴ・パイナップルを買う順番は考慮しないものとします。
制約
- 0\le N\le 100
- 0\le S\le 1000
- 1\le A_i, P_i\le 500\ (1 \le i \le N)
- 入力される値はすべて整数である
入力
入力は次の形式で標準入力から与えられます。
N S A_1 A_2 \cdots A_N P_1 P_2 \cdots P_N
出力
リンゴ・パイナップルをそれぞれ1つずつ購入しようとするとき、合計金額が丁度S円になるような買い方が何通りあるかを出力してください。
サンプルプログラム
入力を受け取るサンプルプログラムを以下に示します。
N, S = map(int, input().split()) A = list(map(int, input().split())) B = list(map(int, input().split())) # リンゴ・パイナップルをそれぞれ1つずつ購入するとき合計S円になるような買い方が何通りあるか # ここにプログラムを追記
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
3 400 100 100 130 270 300 250
出力例1
3
合計が400円になる買い方は以下の3通りです。
1つ目のリンゴ、2つ目のパイナップルを購入すると、100円 + 300円 = 400円となります。
2つ目のリンゴ、2つ目のパイナップルを購入すると、100円 + 300円 = 400円となります。
3つ目のリンゴ、1つ目のパイナップルを購入すると、130円 + 270円 = 400円となります。
1つ目のリンゴと2つ目のリンゴがどちらも100円ですが、別の買い方として数えることに注意してください。
入力例2
10 600 70 110 90 120 90 20 260 150 220 150 170 100 250 350 60 280 450 460 20 220
出力例2
2
入力例3
3 200 100 100 100 100 100 100
出力例3
9
入力例4
1 0 100 200
出力例4
0
合計0円で買うことはできません。
ヒント
- ループを使わないで書く
- パターンを見つける
- ループで書き直す
に沿って書く場合の流れをヒントで説明します。
まずは自分で考えてみて、詰まったら見てみましょう。
ヒント1 (ループを使わないで書く)
合計がS円になるような買い方が何通りあるかを求めるので、 一般のNでは考えにくいので、試してみるときはNを小さい値で仮定してみるとよいです。 添え字の変化に着目するとパターン化できそうです。クリックでヒントを見る
すべての組み合わせをif文で確認できれば答えが求まるはずです。
N = 3のケースを全て書き出してみます。(添え字として0始まりの値を使っている点に注意してください。)ans = 0
if A[0] + P[0] == S:
ans += 1
if A[0] + P[1] == S:
ans += 1
if A[0] + P[2] == S:
ans += 1
if A[1] + P[0] == S:
ans += 1
if A[1] + P[1] == S:
ans += 1
if A[1] + P[2] == S:
ans += 1
if A[2] + P[0] == S:
ans += 1
if A[2] + P[1] == S:
ans += 1
if A[2] + P[2] == S:
ans += 1
ヒント2 (パターンを見つける)
変数i, jを導入してi番目のリンゴ、j番目のパイナップルを買う場合を考えます。 あとはi, jを網羅的に動かして上の文を実行できればよいです。クリックでヒントを見る
条件式は次のようになります。if A[i] + P[j] == S:
ans += 1
ヒント3 (ループで書き直す)
変数i, jを導入してi番目のリンゴ、j番目のパイナップルを買う場合の判定文は次のようになります。 i, jはそれぞれ別々に0からN - 1までの値を取ります。クリックでヒントを見る
if A[i] + P[j] == S:
ans += 1
このように変数(ここではi, j)の組み合わせを列挙したい場合は、多重ループを用います。
今回の場合は変数がi, jの2つなので、次のような二重ループになります。for i in range(N):
for j in range(N):
# i, jを使う
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
10 520
430 310 230 390 130 220 70 370 400 160
390 120 450 30 250 140 200 300 270 30
テスト出力1
4
テスト入力2
100 500
247 365 116 339 302 274 383 230 444 136 12 100 92 498 16 190 252 438 404 493 46 105 197 254 180 455 233 280 289 286 301 205 200 477 273 481 494 287 202 211 327 359 341 4 51 336 101 416 142 35 401 457 61 179 33 362 180 176 60 247 499 44 279 372 424 439 224 99 379 322 110 159 383 143 164 435 6 461 61 391 38 225 163 273 222 156 33 300 42 228 164 22 244 66 28 208 243 36 417 93
62 231 388 7 434 37 474 357 262 182 36 298 426 331 252 129 113 156 111 441 375 210 492 499 302 287 493 170 262 233 475 406 72 401 468 156 220 1 410 12 223 150 240 159 345 239 455 404 419 19 46 174 499 218 423 145 196 307 401 260 470 424 171 284 437 44 500 316 156 192 422 391 365 485 145 22 410 124 110 182 28 143 203 289 95 85 415 401 191 268 262 341 391 130 364 274 379 443 53 389
テスト出力2
15
テスト入力3
100 1000
500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500
500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500
テスト出力3
10000
解答例
必ず自分で問題に挑戦してみてから見てください。
解答例1 解答例2 (Listに対するfor文を用いた解法)クリックで解答例を見る
# 入力値を読み込む
N, S = map(int, input().split())
A = list(map(int, input().split()))
P = list(map(int, input().split()))
# りんごとパイナップルを1つずつ購入する組み合わせが、合計S円になる方法の数を計算する
ans = 0 # 方法の数をカウントするための変数
# すべての組み合わせをチェック
for i in range(N):
for j in range(N):
if A[i] + P[j] == S:
ans += 1
# 結果を出力
print(ans)
# 入力値を読み込む
N, S = map(int, input().split())
A = list(map(int, input().split()))
P = list(map(int, input().split()))
# りんごとパイナップルを1つずつ購入する組み合わせが、合計S円になる方法の数を計算する
ans = 0 # 方法の数をカウントするための変数
# すべての組み合わせをチェック
for x in A:
for y in P:
if x + y == S:
ans += 1
# 結果を出力
print(ans)
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
明日、英語の単語テストがあります。出題される可能性のある単語は S_1, S_2, \dots, S_N の N 個です。
長い単語が好きであるあなたは、これらの単語のうち K 文字以上の単語を勉強することにしました。
S_1, S_2, \dots, S_N から K 文字以上 の単語を取り出し、順序を変えず空白区切りで 1 行に出力してください。
注意: この問題は for 文のみで正答することが可能です。しかし本節は内包表記の節ですので、極力内包表記を使った回答を考えてみてください。
制約
- 1 \le N \le 20
- 1 \le K \le 16
- S_i\ (1 \le i \le N) は英小文字からなる長さ 1 以上 15 以下の文字列である。
入力
入力は以下の形式で標準入力から与えられる。
N K S_1 S_2 \cdots S_N
出力
S_1, S_2, \dots, S_N から K 文字以上 の単語を取り出し、順序を変えず空白区切りで 1 行に出力せよ。
ただし、K 文字以上の単語が 1 個もない場合は、空行を出力せよ。
入力例 1
8 6 apple is solution dog hospital tree success cat
出力例 1
solution hospital success
apple, is, solution, dog, hospital, tree, success, cat のうち、6 文字以上の単語は solution, hospital, success の 3 個です。
入力例 2
10 5 study pen computer car table bus education phone veil aide
出力例 2
study computer table education phone
入力例 3
5 10 selection island advice training trial
出力例 3
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
1 1
a
テスト出力1
a
テスト入力2
20 16
appearance relationship instruction proof recommendation analysis development accommodation requirement transportation announcement assistance difference understanding identification freedom population aspect conference environment
テスト出力2
テスト入力3
20 13
responsibility advertisement achievement determination embarrassment opportunity explanation imagination information independence consideration application introduction organization presentation communication appreciation cooperation observation preparation
テスト出力3
responsibility advertisement determination embarrassment consideration communication
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
# 入力
N, K = map(int, input().split())
S = input().split()
# K文字以上の単語を抽出
result = [word for word in S if len(word) >= K]
# 空白区切りで出力
print(*result)
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
あるゲーム大会に 1 から N の番号が割り当てられた N 人が参加し、総当たり形式で試合が行われます。これまでに M 回の試合が行われました。i 番目 (1 ≤ i ≤ M) の試合では参加者 A_i と参加者 B_i が勝負し、勝者は参加者 A_i で、敗者は参加者 B_i でした。
M 回の試合が終了した時点での試合結果の表を作成し、出力してください。
制約
- 1\le N\le 100
- 0\le M\le \frac{N\cdot(N-1)}{2}
- 1\le A_i, B_i\le N\ (1 \le i \le M)
- A_i \neq B_i\ (1 \le i \le M)
- 同じ参加者同士が 2 回以上試合を行うことはない
- 入力される値はすべて整数である
入力
入力は次の形式で標準入力から与えられる。
N M A_1 B_1 A_2 B_2 A_3 B_3 : : A_M B_M
出力
M 試合が終了した時点での試合結果の表を以下の形式で出力せよ。
R_{1, 1} R_{1, 2} R_{1, 3} \cdots R_{1, N}
R_{2, 1} R_{2, 2} R_{2, 3} \cdots R_{2, N}
R_{3, 1} R_{3, 2} R_{3, 3} \cdots R_{3, N}
\vdots \vdots \vdots \vdots \ddots \vdots
R_{N, 1} R_{N, 2} R_{N, 3} \cdots R_{N, N}
ここで、R_{i, j} (1 ≤ i,j ≤ N) は以下で定義される文字である。
- 参加者 i と参加者 j が試合をした場合
- その試合で参加者 i が勝ったなら、R_{i, j} = {}
o - その試合で参加者 i が負けたなら、R_{i, j} = {}
x - 参加者 i と参加者 j が試合をしていない場合
- R_{i, j} = {}
-
入出力例も参考にしてください。
サンプルプログラム
N, M = map(int, input().split()) AB = [list(map(int, input().split())) for i in range(M)] # ここにコードを追記する
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
3 2 1 2 3 1
出力例1
- o x x - - o - -
- 最初の試合では参加者 1 と参加者 2 が試合を行い参加者 1 が勝ったので、R_{1, 2} = {}
o、R_{2, 1} = {}xとなります。 - 2 番目の試合では参加者 3 と参加者 1 が試合を行い参加者 3 が勝ったので、R_{3, 1} = {}
o、R_{1, 3} = {}xとなります。 - これ以外の試合は行われていないので、残りのマスは R_{i, j} = {}
-となります。
入力例2
7 12 1 5 5 4 6 2 1 7 2 4 6 3 1 3 6 4 3 7 5 7 4 3 6 1
出力例2
- - o - o x o - - - o - x - x - - x - x o - x o - x x - x - - o - - o o o o o - - - x - x - x - -
入力例3
1 0
出力例3
-
ヒント
まずは、試合結果の表をプログラムで管理するために、N\cross Nの2次元配列を用意しましょう。 初期値が0で縦a行、横b列の2次元配列の宣言方法は次の通りでした。クリックでヒントを開く
result = [[0] * b for _ in range(a)]
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
データが大きすぎるため省略クリックでテスト入出力を見る
テスト入力1
4 6
1 2
1 3
1 4
2 3
2 4
3 4
テスト出力1
- o o o
x - o o
x x - o
x x x -
テスト入力2
20 56
14 18
8 19
18 20
5 15
17 3
12 15
7 3
14 12
18 17
2 12
4 12
17 5
11 10
14 13
8 5
8 1
16 13
17 7
16 18
20 8
10 7
9 20
17 11
8 2
6 4
9 19
13 3
7 15
13 9
4 2
18 7
20 2
17 2
8 18
5 16
1 12
6 1
11 2
9 6
11 15
17 19
18 6
8 17
15 10
10 6
1 18
15 19
9 7
2 14
4 19
20 11
16 12
5 2
16 9
13 2
12 20
テスト出力2
- - - - - x - x - - - o - - - - - o - -
- - - x x - - x - - x o x o - - x - - x
- - - - - - x - - - - - x - - - x - - -
- o - - - x - - - - - o - - - - - - o -
- o - - - - - x - - - - - - o o x - - -
o - - o - - - - x x - - - - - - - x - -
- - o - - - - - x x - - - - o - x x - -
o o - - o - - - - - - - - - - - o o o x
- - - - - o o - - - - - x - - x - - o o
- - - - - o o - - - x - - - x - - - - -
- o - - - - - - - o - - - - o - x - - x
x x - x - - - - - - - - - x o x - - - o
- o o - - - - - o - - - - x - x - - - -
- x - - - - - - - - - o o - - - - o - -
- - - - x - x - - o x x - - - - - - o -
- - - - x - - - o - - o o - - - - o - -
- o o - o - o x - - o - - - - - - x o -
x - - - - o o x - - - - - x - x o - - o
- - - x - - - x x - - - - - x - x - - -
- o - - - - - o x - o x - - - - - x - -
テスト入力3
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
N, M = map(int, input().split())
AB = [list(map(int, input().split())) for i in range(M)]
result = [["-"] * N for _ in range(N)]
for a, b in AB:
a -=1
b -=1
result[a][b] = "o"
result[b][a] = "x"
for row in result:
print(" ".join(row))
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
あなたは A 社を経営する社長です。A 社は N 個の組織からなり、それぞれに 0 から N - 1 までの番号が付いています。組織 0 はトップの組織です。
組織間には親子関係があり、組織 0 以外の N - 1 個の組織にはそれぞれ 1 つの親組織が存在します。
組織 i\ (1 ≤ i ≤ N - 1) の親組織は組織 p_i です。
ここで、ある組織からその組織の親組織をたどることを繰り返すと、必ずトップの組織(組織 0)に到達します。
あなたは全ての組織に報告書を提出するように求めました。
混雑を避けるために、「各組織は子組織の報告書がそろったら、自身の報告書 1 枚を加えて親組織に送る」ことを繰り返します。子組織が無いような組織は自身の報告書 1 枚だけをすぐに親組織に送ります。
トップの組織は子組織の報告書がそろったら、自身の報告書を加えて社長に提出します。
各組織について、「その組織が親組織に提出することになる報告書の枚数」を出力するプログラムを作成してください。
ただしトップの組織については「社長に提出する報告書の枚数」を出力してください。
制約
- 1 ≤ N ≤ 50
- 0 ≤ p_i ≤ N - 1\ (1 ≤ i ≤ N - 1)
- ある組織からその組織の親組織をたどることを繰り返すと、必ずトップの組織(組織 0)に到達する。
- 入力される値はすべて整数である。
入力
入力は次の形式で標準入力から与えられます。
N
p_1 p_2 p_3 \ldots p_{N - 1}
組織 0 はトップの組織であり、親組織が存在しないことに注意してください。
出力
\text{ans}_0
\text{ans}_1
\text{ans}_2
\vdots
\text{ans}_{N - 1}
N 行出力してください。i + 1 行目 (0 ≤ i ≤ N-1) には、組織 i についての答え \text{ans}_i を出力してください。
サンプルプログラム
# x 番の組織が親組織に提出する報告書の枚数を返す関数
def num_report(children, x):
# ここに追記して再帰関数を実装する
# これ以降の行は変更しなくてよい
N = int(input())
# p[i] : 組織 i の親組織
# 組織 0 の親組織は存在しないので -1 を入れておく
# 組織 0 に相当する部分は入力で与えられないため、リスト [-1] を作成して "+" 演算子で結合する
p = [-1] + [int(c) for c in input().split()]
# children[i] = 組織 i の子組織のリスト
children = [[] for _ in range(N)]
for i in range(1, N):
parent = p[i] # 組織 i の親組織は parent
children[parent].append(i) # parent の子組織リストに i を追加
# 各組織について答えを計算し出力する
for i in range(N):
res = num_report(children, i)
print(res)
関数 num_report の引数 children は二次元リストで、組織 x の子組織の番号一覧はchildren[x] で得ることができます。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
6 0 0 1 1 4
出力例1
6 4 1 1 2 1
組織の関係は次の図のようになります。(子組織から親組織の向きに矢印が向いています。)
番号の隣に書いてある青い数字が各組織についての答えです。
入力例2
8 0 0 1 2 0 3 6
出力例2
8 4 2 3 1 1 2 1
組織の関係は次の図のようになります。(子組織から親組織の向きに矢印が向いています。)
番号の隣に書いてある青い数字が各組織についての答えです。
ヒント
次のようにすることで この問題は 2.05.再帰関数 の例題に非常に近い問題となっているので、そちらも参考にしてください。クリックでヒントを開く
x 番の組織の子組織についての処理が行えます。for c in children[x]:
# (c についての処理)
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
20
0 1 1 3 0 0 1 3 5 9 6 8 8 8 0 4 7 12 13
テスト出力1
20
13
1
9
2
3
2
2
6
2
1
1
2
2
1
1
1
1
1
1
テスト入力2
30
0 1 0 1 0 3 1 2 8 6 1 3 0 4 2 3 0 14 16 13 5 2 16 14 19 2 7 2 26
テスト出力2
30
16
8
8
4
2
2
2
2
1
1
1
1
2
3
1
4
1
1
2
1
1
1
1
1
1
2
1
1
1
テスト入力3
50
0 0 0 2 3 1 6 3 4 0 9 5 2 12 7 13 14 1 3 14 2 10 17 7 8 1 15 11 19 29 26 20 7 18 10 24 19 2 19 29 29 9 21 42 0 19 24 44 26
テスト出力3
50
14
13
18
7
7
8
7
2
6
3
2
6
2
5
2
1
2
2
8
2
2
1
1
3
1
3
1
1
4
1
1
1
1
1
1
1
1
1
1
1
1
3
1
2
1
1
1
1
1
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
# x 番の組織が親組織に提出する報告書の枚数を返す関数
def num_report(children, x):
# ここに追記して再帰関数を実装する
# ベースケース
if not children[x]:
return 1
# 再帰ステップ
ans = 1 # 自身の報告書
for c in children[x]:
ans += num_report(children, c)
return ans
# これ以降の行は変更しなくてよい
N = int(input())
# p[i] : 組織 i の親組織
# 組織 0 の親組織は存在しないので -1 を入れておく
# 組織 0 に相当する部分は入力で与えられないため、リスト [-1] を作成して "+" 演算子で結合する
p = [-1] + list(map(int, input().split()))
# children[i] = 組織 i の子組織のリスト
children = [[] for _ in range(N)]
for i in range(1, N):
parent = p[i] # 組織 i の親組織は parent
children[parent].append(i) # parent の子組織リストに i を追加
# 各組織について答えを計算し出力する
for i in range(N):
res = num_report(children, i)
print(res)
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
次のプログラムでは f0 から f5 の 6 つの関数が定義されており、main 関数から呼び出されています。
それぞれの関数の計算量を見積もって、最も計算時間のかかる関数を呼び出している行をコメントアウトし、PyPy で提出してください。
制限時間は 2 秒です。なお、AtCoder のジャッジでは 1 秒あたり 10^8 〜 10^9 回程度の計算が可能です。
最も計算時間のかかる関数を呼び出している行がコメントアウトされていない場合、提出結果は となります。
また、PyPy ではなく CPython で提出すると、正しくコメントアウトされている場合でも となるので注意してください。
制約を読み、各関数の実行時間を見積もりましょう。
プログラム
def f0(N):
return 1
def f1(N, M):
s = 0
for i in range(N):
s += 1
for i in range(M):
s += 1
return s
def f2(N):
s = 0
for i in range(N):
t = N
cnt = 0
while t > 0:
cnt += 1
t //= 2
s += cnt
return s
def f3(N):
s = 0
for i in range(3):
for j in range(3):
s += 1
return s
def f4(N):
s = 0
for i in range(N):
for j in range(N):
s += i + j
return s
def f5(N, M):
s = 0
for i in range(N):
for j in range(M):
s += i + j
return s
# 標準入力から値を取得
N, M = map(int, input().split())
# 計算結果の変数を初期化
a0, a1, a2, a3, a4, a5 = -1, -1, -1, -1, -1, -1
# 計算量が最も大きいものを 1 つだけコメントアウトする (先頭に # をつける)
a0 = f0(N)
a1 = f1(N, M)
a2 = f2(N)
a3 = f3(N)
a4 = f4(N)
a5 = f5(N, M)
# 結果を出力
print(f"f0: {a0}")
print(f"f1: {a1}")
print(f"f2: {a2}")
print(f"f3: {a3}")
print(f"f4: {a4}")
print(f"f5: {a5}")
制約
- 0 \leq N \leq 10^6
- 0 \leq M \leq 10^2
回答例
答え方の例です。
この例では f0 の呼び出しをコメントアウトしていますが、f0 の計算量は O(1) 時間なので、この回答は不正解 となります。
def f0(N):
return 1
def f1(N, M):
s = 0
for i in range(N):
s += 1
for i in range(M):
s += 1
return s
def f2(N):
s = 0
for i in range(N):
t = N
cnt = 0
while t > 0:
cnt += 1
t //= 2
s += cnt
return s
def f3(N):
s = 0
for i in range(3):
for j in range(3):
s += 1
return s
def f4(N):
s = 0
for i in range(N):
for j in range(N):
s += i + j
return s
def f5(N, M):
s = 0
for i in range(N):
for j in range(M):
s += i + j
return s
# 標準入力から値を取得
N, M = map(int, input().split())
# 計算結果の変数を初期化
a0, a1, a2, a3, a4, a5 = -1, -1, -1, -1, -1, -1
# 計算量が最も大きいものを 1 つだけコメントアウトする (先頭に # をつける)
# a0 = f0(N)
a1 = f1(N, M)
a2 = f2(N)
a3 = f3(N)
a4 = f4(N)
a5 = f5(N, M)
# 結果を出力
print(f"f0: {a0}")
print(f"f1: {a1}")
print(f"f2: {a2}")
print(f"f3: {a3}")
print(f"f4: {a4}")
print(f"f5: {a5}")
ヒント
それぞれの関数の時間計算量を示します。 N と M の大きさを考えて、最も実行時間が長いものをコメントアウトしましょう。クリックでヒントを開く
時間計算量
f0O(1)
f1O(N+M)
f2O(N \log N)
f3O(1)
f4O(N^2)
f5O(NM)
テスト入出力
書いたプログラムが AC にならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
1000000 100
テスト出力1
f0: 1
f1: 1000100
f2: 20000000
f3: 9
f4: -1
f5: 50004900000000
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
def f0(N):
return 1
def f1(N, M):
s = 0
for i in range(N):
s += 1
for i in range(M):
s += 1
return s
def f2(N):
s = 0
for i in range(N):
t = N
cnt = 0
while t > 0:
cnt += 1
t //= 2
s += cnt
return s
def f3(N):
s = 0
for i in range(3):
for j in range(3):
s += 1
return s
def f4(N):
s = 0
for i in range(N):
for j in range(N):
s += i + j
return s
def f5(N, M):
s = 0
for i in range(N):
for j in range(M):
s += i + j
return s
# 標準入力から値を取得
N, M = map(int, input().split())
# 計算結果の変数を初期化
a0, a1, a2, a3, a4, a5 = -1, -1, -1, -1, -1, -1
# 計算量が最も大きいものを 1 つだけコメントアウトする (先頭に # をつける)
a0 = f0(N)
a1 = f1(N, M)
a2 = f2(N)
a3 = f3(N)
# a4 = f4(N)
a5 = f5(N, M)
# 結果を出力
print(f"f0: {a0}")
print(f"f1: {a1}")
print(f"f2: {a2}")
print(f"f3: {a3}")
print(f"f4: {a4}")
print(f"f5: {a5}")
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
N要素の配列 A₁, A₂, …, Aₙ が与えられます。
この配列の中の値のうち、出現回数が最も多い値とその出現回数を求めてください。
ただし、出現回数が最大になる値は複数存在しないものとします。
制約が大きいため計算量に注意してプログラムを作成してください。
制約
- 0 ≤ N ≤ 10⁵
- 0 ≤ Aᵢ ≤ 10⁹ (1 ≤ i ≤ N)
- 出現回数が最大になるような値は複数存在しない
入力
入力は次の形式で標準入力から与えられます:
N A₁ A₂ … Aₙ
出力
値 出現回数
出現回数が最も多い値と、その出現回数をスペース区切りで出力してください。
- ジャッジでは入力例以外のケースに関してもテストされることに注意してください。
- 特に、ジャッジのテストケースには大きい入力が含まれているので、TLEにならないように注意してください。
入力例1
5 1 4 4 2 3
出力例1
4 2
入力の配列に含まれる各値の出現回数は以下のようになっています。
- 1 の出現回数は 1 回
- 2 の出現回数は 1 回
- 3 の出現回数は 1 回
- 4 の出現回数は 2 回
出現回数 2 回が最大でその値は 4 なので、4 2 と出力します。
入力例2
6 3 2 3 1 3 2
出力例2
3 3
入力例3
1 1000000000
出力例3
1000000000 1
ヒント
クリックでヒントを開く
dict で管理しましょう。 dict への追加・アクセスの計算量は O(1) です。 N² は 10¹⁰ なので、O(N²) では TLE になります。 N log N ≈ 1.6×10⁶ なので、O(N log N) なら十分間に合います。
テスト入出力
データが大きすぎるため省略 データが大きすぎるため省略クリックでテスト入出力を見る
テスト入力1
テスト入力2
解答例(Python)
クリックで解答例を見る
N = int(input())
A = list(map(int, input().split()))
cnt = {}
for x in A:
if x in cnt:
# 既に含まれているなら +1
cnt[x] += 1
else:
# 含まれていないなら、1を追加
cnt[x] = 1
max_cnt = 0 # 出現回数の最大値を保持
ans = -1 # 出現回数が最大になる値を保持
for x in A:
# 今見ているxの出現回数が、その時点の最大よりも大きければ更新
if max_cnt < cnt[x]:
max_cnt = cnt[x]
ans = x
print(ans, max_cnt)
実行時間制限: 2 sec / メモリ制限: 1024 MiB
この問題は ABC213 の A 問題「Bitwise Exclusive Or」に追記したものです。また、テストケースは別のものとなっています。
問題文
0 \le A, B \le 255 の整数 A, B が与えられます。
A \text{ xor } C = B となる 0 以上の整数 C を求めてください。
なお、そのような C はただ 1 つ存在し、0 \le C \le 255
であることが証明されます。
整数 a, b のビットごとの排他的論理和 a \text{ xor } b 例えば、3 \text{ xor } 5 = 6 となります。xor とは
は、以下のように定義されます。
(二進表記すると: 011 \text{ xor } 101 = 110)
制約
- 0 \le A, B \le 255
- 入力に含まれる値はすべて整数である
入力
入力は以下の形式で標準入力から与えられる。
A B
出力
答えを出力せよ。
入力例 1
3 6
出力例 1
5
3 は二進表記で 011、5 は二進表記で 101 なので、これらの \text{ xor } は二進表記で 110、十進表記で 6 です。
このように、3 \text{ xor } 5 = 6 となるので、答えは 5 です。
入力例 2
10 12
出力例 2
6
ヒント
クリックでヒントを開く
x ^ y と書けます。
テスト入出力
書いたプログラムがACにならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
255 255
テスト出力1
0
テスト入力2
123 45
テスト出力2
86
テスト入力3
101 154
テスト出力3
255
解答例(Python)
クリックで解答例1を見る
A, B = map(int, input().split())
# C の候補を全て試し、A xor C = B を満たすか確かめる
for C in range(256):
if (A ^ C) == B:
print(C)
クリックで解答例2を見る
A, B = map(int, input().split())
# A xor C = B のとき、C = A xor B となる
print(A ^ B)
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
整数 a_i, b_i のペア (a_i, b_i) が N 個与えられます(1 \le i \le N)。
b_i が小さい順にペアを並べ替えてください。
制約
- 1 \le N \le 100
- 1 \le a_i, b_i \le 10^9
- b_i は全て異なる
- 入力はすべて整数
入力
入力は次の形式で標準入力から与えられます。
N a_1 b_1 a_2 b_2 ⋮ ⋮ a_N b_N
出力
ペアを並べ替えた順に 1 行毎に出力してください。
各ペアは a_i, b_i をスペース区切りで出力してください。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
3 5 2 2 7 4 1
出力例1
4 1 5 2 2 7
(5, 2), (2, 7), (4, 1) という 3 つのペアがあり、b_i の値が小さい順に並べ替えると、(4, 1), (5, 2), (2, 7) となります。
入力例2
5 1 2 3 4 5 6 7 8 9 10
出力例2
1 2 3 4 5 6 7 8 9 10
ヒント
クリックでヒントを開く
tuple で 2 つの整数のペアを表すことができます。a.sort() とします。
テスト入出力
書いたプログラムが AC にならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
100
93 4
54 22
36 41
55 65
48 27
12 1
37 67
68 39
80 10
56 8
87 90
16 47
76 88
38 13
46 87
40 48
84 68
94 33
49 29
3 11
98 6
18 21
85 77
23 45
73 58
78 42
31 12
21 60
66 54
47 14
9 7
28 53
41 82
91 83
61 74
92 91
96 95
90 81
17 66
22 89
72 43
39 56
57 80
70 100
58 69
74 34
51 64
25 20
67 25
97 62
63 55
19 26
15 2
82 5
20 92
34 31
43 73
79 28
1 57
99 32
13 38
88 36
24 51
59 19
64 23
89 79
65 3
81 84
27 78
44 52
53 59
6 61
50 71
14 40
2 49
83 75
77 96
30 85
95 15
71 86
35 50
52 44
42 18
75 70
29 94
8 46
60 76
5 98
69 93
11 99
10 72
32 35
7 9
86 24
26 16
62 17
100 97
4 30
45 63
33 37
テスト出力1
12 1
15 2
65 3
93 4
82 5
98 6
9 7
56 8
7 9
80 10
3 11
31 12
38 13
47 14
95 15
26 16
62 17
42 18
59 19
25 20
18 21
54 22
64 23
86 24
67 25
19 26
48 27
79 28
49 29
4 30
34 31
99 32
94 33
74 34
32 35
88 36
33 37
13 38
68 39
14 40
36 41
78 42
72 43
52 44
23 45
8 46
16 47
40 48
2 49
35 50
24 51
44 52
28 53
66 54
63 55
39 56
1 57
73 58
53 59
21 60
6 61
97 62
45 63
51 64
55 65
17 66
37 67
84 68
58 69
75 70
50 71
10 72
43 73
61 74
83 75
60 76
85 77
27 78
89 79
57 80
90 81
41 82
91 83
81 84
30 85
71 86
46 87
76 88
22 89
87 90
92 91
20 92
69 93
29 94
96 95
77 96
100 97
5 98
11 99
70 100
テスト入力2
100
516111320 607515272
222610184 248356480
61883986 245487676
206662228 533989888
69129331 777444148
240199961 432234636
426231114 336813804
321022003 57262799
987178129 850725892
947102866 972781313
925126447 138391343
616274448 355808755
714725587 135574527
242294936 747031846
712001433 210877082
181182763 770306728
93942008 774494957
724829041 835108740
344285556 521741371
833231327 603241645
607948534 214246948
918457894 886239485
235309772 705607918
283022479 376033551
274016160 224876948
119317651 487762742
86470334 681700654
230829137 667556773
786823599 522783812
552745413 742568795
187877449 678955882
92450487 797581025
57997903 741784382
15453784 899476414
228873791 489714188
923423708 985237362
178220373 117577774
523186879 681227121
841286768 74441749
229826134 478391450
62710049 210080103
594857199 60772664
728567957 220290043
277000690 799270840
828251052 813032112
322627026 328640184
630777206 93015078
143835290 305081041
78963996 850741582
185710453 415807807
224069168 194535462
765198511 925540935
67423218 161316172
139362266 380170512
23387958 140419953
727968221 212850176
929329071 680065291
80699708 674702419
824108967 489282458
563350357 865651077
580350921 922504314
124656307 134201888
513360123 776145804
161691774 176062866
681917529 535777959
798798922 678858034
778992896 889103485
983935974 111383938
589373003 592835023
980332103 729109938
586355723 562793775
424189799 402925777
326355130 246164484
106061524 868992059
175266265 361785497
247489202 829929333
872172162 585678993
725362470 819053997
856167633 586840059
474710785 856608830
638675377 822416002
176847119 78399228
238118171 211620634
302761599 410660344
340827370 584914156
840925927 471614751
278196506 194743308
921788254 661004915
418241172 372234551
423524176 744703832
79167871 125578990
808014283 603127562
319194141 766981002
81534592 626533314
359147052 464468288
279768551 598170192
659558263 966172428
339372240 602852466
583878922 371264416
674367424 759010423
テスト出力2
321022003 57262799
594857199 60772664
841286768 74441749
176847119 78399228
630777206 93015078
983935974 111383938
178220373 117577774
79167871 125578990
124656307 134201888
714725587 135574527
925126447 138391343
23387958 140419953
67423218 161316172
161691774 176062866
224069168 194535462
278196506 194743308
62710049 210080103
712001433 210877082
238118171 211620634
727968221 212850176
607948534 214246948
728567957 220290043
274016160 224876948
61883986 245487676
326355130 246164484
222610184 248356480
143835290 305081041
322627026 328640184
426231114 336813804
616274448 355808755
175266265 361785497
583878922 371264416
418241172 372234551
283022479 376033551
139362266 380170512
424189799 402925777
302761599 410660344
185710453 415807807
240199961 432234636
359147052 464468288
840925927 471614751
229826134 478391450
119317651 487762742
824108967 489282458
228873791 489714188
344285556 521741371
786823599 522783812
206662228 533989888
681917529 535777959
586355723 562793775
340827370 584914156
872172162 585678993
856167633 586840059
589373003 592835023
279768551 598170192
339372240 602852466
808014283 603127562
833231327 603241645
516111320 607515272
81534592 626533314
921788254 661004915
230829137 667556773
80699708 674702419
798798922 678858034
187877449 678955882
929329071 680065291
523186879 681227121
86470334 681700654
235309772 705607918
980332103 729109938
57997903 741784382
552745413 742568795
423524176 744703832
242294936 747031846
674367424 759010423
319194141 766981002
181182763 770306728
93942008 774494957
513360123 776145804
69129331 777444148
92450487 797581025
277000690 799270840
828251052 813032112
725362470 819053997
638675377 822416002
247489202 829929333
724829041 835108740
987178129 850725892
78963996 850741582
474710785 856608830
563350357 865651077
106061524 868992059
918457894 886239485
778992896 889103485
15453784 899476414
580350921 922504314
765198511 925540935
659558263 966172428
947102866 972781313
923423708 985237362
解答例
必ず自分で問題に挑戦してみてから見てください。
b, a の順でペアにすれば、sort するだけで b が小さい順に並べ替えることができます。クリックで解答例1を見る
N = int(input())
P = []
for i in range(N):
a, b = map(int, input().split())
# b, a の順でペアにする
P.append((b, a))
P.sort()
# b, a の順であることに注意
for b, a in P:
print(a, b)
sortのkeyを与えます。クリックで解答例2を見る
N = int(input())
P = []
for i in range(N):
a, b = map(int, input().split())
P.append((a, b))
# 2番目の要素でソート
P.sort(key = lambda x: x[1])
for a, b in P:
print(a, b)
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
次のように定義される関数 f(n) があります。
\[ f(n)=\begin{cases} 1 & (n=0のとき)\\ f\!\left(\left\lfloor\frac{n}{2}\right\rfloor\right) + f\!\left(\left\lfloor\frac{n}{3}\right\rfloor\right) + f\!\left(\left\lfloor\frac{n}{5}\right\rfloor\right) & (n\geq 1のとき) \end{cases} \]
\lfloor x \rfloor は x を整数に切り捨てた値を表します。例えば \lfloor 2.718 \rfloor=2、\lfloor 3 \rfloor=3 です。
正整数 N が与えられるので f(N) を求めてください。
制約
- 1 \le N \le 10^{18}
- N は整数
入力
入力は次の形式で標準入力から与えられます。
N
出力
f(N) を出力してください。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
3
出力例1
7
f(3)=f(1)+f(1)+f(0)=(f(0)+f(0)+f(0))+(f(0)+f(0)+f(0))+1=7 となります。
入力例2
987654321098765
出力例2
5977712553952371
ヒント
クリックでヒントを開く
functools.cache により関数をメモ化することができます。
テスト入出力
書いたプログラムが AC にならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
1
テスト出力1
3
テスト入力2
1000000000000000000
テスト出力2
7551346630825729459
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
from functools import cache
@cache # メモ化
def f(n):
if n == 0:
return 1
return f(n//2) + f(n//3) + f(n//5)
N = int(input())
print(f(N))
実行時間制限: 2 sec / メモリ制限: 1024 MiB
問題文
次のように定義される関数 f(n) があります。
f(n)=\begin{cases}0 & (n=0のとき)\\f(n-1)+1 & (n\geq 1 かつ\mathrm{popcount}(n)が奇数のとき)\\f(n-2)+1 & (n\geq 1 かつ\mathrm{popcount}(n)が偶数のとき)\end{cases}
\mathrm{popcount}(n) は n を 2 進法で表したときの 1 の個数を表します。例えば 13 は 2 進法で 1101 なので \mathrm{popcount}(13)=3 です。
正整数 N が与えられるので f(N) を求めてください。
制約
- 1 \le N \le 10^5
- N は整数
入力
入力は次の形式で標準入力から与えられます。
N
出力
f(N) を出力してください。
ジャッジでは以下の入力例以外のケースに関してもテストされることに注意。
入力例1
3
出力例1
2
\mathrm{popcount}(3)=2、\mathrm{popcount}(1)=1 なので
f(3)=f(3-2)+1=(f(1-1)+1)+1=(0+1)+1=2 となります。
入力例2
67890
出力例2
45260
ヒント
クリックでヒントを開く
n.bit_count() で求めることができます。sys.setrecursionlimit により再帰の上限回数を変更することができます。
テスト入出力
書いたプログラムが AC にならず、原因がどうしてもわからないときだけ見てください。
クリックでテスト入出力を見る
テスト入力1
1
テスト出力1
1
テスト入力2
100000
テスト出力2
66667
解答例
必ず自分で問題に挑戦してみてから見てください。
クリックで解答例を見る
# 再帰上限の引き上げ
import sys
sys.setrecursionlimit(10**6)
def f(n):
if n == 0:
return 0
if n.bit_count() % 2 == 1:
return f(n-1) + 1
else:
return f(n-2) + 1
N = int(input())
print(f(N))