E - Forbidden Prefix 解説
by  sotanishy
sotanishy

前提:トライ木 (Trie)
本問題は,トライ木 (Trie) の練習問題です.トライ木は,文字列のリストを根付き木として表現するデータ構造であり,木の各頂点に適切な情報を持たせることで,接頭辞に関する処理を効率的に行うことができます.
トライ木は,各頂点が文字を表し,根から他の頂点までのパスが文字列に対応するように構成されます.共通の接頭辞を持つ文字列は,トライ木の根に近い部分でパスを共有します.
トライ木の各頂点は,以下の情報を持ちます.
- その頂点が表す文字
- その頂点の子のリスト
- その頂点で受理される文字列のリスト:根からその頂点へのパスが表す文字列と一致する文字列のリスト
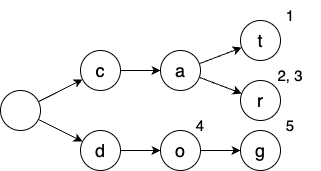
例えば,\((S_1,S_2,S_3,S_4,S_5)=(\texttt{cat},\texttt{car},\texttt{car},\texttt{do},\texttt{dog})\) という文字列のリストを表すトライ木は以下のようになります.頂点の右上の数字が,その頂点が受理する文字列を表しています.
本問題の解法
トライ木を用いて本問題を解く方法を述べます.与えられる文字列 \(S_i\) を(\(X,Y\) のどちらに属するかに関係なく)すべて \(1\) つのトライ木 \(T\) で管理します.また,「\(Y\) に含まれる文字列 \(S_i\) であって,ある \(X\) の要素 \(S_j\) を接頭辞として持つもの」の集合 \(Z\) を管理します.求める答えは \(|Y| - |Z|\) となります.\(S_i\) が与えられるごとに,\(Z\) を高速に更新できれば,問題を解くことができます.
\(Z\) に要素が追加される状況は以下の \(2\) 通りです.
- クエリ \(1\) において \(S_i\) を \(X\) に追加したことで,\(S_j \in Y \; (j<i)\) が \(S_i\) を接頭辞として含むようになり,\(S_j\) が \(Z\) に追加される
- クエリ \(2\) において \(S_i\) を \(Y\) に追加したことで,\(S_j \in X \; (j<i)\) が \(S_i\) に接頭辞として含まれるようになり,\(S_i\) が \(Z\) に追加される
以下,それぞれのクエリを処理する方法を述べます.
クエリ 1 の処理
\(S_i \in X\) を受理する頂点を根とする部分木に,\(S_j \in Y\) を受理する頂点があれば,\(S_j\) を \(Z\) に追加することになります.
部分木の頂点をすべて調べていては,実行時間制限に間に合いません.そこで,あらかじめ \(T\) の各頂点 \(v\) について,「次に \(v\) で受理されるような \(S_i\in X\) が追加されたとき,新たに \(Z\) に追加する \(S_j\in Y\) の集合」\(Z_v\) を管理しておきます.これはあらかじめ \(S_j \in Y\) を \(T\) に追加するときに,\(S_j\) の接頭辞を受理する頂点 \(v\) すべてについて,\(S_j\) を \(Z_v\) に追加しておけばよいです. そして,\(S_i\in X\) を追加するとき,\(S_i\) を受理する頂点を \(v\) として,「\(j\in Z_v\) をすべて \(Z\) に追加し,その後 \(Z_v\) を空にする」という操作を行います.\(Z_v\) の要素数は \(Q\) 個程度になりうるので,一見非効率的ですが,操作全体で \(S_j\) がいずれかの \(Z_v\) から取り出される回数はたかだか \(|S_j|\) 回です.よって,すべての処理にかかる時間計算量は \(O( \sum_{i=1}^Q |S_i| \log Q)\) です.
クエリ 2 の処理
\(S_i \in Y\) の接頭辞を受理する頂点 \(v\) であって,ある \(S_j \in X\) を受理するようなものがあるか判定すればよいです.これは,\(T\) の各頂点 \(v\) について,その頂点で受理される \(X\) の文字列が存在するかどうかを表すフラグ \(f_v\) を管理しておけばよいです.つまり,\(X\) の文字列を \(T\) に追加するとき,それを受理する頂点を \(v\) として \(f_v=\mathrm{true}\) と設定し,\(Y\) の文字列を追加したときには,その接頭辞を受理する頂点の先祖 \(v\) であって \(f_v=\mathrm{true}\) なるものがあるかどうか判定すればよいです.
まとめ
クエリ 1, 2 の処理をまとめて,各クエリについて以下のように処理をすればよいです.
- \(S_i\) を \(X\) に追加するとき
- \(S_i\) を \(T\) に追加する
- \(S_i\) を受理する頂点を \(v\) として,以下を行う
- 各 \(S_j\in Z_v\) を \(Z\) に追加する.その後,\(Z_v\) を空にする
- \(f_v=\mathrm{true}\) とする
- \(S_i\) を \(Y\) に追加するとき
- \(S_i\) を \(T\) に追加する
- \(S_i\) の接頭辞を受理する頂点 \(v\) それぞれについて以下を行う
- \(Z_v\) に \(i\) を追加する
- \(f_v=\mathrm{true}\) ならば,\(Z\) に \(i\) を追加する
全体の時間計算量は \(O(\sum_{i=1}^Q |S_i| \log Q)\) です.
投稿日時:
最終更新: