 /
/ 
実行時間制限: 2 sec / メモリ制限: 1024 MiB
配点 : 100 点
問題文
sは文字
m本の入力文字列s_1,...,s_mについて,それぞれの逆相補鎖配列を出力せよ.
制約
- s_1,...,s_mは
A ,C ,G ,T からなる文字列である. - 1 \leq m \leq 100とする.
- 1 \leq |s_1|, \ldots, |s_m| \leq 1000 (文字列xの長さを|x|と記述する.)
入力
入力は以下の形式で標準入力から与えられる.
m s1 s2 : sm
出力
入力文字列の逆相補鎖配列を出力せよ.各逆相補鎖配列は一行で出力し,対応する入力文字列と同じ順序で出力すること.
入力例 1
6 CATAGAACGACTATT TA GCGGCTTTTTGAAGCGT TACCTTGATCA GGCGTGCATAG T
出力例 1
AATAGTCGTTCTATG TA ACGCTTCAAAAAGCCGC TGATCAAGGTA CTATGCACGCC A
問題の背景
※ この項目は読まなくても問題を解くことができますが,出題の背景となりますため,ご興味を持ってくださった方はお読みいただけると幸いです.
DNAと塩基配列
生物の構成に必要な遺伝情報はDNAに保存されています.それでは,DNAはどのようにして遺伝情報を持つのでしょうか?
ヌクレオチドが鎖状に連なった物質を一本鎖DNAと呼びます.DNAは,長さが同じで対応関係のある二本の一本鎖DNAが結合してらせん構造を形成した物質です.ここではまず,一本鎖DNAについて説明をします. 一本鎖DNAを構成する各ヌクレオチドは塩基を一つ含みます.塩基はアデニン(adenin), シトシン(cytosin), グアニン(guanine),チミン(thymine) の4種類です.そのため,各ヌクレオチドの塩基を鎖の端から順に読み取ると,4種類の記号から成る配列と解釈することができます.鎖の両端は,ヌクレオチドの構造に応じて一方を5'末端,他方を3'末端と区別することができるため,一般的には,5'端から\rightarrow3'端の向きに記号を読み取って配列とみなします. この配列を,DNA配列,塩基配列,ゲノム配列などと呼びます.配列の各要素は塩基の頭文字により表現します.例えば下図のように,5'末端\rightarrow3'末端に向かってアデニン,シトシン,シトシン,チミンが並んでいる場合は,ACCTと表記します.
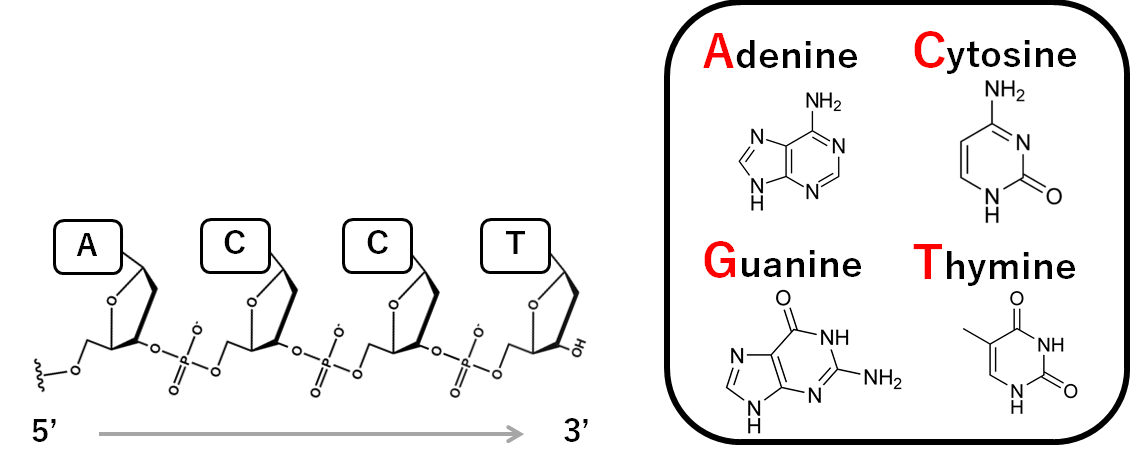
DNAの構造,逆相補鎖
一本鎖DNAの各塩基は,特定の別の塩基と結合する性質を持っています.具体的には,アデニン(A)はチミン(T)と,シトシン(C)はグアニン(G)と互いに結合します.DNAを構成する二本の鎖は,向かい合う塩基同士が全て結合するような塩基の並びをしており,それゆえに,二本の鎖が離れることなく二重らせんを形成できるのです.ここで注意が必要なのは,二本の鎖は互いに逆向きに並んでいるということです.下図の下の鎖では,5'末端\rightarrow3'末端に向かってアデニン(A),シトシン(C),チミン(T),グアニン(G)と並んでいます.上の鎖では5'末端\rightarrow3'末端に向かってシトシン(C),アデニン(A),グアニン(G),チミン(T)と並んでおり,それぞれの塩基は上の鎖の対応する塩基と結合しています.
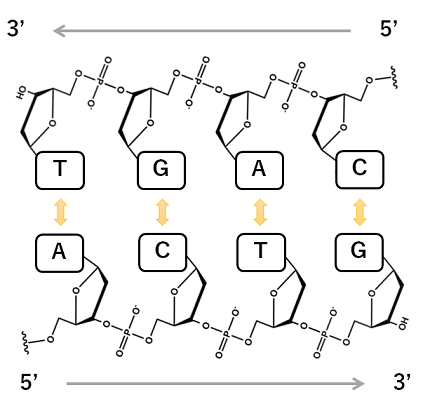
二重らせんを形成する一方の鎖に対して,もう一方の鎖を逆相補鎖と呼びます.図の例の場合,下の鎖の塩基配列はACTGと記述し,その逆相補鎖である上の鎖の塩基配列はCAGTと記述します.(TGACでないことに注意.) 二つの鎖は互いに対応関係のある塩基の並びをしているため,DNAは同一の情報を二重に保持しているといえます.そして,生物には一方の鎖に損傷が生じても,他方の鎖を元に損傷個所を復元する仕組みが備わっています. さて, DNAの遺伝情報は二本の鎖のどちらを読み出し元とするかによって,二通りの塩基配列で表記されることになります.例えば,DNAのある部分がAGGCと表記されている場合,その逆相補鎖の塩基配列であるGCCTと表記しても同じ情報とみなすことができるのです.
Score : 100 points
Problem Statement
s is a string consisting of characters
Output all the reverse complement sequences of m input sequences: s_1,...,s_m.
Constraints
- s_1,...,s_m are strings consisting of
A ,C ,G ,T . - 1 \leq m<100
- 1 \leq |s_1|, \ldots, |s_m| <1000 (the length of x is denoted by |x|.)
Input
Input is given from Standard Input in the following format:
m s1 s2 : sm
Output
Print reverse complement sequences of input sequences. Each sequence should be printed as a single line, and the order of the output sequences must be the same as the order of input sequences.
Sample Input 1
6 CATAGAACGACTATT TA GCGGCTTTTTGAAGCGT TACCTTGATCA GGCGTGCATAG T
Sample Output 1
AATAGTCGTTCTATG TA ACGCTTCAAAAAGCCGC TGATCAAGGTA CTATGCACGCC A