G - Copy Query 解説 by en_translator
This problem can be solved using a persistent segment tree.
Explanation of persistent segment tree itself can be found as an article of AtCoder Algorithm Lectures, which has just launched the other day. (Translator’s note: since there is no English translation for that article, I put a translation at the end of this editorial.)
Instead of maintaining a sequence itself, maintain a root of a segment tree at some moment.
If we denote by \(P_i\) a root corresponding to sequence \(A_i\), each query can be processed as follows:
- Type \(1\): replace \(R_{X_i}\) with \(R_{Y_i}\). The time complexity is \(O(1)\).
- Type \(2\): perform an element-wise update against the segment tree at the moment corresponding to \(R_{X_i}\). The time complexity is \(O(\log N)\).
- Type \(3\): perform a segment-wise operation against the segment tree at the moment corresponding to \(R_{X_i}\). The time complexity is \(O(\log N)\).
Sample code (C++):
#include<bits/stdc++.h>
using namespace std;
// https://ei1333.github.io/library/structure/segment-tree/persistent-segment-tree.hpp.html
template <typename Monoid>
struct PersistentSegmentTree {
using S = typename Monoid::S;
struct Node {
S d;
Node *l, *r;
};
using NP = Node*;
private:
int n{};
Monoid m;
NP merge(NP l, NP r) const { return new Node{m.op(l->d, r->d), l, r}; }
NP build(int l, int r, const vector<S>& v) const {
if (l + 1 == r) return new Node{v[l], nullptr, nullptr};
NP lp = build(l, (l + r) / 2, v);
NP rp = build((l + r) / 2, r, v);
return merge(lp, rp);
}
NP set(int a, const S& x, NP k, int l, int r) const {
if (r <= a || a + 1 <= l) {
return k;
} else if (a <= l && r <= a + 1) {
return new Node{x, nullptr, nullptr};
} else {
return merge(set(a, x, k->l, l, (l + r) >> 1),
set(a, x, k->r, (l + r) >> 1, r));
}
}
NP apply(int a, const S& x, NP k, int l, int r) const {
if (r <= a || a + 1 <= l) {
return k;
} else if (a <= l && r <= a + 1) {
return new Node{m.op(k->d, x), nullptr, nullptr};
} else {
return merge(apply(a, x, k->l, l, (l + r) >> 1),
apply(a, x, k->r, (l + r) >> 1, r));
}
}
S prod(int a, int b, NP k, int l, int r) const {
if (r <= a || b <= l) {
return m.e();
} else if (a <= l && r <= b) {
return k->d;
} else {
return m.op(prod(a, b, k->l, l, (l + r) >> 1),
prod(a, b, k->r, (l + r) >> 1, r));
}
}
public:
PersistentSegmentTree() = default;
explicit PersistentSegmentTree(Monoid m, int n) : m(m), n(n) {}
NP build(const vector<S>& v) const {
assert(n == (int)v.size());
return build(0, n, v);
}
NP set(NP t, int k, const S& x) const { return set(k, x, t, 0, n); }
S get(NP t, int k) const {
int l = 0, r = n;
while (l + 1 < r) {
int p = (l + r) / 2;
if (k < p) {
t = t->l;
r = p;
} else {
t = t->r;
l = p;
}
}
return t->d;
}
NP apply(NP t, int k, const S& x) const { return apply(k, x, t, 0, n); }
S prod(NP t, int a, int b) const { return prod(a, b, t, 0, n); }
S all_prod(NP t) const { return t->d; }
};
using ll=long long;
struct Mnd {
using S = ll;
static constexpr S op(const S& a, const S& b) { return (a+b); }
static constexpr S e() { return 0; }
};
int main(){
ll n,m,q;
cin >> n >> m >> q;
PersistentSegmentTree pseg(Mnd(),m);
vector<ll> ini(m,0);
auto iseg=pseg.build(ini);
vector< decltype(pseg)::NP > root(n,iseg);
vector<ll> res;
while(q--){
ll typ;
cin >> typ;
if(typ==1){
ll x,y;
cin >> x >> y;
x--; y--;
root[x]=root[y];
}
else if(typ==2){
ll x,y,z;
cin >> x >> y >> z;
x--; y--;
root[x]=pseg.set(root[x],y,z);
}
else{
ll x,l,r;
cin >> x >> l >> r;
x--; l--;
res.push_back(pseg.prod(root[x],l,r));
}
}
for(auto &nx : res){
cout << nx << "\n";
}
return 0;
}
Below is the translation of the article “persistent segment tree” in AtCoder Algorithm Lectures.
1. Summary
An ordinary segment tree discards old states on updates, only maintaining the newest version. On the other hand, a persistent segment tree allows access and update on any version in the past.
A persistent segment tree is not only a good introduction for persistent data structure, but also a data structure that is widely applicable in competitive programming.
In this article, we explain the fundamental structure of a persistent segment tree, and introduce applications based on actual contest problems.
2. Prerequisites
This article requires the basic knowledge of a segment tree and a lazy segment tree.
3. Persistent Data Structure
Usually, we work on ephemeral data structures. In other words, when we modify a data structure, we discard the old version and only keep the new version. To the contrary, a data structure that allows access and update to any versions in the past is called a fully persistent data structure. In this article, “persistent” refers to full persistence.
Let us take a specific example. Consider the following basic problem:
Problem 1. Given an integer sequence \(A = (A _ 1, A _ 2, \dots, A _ N)\), process \(Q\) given queries.
The \(q\)-th query is of one of the following two types:
1 i x: Set the $i$-th element of $A$ to $x$.2 l r: Output the minimum value among the $l$-th through $r$-th elements.
This problem can be solved with a segment tree in \(\mathrm{O}(\log N)\) time per query. How about this problem?
Problem 2. Given an integer sequence \(A _ 0 = (A _ {0,1}, A _ {0,2}, \dots, A _ {0,N})\), process \(Q\) given queries.
The \(q\)-th query is of one of the following two types:
1 t i x: Let \(A _ q\) be the sequence obtained by modifying the \(i\)-th element of sequence \(A _ t\) to \(x\).2 t l r: Output the minimum value among the \(l\)-th through \(r\)-th elements of \(A _ t\).
If the queries are offline, that is, if the \(Q\) queries are all given at once, we can prefetch those queries and use a segment tree to solve them. Specifically, if we regard an update query 1 t i x as an operation of turning \(A _ t\) into a new version \(A _ q\), the versions form a tree, so we can do DFS (Depth-First Search) on this tree while performing element-wise updates on the segment trees to handle queries against any versions. However, if the queries are online, that is, a new query is given only after answering the previous query, it cannot be solved with an ordinary segment tree.
We could also naively “store all previous sequences in an array,” but of course this costs \(O(N)\) time and space per query, which is quite inefficient.
Persistent data structures are utilized when we want to handle past states, as well as the present state, of the data structure, as in this example. (Especially, Problem 2 can be solved as efficiently as \(\mathrm{O}(\log N)\) time if we use a persistent data structure.)
Among various persistent data structures, in this article we introduce a most versatile data structure in competitive programming: persistent segment tree.
4. Persistent Segment Tree
A persistent segment tree is a persistent variant of a segment tree. In this chapter, we will describe the structure of a persistent segment tree.
4.1. Segment tree using a pointer
A persistent segment tree is a data structure based on a segment tree using pointers. (Such a segment tree is sometimes called a recursive segment tree.) To understand a persistent segment tree, let us review the structure of a pointer-based segment tree.
The figure below illustrates the segment tree corresponding to a sequence \((5, 9, 4, 7)\). A segment tree has a structure called leaf tree—in other words, each leaf stores information for an element of the underlying sequence, and internal nodes store data to merge them. Each internal node has exactly two pointers, to left and right children.
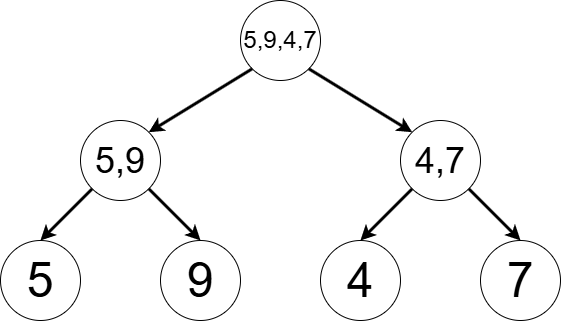
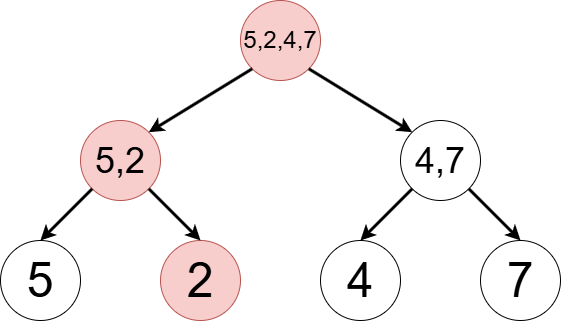
When we set the \(2\)-nd element to \(2\), the states of the vertices in the segment tree changes as follows. We can observer that the leaf corresponding to the \(2\)-nd element, as well as the ancestors, are updated. In total, \(\mathrm{O}(\log N)\) elements are updated, where \(N\) is the length of the sequence. We also see that the structure of the tree—or the pointees of the internal nodes’ pointers—remain invariant.
Let us extend our insight so far to understand the structure of a persistent segment tree. We will describe the following three operations:
- Updating an element
- Updating a segment
- Copy-pasting a segment
4.2. Updating an element
One important issue is how to identify the versions of a segment tree. That is, an ordinary segment tree has only version, so no identification is needed, while a persistent segment tree has multiple versions, which we need to distinguish.
In a persistent segment tree, this issue is resolved by corresponding a version to a root one-to-one; that is, a tree with different versions have different roots.
Based on this premiss, we will describe how to update an element of a persistent segment tree. As we already mentioned above, a persistent segment tree is a pointer-based segment tree, so the information storage format is identical to a segment tree.
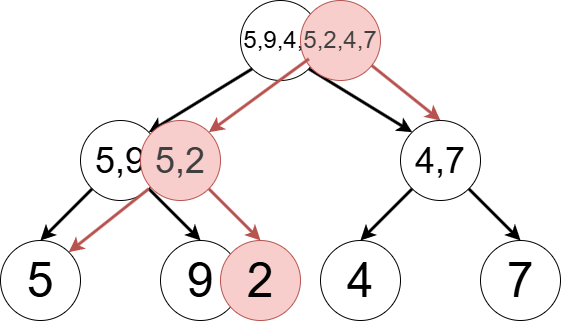
What is particular to a persistent segment tree is the operations required for an element update. As described before, updating an element of a segment tree requires modifying \(\mathrm{O}(\log N)\) vertices. However, rewriting the value on a vertex in the same way as we do for a segment tree destroys the information of an older version a segment tree, so we need to avoid it. Instead, for these \(\mathrm{O}(\log N)\) vertices, we clone those vertices to create new ones, and then modify the cloned vertices. This is the key operation of a persistent segment tree. We clone vertices, add appropriate edges to form a new segment tree, and treat its root as the new version.
The figure below visualizes a persistent segment tree managing the sequence \((5,9,4,7)\), and the modification we perform to set the \(2\)-nd element to \(2\), obtaining a segment tree of a new version (illustrated as red vertices). We can see that traversing form the white root yields the sequence \((5,9,4,7)\), and from the red root \((5,2,4,7)\). While the data structure has become quite complex, if we fix a specific root it can be handled in the same way as an ordinary segment tree. By constructing a new segment tree via cloning vertices, the segment trees of old and new versions can coexist.
4.3. Updating a segment
A persistent variant exists not only for an ordinary segment tree supporting element-wise updates, but also for a lazy segment tree supporting segment-wise updates.
A segment-wise update on a lazy segment tree is fulfilled as below:
- Propagate values for lazy evaluation, from root to leaves.
- Apply the desired operator against the vertices corresponding to the \(\mathrm{O}(\log N)\) segments.
- Compute the values resulting from the application, from leaves to root.
In these three steps, only \(\mathrm{O}(\log N)\) vertices are modified. Thus, just as an ordinary element-wise update, we may clone vertices every time we need to update them to obtain a new segment tree.
For example, to propagate values for lazy evaluation, we need to:
- clone the vertex itself, which stores the result of the propagation;
- clone the children nodes, and let the pointers point at them. Propagate values for lazy evaluation onto these cloned nodes.
Be careful not to propagate values to existent nodes.
4.4. Copy-pasting a segment
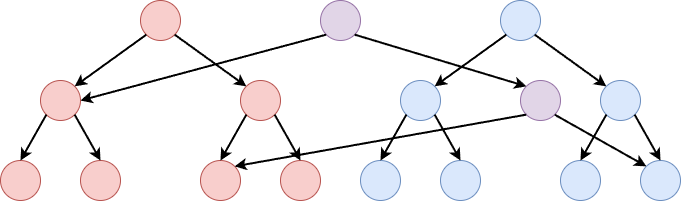
A special operation that is not supported by an ordinary segment tree is a copy-pasting a segment. More specifically, when there are lazy segment trees of the same versions, we may copy a segment in a certain version and paste it onto the same position in another version, to obtain a new version. Since a segment on a segment tree can be represented as \(\mathrm{O}(\log N)\), we may clone these nodes and modify the pointers.
For example, in the figure below, we copy the \(1\)-st through \(3\)-rd elements of the segment tree to the right onto the other to the left, to obtain the one in the middle.
4.5. Sample implementation
As a sample implementation of a persistent segment tree, we introduce a submission to Range Kth Smallest in Library Checker. The solution to the problem is described in Chapter 5, Problem 4.
5. Examples of Problems
(Translator’s note: This chapter will be translated in the near future.)
6. Summary
In this article, we described the structure of a persistent segment tree. A persistent segment tree involves a wide range of fundamental ideas of persistent data structures; understanding the working principle helps learning other persistent data structures like persistent arrays and persistent balanced binary search tree. There are many other kinds of persistent structures, so if you are interested, we recommend you to take a look at them too.
We also introduced several applications in the Example Problems chapter. A persistent segment tree has various applications, such as processing complex segment queries or optimizing DP. Keeping the techniques on hand enables solving a wide range of problems. We highly recommend working through the examples yourself to get a firm grasp of how persistent segment trees work.
7. References
- James R. Driscoll, Neil Sarnak, Daniel Dominic Sleator, Robert Endre Tarjan. Making Data Structures Persistent. Proceedings of the Eighteenth Annual ACM Symposium on Theory of Computing. pp. 109–121. 1986. DOI: 10.1145⁄12130.12142. https://doi.org/10.1145⁄12130.12142.
- 37zigenのHP. 永続セグメント木・永続遅延セグメント木. https://37zigen.com/persistent-segment-tree/. (Date viewed: 2026-04-05).
- USACO Guide. Persistent Data Structures. https://usaco.guide/adv/persistent?lang=cpp. (Date viewed: 2026-04-05).
投稿日時:
最終更新: