実行時間制限: 2 sec / メモリ制限: 1024 MiB
ストーリー
高橋くんは複数人で対戦する陣取りゲームで遊ぶことにした。 AI を相手に土地の支配を争い、できるだけ大差をつけて勝利することを目指せ。
問題文
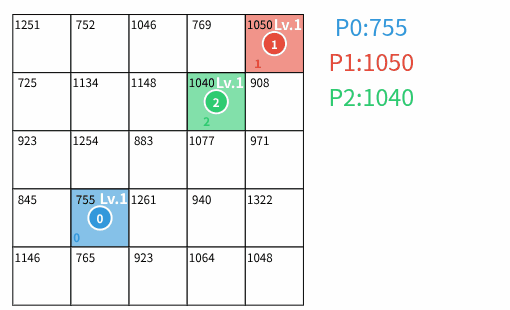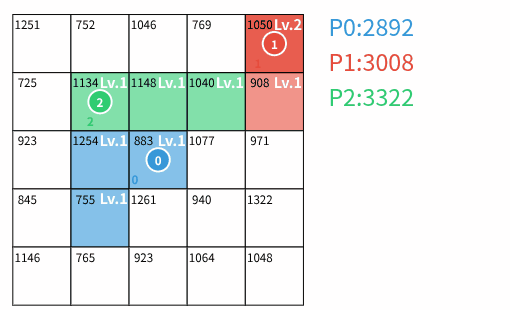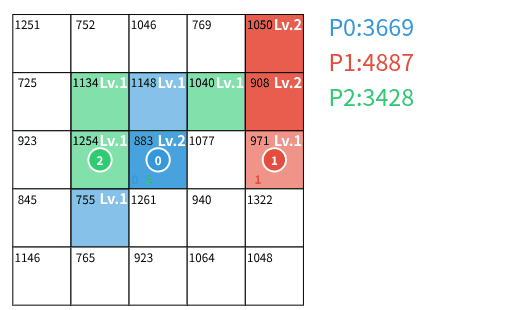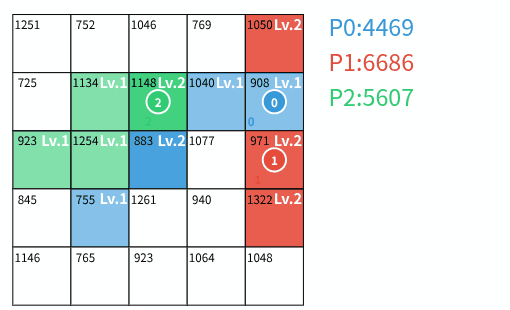
N\times N のマス目で表される土地がある。一番左上のマスの座標を (0,0) とし、そこから下方向に i マス、右方向に j マス移動した先のマスの座標を (i,j) とする。
この土地上で、M 人のプレイヤーが陣取りゲームを行う。 プレイヤーは 0 から M-1 までの M 人であり、高橋くん(プレイヤー 0)以外の M-1 人は AI が操作する。
各プレイヤー p は初期状態で 1 マスの初期領土 (sx_p,sy_p) を所有し、そのマスの上に駒を置く。
各マス (i,j) は価値 V_{i,j} とレベル L_{i,j} を持つ。 価値はゲームの進行によらず不変であり、レベルはゲームの進行に応じて変化する値である。 初期状態において、各プレイヤーの初期領土のレベルは 1 であり、誰の領土でもないマスのレベルは 0 である。
T ターンのゲームを行う。各ターンは以下の手順で進行する。
- 移動先の決定: 全てのプレイヤーは同時に駒の移動先を決定する。移動先は以下の条件を満たす必要がある。
- プレイヤーの駒の現在位置から、上下左右に隣接する自分の領土を経由して到達できるマスの集合を到達可能領土とする。このとき、移動先は到達可能領土に含まれるか、到達可能領土のいずれかのマスに隣接していなければならない。
- 移動先に他のプレイヤーの駒が存在してはならない。
- 競合解決: 全ての駒を同時に移動した後、2 つ以上の駒が存在する各マスについて以下の処理を行う。
- そのマスの所有者の駒が含まれる場合、その駒のみを盤面に残し、残りの駒を全て回収する。
- そのマスが誰の領土でもない場合、またはそのマスの所有者の駒が含まれない場合は、そのマスに存在する全ての駒を回収する。
- 領土の更新: 回収されなかった各プレイヤーの駒について、移動先マスの条件に応じて以下の処理を適用する。
- 占領: 誰の領土でもないマスの場合、自分の領土とし、レベルを 1 にする。
- 強化: 自分の領土の場合、レベルを 1 増加させる。ただし、レベルの上限は入力で与えられる定数 U であり、既に U の場合は変化しない。
- 攻撃: 他のプレイヤーの領土の場合、レベルを 1 減少させる。これによってレベルが 0 になった場合、そのマスを自分の領土とし、レベルを 1 にする。レベルが 0 にならなかった場合、攻撃したプレイヤーの駒を回収する。
- 駒の復帰: このターンに回収した駒は、このターンの開始時点(移動前)のマスに戻す。
なお、プレイヤーの駒は常に自分の領土上に存在し、駒が存在するマスは他のプレイヤーの攻撃対象にならないため、プレイヤーの領土が 0 マスになることはない。
T ターン終了後、各プレイヤー p の(到達可能でない領土を含む)全ての領土 (i,j) に対する V_{i,j} \times L_{i,j} の総和をプレイヤー p のスコア S_p とする。
高橋くんは、スコアの最も高い AI プレイヤーに対する自分のスコアの比率をなるべく大きくしたいと考えている。 すなわち、高橋くん(プレイヤー 0)のスコアを S_0、スコアの最も高い AI プレイヤーのスコアを S_A としたとき、S_0 / S_A がなるべく大きくなるように、プレイヤー 0 の各ターンの行動を決定せよ。
AIの行動決定方法
AI プレイヤー p (1\leq p\leq M-1) は内部パラメータ wa_p, wb_p, wc_p, wd_p, \varepsilon_p を持ち、以下のアルゴリズムで移動先を決定する。
各マス (i,j) のプレイヤー p にとっての評価値 A_{p,i,j} を次のように定義する。
- 誰の領土でもない場合: A_{p,i,j}=V_{i,j}\times wa_p
- 自分の領土でレベルが U 未満の場合: A_{p,i,j}=V_{i,j}\times wb_p
- 自分の領土でレベルが U の場合: A_{p,i,j}=0
- 他のプレイヤーの領土でレベルが 1 の場合: A_{p,i,j}=V_{i,j}\times wc_p
- 他のプレイヤーの領土でレベルが 2 以上の場合: A_{p,i,j}=V_{i,j}\times wd_p
プレイヤー p の移動可能な全てのマスの集合を B_p とする。以下のようにしてプレイヤー p の移動先を決定する。
- 確率 \varepsilon_p でランダム行動を行う。
- B_p の中から一様ランダムに 1 つ選ぶ。
- 確率 1-\varepsilon_p で貪欲行動を行う。
- B_p の中で評価値 A_{p,i,j} が最大のマスを選ぶ。そのようなマスが複数存在する場合は、その中から一様ランダムに 1 つ選ぶ。
得点
高橋くん(プレイヤー 0)のスコアを S_0、AI プレイヤーのうちスコアが最も高いもののスコアを S_A=\max_{1 \leq p \leq M-1} S_p とする。 このとき、テストケースの絶対スコアを \[ \mathrm{round}\left(10^5 \times \log_2\left(1+\frac{S_0}{S_A}\right)\right) \] とする。 絶対スコアは高ければ高いほど良い。
各テストケース毎に、\mathrm{round}\left(10^9 \times \frac{\text{自身の絶対スコア}}{\text{全参加者中の最大絶対スコア}}\right) の相対評価スコアが得られ、その和が提出の得点となる。
最終順位はコンテスト終了後に実施されるより多くの入力に対するシステムテストにおける得点で決定される。 暫定テスト、システムテストともに、不正な出力や制限時間超過をした場合、そのテストケースの相対評価スコアは0点となり、そのテストケースにおいては「全参加者中の最大絶対スコア」の計算から除外される。 システムテストは CE 以外の結果を得た一番最後の提出に対してのみ行われるため、最終的に提出する解答を間違えないよう注意せよ。
テストケース数
- 暫定テスト: 100個
- システムテスト: 3000個、コンテスト終了後に seeds.txt (sha256=24432b101519407fc0e5c2f92f3b939089115b79fd2e71ab3ee737ebc53e0601) を公開
相対評価システムについて
暫定テスト、システムテストともに、CE 以外の結果を得た一番最後の提出のみが順位表に反映される。相対評価スコアの計算に用いられる各テストケース毎の全参加者中の最大絶対スコアの算出においても、順位表に反映されている最終提出のみが用いられる。
順位表に表示されているスコアは相対評価スコアであり、新規提出があるたびに、相対評価スコアが再計算される。 一方、提出一覧から確認出来る各提出のスコアは各テストケース毎の絶対スコアをそのまま足し合わせたものであり、相対評価スコアは表示されない。 最新以外の提出の、現在の順位表における相対評価スコアを知るためには、再提出が必要である。 不正な出力や制限時間超過をした場合、提出一覧から確認出来るスコアは0となるが、順位表には正解したテストケースに対する相対スコアの和が表示されている。
実行時間について
実行時間には多少のブレが生じます。 また、システムテストでは同時に大量の実行を行うため、暫定テストに比べて数%程度実行時間が伸びる現象が確認されています。 そのため、実行時間制限ギリギリの提出がシステムテストでTLEとなる可能性があります。 プログラム内で時間を計測して処理を打ち切るか、実行時間に余裕を持たせるようお願いします。
入出力
はじめに、盤面のサイズ N、プレイヤー数 M、ターン数 T、レベル上限 U、各マス (i,j) の価値 V_{i,j}、各プレイヤー p の初期領土 (sx_p,sy_p) が以下の形式で標準入力から与えられる。
N M T U
V_{0,0} \cdots V_{0,N-1}
\vdots
V_{N-1,0} \cdots V_{N-1,N-1}
sx_0 sy_0
\vdots
sx_{M-1} sy_{M-1}
各値はそれぞれ以下の制約を満たす。
- N = 10
- 2\leq M\leq 8
- T = 100
- 1\leq U\leq 5
- 1\leq V_{i,j}
- \displaystyle\sum_{i,j}V_{i,j}=1000\times N^2
- 0\leq sx_p,sy_p\leq N-1
- 各プレイヤー p の初期領土 (sx_p,sy_p) は互いに相異なる。
上記の情報を読み込んだ後、各ターン t (1\leq t\leq T) について以下の入出力を繰り返す。
各ターンでは、プレイヤー 0 の駒の移動先 (tx_0,ty_0) を以下の形式で標準出力に一行で出力せよ。駒の移動先は、問題文に記載された条件を満たす必要がある。
tx_0 ty_0
出力の後には改行をし、更に標準出力を flush しなければならない。 そうしない場合、TLEとなる可能性がある。
その後、ターン t 終了時点の盤面情報として、各プレイヤー p が駒の移動先として選んだマス (tx_p,ty_p)、ターン終了時における各プレイヤー p の駒の位置 (ex_p,ey_p)、ターン終了時における各マス (i,j) の所有者 O_{i,j} およびレベル L_{i,j} が以下の形式で標準入力から与えられる。
tx_0 ty_0
\vdots
tx_{M-1} ty_{M-1}
ex_0 ey_0
\vdots
ex_{M-1} ey_{M-1}
O_{0,0} \cdots O_{0,N-1}
\vdots
O_{N-1,0} \cdots O_{N-1,N-1}
L_{0,0} \cdots L_{0,N-1}
\vdots
L_{N-1,0} \cdots L_{N-1,N-1}
各値はそれぞれ以下の制約を満たす。
- 0\leq tx_p,ty_p\leq N-1
- 0\leq ex_p,ey_p\leq N-1
- -1\leq O_{i,j}\leq M-1
- O_{i,j}=-1 の場合、そのマスは誰の領土でもないことを表す。
- 0\leq L_{i,j}\leq U
例
| ターン | Output | Input |
|---|---|---|
| 初期入力 | 10 3 100 2 990 1001 985 ... ... 3 4 7 2 5 8 |
|
| 1 | 3 5 |
3 5 7 3 5 7 3 5 7 3 5 7 -1 -1 -1 ... ... 0 0 0 ... ... |
| \vdots | ||
| 100 | 4 6 |
4 6 6 1 4 9 4 6 6 1 4 9 0 0 -1 ... ... 2 1 0 ... ... |
入力生成方法
L 以上 U 以下の整数値を一様ランダムに生成する関数を \mathrm{randint}(L,U)、 L 以上 U 未満の実数値を一様ランダムに生成する関数を \mathrm{randdouble}(L,U) で表す。
- プレイヤー数 M は \mathrm{randint}(2,8) により生成される。
- レベル上限 U は \mathrm{randint}(1,5) により生成される。
- 各プレイヤーの初期位置 (sx_p,sy_p) は互いに重複しないように一様ランダムに生成される。
V の生成
V_{i,j} は以下の手順で生成される。
- a=\mathrm{randdouble}(0.0,3.0) とする。
- 各マス (i,j) について、V_{i,j}=(\mathrm{randdouble}(0.5,1.0))^a で初期化する。
- K=\mathrm{randint}(0,2) とし、以下の手順を K 回繰り返す。
- x=\mathrm{randint}(0,N-1)、y=\mathrm{randint}(0,N-1)、b=\mathrm{randdouble}(1.0,4.0)、m=\mathrm{randint}(0,4)、R=\mathrm{randdouble}(1.0,5.0) とする。
- m の値に応じて各マス (i,j) に以下の加算を行う。
- m=0 : V_{i,j}=V_{i,j}+b\times\exp\left(-\frac{(i-x)^2+(j-y)^2}{2R^2}\right)
- m=1 : V_{i,j}=V_{i,j}+\frac{b}{1+\sqrt{(i-x)^2+(j-y)^2}/R}
- m=2 : (i-x)^2+(j-y)^2\leq R^2 を満たすマスに対し V_{i,j}=V_{i,j}+b/4
- m=3 : V_{i,j}=V_{i,j}+\frac{b}{1+(|i-x|+|j-y|)/R}
- m=4 : |i-x|+|j-y|\leq R を満たすマスに対し V_{i,j}=V_{i,j}+b/4
- 全ての V_{i,j} の総和を S とし、V_{i,j}=\left\lceil \frac{V_{i,j}\times 1000\times N^2}{S}\right\rceil とする。
- \displaystyle\sum_{i,j}V_{i,j}>1000\times N^2 の間、V_{i,j}\geq 2 を満たすマスの中から一様ランダムに 1 つ選んで V_{i,j} を 1 減少させることを繰り返す。
AI内部パラメータの生成
各 AI プレイヤー p (1\leq p\leq M-1) について、
- wa_p,wb_p,wc_p,wd_p はそれぞれ独立に \mathrm{randdouble}(0.3,1.0) により生成される。
- \varepsilon_p は \mathrm{randdouble}(0.1,0.5) により生成される。
ツール(入力ジェネレータ・ビジュアライザ)
- Web版: ローカル版より高性能でアニメーション表示と手動プレイが可能です。
- ローカル版: 使用するにはRust言語のコンパイル環境をご用意下さい。
- Windows用のコンパイル済みバイナリ: Rust言語の環境構築が面倒な方は代わりにこちらをご利用下さい。
コンテスト期間中に、seed=0 に対するビジュアライザの出力画像(PNG)のみ X で共有が可能です。動画形式での共有は禁止されているのでご注意下さい。 必ず指定されたハッシュタグを用い、公開アカウントを使用して下さい。共有出来るのはseed=0に対するビジュアライズ結果と点数のみで、GIF動画や出力文字列、他のシードでの点数の共有や、解法・考察に関する言及は禁止です。
ツールで用いられる入力ファイルの仕様
ローカルテスタに与える入力ファイルは解答プログラムに与えられる初期入力の末尾に以下の形式の情報が追加されている。これらの情報はジャッジ内部でのみ使用され、解答プログラムには与えられない。
初期入力に続いて M-1 行に、各AIプレイヤー p (1\leq p\leq M-1) の内部パラメータが以下の形式で与えられる。
wa_p wb_p wc_p wd_p \varepsilon_p
続いて T\times(M-1) 行に、各ターン t (1\leq t\leq T) および各 AI プレイヤー p (1\leq p\leq M-1) の行動決定に使用される互いに独立な 0 以上 1 未満の一様乱数 r_{1,t,p} と r_{2,t,p} が以下の形式で与えられる。 ここで、r_{1,t,p} はランダム行動か貪欲行動かの決定に、r_{2,t,p} は移動先の選択に使用される。
r_{1,t,p} r_{2,t,p}
サンプルプログラム
詳細
Python による解答例を示す。このプログラムでは、各ターンにおいてプレイヤー 0 の移動可能なマスの集合をBFSで計算し、その中から一様ランダムに移動先を選択している。
from collections import deque
import random
random.seed(0)
DX = [-1, 1, 0, 0]
DY = [0, 0, -1, 1]
def read_initial_input():
N, M, T, U = map(int, input().split())
V = [list(map(int, input().split())) for _ in range(N)]
sx, sy = [0] * M, [0] * M
for p in range(M):
sx[p], sy[p] = map(int, input().split())
owner = [[-1] * N for _ in range(N)]
level = [[0] * N for _ in range(N)]
px, py = list(sx), list(sy)
for p in range(M):
owner[sx[p]][sy[p]] = p
level[sx[p]][sy[p]] = 1
return N, M, T, U, V, owner, level, px, py
def get_candidates(N, M, owner, px, py):
reachable = {(px[0], py[0])}
queue = deque([(px[0], py[0])])
while queue:
x, y = queue.popleft()
for d in range(4):
nx, ny = x + DX[d], y + DY[d]
if 0 <= nx < N and 0 <= ny < N and (nx, ny) not in reachable and owner[nx][ny] == 0:
reachable.add((nx, ny))
queue.append((nx, ny))
candidates = set(reachable)
for x, y in reachable:
for d in range(4):
nx, ny = x + DX[d], y + DY[d]
if 0 <= nx < N and 0 <= ny < N:
candidates.add((nx, ny))
for p in range(1, M):
candidates.discard((px[p], py[p]))
return candidates
def read_turn_result(N, M, owner, level, px, py):
for _ in range(M):
tx, ty = map(int, input().split())
for p in range(M):
px[p], py[p] = map(int, input().split())
for i in range(N):
row = list(map(int, input().split()))
for j in range(N):
owner[i][j] = row[j]
for i in range(N):
row = list(map(int, input().split()))
for j in range(N):
level[i][j] = row[j]
def main():
N, M, T, U, V, owner, level, px, py = read_initial_input()
for _ in range(T):
candidates = get_candidates(N, M, owner, px, py)
tx, ty = random.choice(list(candidates))
print(tx, ty, flush=True)
read_turn_result(N, M, owner, level, px, py)
if __name__ == '__main__':
main()
Story
Takahashi has decided to play a territory-capturing game in which multiple players compete against each other. Compete against AI opponents for control of the land, and aim to win by as large a margin as possible.
Problem Statement
There is a land represented by an N\times N grid. Let (0, 0) be the coordinates of the top-left cell, and (i, j) be the coordinates of the cell located i cells down and j cells to the right from there.
On this land, M players play a territory-capturing game. The players are numbered from 0 to M-1. The other M-1 players besides Takahashi (player 0) are controlled by AI.
Each player p initially owns one cell (sx_p,sy_p) as their initial territory, and places a piece on that cell.
Each cell (i,j) has a value V_{i,j} and a level L_{i,j}. The value does not change throughout the game, while the level changes as the game progresses. In the initial state, the level of each player’s initial territory is 1, and the level of cells that belong to no player is 0.
The game consists of T turns. Each turn proceeds according to the following steps.
- Decision of Move Destination: All players simultaneously decide the destination of their piece. The destination must satisfy the following conditions.
- Define the reachable territory as the set of cells that can be reached from the current position of the player’s piece by traversing adjacent (up, down, left, right) cells that belong to the player. The destination must either be included in the reachable territory or be adjacent to at least one cell in the reachable territory.
- The destination must not contain another player’s piece.
- Conflict Resolution: After all pieces have been moved simultaneously, the following process is applied to each cell that contains two or more pieces.
- If the cell contains the piece of the owner of that cell, only that piece remains on the board and all other pieces on that cell are removed.
- If the cell belongs to no player, or if it does not contain the piece of the owner of that cell, then all pieces on that cell are removed.
- Territory Update: For each player’s piece that was not removed, apply the following process according to the condition of the destination cell.
- Occupation: If the cell belongs to no player, it becomes the player’s territory and its level becomes 1.
- Reinforcement: If the cell is already the player’s territory, increase its level by 1. However, the maximum level is the constant U given in the input; if the level is already U, it does not change.
- Attack: If the cell belongs to another player, decrease its level by 1. If the level becomes 0 as a result, the cell becomes the attacking player’s territory and its level becomes 1. If the level does not become 0, the attacking player’s piece is removed.
- Piece Restoration: All pieces removed during this turn are returned to the cells where they were located at the beginning of this turn (before movement).
Note that a player’s piece always exists on their own territory, and a cell containing a piece is not subject to attack by other players. Therefore, a player’s territory never becomes empty.
After T turns, the score S_p of each player p is defined as the sum of V_{i,j} \times L_{i,j} over all cells (i,j) that belong to player p (including territories that are not reachable).
Takahashi aims to maximize the ratio of his score to that of the highest-scoring AI player. That is, let S_0 be the score of Takahashi (player 0), and let S_A be the score of the highest-scoring AI player. Your task is to choose the actions of player 0 in each turn so as to maximize S_0 / S_A.
AI Action Policy
Each AI player p (1\leq p\leq M-1) has internal parameters wa_p, wb_p, wc_p, wd_p, and \varepsilon_p, and determines its move destination according to the following algorithm.
For each cell (i,j), define the evaluation value A_{p,i,j} for player p as follows.
- If the cell belongs to no player: A_{p,i,j}=V_{i,j}\times wa_p
- If the cell belongs to player p and its level is less than U: A_{p,i,j}=V_{i,j}\times wb_p
- If the cell belongs to player p and its level is U: A_{p,i,j}=0
- If the cell belongs to another player and its level is 1: A_{p,i,j}=V_{i,j}\times wc_p
- If the cell belongs to another player and its level is at least 2: A_{p,i,j}=V_{i,j}\times wd_p
Let B_p be the set of all cells to which player p can move. The move destination of player p is determined as follows.
- With probability \varepsilon_p, perform a random action.
- Choose one cell uniformly at random from B_p.
- With probability 1-\varepsilon_p, perform a greedy action.
- Choose a cell in B_p that maximizes A_{p,i,j}. If multiple such cells exist, choose one uniformly at random from among them.
Scoring
Let S_0 be the score of Takahashi (player 0), and let S_A=\max_{1 \leq p \leq M-1} S_p be the highest score among the AI players. The absolute score for a test case is defined as \[ \mathrm{round}\left(10^5 \times \log_2\left(1+\frac{S_0}{S_A}\right)\right). \] The higher the absolute score, the better.
For each test case, we compute the relative score \mathrm{round}(10^9\times \frac{\mathrm{YOUR}}{\mathrm{MAX}}), where YOUR is your absolute score and MAX is the highest absolute score among all competitors obtained on that test case. The score of the submission is the sum of the relative scores.
The final ranking will be determined by the system test with more inputs which will be run after the contest is over. In both the provisional/system test, if your submission produces illegal output or exceeds the time limit for some test cases, only the score for those test cases will be zero, and your submission will be excluded from the MAX calculation for those test cases.
The system test will be performed only for the last submission which received a result other than CE . Be careful not to make a mistake in the final submission.
Number of test cases
- Provisional test: 100
- System test: 3000. We will publish seeds.txt (sha256=24432b101519407fc0e5c2f92f3b939089115b79fd2e71ab3ee737ebc53e0601) after the contest is over.
About relative evaluation system
In both the provisional/system test, the standings will be calculated using only the last submission which received a result other than CE. Only the last submissions are used to calculate the MAX for each test case when calculating the relative scores.
The scores shown in the standings are relative, and whenever a new submission arrives, all relative scores are recalculated. On the other hand, the score for each submission shown on the submissions page is the sum of the absolute score for each test case, and the relative scores are not shown. In order to know the relative score of submission other than the latest one in the current standings, you need to resubmit it. If your submission produces illegal output or exceeds the time limit for some test cases, the score shown on the submissions page will be 0, but the standings show the sum of the relative scores for the test cases that were answered correctly.
About execution time
Execution time may vary slightly from run to run. In addition, since system tests simultaneously perform a large number of executions, it has been observed that execution time increases by several percent compared to provisional tests. For these reasons, submissions that are very close to the time limit may result in TLE in the system test. Please measure the execution time in your program to terminate the process, or have enough margin in the execution time.
Input and Output
First, the board size N, the number of players M, the number of turns T, the level cap U, the value V_{i,j} of each cell (i,j), and the initial territory (sx_p,sy_p) of each player p are given from Standard Input in the following format.
N M T U
V_{0,0} \cdots V_{0,N-1}
\vdots
V_{N-1,0} \cdots V_{N-1,N-1}
sx_0 sy_0
\vdots
sx_{M-1} sy_{M-1}
Each value satisfies the following constraints.
- N = 10
- 2\leq M\leq 8
- T = 100
- 1\leq U\leq 5
- 1\leq V_{i,j}
- \displaystyle\sum_{i,j}V_{i,j}=1000\times N^2
- 0\leq sx_p,sy_p\leq N-1
- The initial territories (sx_p,sy_p) of all players p are pairwise distinct.
After reading the above information, repeat the following input/output for each turn t (1\leq t\leq T).
In each turn, output the destination (tx_0,ty_0) of player 0's piece in one line to Standard Output in the following format. The destination must satisfy the conditions described in the problem statement.
tx_0 ty_0
The output must be followed by a new line, and you have to flush Standard Output. Otherwise, the submission might be judged as TLE.
Then, as the board information at the end of turn t, the cell (tx_p,ty_p) chosen by each player p as the move destination, the position (ex_p,ey_p) of each player p's piece at the end of the turn, and the owner O_{i,j} and level L_{i,j} of each cell (i,j) at the end of the turn are given from Standard Input in the following format.
tx_0 ty_0
\vdots
tx_{M-1} ty_{M-1}
ex_0 ey_0
\vdots
ex_{M-1} ey_{M-1}
O_{0,0} \cdots O_{0,N-1}
\vdots
O_{N-1,0} \cdots O_{N-1,N-1}
L_{0,0} \cdots L_{0,N-1}
\vdots
L_{N-1,0} \cdots L_{N-1,N-1}
Each value satisfies the following constraints.
- 0\leq tx_p,ty_p\leq N-1
- 0\leq ex_p,ey_p\leq N-1
- -1\leq O_{i,j}\leq M-1
- If O_{i,j}=-1, the cell belongs to no player.
- 0\leq L_{i,j}\leq U
Example
| Turn | Output | Input |
|---|---|---|
| Initial Input | 10 3 100 2 990 1001 985 ... ... 3 4 7 2 5 8 |
|
| 1 | 3 5 |
3 5 7 3 5 7 3 5 7 3 5 7 -1 -1 -1 ... ... 0 0 0 ... ... |
| \vdots | ||
| 100 | 4 6 |
4 6 6 1 4 9 4 6 6 1 4 9 0 0 -1 ... ... 2 1 0 ... ... |
Input Generation
Let \mathrm{randint}(L,U) denote a function that generates an integer value uniformly at random between L and U (inclusive). Let \mathrm{randdouble}(L,U) denote a function that generates a real value uniformly at random in the range [L,U).
- The number of players M is generated by \mathrm{randint}(2,8).
- The level cap U is generated by \mathrm{randint}(1,5).
- The initial positions (sx_p,sy_p) of the players are generated uniformly at random so that no two positions overlap.
Generation of V
V_{i,j} is generated by the following procedure.
- Let a=\mathrm{randdouble}(0.0,3.0).
- For each cell (i,j), initialize V_{i,j}=(\mathrm{randdouble}(0.5,1.0))^a.
- Let K=\mathrm{randint}(0,2), and repeat the following procedure K times.
- Let x=\mathrm{randint}(0,N-1), y=\mathrm{randint}(0,N-1), b=\mathrm{randdouble}(1.0,4.0), m=\mathrm{randint}(0,4), and R=\mathrm{randdouble}(1.0,5.0).
- Depending on the value of m, add the following to each cell (i,j).
- m=0 : V_{i,j}=V_{i,j}+b\times\exp\left(-\frac{(i-x)^2+(j-y)^2}{2R^2}\right)
- m=1 : V_{i,j}=V_{i,j}+\frac{b}{1+\sqrt{(i-x)^2+(j-y)^2}/R}
- m=2 : For cells satisfying (i-x)^2+(j-y)^2\leq R^2, set V_{i,j}=V_{i,j}+b/4
- m=3 : V_{i,j}=V_{i,j}+\frac{b}{1+(|i-x|+|j-y|)/R}
- m=4 : For cells satisfying |i-x|+|j-y|\leq R, set V_{i,j}=V_{i,j}+b/4
- Let S be the sum of all V_{i,j}, and set V_{i,j}=\left\lceil \frac{V_{i,j}\times 1000\times N^2}{S}\right\rceil.
- While \displaystyle\sum_{i,j}V_{i,j}>1000\times N^2, repeatedly choose one cell uniformly at random among those with V_{i,j}\geq 2 and decrease V_{i,j} by 1.
Generation of AI Internal Parameters
For each AI player p (1\leq p\leq M-1),
- wa_p,wb_p,wc_p,wd_p are generated independently by \mathrm{randdouble}(0.3,1.0).
- \varepsilon_p is generated by \mathrm{randdouble}(0.1,0.5).
Tools (Input generator and visualizer)
- Web version: This is more powerful than the local version providing animations and manual play.
- Local version: You need a compilation environment of Rust language.
- Pre-compiled binary for Windows: If you are not familiar with the Rust language environment, please use this instead.
You are allowed to share output images (PNG) of the provided visualizer for seed=0 on X during the contest. You have to use the specified hashtag and public account. You can only share visualization results and scores for seed=0. Do not share videos, output itself, scores for other seeds or mention solutions or discussions.
Input File Format Used by the Tool
The input file given to the local tester has additional information appended to the end of the initial input that is given to the solution program, in the following format. This information is used only inside the judge and is not given to the solution program.
Following the initial input, the internal parameters of each AI player p (1\leq p\leq M-1) are given in M-1 lines in the following format.
wa_p wb_p wc_p wd_p \varepsilon_p
Then, in T\times(M-1) lines, two independent uniform random numbers r_{1,t,p} and r_{2,t,p} in the range [0,1), which are used for action selection of each AI player p (1\leq p\leq M-1) in each turn t (1\leq t\leq T), are given in the following format. Here, r_{1,t,p} is used to decide whether to take a random action or a greedy action, and r_{2,t,p} is used to choose the move destination.
r_{1,t,p} r_{2,t,p}
Sample Solution
Details
A sample solution in Python is shown below. In this program, at each turn, the set of cells to which player 0 can move is computed using BFS, and one destination is chosen uniformly at random from among them.
from collections import deque
import random
random.seed(0)
DX = [-1, 1, 0, 0]
DY = [0, 0, -1, 1]
def read_initial_input():
N, M, T, U = map(int, input().split())
V = [list(map(int, input().split())) for _ in range(N)]
sx, sy = [0] * M, [0] * M
for p in range(M):
sx[p], sy[p] = map(int, input().split())
owner = [[-1] * N for _ in range(N)]
level = [[0] * N for _ in range(N)]
px, py = list(sx), list(sy)
for p in range(M):
owner[sx[p]][sy[p]] = p
level[sx[p]][sy[p]] = 1
return N, M, T, U, V, owner, level, px, py
def get_candidates(N, M, owner, px, py):
reachable = {(px[0], py[0])}
queue = deque([(px[0], py[0])])
while queue:
x, y = queue.popleft()
for d in range(4):
nx, ny = x + DX[d], y + DY[d]
if 0 <= nx < N and 0 <= ny < N and (nx, ny) not in reachable and owner[nx][ny] == 0:
reachable.add((nx, ny))
queue.append((nx, ny))
candidates = set(reachable)
for x, y in reachable:
for d in range(4):
nx, ny = x + DX[d], y + DY[d]
if 0 <= nx < N and 0 <= ny < N:
candidates.add((nx, ny))
for p in range(1, M):
candidates.discard((px[p], py[p]))
return candidates
def read_turn_result(N, M, owner, level, px, py):
for _ in range(M):
tx, ty = map(int, input().split())
for p in range(M):
px[p], py[p] = map(int, input().split())
for i in range(N):
row = list(map(int, input().split()))
for j in range(N):
owner[i][j] = row[j]
for i in range(N):
row = list(map(int, input().split()))
for j in range(N):
level[i][j] = row[j]
def main():
N, M, T, U, V, owner, level, px, py = read_initial_input()
for _ in range(T):
candidates = get_candidates(N, M, owner, px, py)
tx, ty = random.choice(list(candidates))
print(tx, ty, flush=True)
read_turn_result(N, M, owner, level, px, py)
if __name__ == '__main__':
main()
実行時間制限: 0 msec / メモリ制限: 1024 MiB